Запуск потока
Запуск потока
Теперь, когда мы знаем, как запустить другой процесс, давайте рассмотрим, как осуществить запуск другого потока.
Любой поток может создать другой поток в том же самом процессе; на это не налагается никаких ограничений (за исключением объема памяти, конечно!) Наиболее общий путь реализации этого — использование вызова функций POSIX pthread_create():
#include <pthread.h>
int pthread_create(pthread_t *thread,
const pthread_attr_t *attr,
void*(*start_routine)(void*), void *arg);
Функция pthread_create() имеет четыре аргумента :
thread указатель на pthread_t, где хранится идентификатор потока attr атрибутная запись start_routine подпрограмма, с которой начинается поток arg параметр, который передается подпрограмме start_routineОтметим, что указатель thread и атрибутная запись (attr) — необязательные элементы, вы может передавать вместо них NULL.
Параметр thread может использоваться для хранения идентификатора вновь создаваемого потока. Обратите внимание, что в примерах, приведенных ниже, мы передадим NULL, обозначив этим, что мы не заботимся о том, какой идентификатор будет иметь вновь создаваемый поток.
Если бы нам было до этого дело, мы бы сделали так:
pthread_t tid;
pthread_create(&tid, ...
printf("Новый поток имеет идентификатор %d ", tid);
Такое применение совершенно типично, потому что вам часто может потребоваться знать, какой поток выполняет какой участок кода.
 Небольшой тонкий момент. Новый поток может начать работать еще до присвоения значения параметру tid. Это означает, что вы должны внимательно относиться к использованию tid в качестве глобальной переменной. В примере, приведенном выше, все будет корректно, потому что вызов pthread_create() отработал до использования tid, что означает, что на момент использования tid имел корректное значение.
Небольшой тонкий момент. Новый поток может начать работать еще до присвоения значения параметру tid. Это означает, что вы должны внимательно относиться к использованию tid в качестве глобальной переменной. В примере, приведенном выше, все будет корректно, потому что вызов pthread_create() отработал до использования tid, что означает, что на момент использования tid имел корректное значение.
Новый поток начинает выполнение с функции start_routine(), с параметром arg.
Атрибутная запись потока
Когда вы осуществляете запуск нового потока, он может следовать ряду четко определенных установок по умолчанию, или же вы можете явно задать его характеристики.
Прежде, чем мы перейдем к обсуждению задания атрибутов потока, рассмотрим тип данных pthread_attr_t:
typedef struct {
int flags;
size_t stacksize;
void *stackaddr;
void (*exitfunc)(void *status);
int policy;
struct sched_param param;
unsigned guardsize;
} pthread_attr_t;
В основном эти поля используются как:
flags Неисчисляемые (булевы) характеристики потока — например, создается поток как «обособленный» или «синхронизирующий». stacksize, stackaddr и guardsize Параметры стека. exitfunc Функция, выполняемая перед завершением потока. policy и param Параметры диспетчеризации.Доступны следующие функции:
Управление атрибутами
pthread_attr_destroy()
pthread_attr_init()
Флаги (булевы характеристики)
pthread_attr_getdetachstate()
pthread_attr_setdetachstate()
pthread_attr_getinheritsched()
pthread_attr_setinheritsched()
pthread_attr_getscope()
pthread_attr_setscope()
Параметры стека
pthread_attr_getguardsize()
pthread_attr_setguardsize()
pthread_attr_getstackaddr()
pthread_attr_setstackaddr()
pthread_attr_getstacksize()
pthread_attr_setstacksize()
Параметры диспетчеризации
pthread_attr_getschedparam()
pthread_attr_setschedparam()
pthread_attr_getschedpolicy()
pthread_attr_setschedpolicy()
Список выглядит довольно большим (18 функций), но в действительности нас будет заботить применение только примерно половины функций из этого списка, потому что все эти они сгруппированы по парам «get» — «set», т.е. в каждой паре есть функция как получения параметров (get), так и их установки (set) — за исключением функций pthread_attr_init() и pthread_attr_destroy().
Прежде чем мы исследуем назначения атрибутов, следует отметить одно обстоятельство. Вы обязаны вызвать pthread_attr_init() для инициализации атрибутной записи до момента ее использования, задействовать ее с помощью соответствующей функции (функций) pthread_attr_set*() и только затем вызвать функцию pthread_create() для создания потока. Изменение атрибутной записи после того, как поток уже создан, не будет иметь никакого действия.
