7.1. Перебор элементов контейнера
7.1. Перебор элементов контейнера
Проблема
Имеется диапазон итераторов — скорее всего, из стандартного контейнера — и стандартные алгоритмы не удовлетворяют вашим требованиям, так что вам требуется выполнить итерации самостоятельно.
Решение
Для доступа к элементам контейнера и перехода от одного элемента к другому используйте iterator или const_iterator. В стандартной библиотеке алгоритмы и контейнеры взаимодействуют с помощью итераторов, и одной из базовых идей стандартных алгоритмов является то, что они избавляют вас от необходимости непосредственного использования итераторов, за исключением тех случаев, когда вы пишете собственный алгоритм. И даже в этом случае вы должны понимать различные типы итераторов с тем, чтобы эффективно использовать стандартные алгоритмы и контейнеры. Пример 7.1 представляет некоторые простые способы использования итераторов.
Пример 7.1. Использование итераторов с контейнерами
#include <iostream>
#include <list>
#include <algorithm>
#include <string>
using namespace std;
static const int ARRAY_SIZE = 5;
template<typename T, typename FwdIter>
FwdIter fixOutliersUBound(FwdIter p1,
FwdIter p2, const T& oldVal, const T& newVal) {
for ( ; p1 != p2; ++p1) {
if (greater<T>(*p1, oldVal)) {
*p1 = newVal;
}
}
}
int main() {
list<string> lstStr;
lstStr.push_back("Please");
lstStr.push_back("leave");
lstStr.push_back("a");
lstStr.push_back("message");
// Создать итератор для последовательного перебора элементов списка
for (list<string>::iterator p = lstStr.begin();
p != lstStr.end(); ++p) {
cout << *p << endl;
}
// Или можно использовать reverse_iterator для перебора от конца
// к началу, rbegin возвращает reverse_iterator, указывающий
// на последний элемент, a rend возвращает reverse_iterator, указывающий
// на один-перед-первым.
for (list<string>::reverse_iterator p = lstStr.rbegin();
p != lstStr.rend(); ++p) {
cout << *p << endl;
}
// Перебор диапазона элементов
string arrStr[ARRAY_SIZE] = {"My", "cup", "cup", "runneth", "over"};
for (string* p = &arrStr[0];
p != &arrStr[ARRAY_SIZE]; ++p) {
cout << *p << endl;
}
// Использование стандартных алгоритмов со стандартной последовательностью
list<string> lstStrDest;
unique_copy(&arrStr[0], &arrStr[ARRAY_SIZE],
back_inserter(lstStrDest));
}
Обсуждение
Итератор — это тип, который используется для ссылки на единственный объект в контейнере. Стандартные контейнеры используют итераторы как основной механизм для доступа к содержащимся в них элементам. Итератор ведет себя как указатель; для доступа к объекту, на который указывает итератор, вы его разыменовываете (с помощью операторов * или ->), а для перевода итератора вперед или назад используется синтаксис, аналогичный арифметике указателей. Однако есть несколько причин, по которым итератор — это не то же самое, что указатель. Однако перед тем, как я покажу их, давайте рассмотрим основы использования итераторов.
Использование итераторов
Итератор объявляется с помощью типа, элементы которого с его помощью будут перебираться. Например, в примере 7.1 используется list<string>, так что итератор объявляется вот так.
list<string>::iterator p = lstStr.begin();
Если вы не работали со стандартными контейнерами, то часть этого объявления ::iterator может выглядеть несколько необычно. Это вложенный в шаблон класса list typedef, предназначенный именно для этой цели — чтобы пользователи контейнера могли создать итератор для данного конкретного экземпляра шаблона. Это стандартное соглашение, которому следуют все стандартные контейнеры. Например, можно объявить итератор для list<int> или для set<MyClass>, как здесь.
