Идентификаторы отправителя, каналы и другие параметры
Идентификаторы отправителя, каналы и другие параметры
Мы с вами пока не обсуждали различные параметры, используемые в ранее рассмотренных примерах, чтобы можно было сконцентрировать внимание на самих принципах обмена сообщениями. Теперь поговорим об этих параметрах более подробно.
Дополнительно о каналах
В приведенном выше примере с сервером мы видели, что сервер создал один-единственный канал. Конечно, можно было создать больше, но обычно серверы так не делают. (Наиболее очевидный пример сервера с двумя каналами — это администратор штатной сети qnet — вот уж определенно эксцентричный образец программного обеспечения !)
Оказывается, что в действительности нет большой необходимости в создании нескольких каналов. Главное назначение канала состоит в том, чтобы четко указать серверу, где «слушать» на предмет входящих сообщений, и четко указать клиентам, куда передавать сообщения (через соответствующие соединения). Единственная ситуация, когда вам могло бы понадобиться использовать несколько каналов в сервере, — это если бы хотели реализовать сервер, предоставляющий различные услуги (или различные классы услуг) в зависимости от того, по какому каналу было принято сообщение. Второй канал мог бы применяться, например, для отправки сообщений типа «импульс», пробуждающих субсерверы — это гарантировало бы развязку этого сервиса от служебных функций, предоставляемых обычными сообщениями по первому каналу.
В предыдущем параграфе я утверждал, что вы могли бы использовать в сервере пул потоков, готовый принимать сообщения от клиентов, и что реально не имеет значения, который именно из потоков в пуле получит запрос. Это еще один аспект «канальной абстракции». В предыдущих версиях QNX (особенно в QNX4), клиент мог передать сообщение серверу, определяя его идентификатором узла (node ID) и идентификатором процесса (process ID) на этом узле. Поскольку QNX4 — однопоточная ОС, никакого беспорядка с тем, кому передается сообщение, в ней быть не могло. Однако, стоит ввести понятие потока, и встает дополнительная проблема адресации потоков в процессе (ведь именно потоки собственно предоставляют сервисы). Поскольку поток — вещь преходящая, в действительности для клиента не имеет смысла подключаться к четко определенному потоку в четко определенном процессе на четко определенном узле. К тому же, а что если нужный поток занят? Мы тогда должны были бы обеспечить клиенту возможность выбрать «незанятый поток из некоторого пула потоков, предоставляющих нужный сервис».
Так вот, для этого и существуют каналы. Канал — это «адрес» некоторого «пула потоков, предоставляющих нужный сервис». Суть здесь заключается в том, что вызвать функцию MsgReceive() по одному и тому же каналу могут несколько потоков одновременно. Все они будут блокированы, но входящее сообщение будет передано только одному из них.
Кто послал сообщение?
Довольно часто серверу необходимо знать, кто послал ему сообщение. Для этого есть ряд причин, например:
• учет клиентов;
• управление доступом;
• определение контекстных связей;
• выбор типа сервиса;
• и т.д.
Сделать так, чтобы клиент передавал серверу эту информацию с каждым сообщением, было бы излишне громоздким (да и давало бы лишние лазейки в системе защиты). Поэтому существует специальная структура, заполняемая ядром всякий раз, когда функция MsgReceive() разблокируется, приняв сообщение. Эта структура имеет тип struct _msg_info и содержит в себе следующее:
struct _msg_info {
int nd;
int srcnd;
pid_t pid;
int32_t chid;
int32_t scoid;
int32_t coid;
int32_t msglen;
int32_t tid;
int16_t priority;
int16_t flags;
int32_t srcmsglen;
};
Вы передаете все это функции MsgReceive() в качестве последнего параметра. Если вы передаете NULL, то не произойдет ничего. (Информацию все равно можно будет потом получить с помощью вызова функции MsgInfo() — она не теряется!)