Администрирование атрибутов потока
Перед использованием атрибутной записи для ее инициализации следует вызвать функцию pthread_attr_init():
...
pthread_attr_t attr;
...
pthread_attr_init(&attr);
Вы можете также вызывать pthread_attr_destroy() для «деинициализации» атрибутной записи потока, но так обычно никто не делает (если не требуется жесткой POSIX-совместимости).
В приведенных ниже описаниях значения по умолчанию помечены комментарием «(по умолчанию)».
Атрибут потока «flags» (флаги)
Три функции — pthread_attr_setdetachstate(), pthread_attr_setinheritsched() и pthread_attr_setscope() — определяют, создается ли поток как «синхронизирующий» («joinable») или как «обособленный» (detached), наследует ли поток атрибуты диспетчеризации от создающего потока или использует атрибуты диспетчеризации, указанные в функциях pthread_attr_setschedparam() и pthread_attr_setschedpolicy(), и, наконец, имеет ли поток масштаб «системы» или «процесса».
Для создания «синхронизирующего» потока (это значит, что с завершением этого потока можно синхронизировать другой поток при помощи функции pthread_join()), используется вызов:
(по умолчанию)
pthread_attr_setdetachstate(&attr,
PTHREAD_CREATE_JOINABLE);
Чтобы создать поток, синхронизация с завершением которого невозможна (такой поток называют «обособленным»), надо было бы сделать так:
pthread_attr_setdetachstate(&attr,
PTHREAD_CREATE_DETACHED);
Если вы желаете, чтобы поток унаследовал атрибуты диспетчеризации от потока, его создающего (то есть имел бы ту же самую дисциплину диспетчеризации и тот же самый приоритет, что и родитель), вам следует сделать так:
(по умолчанию)
pthread_attr_setinheritsched(&attr, PTHREAD_INHERIT_SCHED);
Для создания потока, который использует атрибуты диспетчеризации, указанные в непосредственно в атрибутной записи (это делается при помощи функций pthread_attr_setsetschedparam() и pthread_attr_setschedpolicy()), вызов выглядел бы следующим образом:
pthread_attr_setinheritsched(&attr,
PTHREAD_EXPLICIT_SCHED);
И наконец, функция pthread_attr_setscope(). Вам не придется ее вызывать никогда. Почему? Потому что QNX/Neutrino поддерживает для потоков только масштаб системы, и соответствующее значение устанавливается по умолчанию, когда вы инициализируете атрибут. (Масштаб системы означает, что за обладание ресурсами все потоки в системе конкурируют друг с другом; масштаб процесса же означает, что потоки конкурируют за процессор только в пределах «своего» процесса, а диспетчеризацию процессов выполняет ядро).
Если вам необходимо вызвать эту функцию, вы можете сделать это только следующим образом:
(по умолчанию)
pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
Атрибуты потока «stack» (параметры стека)
Прототипы функций установки параметров стека в атрибутах потока выглядят следующим образом:
int pthread_attr_setguardsize(pthread_attr_t *attr,
size_t gsize);
int pthread_attr_setstackaddr(pthread_attr_t *attr,
void *addr);
int pthread_attr_setstacksize(pthread_attr_t *attr,
size_t ssize);
Все эти три функции имеют в качестве первого параметра атрибутную запись, вторые параметры перечислены ниже:
gsize Размер «области защиты». addr Адрес стека, если последний вами предусмотрен. ssize Размер стека.Область защиты — это область памяти, расположенная сразу после стека, которую поток не может использовать для записи. Если это происходит (а это означает, что стек вот-вот переполнится), потоку будет послан SIGSEGV. Если размер области защиты равен 0, это означает, что области защиты не предусматривается. Это также подразумевает, что проверка стека на переполнение выполняться не будет. Если размер области защиты отличен от нуля, то это устанавливает его по меньшей мере в общесистемное значение по умолчанию (которое вы можете получить по запросу sysconf(), указав ему константу _SC_PAGESIZE). Заметьте, что ненулевой минимально возможный размер области защиты составляет одну страницу (например, 4 Кб для процессора x86). Также отметьте, что страница защиты не занимает никакой физической памяти, это уловка с применением виртуальной адресации (MMU). Параметр addr представляет собой адрес стека, если вы его задаете явно. Вы можете задать вместо него NULL, что будет значить, что система будет должна сама распределить (и освободить!) стек для потока. Преимущество явного определения стека для потока состоит в том, что вы сможете делать «посмертный» (после аварийного завершения) анализ глубины стека. Это достигается распределением области стека и заполнением ее некоторой «подписью» (например, многократно повторяемой строкой «STACK»), после чего поток запускается на выполнение. По завершении работы потока вы сможете проанализировать область стека и посмотреть, на какую глубину поток затер в ней вашу «подпись», и тем самым определить максимальную глубину стека, использованную потоком в данном конкретном сеансе выполнения.
