Составные сообщения
Составные сообщения
До сих пор мы демонстрировали только обмен сообщениями, когда данные передаются из одного буфера в адресном пространстве клиента в другой буфер в адресном пространстве сервера (и наоборот — в случае ответа на сообщение).
При том, что данный подход вполне приемлем для большинства приложений, его применение далеко не всегда эффективно. Вспомните: наша функция write() из Си-библиотеки берет переданный ей буфер и добавляет в его начало небольшой заголовок. Используя то, что мы уже изучили ранее, вы могли бы ожидать, что реализация write() в Си-библиотеке может выглядеть примерно так (это не реальный код!):
ssize_t write(int fd, const void *buf, size_t nbytes) {
char *newbuf;
io_write_t *wptr;
int nwritten;
newbuf = malloc(nbytes + sizeof(io_write_t));
// Заполнить write_header
wptr = (io_write_t*)newbuf;
wptr->type = _IO_WRITE;
wptr->nbytes = nbytes;
// Сохранить данные от клиента
memcpy(newbuf + sizeof(io_write_t), buf, nbytes);
// Отправить сообщение серверу
nwritten =
MsgSend(fd, newbuf, nbytes + sizeof(io_write_t),
newbuf, sizeof(io_write_t));
free(newbuf);
return(nwritten);
}
Понимаете, что произошло? Несколько неприятных вещей:
• Функция write() теперь должна быть способна выделить память под буфер достаточно большого размера как для данных клиента (которые могут быть довольно значительными по объему), так и для заголовка. Размер заголовка не имеет значения — в этом случае он был равен 12 байтам.
• Мы были должны скопировать данные дважды: в первый раз — при использовании функции memcpy(), и затем еще раз, снова — уже при осуществлении передачи сообщения.
• Мы должны были предусмотреть указатель на тип io_write_t и установить его на начало буфера, вместо использования обычных механизмов доступа (впрочем, это незначительный недостаток).
Поскольку ядро намерено копировать данные в любом случае, было бы хорошо, если бы мы смогли сообщить ему о том, что одна часть данных (заголовок) фиксирована по некоторому адресу, а другая часть (собственно данные) фиксирована где- нибудь еще, без необходимости самим вручную собирать буферы из частей и копировать данные.
На наше счастье, в QNX/Neutrino реализован механизм, который позволяет нам сделать именно так! Механизм этот называется IOV (i/o vector), или «вектор ввода/вывода».
Давайте для начала рассмотрим некоторую программу, а затем обсудим, что происходит с применением такого вектора.
#include <sys/neutrino.h>
ssize_t write(int fd, const void *buf, size_t nbytes) {
io_write_t whdr;
iov_t iov[2];
// Установить IOV на обе части:
SETIOV(iov + 0, &whdr, sizeof(whdr));
SETIOV(iov + 1, buf, nbytes);
// Заполнить io_write_t
whdr.type = _IO_WRITE;
whdr.nbytes = nbytes;
// Отправить сообщение серверу
return (MsgSendv(coid, iov, 2, iov, 1));
}
Прежде всего, обратите внимание на то, что не применяется никакой функции malloc() и никакой функции memcpy(). Затем обратим внимание на тип применяемого вектора IOV — iov_t. Это структура, которая содержит два элемента — адрес и длину. Мы определили массив из двух таких структур и назвали его iov.
Определение типа вектора iov_t содержится в <sys/neutrino.h> и выглядит так:
typedef struct iovec {
void *iov_base;
size_t iov_len;
} iov_t;
Мы заполняем в этой структуре пары «адрес — длина» для заголовка операции записи (первая часть) и для данных клиента (вторая часть). Существует удобная макрокоманда, SETIOV(), которая выполняет за нас необходимые присвоения. Она формально определена следующим образом:
#include <sys/neutrino.h>
#define SETIOV(_iov, _addr, _len)
((_iov)->iov_base = (void *)(_addr),
(_iov)->iov_len = (_len))
Макрос SETIOV() принимает вектор iov_t, а также адрес и данные о длине, которые подлежат записи в вектор IOV.
