Ядро в роли арбитра
Ядро в роли арбитра
Так кто же определяет, который из потоков должен выполняться в данный момент времени? Этим занимается ядро.
Ядро определяет, который из потоков должен использовать процессор в данный момент времени и переключает контекст на этот поток. Давайте посмотрим, что ядро при этом делает с процессором.
Процессор имеет несколько регистров (точное их число зависит от принадлежности процессора к серии, например, сравните процессор x86 с процессором MIPS, а характерный представитель серии, например, процессор 80486 — с процессором Pentium). В тот момент, когда поток выполняется, информация о нем хранится в указанных регистрах (например, данные о размещении программы в памяти).
Когда же ядро принимает решение о том, что должен выполняться другой поток, оно должно сделать следующее:
1. Сохранить текущее состояние регистров активного потока и другую контекстную информацию.
2. Записать в регистры информацию для нового потока, а также загрузить новый контекст.
Как ядро принимает решение о том, что должен выполняться другой поток? Оно анализирует, действительно ли в данный момент времени данный поток готов к использованию процессора. Когда мы обсуждали, например, мутексы, мы говорили о состояниях блокировки (это происходило в тех случаях, когда поток пытался завладеть мутексом, уже принадлежащим другому потоку, и поэтому блокировался). Таким образом, с точки зрения ядра мы имеем один поток, который может использовать процессор, и другой поток, которые не может этого делать, потому что он заблокирован в ожидании мутекса. В этом случае ядро предоставляет процессор потоку, который готов к работе, а другой поток заносит в свой внутренний список (чтобы можно было отслеживать отслеживал запрос потока на мутекс).
Очевидно, это не очень-то интересная ситуация. Предположим, что готовы к выполнению сразу несколько потоков. Вспомним, не мы ли делегировали доступ к мутексу на основе приоритета и продолжительности ожидания? Ядро тоже использует подобную схему для определения того, который из потоков должен работать следующим. При этом играют роль два фактора: приоритет и дисциплина диспетчеризации. Рассмотрим их по очереди.
Концепция приоритетов
Рассмотрим два готовых к выполнению потока. Если эти поток имеют различные приоритеты, то весьма прост — ядро отдает процессор потоку с высшим приоритетом. Приоритеты в QNX/ Neutrino пронумерованы от единицы (самый низкий) и далее, в единичным дискретом — так же, как это было упомянуто в обсуждении получения мутекса. Заметьте, что нулевой приоритет использовать нельзя — он зарезервирован для «холостого» (idle) потока (на профессиональном жаргоне часто называемого «холодильником» — прим. ред.). (Если вы захотите узнать минимальное или максимальное значение приоритета, определенное для вашей системы, используйте функции sched_get_priority_min() и sched_get_priority_max() — они описаны в <sched.h>. В данной книге мы будем предполагать, что приоритет 1 является самым низким, а 63 самым высоким.
Если другой поток с более высоким приоритетом вдруг становится готов к выполнению, ядро немедленно переключит контекст на поток с более высоким приоритетом. Это называется вытеснением— поток с высшим приоритетом вытесняет поток с низшим приоритетом. Когда поток с высшим приоритетом заканчивает свою работу, и ядро переключает контекст обратно на поток с низшим приоритетом, который выполнялся ранее, мы называем это возобновлением— ядро возобновляет работу предыдущего потока.
Теперь предположим, что не один, а два потока готовы к выполнению и имеют один и тот же приоритет.
Дисциплины диспетчеризации
Предположим, что в данное время выполняется один из потоков, Рассмотрим правила, которые используются ядром при принятии решения о переключении контекста в такой ситуации. (Разумеется, все это обсуждение в действительности применимо только к потокам с одинаковыми приоритетами — как только будет готов к выполнению поток с высшим приоритетом, процессор будет отдан ему. В этом вся суть приоритетов в операционной системе реального времени.)
Ядро QNX/Neutrino поддерживает две дисциплины диспетчеризации: карусельную, она же RR (Round Robin), и FIFO (First In — First Out).
Диспетчеризация FIFO
При диспетчеризации FIFO процессор предоставляется потоку на столько времени, сколько ему необходимо. Это означает, что если один поток занят длительными вычислениями, и никакой другой поток с более высоким приоритетом не готов к выполнению, то этот поток потенциально может выполняться вечно. А как же потоки с тем же приоритетом? Они будут заблокированы тоже. (То, что в этот же момент потоки с более низким приоритетом будут заблокированы, должно быть очевидно.)