list<int>::iterator p1;
set<MyClass>::iterator p2;
Возвращаясь обратно к нашему примеру, итератор о инициализируется первым элементом последовательности, который возвращается методом begin. Чтобы перейти к следующему элементу, используется operator++. Можно использовать как префиксный инкремент так и постфиксный инкремент (p++), аналогично указателям на элементы массивов, но префиксный инкремент не создает временного значения, так что он более эффективен и является предпочтительным. Постфиксный инкремент (p++) должен создавать временную переменную, так как он возвращает значение p до его инкрементирования. Однако он не может инкрементировать значение после того, как вернет его, так что он вынужден делать копию текущего значения, инкрементировать текущее значение, а затем возвращать временное значение. Создание таких временных переменных с течением времени требует все больших и больших затрат, так что если вам не требуется именно постфиксное поведение, используйте префиксный инкремент.
Как только будет достигнут элемент end, переход на следующий элемент следует прекратить. Или, строго говоря, когда будет достигнут элемент, следующий за end. В отношении стандартных контейнеров принято некое мистическое значение, которое представляет элемент, идущий сразу за последним элементом последовательности, и именно оно возвращается методом end. Этот подход работает в цикле for, как в этом примере:
for (list<string>::iterator p = lstStr.begin();
p != lstStr.end(); ++p) {
cout << *p << endl;
}
Как только p станет равен end, p больше не может увеличиваться. Если контейнер пуст, то begin == end равно true, и тело цикла никогда не выполнится. (Однако для проверки пустоты контейнера следует использовать метод empty, а не сравнивать begin и end или использовать выражение вида size == 0.)
Это простое объяснение функциональности итераторов, но это не все. Во-первых, как только что было сказано, итератор работает как rvalue или lvalue, что означает, что его разыменованное значение можно присваивать другим переменным, а можно присвоить новое значение ему. Для того чтобы заменить все элементы в списке строк, можно написать нечто подобное следующему
for (list<string>::iterator p = lstStr.begin();
p != lstStr.end(); ++p) {
*p = "mustard";
}
Так как *p ссылается на объект типа string, для присвоения элементу контейнера новой строки используется выражение string::operator=(const char*). Но что, если lstStr — это объект типа const? В этом случае iterator не работает, так как его разыменовывание дает не-const объект. Здесь требуется использовать const_iterator, который возвращает только rvalue. Представьте, что вы решили написать простую функцию для печати содержимого контейнера. Естественно, что передавать контейнер следует как const-ссылку.
template<typename T>
void printElements(const T& cont) {
for(T::const_iterator p = cont.begin();
p ! = cont.end(); ++p) {
cout << *p << endl;
}
}
В этой ситуации следует использовать именно const, a const_iterator позволит компилятору не дать вам изменить *p.
Время от времени вам также может потребоваться перебирать элементы контейнера в обратном порядке. Это можно сделать с помощью обычного iterator, но также имеется reverse_iterator, который предназначен специально для этой задачи. reverse_iterator ведет себя точно так же, как и обычный iterator, за исключением того, что его инкремент и декремент работают противоположно обычному iterator и вместо использования методов begin и end контейнера с ним используются методы rbegin и rend, которые возвращают reverse_iterator. reverse_iterator позволяет просматривать последовательность в обратном порядке. Например, вместо инициализации reverse_iterator с помощью begin он инициализируется с помощью rbegin, который возвращает reverse_iterator, указывающий на последний элемент последовательности. operator++ перемещает его назад — по направлению к началу последовательности, rend возвращает reverse_iterator, который указывает на элемент, находящийся перед первым элементом. Вот как это выглядит.
for (list<string>::reverse_iterator p = lstStr.rbegin();
p != lstStr.rend(); ++p) {
cout << *p << endl;
}
Но может возникнуть ситуация, когда использовать reverse_iterator невозможно. В этом случае используйте обычный iterator, как здесь.
for (list<string>::iterator p = --lstStr.end();
p != --lstStr.begin(); --p) {
cout << *p << endl;
}
Наконец, если вы знаете, на сколько элементов вперед или назад следует выполнить перебор, используйте вычисление значения, на которое следует перевести итератор. Например, чтобы перейти в середину списка, сделайте вот так.