Давайте взглянем на поля этой структуры:
nd, srcnd, pid и tid Это дескриптор узла, идентификатор процесса и идентификатор потока клиента. (Заметьте, что nd — это дескриптор принимающего узла для режима передачи, a srcnd — это дескриптор передающего узла для режима приема. Для этого имеется очень серьезное основание ;-), которое мы рассмотрим ниже в разделе «Несколько замечаний о дескрипторах узлов»). priority Приоритет потока, пославшего сообщение. chid, coid Идентификатор канала, по которому сообщение было передано, и идентификатор использованного при этом соединения. scoid Идентификатор соединения с сервером. Это внутренний идентификатор, который применяется ядром для маршрутизации сообщения от сервера назад к клиенту Вам не нужно ничего знать об этом идентификаторе, кроме одного любопытно факта, что это будет небольшое целое число, которое уникально идентифицирует клиента. flags Содержит различные битовые флаги: _NTO_MI_ENDIAN_BIG, _NTO_MI_ENDIAN_DIFF, _NTO_MI_NET_CRED_DIRTY и _NTO_MI_UNBLOCK_REQ. Биты _NTO_MI_ENDIAN_BIG и _NTO_MI_ENDIAN_DIFF сообщат вам о порядке байт в слове для отправившей сообщение машины (в случае, если сообщение пришло через сеть от машины с другим порядком байт), бит _NTO_MI_NET_CRED_DIRTY зарезервирован для внутреннего использования, значение бита _NTO_MI_UNBLOCK_REQ мы рассмотрим в разделе «Использование бита _NTO_MI_UNBLOCK_REQ», см. ниже. msglen Число принятых байт. srcmsglen Длина исходного сообщения в байтах, как оно было отправлено клиентом. Это число может превышать значение msglen — например, в случае приема меньшего количества данных, чем было послано. Заметьте, что это поле действительно только в том случае, если установлен бит _NTO_CHF_SENDER_LEN в переданном функции ChannelCreate() (для канала, по которому было получено данное сообщение) параметре flags.Идентификатор отправителя (receive ID), он же клиентский жетон (client cookie)
В примере программы, представленном выше, отметьте следующее:
rcvid = MsgReceive(...);
...
MsgReply(rcvid, ...);
Это — ключевой фрагмент, потому что именно в нем иллюстрируется привязка приема сообщения от клиента к последующему ответу этому конкретному клиенту. Идентификатор отправителя — это целое число, которое действует как жетон («magic cookie»), который вы получаете от клиента и обязаны хранить, если вы желаете впоследствии взаимодействовать с этим клиентом. Что произойдет, если вы его потеряете? Его больше нет. Функция MsgSend() клиента не разблокируется, пока вы (конкретный сервер) живы, или пока не произошел тайм-аут обмена сообщениями (и даже в этом случае все не так просто; см. функцию TimerTimeout() в справочном руководстве по библиотеке Си и обсуждение о применения в главе «Часы, таймеры и периодические уведомления», раздел «Тайм-ауты ядра»).
 Не пытайтесь извлечь из значения идентификатора отправителя какой-либо конкретный смысл — он может измениться в будущих версиях операционной системы. Единственное, что нужно знать — что он уникален, то есть у вас никогда не будет двух различных клиентов с одним и тем же идентификатором отправителя (иначе ядро просто не сможет их различить, когда вы вызовете MsgReply()).
Не пытайтесь извлечь из значения идентификатора отправителя какой-либо конкретный смысл — он может измениться в будущих версиях операционной системы. Единственное, что нужно знать — что он уникален, то есть у вас никогда не будет двух различных клиентов с одним и тем же идентификатором отправителя (иначе ядро просто не сможет их различить, когда вы вызовете MsgReply()).
Отметим также, что за исключением одного частного случая (с применением функции MsgDeliverEvent(), которую мы рассмотрим позже), после вызова функции MsgReply() соответствующий идентификатор отправителя перестает иметь смысл.
Таким образом, мы плавно переходим к функции MsgReply().
Ответ клиенту
Функция MsgReply() принимает в качестве параметров идентификатор отправителя, код возврата, указатель на сообщение и размер этого сообщения. Мы только что обсудили идентификатор отправителя — он уникально идентифицирует того, кому должно быть отправлено ответное сообщение. Код возврата указывает, какой код должна возвратить функция MsgSend() клиента. Наконец, указатель на сообщение и размер указывают на местоположение и размер (необязательного!) ответного сообщения, которое следует отправить.
Функция MsgReply() может показаться очень простой (и так оно и есть), но рассмотреть ее применение было бы полезно.
А можно и не отвечать
Однако, вы вовсе не обязаны обязательно ответить клиенту перед приемом новых сообщений от других клиентов с помощью функции MsgReceive()! Это положение можно с успехом использовать в множестве различных сценариев.
