Модель «сервер/субсервер»
Модель «сервер/субсервер»
Давайте теперь рассмотрим модель «сервер/субсервер», а затем наложим ее на модель многопоточности.
В соответствием с моделью «сервер/субсервер», сервер по- прежнему обеспечивает обслуживание клиентуры, но поскольку обслуживание запросов может занимать слишком много времени, мы должны быть способны поставить запрос на обработку и при этом не потерять способность обрабатывать новые запросы, продолжающие поступать от других клиентов.
Если бы мы попытались реализовать эту задачу с применением традиционной однопоточной модели «клиент/сервер», то после получения одного запроса и начала его обработки мы потеряли бы способность воспринимать другие запросы — нам приходилось бы периодически прекращать обработку, проверять, есть ли еще запросы, помещать таковые (если они есть) в очередь заданий и затем продолжать обработку, уже распыляя внимание на обработку всевозможных заданий, находящихся в очереди. Не очень-то эффективно. Фактически мы здесь дублируем работу ядра путем реализации дополнительного квантования времени между заданиями!
Представьте себе, каково вам было бы делать все это самому. Вы сидите за своим рабочим столом в офисе, и кто-то приносит вам полную папку заданий на выполнение. Вы начинаете их выполнять. Вы по уши заняты работой, и тут в дверном проеме появляется кто-то еще, с еще одним списком не менее первоочередных заданий. Теперь у вас на рабочем столе имеете два списка неотложных дел, и вы продолжаете работать, стараясь выполнить все. Вы тратите несколько минут на работы из одного списка, потом переключаете внимание на другой, и так далее, периодически посматривая на дверной проем, на случай если кто- нибудь принесет еще.
В такой ситуации было бы гораздо разумнее как раз применить модель «сервер/субсервер». В соответствии с этой моделью, у нас есть сервер, который создает ряд других процессов (субсерверов). Каждый из этих субсерверов посылает сообщение серверу, но сервер не отвечает им, пока не получит запрос от клиента. Затем сервер передает запрос клиента одному из субсерверов, отвечая на его сообщение заданием, которое субсервер обязан выполнить. Этот процесс показан на приведенном ниже рисунке. Отметьте для себя направления стрелок — они соответствуют направлениям передачи сообщений!
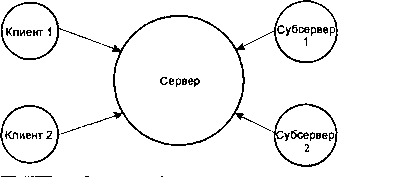
Модель «сервер/субсервер».
Если бы вы делали что-то подобное, вы бы, скорее всего, наняли дополнительно несколько служащих. Эти служащие все пришли бы к вам (как субсерверы посылают сообщение серверу — отсюда направление стрелок на рисунке) в поисках, чего бы такого сделать. Первоначально у вас могло и не быть для них никакой работы — в таком случае их запросы остались бы без ответа. Но теперь, когда кто-нибудь принесет вам кипу бумаг, вы скажете одному из ваших подчиненных: «Это тебе!» — и подчиненный пойдет заниматься делом. Аналогично, по мере поступления других заданий вы и далее будете делегировать их остальным подчиненным.
Хитрость этой модели заключается в том, что она является управляемой по ответу (reply-driven) — выполнение задания начинается с вашего ответа (reply) субсерверу. Стандартная же модель «клиент/сервер» является управляемой по запросу (send-driven), поскольку работа начинается с передачи сообщения серверу.
Но почему клиенты приходят именно к вам в офис, а не в офисы нанятых вами работников? Почему именно вы распределяете работу? Ответ довольно прост: вы — координатор, ответственный за определенную задачу, и ваша обязанность — гарантировать ее выполнение. Ваши клиенты, заказывающие вам работу, знают Вас, но не знают ни имен, ни местонахождения ваших (возможно, временных) работников.
Как вы, вероятно, и подозревали, концепцию единого многопоточного сервера и модель «сервер/субсервер» можно комбинировать. Главная хитрость при этом будет в определении того, какие части задачи лучше было бы распределить по машинам в сети (обычно это касается компонентов системы, которые не генерируют большого трафика), а какие — по процессорам SMP-архитектур (чаще всего это элементы, требующие наличия разделяемой области данных).
Зачем можно было бы комбинировать эти два метода? Используя подход «сервер/субсервер», мы сможем распределять работу между узлами сети. Это в действительности означает, что мы ограничены только числом доступных в сети машин (ну, и полосой пропускания сети, разумеется).