size_t i = lstStr.size();
list<string>::iterator p = begin();
p += i/2; // Переход к середине последовательности
Но помните: в зависимости от типа используемого контейнера эта операция может иметь как постоянную, так и линейную сложность. При использовании контейнеров, которые хранят элементы последовательно, таких как vector или deque, iterator может перейти на любое вычисленное значение за постоянное время. Но при использовании контейнера на основе узлов, такого как list, такая операция произвольного доступа недоступна. Вместо этого приходится перебирать все элементы, пока не будет найден нужный. Это очень дорого. Именно поэтому выбор контейнера, используемого в каждой конкретной ситуации, определяется требованиями к перебору элементов контейнера и их поиска в нем. (За более подробной информацией о работе стандартных контейнеров обратитесь к главе 6.)
При использовании контейнеров, допускающих произвольный доступ, для доступа к элементам использования operator[] с индексной переменной следует предпочитать iterator. Это особенно важно при написании обобщенного алгоритма в виде шаблона функции, так как не все контейнеры поддерживают iterator с произвольным доступом.
С итератором можно делает еще много чего, но не с любым iterator. iterator может принадлежать к одной из пяти категорий, обладающих разной степенью функциональности. Однако они не так просты, как иерархия классов, так что именно это я далее и опишу.
Категории итераторов
Итераторы, предоставляемые различными типами контейнеров, не обязательно все умеют делать одно и то же. Например, vector<T>::iterator позволяет использовать для перехода на некоторое количество элементов вперед operator+=, в то время как list<T>::iterator не позволяет. Разница между этими двумя типами итераторов определяется их категорией.
Категории итераторов — это, по сути, интерфейс (не технически; для реализации категорий итераторов абстрактные базовые классы не используются). Имеется пять категорий, и каждая предлагает увеличение возможностей. Вот как они выглядят — от наименее до наиболее функциональной.
Input iterator (Итератор ввода)
Итератор ввода поддерживает переход вперед с помощью p++ или ++p и разыменовывание с помощью *p. При его разыменовывании возвращается rvalue, iterator ввода используется для таких вещей, как потоки, где разыменовывание итератора ввода означает извлечение очередного элемента из потока, что позволяет прочесть только один конкретный элемент.
Output iterator (Итератор вывода)
Итератор вывода поддерживает переход вперед с помощью p++ или ++p и разыменовывание с помощью *p. От итератора ввода он отличается тем, что из него невозможно читать, а можно только записывать в него — по одному элементу за раз. Также, в отличие от итератора ввода, он возвращает не rvalue, a lvalue, так что в него можно записывать значение, а извлекать из него — нельзя.
Forward iterator (Однонаправленный итератор)
Однонаправленный итератор объединяет функциональность итераторов ввода и вывода: он поддерживает ++p и p++, а *p может рассматриваться как rvalue или lvalue. Однонаправленный итератор можно использовать везде, где требуется итератор ввода или вывода, используя то преимущество, что читать из него и записывать в него после его разыменовывания можно без ограничений
Bidirectional iterator (Двунаправленный итератор)
Как следует из его названия, двунаправленный iterator может перемещаться как вперед, так и назад. Это однонаправленный iterator, который может перемещаться назад с помощью --p или p--.
Random-access iterator (Итератор произвольного доступа)
Итератор произвольного доступа делает все, что делает двунаправленный iterator, но также поддерживает операции, аналогичные операциям с указателями.. Для доступа к элементу, расположенному в позиции n после p последовательности, можно использовать p[n], можно складывать его значение или вычитать из него с помощью +, +=, - или -=, перемещая его вперед или назад на заданное количество элементов. Также с помощью <, >, <= или >= можно сравнивать два итератора p1 и p2, определяя их относительный порядок (при условии, что они оба относятся к одной и той же последовательности).
Или можно представить все в виде диаграммы Венна. Она представлена на рис. 7.1.