В типовом драйвере устройства клиент может выдать запросом, который не будет обслужен в течение продолжительного времени. Например, клиент может запросить драйвер аналого-цифрового преобразователя (АЦП): «Сходи-ка принеси мне данные за следующие 45 секунд.» Драйвер АЦП не может себе позволить вывесить табличку «Закрыто» на целых 45 секунд, потому что другим клиентам тоже может срочно что-нибудь понадобиться — например, данные по другому каналу, информация о состоянии, и т.п.
В соответствии со своей архитектурой, драйвер АЦП просто поставит в очередь полученный от функции MsgReceive() идентификатор отправителя, осуществит запуск 45-секундного процесса накопления данных и снова вернется к обработке клиентских запросов. По истечении этого 45-секундного интервала, когда данные накоплены, драйвер АЦП сможет найти идентификатор отправителя, связанный с данным запросом, и ответить нужному клиенту.
Вам также может понадобиться задержаться с ответом клиенту в случае модели «сервер/субсервер» (то есть некоторые клиенты — на самом деле субсерверы). Вы можете просто запомнить идентификаторы ищущих работу субсерверов и сохранить их до поры до времени. Когда работа для субсерверов появится, тогда и только тогда вы ответите субсерверу, указав, что именно он должен сделать.
Ответ без данных или с кодом ошибки (errno)
Когда дело наконец доходит до ответа клиенту, вы совершенно не обязаны передавать ему какие-либо данные. Это может использоваться в двух случаях.
Вы можете отправить клиенту ответ без данных, если единственная цель ответа — разблокировать клиента. Скажем, клиент желает быть блокированным до некоторого события, а до какого именно — ему знать не обязательно. В этом случае функции MsgReply() не потребуется никаких данных, достаточно будет только идентификатора отправителя:
MsgReply(rcvid, EOK, NULL, 0);
Такой вызов разблокирует клиента (но не передаст ему никаких данных) и возвратит код EOK («успешное завершение»).
Как вариант, вы можете при желании возвратить клиенту код ошибки. Вы не сможете сделать это с помощью функции MsgReply(), вместо нее для этого используется функция MsgError():
MsgError(rcvid, EROFS);
В приведенном выше примере сервер обнаруживает, что клиент пытается записать данные в файловую систему, предназначенную только для чтения, и вместо данных возвращает клиенту код ошибки (errno) EROFS.
Еще одним поводом ответить клиенту без данных (и соответствующие вызовы мы вскоре рассмотрим) может быть то, что данные уже переданы ранее (с помощью функции MsgWrite()), и больше никаких данных нет.
Почему применяются два типа вызовов? Они немного различны. В то время как обе функции MsgError() и MsgReply() разблокируют клиента, функция MsgError() при этом не передаст никаких данных, заставит функцию MsgSend() клиента возвратить -1 и установит переменную errno на стороне клиента в значение, переданное функции MsgError() в качестве второго аргумента.
С другой стороны, функция MsgReply() может передавать данные (как видно из ее третьего и четвертого параметров) и заставляет функцию MsgSend() клиента возвратить значение, переданное MsgReply() в качестве второго аргумента. Переменная errno клиента остается нетронутой.
В общем случае, если вам нужно только сообщить о результатах действия («прошло/не прошло»), лучше применять функцию MsgError(). Если бы вы возвращали данные, здесь была бы необходима функция MsgReply(). Обычно, когда вы возвращаете данные, вторым параметром функции MsgReply() будет положительное целое число, указывающее на число возвращаемых байт.
Определение идентификаторов узла, процесса и канала (ND/PID/CHID) нужного сервера
Ранее мы отметили, что для соединения с сервером функции ConnectAttach() необходимо указать дескриптор узла (Node Descriptor — ND), идентификатор процесса (process ID — PID), а также идентификатор канала (Channel ID — CHID). До настоящего момента мы не обсуждали, как именно клиент находит эту информацию.
Если один процесс создает другой процесс, тогда это просто — вызов создания процесса возвращает идентификатор вновь созданного процесса. Создающий процесс может либо передать собственные PID и CHID вновь созданному процессу в командной строке, либо вновь созданный процесс может вызвать функцию getppid() для получения идентификатора родительского процесса, и использовать некоторый «известный» идентификатор канала.
А что если у нас два совершенно чужих процесса? Это возможно, например, в том случае, если сервер создан некоей третьей стороной, а вашему приложению нужно уметь общаться с этим сервером. Реально мы должны найти ответ на вопрос: «Как сервер объявляет о своем местонахождении?»