Параметр ssize определяет размер стека. Если вы явно задаете адрес области стека в параметре addr, то параметр ssize должен задавать размер этой области. Если вы не задаете адрес области стека в параметре addr (то есть передаете вместо адреса NULL), то параметр ssize сообщает системе, стек какого размера следует распределить. Если вы укажете для параметра ssize значение 0 (ноль), система выберет размер стека, заданный по умолчанию. Очевидно, что задавать 0 в качестве параметра ssize и при этом явно указывать адрес стека, используя параметр addr — порочная практика, поскольку в действительности вы тем самым заявляете: «вот указатель на объект, который имеет некоторый заданный по умолчанию размер». Проблема здесь заключается в том, что между размером объекта и передаваемым значением нет никакой связи.
Если стек назначается с помощью параметра attr, данный поток не будет защищен от переполнения этого стека (то есть область защиты будет отсутствовать).
Атрибуты потока «scheduling» (диспетчеризация)
Наконец, если вы определяете PTHREAD_EXPLICIT_SCHED для функции pthread_attr_setinheritsched(), тогда вам необходимо будет как-то определить дисциплину диспетчеризации и приоритет для потока, который вы намерены создать.
Это выполняется с помощью двух функций:
int pthread_attr_setschedparam(pthread_attr_t *attr,
const struct sched_param *param);
int pthread_attr_setschedpolicy(pthread_attr_t *attr,
int policy);
С параметром policy все просто — это либо SCHED_FIFO, либо SCHED_RR, либо SCHED_OTHER.
В рассматриваемой версии QNX/Neutrino параметр SCHED_OTHER интерпретируется как SCHED_RR (карусельная диспетчеризация).
Параметр param — структура, которая содержит единственный элемент: sched_priority. Задайте этот параметр путем прямого присвоения ему значения желаемого приоритета.
Стандартная ошибка, которой следует избегать, заключается в задании PTHREAD_EXPLICIT_SCHED и затем определением только дисциплины диспетчеризации. Проблема состоит в том, что в инициализированной атрибутной записи значение param.sched_priority есть 0 (ноль). Это тот же самый приоритет, что и у «холостого» потока (IDLE), что означает, что создаваемый вами поток будет конкурировать за процессор с «холостым» потоком.
Плавали, знаем. :-)
На том, что QSSL зарезервировала нулевой приоритет только для «холостого» потока, уже «прокололось» немало программистов. Поток с нулевым приоритетом просто не сможет выполняться.
Несколько примеров
Давайте рассмотрим ряд примеров. Будем считать, что в обсуждаемой программе подключены нужные заголовочные файлы (<pthread.h> и <sched.h>), а также что поток, который предстоит создать, называется new_thread(), и для него существуют все необходимые прототипы и определения.
Самый обычный способ создания потока — просто оставить везде значения по умолчанию:
pthread_create(NULL, NULL, new_thread, NULL);
В вышеупомянутом примере мы создали наш новый поток со значениями параметров по умолчанию и передали ему NULL в качестве его единственного параметра (третий NULL в указанном выше вызове pthread_create()).