Если работающий поток завершает свою работу или добровольно уступает процессор, ядро анализирует состояние других потоков того же самого приоритета на готовность их к выполнению. Если таковых не имеется, то ядро анализирует потоки с более низким приоритетом, готовые к выполнению. Заметьте, что выражение «добровольно уступить процессор» может означать одну из двух возможных ситуаций. Если поток переходит в режим ожидания, блокируется на семафоре, и т.д., тогда — да, может выполняться поток с более низким приоритетом (как описано выше). Но существует также специальная функция sched_yield() (базированная на системном вызове SchedYield()), по которому процессор передается только другому потоку с тем же самым приоритетом — если бы был готов к выполнению поток с высшим приоритетом, у потока с низшим приоритетом все равно не было бы никаких шансов получить управление. Если поток вызывает функцию sched_yield(), но никакой другой поток с таким же самым приоритетом не готов к выполнению, первоначальный поток продолжает работу. В реальности, функция sched_yield() применяется для того, чтобы дать шанс другому потоку с таким же самым приоритетом получить доступ к процессору.
На рисунке, приведенном ниже, мы видим три потока, размещенных в двух различных процессах:
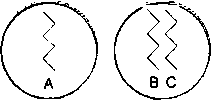
Три потока в двух различных процессах.
Если мы предположим, что потоки «А» и «В» находятся в состоянии READY («готов»), что поток «С» блокирован (возможно, в ожидании мутекса), а другой поток «D» (не показан) в настоящее время выполняется, то очередь готовности, которую поддерживает ядро QNX/Neutrino, будет выглядеть следующим образом:
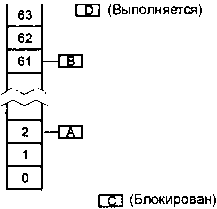
Два потока в очереди готовности, один блокирован, один выполняется.
На рисунке иллюстрируется внутренняя очередь готовности, которую использует ядро при принятии решения о том, кого запланировать на выполнение следующим. Заметьте, что поток «С» не находится в очереди готовности, потому что он блокирован, и поток «D» также не находится в этой очереди, потому что он уже выполняется.
Карусельная диспетчеризация (RR)
Дисциплина RR (карусельная диспетчеризация) аналогична дисциплине диспетчеризации FIFO, за исключением того, что поток не будет работать бесконечно, если имеется другой поток с тем же самым приоритетом. Поток будет работать только в течение предопределенного кванта времени (который фиксирован и не может быть изменен). Вы можете узнать величину кванта времени, используя функцию sched_rr_get_interval().
Когда ядро запускает на обработку поток с дисциплиной диспетчеризации RR, оно засекает время. Если поток не блокируется в течение выделенного ему кванта времени, квант времени истечет. Тогда ядро проверяет наличие другого готового к выполнению потока с тем же самым приоритетом. Если такой поток обнаруживается, то ядро активирует его. Если такого потока нет, то ядро снова ставит на выполнение предыдущий поток (то есть ядро выделяет потоку для работы еще один квант времени).
Постулаты
Давайте сделаем сводку правил диспетчеризации (для одиночного процессора) и отсортируем их в порядке важности:
• только один поток может выполняться в данный момент времени;
• всегда должен выполняться поток с наивысшим авторитетом;
• поток должен работать до тех пор, пока он не блокируется иди не завершается;
• поток, диспетчеризуемый по дисциплине карусельного типа (RR), должен работать в течение выделенного ему кванта времени, после чего ядро обязано его перепланировать (при необходимости).
Для систем с несколькими процессорами, приведенные выше правила остаются такими же, за исключением того, что несколько процессоров могут одновременно выполнять несколько потоков. Порядок, в котором потоки выполняются (то есть последовательность, в которой потоки ставятся на выполнение в многопроцессорной системе), определяется точно так же, как для одиночного процессора — в любой момент времени будет выполняться готовый к выполнению поток с наивысшим приоритетом. Если существует другой готовый к выполнению поток с более высоким приоритетом, и имеется доступный процессор, то этот поток будет выполняться на следующем процессоре, и так далее. Если имеющегося числа потоков недостаточно для того, чтобы загрузить все процессоры по такому принципу, то нет проблем — «неактивные» процессоры будут выполнять «холостой» поток (его приоритет равен нулю, то есть ниже, чем приоритет любого пользовательского потока) Если для того, чтобы обработать всю очередь, недостаточно процессоров, тогда только N потоков с наивысшим приоритетом будут выполняться, где N — число доступных процессоров. Другие потоки будут готовы к выполнению, но в действительности выполняться не будут. Отметим, что вопросы диспетчеризации потоков в симметричной мультипроцессорной системе все еще исследуются, так что возможно, что этот порядок может измениться в будущем.