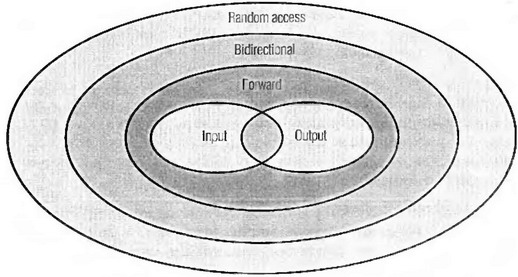
Рис. 7.1. Категории итераторов
Большая часть стандартных контейнеров поддерживает как минимум двунаправленный iterator, некоторые (vector и deque) предоставляют iterator произвольного доступа. Категория итератора, поддерживаемая контейнером, определяется стандартом.
В большинстве случае вы будете использовать iterator для простейших задач: поиск элемента и его удаление или что-либо подобное. Для этой цели требуется только однонаправленный iterator, который доступен для всех контейнеров. Но когда потребуется написать нетривиальный алгоритм или использовать алгоритм из стандартной библиотеки, часто потребуется нечто большее, чем простой однонаправленный iterator. Но как определить, что вам требуется? Здесь на сцену выходят категории итераторов.
Различные категории итераторов позволяют стандартным (и нестандартным) алгоритмам указать диапазон требуемой функциональности. Обычно стандартные алгоритмы работают с диапазонами, указываемыми с помощью итераторов, а не с целыми контейнерами. Объявление стандартного алгоритма говорит, какую категорию iterator он ожидает». Например, std::sort требует итераторов произвольного доступа, так как ему требуется за постоянное время ссылаться на несмежные элементы. Таким образом, объявление sort выглядит вот так.
template<typename RandomAccessIterator>
void sort(RandomAccessIterator first, RandomAccessIterator last);
По имени типа итератора можно определить, что он ожидает итератор произвольного доступа. Если попробовать откомпилировать sort для категории итератора, отличной от произвольного доступа, то она завершится ошибкой, так как младшие категории iterator не реализуют операций, аналогичных арифметике с указателями.
Категория итератора, предоставляемая определенным контейнером и требуемая определенным стандартным алгоритмом, — это то, что определяет, какой алгоритм с каким контейнером может работать. Многие из стандартных алгоритмов описаны далее в этой главе. Таблица 7.1 показывает сокращения, используемые в остальной части главы для указания типов итераторов, принимаемых алгоритмами в качестве аргументов.
Этот рецепт описывал итераторы, как они используются для контейнеров. Но шаблон итераторов используется не только для контейнеров, и, таким образом, имеются другие типы итераторов. Имеются потоковые итераторы, итераторы буферов потоков и итераторы хранения в необработанном виде, но они здесь не описываются.
Смотри также
Глава 6.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Создание контейнера с Web-формой поиска
Создание контейнера с Web-формой поиска Откроем Web-страницу index.htm в Блокноте, найдем созданный в главе 20 фрагмент кода, создающий Web-форму поиска, и удалим его. Вместо него мы вставим сразу после открывающего тега <BODY> код, приведенный в листинге 21.4. Листинг 21.4 <DIV
Создание контейнера с Web-формой поиска
Создание контейнера с Web-формой поиска Откроем Web-страницу index.htm в Блокноте, найдем созданный в главе 20 фрагмент кода, создающий Web-форму поиска, и удалим его. Вместо него мы вставим сразу после открывающего тега <BODY> код, приведенный в листинге 21.4. Листинг 21.4 <DIV
Количество элементов
Количество элементов Итак, список создан. Чтобы вставить в него элементы, достаточной задать их количество. Количество элементов в виртуальном списке задается одной из следующих функций.void CListCtrl::SetItemCount(int iCount);void CListCtrl::SetItemCountEx(int iCount, DWORD dwFlags = LVSICF_NOINVALIDATEALL);iCountновое
Содержание элементов
Содержание элементов Итак, виртуальный список хранит очень мало информации. За заполнение элементов перед отрисовкой отвечает приложение. Для этого список посылает уведомление LVN_GETDISPINFO. Обработчик несложно добавить, воспользовавшись ClassWizzard.В обработчике уведомления
Панель элементов