Вообще говоря, вы можете передавать вашему новому потоку что угодно через параметр arg. Например, число 123:
pthread_create(NULL, NULL, new_thread, (void*)123);
Более сложный пример — создание «обособленного» (detached) потока с диспетчеризацией карусельного типа (RR) и приоритетом 15:
pthread_attr_t attr;
// Инициализировать атрибутную запись
pthread_attr_init(&attr);
// Установить «обособленность»
pthread_attr_setdetachstate(&attr,
PTHREAD_CREATE_DETACHED);
// Отменить наследование по умолчанию (INHERIT_SCHED)
pthread_attr_setinheritsched(&attr,
PTHREAD_EXPLICIT_SCHED);
pthread_attr_setschedpolicy(&attr, SCHED_RR);
attr.param.sched_priority = 15;
// И, наконец, создать поток
pthread_create(NULL, &attr, new_thread, NULL);
Для того чтобы увидеть, как «выглядит» многопоточная программа, можно запустить из командного интерпретатора команду pidin. Скажем, нашу программу зовут spud. Если мы выполняем pidin один раз до создания программой spud потоков, и еще раз — после того, как spud создала два потока (тогда всего их будет три), то вот как примерно будет выглядеть вывод (я укоротил вывод pidin для демонстрации только того, что относится к spud):
# pidin
pid tid name prio STATE Blocked
12301 1 spud 10r READY
# pidin
pid tid name prio STATE Blocked
12301 1 spud 10r READY
12301 2 spud 10r READY
12301 3 spud 10r READY
Вы можете видеть, что процесс spud (идентификатор процесса 12301) имеет три потока (столбец «tid» в таблице). Эти три поток» выполняются с приоритетом 10, с диспетчеризацией карусельного (RR) типа (обозначенной как «r» после цифры 10). Все три процесса находятся в состоянии готовности (READY), т. е. готовы использовать процессор, но в настоящее время не выполняются (поскольку в данный момент выполняется другой поток с более высоким приоритетом).
Теперь, когда мы знаем все о создании потоков, давайте рассмотрим, как и где мы можем этим воспользоваться.
Где хороша многопоточность
Существует два класса задач, где можно было бы эффективно применять многопоточность.
Потоки подобны перегруженным операторам в языке Си++. Поначалу может показаться хорошей идеей перегрузить каждый оператор какой-либо дополнительной интересной функцией, но это сделает программу трудной для восприятия. Аналогичная ситуация с потоками. Вы могли бы создать множество потоков, но это усложнит ваш код и сделает программу малопонятной, а значит, сложной в сопровождении. Разумное же применение потоков, наоборот, внесет в программу дополнительную функциональную ясность.
Применение потоков хорошо там, где можно выполнять операции параллельно — например, в ряде математических задач (графика, цифровая обработка сигналов, и т.д.). Потоки также прекрасны там, где программа должна выполнять несколько независимых функций, при этом использующих общие данные — например, веб-сервер, который обслуживает несколько клиентов одновременно. Эти два класса задач мы здесь и рассмотрим.
Потоки в математических операциях
Предположим, что мы имеем графическую программу, выполняющую алгоритм трассировки луча. Каждая строка растра на экране зависит от содержимого основной базы данных (которая описывает генерируемую картинку). Ключевым моментом здесь является то, что каждая строка растра не зависит от остальных. Это обстоятельство (независимость строк растра) автоматически приводит к программированию данной задачи как многопоточной.
Ниже приведен однопоточный вариант:
int main (int argc, char **argv) {
int x1;
... // Выполнить инициализации
for (x1 = 0; x1 < num_x_lines; x1++) {
do_one_line(x1);
}
... // Вывести результат
}
Здесь мы видим, что программа итеративно по всем значениям рассчитает необходимые растровые строки.
В многопроцессорных системах эта программа будет использовать только один из процессоров. Почему? Потому что мы не указали операционной системе выполнять что-либо параллельно. Операционная система не настолько умна, чтобы посмотреть на программу и сказать: «Эй, секундочку! У нас ее 4 процессора, и похоже, что у нас тут несколько независимых потоков управления. Запущу-ка я это на всех 4 процессорах сразу!»
Так что это дело разработчика (ваше дело!) — сообщить QNX/Neutrino, какие разделы программы следует выполнять параллельно. Проще всего это можно было бы сделать так:
int main (int argc, char **argv) {
int x1;
... // Выполнить инициализации
for (x1 = 0; x1 < num_x_lines; x1++) {
pthread_create(NULL, NULL, do_one_line, (void*)x1);
}
... // Вывести результат
}
С таким упрощением связано множество проблем. Первая из них (и самая незначительная) состоит в том, что функцию do_one_line() придется модифицировать так, чтобы она могла в качестве своего аргумента принимать значение типа void* вместо int. Это можно легко исправить с помощью оператора приведения типа (typecast).