Существует множество способов сделать это; мы рассмотрим только три из них, в порядке возрастания «элегантности»:
1. Открыть файла с известным именем и сохранить в нем ND/PID/CHID. Такой метод является традиционным для серверов UNIX, когда сервер открывает файл (например, /etc/httpd.pid), записывает туда свой идентификатор процесса в виде строки ASCII и предполагают, что клиенты откроют этот файл прочитают из него идентификатор.
2. Использовать для объявления идентификаторов ND/PID/CHID глобальные переменные. Такой способ обычно применяется в многопоточных серверах, которые могут посылать сообщение сами себе. Этот вариант по самой своей природе является очень редким.
3. Занять часть пространства имен путей и стать администратором ресурсов. Мы поговорим об этом в главе «Администраторы ресурсов».
Первый подход относительно прост, но он чреват «загрязнением файловой системы», когда в каталоге /etc лежит куча файлов *.pid. Поскольку файлы устойчивы (имеется в виду, что они выживают после смерти создающего их процесса и перезагрузки машины), очевидного способа стереть эти файлы не существует — разве что использовать этакую программную «старуху с косой», постоянно проверяющую, не пора ли прибрать кого-то из них.
Имеется и другая связанная с этим подходом проблема. Поскольку процесс, который создал файл, может умереть, не удалив этот файл, то вы не сможете узнать, жив ли еще этот процесс, пока не попробуете передать ему сообщение. И это ещё не самое страшное — еще хуже, если комбинация ND/PID/CHID указанная в файле, оказывается настолько старой, что может быть повторно использована другой программой! Получив «чужое» сообщение, эта программа в лучшем случае его проигнорирует его, а ведь может и предпринять некорректные действия. Так что такой подход исключается.
Второй подход, где мы используем глобальные переменные для объявления значений ND/PID/CHID, не является общим решением проблемы, поскольку в нем предполагается способность клиента обратиться к этим глобальным переменным. А поскольку для этого требуется использование разделяемой памяти, это не будет работать в сети! Так что этот метод обычно используется либо в небольших тестовых программах, либо в очень специфичных случаях, но всегда в контексте многопоточной программы.
Что реально происходит, так это то, что один поток в программе является клиентом, а другой поток — сервером. Поток-сервер создает канал и затем размещает идентификатор канала в глобальной переменной (идентификаторы узла и процесса являются одинаковыми для всех потоков в процессе, так что объявлять их не обязательно). Поток-клиент затем берет этот идентификатор канала и выполняет по нему функцию ConnectAttach().
Третий подход — сделать сервер администратором ресурса — является определенно самым прозрачным и поэтому рекомендуемым общим решением. Механизм того, как это делается, изложен в главе «Администраторы ресурсов», а пока все, что вы должны об этом знать — это то, что сервер регистрирует некое имя пути как свою «область ответственности», а клиенты обращаются к нему обычным вызовом функции open().
Не сочту лишним подчеркнуть:
Файловые дескрипторы POSIX в QNX/Neutrino реализованы через идентификаторы соединений, то есть дескриптор файла уже является идентификатором соединения! Органичность этой схемы в том, что поскольку дескриптор файла, возвращаемый функцией open(), фактически является идентификатором соединения, клиенту не нужно выполнять какие-либо дополнительные действия, чтобы использовать это соединение. Например, когда клиент после вызова open() вызывает функцию read(), передавая ей полученный дескриптор, это с минимальными накладными расходами транслируется в функцию MsgSend().
А что насчет приоритетов?
А что произойдет, если сообщение серверу передадут одновременно два процесса с разными приоритетами?
Сообщения всегда доставляются в порядке приоритетов.
Если два процесса посылают сообщения «одновременно», первым доставляется сообщение от процесса с высшим приоритетом.
Если оба процесса имеют одинаковый приоритет, то сообщения будут доставлены в порядке отправки (поскольку в машине с одним процессором не бывает ничего одновременного, и даже в SMP-блоке будет присутствовать некий порядок, поскольку процессоры будут конкурировать между собой за доступ к ядру).
Мы еще вернемся к анализу других тонкостей этой проблемы чуть позже в этой главе, когда будем говорить о проблеме инверсии приоритетов.
Чтение и запись данных
До настоящего времени мы обсуждали основные примитивы обмена сообщениями. Как я и упоминал ранее, это минимум, который необходимо знать. Однако существует еще несколько дополнительных функций, которые делают нашу жизнь значительно проще.