Также отметим, что как только мы создаем IOV для указания на заголовок, мы сможем выделить стек для заголовка без использования malloc(). Это может быть и хорошо, и плохо — это хорошо, когда заголовок невелик, потому что вы хотите исключить головные боли, связанные с динамическим распределением памяти, но это может быть плохо, когда заголовок очень велик, потому что тогда он займет слишком много стекового пространства. Впрочем, заголовки обычно невелики.
В любом случае, вся важная работа выполняется функцией MsgSendv(), которая принимает почти те же самые аргументы, что и функция MsgSend(), которую мы использовали в предыдущем примере:
#include <sys/neutrino.h>
int MsgSendv(int coid, const iov_t *siov, int sparts,
const iov_t *riov, int rparts);
Давайте посмотрим на ее аргументы:
coid Идентификатор соединения, по которому мы передаем — как и при использовании функции MsgSend(). sparts и rparts Число пересылаемых и принимаемых частей, указанных параметрами вектора iov_t; в нашем примере мы присваиваем аргументу sparts значение 2, указывая этим, что пересылаем сообщение из двух частей, а аргументу rparts — значение 1, указывая этим, что мы принимаем ответ из одной части. siov и riov Эти массивы значений типа iov_t указывают на пары «адрес — длина», которые мы желаем переслать. В вышеупомянутом примере мы выделяем siov из двух частей, указывая ими на заголовок и данные клиента, и riov из одной части, указывая им только на заголовок.
Как ядро видит составное сообщение.
Ядро просто прозрачно копирует данные из каждой части вектора IOV из адресного пространства клиента в адресное пространство сервера (и обратно, при ответе на сообщение). Фактически, при этом ядро выполняет операцию фрагментации/дефрагментации сообщения (scatter/gather).
Несколько моментов, которые необходимо запомнить:
• Число фрагментов ограничено значением 231 (больше, чем вам придется использовать!); число 2 в нашем примере — типовое значение.
• Ядро просто копирует данные, указанные вектором IOV, из одного адресного пространства в другое.
• Вектор-источник и вектор-приемник не должны совпадать.
Почему последний пункт так важен? Для того чтобы ответить, рассмотрим все подробнее. Со стороны клиента, скажем, мы выдали:
write(fd, buf, 12000);
в результате чего был создан вектор IOV из двух частей:
• заголовок (12 байт);
• данные (12000 байт);
На стороне сервера (скажем, сервера файловой системы fs-qnx4) мы имеем блоки памяти кэша до 4Кб каждый, и мы хотели бы эффективно принять сообщение непосредственно в эти блоки. В идеале мы бы написали что-то типа:
// Настроить структуру IOV для приема:
SETIOV(iov + 0, &header, sizeof(header.io_write));
SETIOV(iov + 1, &cache_buffer[37], 4096);
SETIOV(iov + 2, &cache_buffer[16], 4096);
SETIOV(iov + 3, &cache_buffer[22], 4096);
rcvid = MsgReceivev(chid, iov, 4, NULL);
Эта программа делает в значительной степени то, что вы и предполагаете: она задает вектор IOV из 4 частей, первая из которых указывает на заголовок, а следующие три части — на блоки кэш-памяти с номерами 37, 16 и 22. (Предположим, что именно эти блоки случайно оказались доступными в данный момент.) Ниже это иллюстрируется графически.
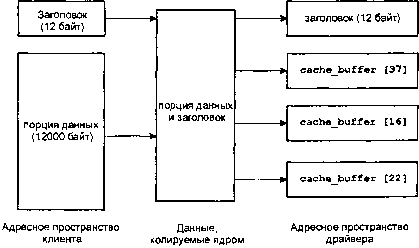
Распределение непрерывных данных по отдельным буферам.
Затем осуществляется вызов функции MsgReceivev(), и ей указывается, что мы намерены принять сообщение по указанному каналу (параметр chid), и что вектор IOV для этой операции состоит из 4 частей.
(Кроме возможности работать с векторами IOV, функция MsgReceivev() действует аналогично функции MsgReceive().)