Вторая проблема несколько сложнее. Скажем, что разрешающая способность дисплея, для которой вы рассчитывали картинку, была равна 1280?1024. Нам пришлось бы создать 1280 потоков! В общем-то, для QNX/Neutrino это не проблема — QNX/Neutrino позволяет создавать до 32767 потоков в одном процессе! Однако, каждый поток должен иметь свой уникальный стек. Если ваш стек имеет разумный размер (скажем 8 Кб), эта программа израсходует под стек 1280?8 Кб (10 мегабайт!) ОЗУ. И ради чего? В вашей системе есть только 4 процессора. Это означает, что только 4 из этих 1280 потоков будут работать одновременно, а другие 1276 потоков будут ожидать доступа к процессору. (В действительности, в данном случае пространство под стек будет выделяться только по мере необходимости. Но тем не менее, это все равно расходование ресурсов впустую — есть ведь еще и другие издержки.)
Более красивым способом решения этой задачи было бы разбить ее на 4 части (по одной подзадаче на каждый процессор), и обрабатывать каждую часть как отдельный поток:
int num_lines_per_cpu;
int num_cpus;
int main (int argc, char **argv) {
int cpu;
... // Выполнить инициализации
// Получить число процессоров
num_cpus = _syspage_ptr->num_cpu;
num_lines_per_cpu = num_x_lines / num_cpus;
for (cpu = 0; cpu < num_cpus; cpu++) {
pthread_create(NULL, NULL, do_one_batch, (void*)cpu);
}
... // Вывести результат
}
void* do_one_batch(void *c) {
int cpu = (int)c;
int x1;
for (x1 = 0; x1 < num_lines_per_cpu; x1++) {
do_line_line(x1 + cpu * num_lines_per_cpu);
}
}
Здесь мы запускаем только num_cpus потоков. Каждый поток будет выполняться на отдельном процессоре. А поскольку мы имеем дело с небольшим числом потоков, мы тем самым не засоряем память ненужными стеками. Обратите внимание, что мы получили число процессоров путем разыменования глобальной переменной — указателя на системную страницу _syspage_ptr. (Дополнительную информацию относительно системной страницы можно найти в книге «Building Embedded Systems» (поставляется в комплекте документации по QNX/ Neutrino — прим. ред.) или в заголовочном файле <sys/syspage.h>).
Программирование для одного или нескольких процессоров
Последняя программа в первую очередь интересна тем, что будет корректно функционировать в системе с одиночным процессором тоже. Просто будет создан только один поток, который и выполнит всю работу. Дополнительные издержки (один стек) с лихвой окупаются гибкостью программы, умеющей работать быстрее в многопроцессорной системе.
Синхронизация по отношению к моменту завершения потока
Я уже упоминал, что с приведенным выше упрощенным примером программы связана масса проблем. Так вот, еще одна связанная с ним проблема состоит в том, что функция main() сначала запускает целый букет потоков, а затем отображает результаты. Но как функция узнает, когда уже можно выводить результаты?
Заставлять main() заниматься опросом, закончены ли вычисления, противоречит самому замыслу ОС реального времени.
int main (int argc, char **argv) {
...
// Запустить потоки, как раньше
while (num_lines_completed < num_x_lines) {
sleep(1);
}
}
He вздумайте писать такие программы!
Для решения этой задачи существуют два изящных решения: применение функций pthread_join() и barrier_wait().
«Присоединение» (joining)
Самый простой метод синхронизации — это «присоединение» потоков. Реально это действие означает ожидание завершения.
Присоединение выполняется одним потоком, ждущим завершения другого потока. Ждущий поток вызывает pthread_join():
#include <pthread.h>
int pthread_join(pthread_t thread, void **value_ptr);
Функции pthread_join() передается идентификатор потока, к которому вы желаете присоединиться, а также необязательный аргумент value_ptr, который может быть использован для сохранения возвращаемого присоединяемым потоком значения (Вы можете передать вместо этого параметра NULL, если это значение для вас не представляет интереса — в данном примере мы так и сделаем).