Рассмотрим пример, в котором для обеспечения обмена сообщениями между клиентом и сервером нам понадобились бы и другие функции.
Клиент вызывает MsgSend() для передачи неких данных серверу. После вызова MsgSend() клиент блокируется. Теперь он ждет, чтобы сервер ему ответил.
Интересные события разворачиваются на стороне сервера. Сервер вызывает функцию MsgReceive() для приема сообщения от клиента. В зависимости от того, как вы спроектировали вашу систему сообщений, сервер может знать, а может и не знать, насколько велико сообщение клиента. Как сервер может не знать, каков реальный размер сообщения? Возьмем наш пример с файловой системой. Предположим, что клиент делает так:
write(fd, buf, 16);
Это сработает так, как и ожидается, если сервер вызовет MsgReceive() с размером буфера, скажем, 1024 байта. Так как наш клиент послал небольшое сообщение (28 байт), никаких проблем не будет.
А что если клиент отправит сообщение, превышающее по размеру 1024 байт — скажем, 1 мегабайт? Например, так:
write(fd, buf, 1000000);
Как сервер мог бы обработать это сообщение поизящнее? Мы могли, к примеру, сказать, что клиенту не позволяется записывать более чем n байт. Тогда функции write() в клиентской Си-библиотеке пришлось бы разбивать каждый «длинный» запрос на несколько запросов по n байт каждый. Неуклюже.
Другая проблема в этом примере заключается в вопросе «А каково должно быть n?»
Как вы видите, этот подход имеет следующие основные недостатки:
• Все функции, которые применяются для обмена сообщениями ограниченного размера, должны быть модифицированы в Си- библиотеке так, чтобы функция передавала запросы в виде серии пакетов. Это само по себе немалый объем работы. Также это может иметь ряд неожиданных побочных эффектов при работе в мнопоточной среде — что если первая часть сообщения от одного потока передана, и тут его вытесняет другой поток клиента и посылает свое собственное сообщение. Что будет с прерванным потоком тогда?
• Все серверы должны быть готовы к обработке сообщения максимально возможного размера. Это означает, что все серверы должны будут иметь значительные области данных, или Си-библиотека будет должна разделять большие запросы на несколько меньших, ухудшая тем самым быстродействие.
К счастью, эта проблема довольно просто обходится, причем даже с дополнительным выигрышем.
Здесь будут особенно полезны функции MsgRead() и MsgWrite(). Важно при этом помнить, что клиент блокирован — это означает, что он не собирается изменять данные, пока сервер их анализирует.
В многопоточном клиенте теоретически возможно, что в область данных заблокированного по серверу клиентского потока залезет другой поток. Такая ситуация рассматривается как некорректная (ошибка проектирования), поскольку серверный поток предполагает, что он имеет монопольный доступ к области данных клиента, пока тот заблокирован.
Функция MsgRead() описана так:
#include <sys/neutrino.h>
int MsgRead(int rcvid, void *msg, int nbytes, int offset);
Функция MsgRead() позволяет Вашему серверу считать nbytes байт данных из адресного пространства заблокированного клиента, начиная со смещения offset от начала клиентского буфера, в буфер, указанный параметром msg. Сервер не блокируется, а клиент не разблокируется. Функция MsgRead() возвращает число байтов, которые были фактически считаны, или возвращает -1, если произошла ошибка.
Итак, давайте подумаем, как бы мы использовали эти возможности в нашем примере с вызовом write(). Библиотечная функция write() создает сообщение с заголовком и посылает его серверу файловой системы fs-qnx4. Сервер принимает небольшую часть сообщения с помощью MsgReceive(), анализирует его и принимает решение, где разместить остальную часть сообщения — например, где-то в уже выделенном буфере дискового кэша.
Давайте рассмотрим пример.