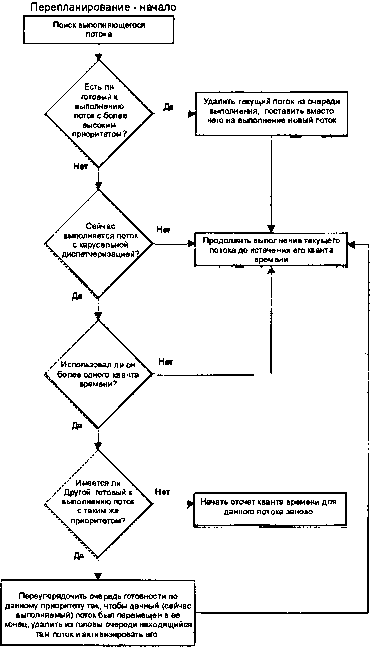
Схема алгоритма диспетчеризации.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Антагонистические роли
Антагонистические роли Одному из рецензентов книги эта глава очень не понравилась. Он сказал, что из-за нее он едва не отложил книгу. Ему доводилось создавать группы, в которых не было антагонистических отношений; группы работали вместе в гармонии и без конфронтации. Я
Ядро системы
Ядро системы Ядро обеспечивает базовую функциональность операционной системы: создает процессы и управляет ими, распределяет память и обеспечивает доступ к файлам и периферийным устройствам.Взаимодействие прикладных задач с ядром происходит посредством стандартного
Linux (ядро)
Linux (ядро) Официальная ссылкаLinux (2.4.19): ftp://ftp.kernel.org/pub/linux/kernel/Содержимое LinuxПоследняя проверка: версия 2.4.18.Файлы поддержкиЯдро Linux и и его заголовочные файлыОписанияЯдро LinuxЯдро – основа любой системы Linux. Когда компьютер включается и загружает Linux, первое, что загружается –
1.4. Ядро
1.4. Ядро Ядро — это сердце ОС, в котором реализовано управление физическими и программными ресурсами компьютера. Помимо этого оно позволяет получить доступ к различному железу. Например, ранние версии ядра обеспечивали работу только двух USB-устройств: клавиатура и мышь.
Семантическое ядро
Семантическое ядро Анализ семантического ядра на полноту охвата. Очень важно, чтобы семантическое ядро охватывало максимально возможное количество проблем пользователей и запросов, формирующих эти проблемы. Нужно выяснить:? охватывает ли семантическое ядро весь
Роли
Роли Роли InterBase - это своего рода суррогатные пользователи. Роли служат для организации пользователей с одинаковыми правами в группы. Например, если у нас имеется группа пользователей, для которых нужен достп только на чтение, то мы создаем роль с именем READER, присваиваем
7.4.1. Организационные роли
7.4.1. Организационные роли Роль представляет собой элемент определенной сферы ответственности, присваиваемый одному или нескольким лицам. В ключевых практиках часто используются следующие описания
Роли
Роли Чтобы девиз «Сам построил, сам и ломай» работал (и работал долго), вам нужна не только традиционная роль разработчика кода, но и другие роли. Конкретнее, должны появиться инженеры, которые помогут разработчикам тестировать эффективно и правильно. Они часто
Снова о роли форматтера .NET
Снова о роли форматтера .NET Заключительным элементом головоломки удаленного взаимодействия .NET является форматтер. Типы TcpChannel и HttpChannel используют свои внутренние форматтеры, задачей которых является перевод объекта сообщения в термины соответствующего протокола. Как
Ядро API Firebird
Ядро API Firebird Программирование с использованием API необходимо при написании драйверов для создания сценариев в таких языках, как PHP и Python, и при разработке объектно- ориентированных классов доступа к данным для объектно-ориентированных языков типа Java, C++ и Object Pascal.
Привилегии через роли
Привилегии через роли Процесс реализации ролей состоит из четырех шагов:1. Создание роли с использованием оператора CREATE ROLE.2. Назначение привилегий этой роли посредством GRANT привилегия то роль.3. Назначение роли пользователям посредством GRANT роль то пользователь.4. Задание
Создание роли
Создание роли Синтаксис создания роли прост:CREATE ROLE <имя-роли>;Пользователь SYSDBA или владелец базы может создавать роли, предоставлять им привилегии и передавать эти "нагруженные" роли пользователям. Если роль предоставлена с параметром WITH ADMIN OPTION, получатель этой роли
Удаление роли
Удаление роли Если вы удаляете роль, то все привилегии, предоставленные этой роли, отменяются. Чтобы удалить роль MAITRE_D, выполните:DROP ROLE MAITRE D;! ! !ПРИМЕЧАНИЕ. Если вам нужно лишь удалить привилегии, предоставленные пользователю с помощью роли, или удалить привилегии роли,
Определить роли и обязанности
Определить роли и обязанности Ясно определяйте роли и обязанности по обеспечению безопасности в вашей компании. Если ответственность по обеспечению безопасности пересекает границы между подразделениями (например, ложится одновременно на системных администраторов,