Где нам брать идентификатор потока? Мы игнорировали его в функции pthread_create(), передав NULL в качестве первого параметра. Давайте исправим нашу программу:
int num_lines_per_cpu;
int num_cpus;
int main(int argc, char **argv) {
int cpu;
pthread_t *thread_ids;
... // Выполнить инициализации
thread_ids = malloc(sizeof(pthread_t) * num_cpus);
num_lines_per_cpu = num_x_lines / num_cpus;
for (cpu = 0; cpu < num_cpus; cpu++) {
pthread_create(
&thread_ids[cpu], NULL, do_one_batch, (void*)cpu);
}
// Синхронизироваться с завершением всех потоков
for (cpu = 0; cpu < num_cpus; cpu++) {
pthread_join(thread_ids[cpu], NULL);
}
... // Вывести результат
}
Обратите внимание, что на этот раз мы передали функции pthread_create() в качестве первого аргумента указатель на pthread_t. Там и будет сохранен идентификатор вновь созданного потока. После того как первый цикл for завершится, у нас будет num_cpu работающих потоков, плюс поток, выполняющий main(). Потребление ресурсов процессора потоком main() нас мало интересует — этот поток потратит все свое время на ожидание.
Ожидание достигается применением функции pthread_join() к каждому из наших потоков. Сначала мы ждем завершения потока thread_ids[0]. Когда он завершится, функция pthread_join() разблокируется. Следующая итерация цикла for заставит нас ждать завершения потока thread_ids[1], и так далее для всех num_cpus потоков.
В этот момент возникает законный вопрос: «А что если потоки завершат работу в обратном порядке?» Другими словами, если имеются 4 процессора, и по какой-либо причине поток, выполняющийся на последнем процессоре (с номером 3), завершит работу первым, затем завершится поток, выполняющийся на процессоре с номером 2, и так далее? Вся прелесть приведенной схемы заключается в том, что ничего плохого не произойдет.
Первое, что произойдет — это то, что pthread_join() блокируется на thread_ids[0]. Тем временем пусть завершится поток thread_ids[3]. Это не окажет абсолютно никакого воздействия на поток main(), который будет по-прежнему ждать завершения первого потока. Затем, пусть завершит работу поток thread_ids[2]. По-прежнему, никаких последствий. И так далее — пока не завершит работу поток thread_ids[0].
В этот момент pthread_join() разблокируется, и мы немедленно переходим к следующей итерации цикла for. Вторая итерация цикла for применит pthread_join() к потоку thread_ids[1], который не будет блокирован, и итерация завершится немедленно. Почему? Потому что поток, идентифицированный как thread_ids[1], уже завершился. Поэтому наш цикл for просто «проскочит» остальные потоки и завершится. В этот момент мы будем знать, что вычислительные потоки синхронизированы, и теперь мы можем выводить результаты отображение.
Применение барьера
Когда мы говорили о синхронизации функции main() по моменту завершения рабочих потоков (в параграфе «Синхронизация по отношению к моменту завершения потока», см. выше), мы упомянули два метода синхронизации: один метод с применением функции pthread_join(), который мы только что рассмотрели, и метод с применением барьера.
Возвращаясь к нашей аналогии с процессами в жилом доме, предположим, что семья пожелала где-нибудь отдохнуть на природе. Водитель садится в микроавтобус и запускает двигатель. И ждет. Водитель будет ждать до тех пор, пока все члены семьи не сядут в машину, и только затем можно будет ехать — не можем же мы кого-нибудь оставить!
Точно так происходит и в нашем примере с выводом графики на дисплей. Основной поток должен дождаться того момента, когда все рабочие потоки завершат работу, и только затем можно начинать следующую часть программы.
Однако, отметьте для себя одну важную отличительную особенность. С применением функции pthread_join() мы ожидаем завершения потоков. Это означает, что на момент ее разблокирования потоков нет больше с нами; они закончили работу и завершились.
В случае с барьером, мы ждем «встречи» определенного числа потоков у барьера. Затем, когда заданное число потоков достигнуто, мы их всех разблокируем (заметьте, что потоки при этом продолжат выполнять свою работу).