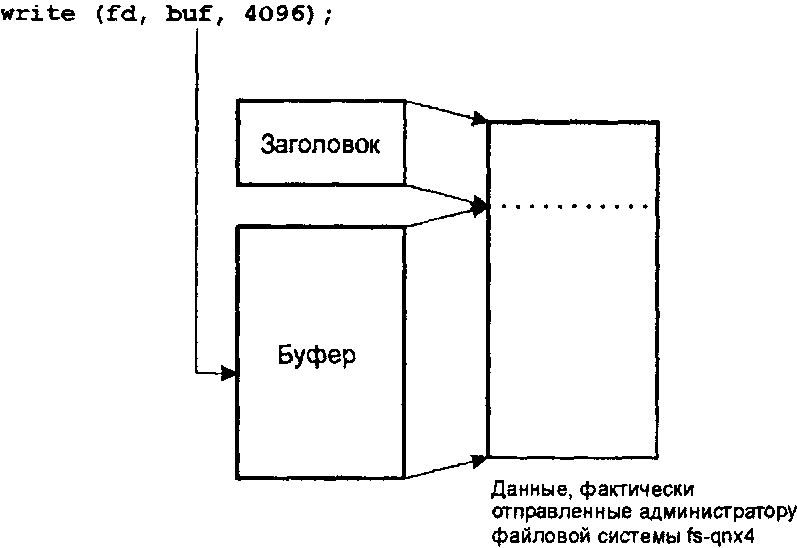
Пример отправки сообщения серверу fs-qnx4 с непрерывным представлением данных.
Итак, клиент решил переслать файловой системе 4Кб данных. (Отметьте для себя, что Си-библиотека добавила к сообщению перед данными небольшой заголовок — чтобы потом можно было узнать, к какому типу принадлежал этот запрос. Мы еще вернемся к этому вопросу, когда будем говорить о составных сообщениях, а также — еще более детально — когда будем анализировать работу администраторов ресурсов.) Файловая система считывает только те данные (заголовок), которые будут ей необходимы для того, чтобы выяснить тип принятого сообщения:
// Часть заголовков, вымышлены для примера
struct _io_write {
uint16_t type;
uint16_t combine_len;
int32_t nbytes;
uint32_t xtype;
};
typedef union {
uint16_t type;
struct _io_read io_read;
struct _io_write io_write;
...
} header_t;
header_t header; // Объявить заголовок
rcvid = MsgReceive(chid, &header, sizeof(header), NULL);
switch (header.type) {
...
case _IO_WRITE:
number_of_bytes = header.io_write.nbytes;
...
Теперь сервер fs-qnx4 знает, что в адресном пространстве клиента находится 4Кб данных (сообщение известило его об этом через элемент структуры nbytes), и что эти данные надо передать в буфер кэша. Теперь сервер fs-qnx4 может сделать так:
MsgRead(rcvid, cache_buffer[index].data,
cache_buffer[index].size, sizeof(header.io_write));
Обратите внимание, что операции приема сообщения задано смещение sizeof(header.io_write) — это сделано для того, чтобы пропустить заголовок, добавленный клиентской библиотекой. Мы предполагаем здесь, что cache_buffer[index].size (размер буфера кэша) равен 4096 (или более) байт.
Для записи данных в адресное пространство клиента есть аналогичная функция:
#include <sys/neutrino.h>
int MsgWrite(int rcvid, const void *msg, int nbytes,
int offset);
Применение функции MsgWrite() позволяет серверу записать данные в адресное пространство клиента, начиная со смещения offset байт от начала указанного клиентом приемного буфера. Эта функция наиболее полезна в случаях, где сервер ограничен в ресурсах, а клиент желает получить от него значительное количество информации.
Например, в системе сбора данных клиент может выделить 4-мегабайтный буфер и приказать драйверу собрать 4 мегабайта данных. Драйверу вовсе не обязательно держать под боком здоровенный буфер просто так, на случай если кто-то вдруг неожиданно запросит передачу большого массива данных.
Драйвер может иметь буфер размером 128Кб для обмена с аппаратурой посредством DMA, а сообщение пересылать в адресное пространство клиента по частям, используя функцию MsgWrite() (разумеется, каждый раз увеличивая смещение на 128Кб). Когда будет передан последний фрагмент, можно будет вызывать MsgReply().
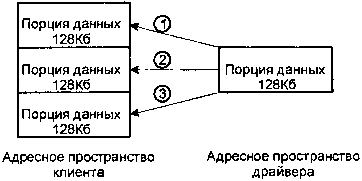
Передача нескольких фрагментов сообщения с помощью функции MsgWrite()
Отметим, что функция MsgWrite() позволяет вам записать различные компоненты данных в различные места, а затем либо просто разбудить клиента вызовом MsgReply():
MsgReply(rcvid, EOK, NULL, 0);
либо сделать это после записи заголовка в начало клиентского буфера:
MsgReply(rcvid, EOK, &header, sizeof(header));
Это довольно изящный трюк для записи неизвестного количества данных, когда вы узнаете, сколько данных нужно было записать, только когда запись уже закончена. Главное — если вы будете использовать второй метод, с записью заголовка после записи данных, не забудьте зарезервировать место под заголовок в начале клиентского буфера!