Панель элементов Добавление и удаление элементов управления из отчета выполняется с помощью кнопок группы Элементы управления , расположенной на вкладке Конструктор . На рис. 7.21 представлено изображения вкладки Конструктор с доступными для добавления в отчет
Добавление новых элементов в панель элементов управления
Добавление новых элементов в панель элементов управления Чтобы получить возможность использовать элемент управления ActiveX, выполните следующее.1. Установите программное обеспечение элемента управления на жесткий диск.Мне кажется, это имеет смысл.2. Зарегистрируйте
82. Используйте подходящие идиомы для реального уменьшения емкости контейнера и удаления элементов
82. Используйте подходящие идиомы для реального уменьшения емкости контейнера и удаления элементов РезюмеДля того чтобы действительно избавиться от излишней емкости контейнера, воспользуйтесь трюком с использованием обмена, а для реального удаления элементов из
7.2. Удаление объектов из контейнера
7.2. Удаление объектов из контейнера ПроблемаТребуется удалить объекты из контейнера.РешениеДля удаления одного или диапазона элементов используйте метод контейнера erase или один из стандартных алгоритмов. Пример 7.2 показывает пару различных способов удаления элементов
11.3. Вычисление суммы и среднего значения элементов контейнера
11.3. Вычисление суммы и среднего значения элементов контейнера ПроблемаТребуется вычислить сумму и среднее значение чисел, содержащихся в контейнере.РешениеДля расчета суммы можно использовать функцию accumulate из заголовочного файла <numeric> и затем разделить ее на
11.7. Инициализация контейнера случайными числами
11.7. Инициализация контейнера случайными числами ПроблемаТребуется заполнить произвольный контейнер случайными числами.РешениеМожно использовать функции generate и generate_n из заголовочного файла <algorithm> совместно с функтором, возвращающим случайные числа. Пример 11.13
Совет 1. Внимательно подходите к выбору контейнера
Совет 1. Внимательно подходите к выбору контейнера •Стандартные последовательные контейнеры STL: vector, string, deque и list.•Стандартные ассоциативные контейнеры STL: set, multiset, map и multimap.•Нестандартные последовательные контейнеры: slist и rope. Контейнер slist представляет односвязный
Совет 7. При использовании контейнеров указателей, для которых вызывался оператор new, не забудьте вызвать delete для указателей перед уничтожением контейнера
Совет 7. При использовании контейнеров указателей, для которых вызывался оператор new, не забудьте вызвать delete для указателей перед уничтожением контейнера Контейнеры STL отличаются умом и сообразительностью. Они поддерживают итераторы для перебора как в прямом, так и в
Совет 20. Определите тип сравнения для ассоциативного контейнера, содержащего указатели
Совет 20. Определите тип сравнения для ассоциативного контейнера, содержащего указатели Предположим, у нас имеется контейнер set, содержащий указатели string*, и мы пытаемся включить в него несколько новых элементов:set<string*> ssp; // ssp = "set of string ptrs"ssp.insert(new string("Anteater"));ssp.insert(new
Хранение элементов в коллекциях и получение элементов из коллекций
Хранение элементов в коллекциях и получение элементов из коллекций Коллекции — это такие объекты, в экземплярах которых могут храниться другие объекты. Одна из самых распространенных разновидностей коллекций — это массив, который инстанцирует NSArray или NSMutableArray. В
Циклический перебор объектов
Циклический перебор объектов Чтобы использовать циклический перебор объектов, выполните следующие действия.1. Активизируйте инструмент выбора щелчком на кнопке Arrow (Указатель) палитры ToolBox (Палитра инструментов).2. Если активна кнопка деактивизируйте ее, щелкнув на ней
Послушай клавиш перебор
Послушай клавиш перебор Команда исследователей из Калифорнийского университета в Беркли (UCB) внесла ощутимый вклад в понимание и освоение некогда сверхсекретной области компрометирующих излучений аппаратуры. На Западе эту тематику принято именовать кратким кодовым