Сначала барьер следует создать при помощи функции barrier_init():
#include <sync.h>
int barrier_init(barrier_t *barrier, const barrier_attr_t *attr, int count);
Эта функция создает объект типа «барьер» по переданному ей адресу (указатель на барьер хранится в параметре barrier) и назначает ему атрибуты, которые определены в attr (мы будем использовать NULL, чтобы установить значения по умолчанию). Число потоков, которые должны вызывать функцию barrier_wait(), передается в параметре count.
После того как барьер создан, каждый из потоков должен будет вызвать функцию barrier_wait(), чтобы сообщить, что он отработал:
#include <sync.h>
int barrier_wait(barrier_t *barrier);
После того как поток вызвал barrier_wait(), он будет блокирован до тех пор, пока число потоков, указанное первоначально в параметре count функции barrier_init(), не вызовет функцию barrier_wait() (они также будут блокированы). После того как нужное число потоков выполнит вызов функции barrier_wait(), все эти потоки будут разблокированы «одновременно».
Вот пример:
/*
* barrier1.c
*/
#include <stdio.h>
#include <time.h>
#include <sync.h>
#include <sys/neutrino.h>
barrier_t barrier; // Объект типа «барьер»
void* thread1(void *not_used) {
time_t now;
char buf[27];
time(&now);
printf("Поток 1, время старта %s", ctime_r(&now, buf));
// Выполнить вычисления
// (вместо этого просто сделаем sleep)
sleep(20);
barrier_wait(&barrier);
// После этого момента все потоки уже завершатся
time(&now);
printf("Барьер в потоке 1, время срабатывания %s",
ctime_r(&now, buf));
}
void* thread2(void *not_used) {
time_t now;
char buf[27];
time(&now);
printf("Поток 2, время старта %s", ctime_r(&now, buf));
// Выполнить вычисления
// (вместо этого просто сделаем sleep)
sleep(40);
barrier_wait(&barrier);
// После этого момента все потоки уже завершатся
time(&now);
printf("Барьер в потоке 2, время срабатывания %s",
ctime_r(&now, buf));
}
main() // Игнорировать аргументы
{
time_t now;
char buf[27];
// Создать барьер со значением счетчика 3
barrier_init(&barrier, NULL, 3);
// Создать два потока, thread1 и thread2
pthread_create(NULL, NULL, thread1, NULL);
pthread_create(NULL, NULL, thread2, NULL);
// Сейчас выполняются оба потока
// Ждать завершения
time(&now);
printf("main(): ожидание у барьера, время %s",
ctime_r(&now, buf));
barrier_wait(&barrier);
// После этого момента все потоки уже завершатся
time(&now);
printf("Барьер в main(), время срабатывания %s",
ctime_r(&now, buf));
}
Основной поток создал объект типа «барьер» и инициализировал его значением счетчика, равным числу потоков (включая себя!), которые должны «встретиться» у барьера, прежде чем он «прорвется». В нашем примере этот индекс был равен 3 — один для потока main(), один для потока thread1() и один для потока thread2(). Затем, как и прежде, стартуют потоки вычисления графики (в нашем случае это потоки thread1() и thread2()). Для примера вместо приведения реальных алгоритмов графических вычислений мы просто временно «усыпили» потоки, указав в них sleep(20) и sleep(40), чтобы имитировать вычисления. Для осуществления синхронизации основной поток (main()) просто блокирует сам себя на барьере, зная, что барьер будет разблокирован только после того, как рабочие потоки аналогично присоединятся к нему.
Как упоминалось ранее, с функцией pthread_join() рабочие потоки для синхронизации главного потока с ними должны умереть. В случае же с барьером потоки живут и чувствуют себя вполне хорошо. Фактически, отработав, они просто разблокируются по функции barrier_wait(). Тонкость здесь в том, что вы обязаны предусмотреть, что эти потоки должны делать дальше! В нашем примере с графикой мы не дали им никакого задания для них — просто потому что мы так придумали алгоритм. В реальной жизни вы могли бы захотеть, например, продолжить вычисления.
Несколько потоков при одиночном процессоре
Предположим, что мы слегка изменили наш пример так, чтобы можно было проиллюстрировать, почему иногда хорошо иметь несколько потоков даже в системе с одиночным процессором.