Объединение этот подход с принципом распределения потоков по различным процессорам в архитектурах SMP, мы получим «вычислительный кластер», где центральный «арбитр» распределяет работу (в модели «сервер/субсервер») между блоками SMP, объединенными в сеть.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Обмен сообщениями и модель «клиент/сервер»
Обмен сообщениями и модель «клиент/сервер» Представьте, что приложение читает данные из файловой системы. На языке QNX это значит, что данное приложение — это клиент, запрашивающий данные у сервера.Модель «клиент/сервер» позволяет говорить о нескольких рабочих
1.7. Модель OSI
1.7. Модель OSI Распространенным способом описания уровней сети является предложенная Международной организацией по стандартизации (International Standards Organization, ISO) модель взаимодействия открытых систем (open systems interconnection, OSI). Эта семиуровневая модель показана на рис. 1.5, где она
Модель ISO/OSI
Модель ISO/OSI Пожалуй, ключевым понятием в стандартизации сетей и всего, что к ним относится, является модель взаимодействия открытых систем (Open System Interconnection, OSI), разработанная «Международной организацией по стандартизации» (International Standards Organization, ISO). На практике применяется
8.16.1 Модель EGP
8.16.1 Модель EGP Маршрутизатор EGP конфигурируется с адресом IP для одного или нескольких внешних соседних маршрутизаторов. Обычно внешние соседи соединены с общей сетью с множественным доступом или объединены одной линией "точка-точка".EGP позволяет маршрутизатору
10.1.2 TCP и модель клиент/сервер
10.1.2 TCP и модель клиент/сервер TCP естественным образом интегрируется в окружение клиент/сервер (см. рис. 10.1). Серверное приложение прослушивает (listen) поступающие запросы на соединение. Например, службы WWW, пересылки файлов или доступа с терминала прослушивают запросы,
14.3 Модель FTP
14.3 Модель FTP Как видно из приведенного выше диалога, пользователь взаимодействует с локальным клиентом FTP (точнее, с соответствующим процессом). Программное обеспечение локального клиента управляет преобразованием данных для удаленного сервера FTP через управляющее
15.2 Модель RPC
15.2 Модель RPC Приложение клиент/сервер для архитектуры ONC функционирует поверх RPC. Работа RPC моделируется обычными вызовами подпрограмм. Например, в языке программирования С вызов обычной подпрограммы в общем случае имеет форму:код_возврата = имя_процедуры
16.14. Сервер kHTTPd — веб-сервер уровня ядра
16.14. Сервер kHTTPd — веб-сервер уровня ядра В операционной системе все процессы можно разделить на два типа: процессы уровня ядра и пользовательские процессы. Процесс уровня ядра запускается и работает очень быстро по сравнению с относительно неповоротливым
11.6.1. Модель фильтра
11.6.1. Модель фильтра Моделью проектирования интерфейсов, которая наиболее традиционно связывается с операционной системой Unix, является фильтр (filter). Программа-фильтр принимает данные на стандартном вводе, трансформирует их определенным образом, после чего они могут
11.6.2. Модель заклинаний
11.6.2. Модель заклинаний Модель заклинаний является простейшей из моделей проектирования интерфейсов. Нет ни ввода, ни вывода данных, только вызов и числовой код завершения. Режим работы заклинания контролируется только условиями запуска. Не существует другого типа
11.6.3. Модель источника
11.6.3. Модель источника Источником (source) является фильтр-подобная программа, которая не требует входных данных, а ее вывод управляется только начальными условиями. Принципиальными примером является утилита Ь( 1), программа для отображения содержимого каталогов в Unix. В
11.6.4. Модель приемника
11.6.4. Модель приемника Приемник (sink) — фильтр-подобная программа, которая принимает данные на стандартном вводе, но не отправляет никаких данных на стандартный вывод. Как и в двух предыдущих моделях, действия программы управляются только стартовыми условиями.Данная
Цветовая модель HSB
Цветовая модель HSB В качестве своеобразной «компенсации» за модель L*a*b, удобную для компьютеров и неудобную для людей, мир компьютерной графики включает модель HSB, которая, наоборот, удобна для людей и неудобна для вычислений. Поэтому, как правило, модель HSB используется
5.1.2. Модель памяти
5.1.2. Модель памяти При совместном использовании сегмента памяти один процесс должен сначала выделить память. Затем все остальные процессы, которые хотят получить доступ к ней, должны подключить сегмент. По окончании работы с сегментом каждый процесс отключает его.
Модель
Модель В любом интерьере наибольшее количество объектов — это модели. Модель может иметь произвольную форму: от примитивных сферы или куба до реалистичных форм человеческой фигуры. Модель призвана передавать формы конкретных объектов. Например, создавая интерьер, мы
Web-модель
Web-модель Web-модель получила свое название, поскольку базируется на популярных браузерах Netscape Navigator и Microsoft Internet Explorer, используемых как средства навигации во Всемирной Паутине - World Wide Web. Эта модель предусматривает встраивание в готовый браузер набора открытых ключей