Опа! Мы сделали ту же самую ошибку, которую уже делали к раньше, когда знакомились с функцией MsgReceive(). Как мы узнаем, сообщение какого типа мы собираемся принять и сколько в нем данных, пока не примем все сообщение целиком?
Мы сможем решить эту проблему тем же способом, что и прежде:
rcvid = MsgReceive(chid, &header, sizeof(header), NULL);
switch (header.message_type) {
...
case _IO_WRITE:
number_of_bytes = header.io_write.nbytes;
// Выделить / найти элемент кэша
// Заполнить элементами кэша 3-элементный IOV
MsgReadv(rcvid, iov, 3, sizeof(header.io_write));
Здесь мы вызываем «предварительную» MsgReceive() (отметьте, что тут мы не используем ее векторную форму, поскольку для сообщения, состоящего из одной части, в ней просто нет необходимости), определяем тип сообщения и затем продолжаем считывать данные из адресного пространства клиента (начиная со смещения sizeof(header.io_write)) в кэш-буферы, определенные трехэлементным вектором IOV.
Обратите внимание, что мы перешли от вектора IOV, состоящего из 4 частей (как в первом примере), к вектору IOV из 3 частей. Дело в том, что в первом примере первый из четырех элементов вектора IOV отводился под заголовок, который на этот раз мы считали непосредственно при помощи функции MsgReceive(), а последние три элемента аналогичны трехэлементному вектору из второго примера — они определяют место, куда мы хотим записать данные.
Можно представить, как мы ответили бы на запрос чтения:
1. Найти элементы кэша, которые соответствуют запрашиваемым данным.
2. Заполнить вектора IOV ссылками на них.
3. Применить функцию MsgWritev() (или MsgReplyv()) для передачи данных клиенту.
Отметим, что если данные начинаются не непосредственно с начала блока кэша (или другой структуры данных), то в этом нет никакой проблемы. Просто сместите первый вектор IOV на точку начала данных и соответственно откорректируйте поле размера.
Как насчет других версий?
Все функции обмена сообщениями, кроме функций семейства MsgSend*(), имеют одинаковую общую форму: если имя функции имеет суффикс «v», значит, она принимает в качестве аргументов вектор IOV и число его частей; в противном случае, она принимает указатель и длину.
Семейство MsgSend*() содержит четыре основных варианта реализации функций с точки зрения буферов источника и адресата, плюс два варианта собственно системного вызова — итого восемь.
В нижеприведенной таблице сведены данные о вариантах функций семейства MsgSend*().
Функция Буфер передачи Буфер приема MsgSend() линейный линейный MsgSendnc() линейный линейный MsgSendsv() линейный IOV MsgSendsvnc() линейный IOV MsgSendvs() IOV линейный MsgSendvsnc() IOV линейный MsgSendv() IOV IOV MsgSendvnc() IOV IOVПод линейным буфером я подразумеваю, что передается единый буфер типа void* вместе с его длиной. Это легко запомнить: суффикс «v» означает «вектор», и он находится на том же самом месте, что и соответствующий параметр — первым или вторым, в зависимости от того, какой буфер — передачи или приема — объявляется векторным.
Хмм. Получается, что функции MsgSendsv() и MsgSendsvnc() идентичны? Да, по части параметров именно так оно и есть. Различие заключается в том, является функция точкой завершения (cancellation point) или нет. Версии с суффиксом «nc» («no cancellation» — прим. ред.) не являются точками завершения, в то время как версии без этого суффикса — являются. (Дополнительную информацию относительно точек завершения и завершаемости (cancelability) вообще можно найти в справочном руководстве по Си-библиотеке в главе, посвященной pthread_cancel().)
Реализация
Вероятно, вы уже подозревали, что все варианты функций MsgRead(), MsgReceive(), MsgSend() и функций MsgWrite() тесно связаны между собой. (Единственное исключение — функция MsgReceivePulse(); мы ее вкратце рассмотрим.)
Которые из этих функций следует применять? В общем-то вопрос этот является чисто философским. Что до меня лично, то я предпочитаю комбинировать.