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Идентификаторы
Идентификаторы Идентификаторами называются имена, которые обозначают переменные, функции и объекты. Некоторые имена являются ключевыми или зарезервированными и не могут использоваться в качестве идентификатора, так как имеют особый смысл. О них будет рассказано
Идентификаторы и имена в IPC
Идентификаторы и имена в IPC Как было показано, отсутствие имен у каналов делает их недоступными для независимых процессов. Этот недостаток устранен у FIFO, которые имеют имена. Другие средства межпроцессного взаимодействия, являющиеся более сложными, требуют
21.5. Многоадресная передача от отправителя
21.5. Многоадресная передача от отправителя Внедрение многоадресной передачи в глобальные сети было затруднено несколькими обстоятельствами. Главная проблема заключается в том, что протокол маршрутизации MRP, описанный в разделе 21.4, должен обеспечивать доставку данных от
Уничтожение полученного маршрута от отправителя
Уничтожение полученного маршрута от отправителя К сожалению, использование параметра маршрутизации образует брешь в системе обеспечения безопасности программ, выполняющих аутентификацию по IP-адресам (сейчас такая проверка считается недостаточной). Если хакер
27.5. Параметры транзитных узлов и параметры получателя IPv6
27.5. Параметры транзитных узлов и параметры получателя IPv6 Параметры для транзитных узлов и параметры получателя IPv6 имеют одинаковый формат, показанный на рис. 27.3. Восьмиразрядное поле следующий заголовок (next header) идентифицирует следующий заголовок, который следует за
Как найти настоящего отправителя письма
Как найти настоящего отправителя письма Просмотрев заголовок письма и определив IP-адрес машины, теоретически можно узнать, кто настоящий отправитель. Сделать это можно, воспользовавшись службой Whois (http://www.whois.net) (рис. 5.5). Она позволяет по IP определить провайдера, его
18.1.4. Другие параметры ядра
18.1.4. Другие параметры ядра debugСообщения ядра (важные и не очень) передаются через функцию printk(). Если сообщение очень важно, то его копия будет передана на консоль, а также функции klogd() для его регистрации на жестком диске.Сообщения передаются на консоль, потому что иногда
20.4.5. Другие параметры ядра
20.4.5. Другие параметры ядра ? debug: сообщения ядра (важные и не очень) передаются через функцию printk(). Если сообщение очень важно, то его копия будет передана на консоль, а также функции klogd() для его регистрации на жестком диске. Сообщения передаются на консоль, потому что
Другие параметры реестра
Другие параметры реестра В конце рассказа о параметрах реестра для браузера Internet Explorer рассмотрим некоторые параметры ветви реестра HKEY_CURRENT_USERSoftwareMicrosoftWindowsCurrentVersionInternet Settings. Как уже было сказано, она содержит конфигурационные настройки браузера для текущего
R.2.3 Идентификаторы
R.2.3 Идентификаторы Идентификатор - это последовательность букв и цифр произвольной длины. Первый символ должен быть буквой, символ подчеркивания _ считается буквой. Прописные и строчные буквы различаются. Все символы
Идентификаторы
Идентификаторы Идентификаторы – это имена констант, переменных, типов, свойств, процедур, функций, программ и программных модулей. Могут быть длиной до 255 символов, начинаться с символа или знака подчеркивания; могут содержать символы, цифры и знаки подчеркивания и не
3.1.1. Идентификаторы процессов
3.1.1. Идентификаторы процессов Каждый процесс в Linux помечается уникальным идентификатором (PID, process identifier). Идентификаторы — это 16-разрядные числа, назначаемые последовательно по мере создания процессов.У всякого процесса имеется также родительский процесс (за
Идентификаторы
Идентификаторы Идентификаторы — это имена переменных, функций и меток, используемых в программе. Идентификатор вводится в объявлении переменной или функции, либо в качестве метки оператора. После этого его можно использовать в последующих операторах программы.
Идентификаторы
Идентификаторы Идентификаторы именуют переменные и функции. С каждым идентификатором ассоциируется тип, который задается при его объявлении. Значение объекта, именуемого идентификатором, зависит от типа следующим образом:1) Идентификаторы переменных целого и