Если мы посылаем или принимаем только одноэлементные сообщения, то зачем нам все эти проблемы с настройкой векторов IOV?
Накладные расходы (кстати, незначительные) по загрузке процессора обычно не зависят от того, настраиваете ли вы все сами или оставляете это ядру или библиотеке. Подход с использованием одноэлементных сообщений избавляет ядро от необходимости манипуляций с адресным пространством и поэтому работает несколько быстрее.
Следует ли вам применять функции, использующие IOV? Конечно! Используйте их всегда, когда вам приходится самостоятельно программировать обмен многоэлементными сообщениями. Никогда непосредственно не копируйте данные при передаче многоэлементных сообщений, даже если для этого потребуется всего несколько строк программы. Это перегрузит систему попытками минимизировать число реальных операций копирования данных туда-сюда; передача указателей происходит намного быстрее, чем копирование данных из буфера в буфер.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
21.3.4. Составные управляющие последовательности
21.3.4. Составные управляющие последовательности Пять двухсимвольных управляющих последовательностей (которые показаны в табл. 21.3) фактически являются префиксами более длинных и сложных последовательностей. Рассмотрим каждую из них по очереди.Таблица 21.3. Составные
Составные объекты
Составные объекты Используя вкладку Create (Создание) командной панели можно объединять два и более объектов для создания нового параметрического объекта Compound Object (Составной объект). Параметры объектов, содержащихся в составном объекте, также можно модифицировать и
Составные карты текстур
Составные карты текстур Составные карты текстур предназначены для объединения нескольких текстур в одну новую сложную текстуру. К таким картам относятся Composite (Составная), Mask (Маска), Mix (Смешивание) и RGB Multiply (RGB-умножение).Рассмотрим некоторые типы составных карт.Composite
2.2. Составные части объектного подхода
2.2. Составные части объектного подхода Парадигмы программирования Дженкинс и Глазго считают, что "в большинстве своем программисты используют в работе один язык программирования и следуют одному стилю. Они программируют в парадигме, навязанной используемым ими языком.
Составные объекты
Составные объекты Составные объекты (Compound objects) – это объекты, которые являются результатом взаимодействия двух или более тел. Используя составные объекты, можно деформировать, разрезать, соединять, удалять и выдавливать поверхности, создавать упорядоченные или
Составные операторы (блоки)
Составные операторы (блоки) "Составной оператор" представляет собой два или более операторов, объединенных с помощью фигурных скобок; он называется также "блоком". В нашей программе размер обуви 2 мы использовали такой оператор, чтобы иметь возможность включить в
5.1. Простые и составные инструкции
5.1. Простые и составные инструкции Простейшей формой является пустая инструкция. Вот как она выглядит:; // пустая инструкцияПустая инструкция используется там, где синтаксис С++ требует употребления инструкции, а логика программы – нет. Например, в следующем цикле while,
Три источника и три составные части народного творчества Василий Щепетнёв
Три источника и три составные части народного творчества Василий Щепетнёв Опубликовано 07 января 2014 Игровые шахматные программы постепенно становятся «вещью в себе». Желающих играть с программами, отдаваясь приятному времяпрепровождению,
Составные объекты и развернутые типы
Составные объекты и развернутые типы Обсуждение структуры объектов времени выполнения показало важную роль ссылок. Для завершения картины необходимо выяснить, как работать со значениями, представляющими собой не ссылки на объекты, а непосредственно сами объекты.
Составные фигуры
Составные фигуры Следующий пример больше чем пример, - он послужит нам образцом проектирования классов в самых различных ситуациях.Рассмотрим структуру, введенную в предыдущей лекции для изучения наследования и содержащую классы графических фигур: FIGURE, OPEN_FIGURE, POLYGON,
Посмотрите на составные часы, складывающие время из сотен других часов Николай Маслухин
Посмотрите на составные часы, складывающие время из сотен других часов Николай Маслухин Опубликовано 15 марта 2013 В эти дни в столице Объединённых Арабских Эмиратов проходит выставка Design Days Dubai 2013, в рамках которой представлена интересная