В таком модифицированном примере один узел на сети ответственен за вычисление строк растра (как и в примере с графикой, рассмотренном выше). Однако, когда строка рассчитана, ее данные должны быть отправлены по сети другому узлу, который выполняет функцию отображения. Ниже приведена соответствующая модифицированная функция main() (на основе первоначального примера без потоков):
int main(int argc, char **argv) {
int x1;
... // выполнить инициализации
for (x1 = 0; x1 < num_x_lines; x1++) {
do _one_line(x1); // Область «С» на схеме
tx_one_line_wait_ack(x1); // Области «X» и «W» на схеме
}
}
Обратите внимание на то, что мы исключили отображающую часть программы и вместо этого добавили функцию tx_one_line_wait_ack(). Далее предположим, что мы имеем дело с достаточно медленной сетью, но процессор в действительности не занимается передачей данных — он просто отдает их некоторым аппаратным средствам, которые уже сами позаботятся об их передаче. Функция tx_one_line_wait_ack() потребует немного процессорного времени на то, чтобы обеспечить передачу данных аппаратным средствам, и после этого, пока не получит подтверждения о получении данных от удаленного узла, не будет потреблять процессорное время вообще.
Ниже представлена диаграмма, иллюстрирующая загрузку процессора в данном случае (графические вычисления на ней обозначены как «С», передача — как «X», а ожидание подтверждения — как «W»).
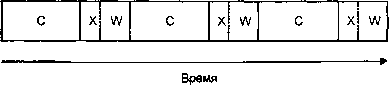
Последовательное выполнение, один процессор.
Минуточку! Мы тратим впустую драгоценные секунды, ожидая, пока аппаратура сделает свое дело!
Если мы сделали бы это в многопоточном варианте, мы смогли бы добиться более эффективного использования процессора, так?
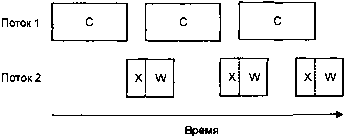
Многопоточное выполнение, один процессор
Это уже намного лучше, потому что теперь, даже при том, второй поток затрачивает немного времени на ожидание, мы добились уменьшения суммарного времени вычислений.
Если бы в нашем примере тратилось Tcompute единиц времени на вычисления, Ttx — на передачу и Twait — на ожидание аппарату средств, тогда для первого случая в нашем примере общие затраты времени на обработку были бы равны:
(Tcompute + Ttx + Twait) ? num_x_lines,
тогда как затраты времени при использовании двух потоков были бы равны:
(Tcompute + Ttx) ? num_x_lines + Twait,
что меньше на величину:
Twait ? (num_x_lines – 1),
в предположении, конечно, что Twait ? Tcompute.
Отметим, что мы изначально будем ограничены интервалом времени, равным:
Tcompute + Ttx ? num_x_lines,
потому что мы должны будем завершить по меньшей мере одно полное вычисление, а также еще и передать данные. Иными словами, мы можем использовать многопоточность для распараллеливания вычислений, но аппаратный ресурс для передачи данных у нас все равно есть только один.
А если бы мы разработали вариант системы с четырьмя потоками и выполнили это в SMP-системе с четырьмя процессорами, это выглядело бы примерно так:
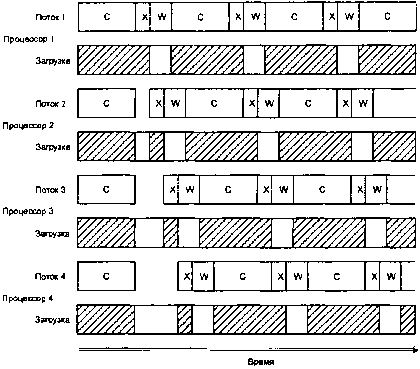
Четыре потока, четыре процессора.
Обратите внимание, насколько каждый из этих четырех центральных процессоров недоиспользован (см. незаштрихованные прямоугольники в строках «Загрузка»). На представленном выше рисунке имеются две интересные зоны. Когда все четыре потока стартуют одновременно, все они вычисляются. К сожалению, когда потоки заканчивают вычисления, они начинают конкурировать за право обладания аппаратными средствами передачи данных (зоны «X» на диаграмме смещены одна относительно другой, поскольку, имея только один передающий ресурс, можно вести только одну передачу одновременно). Это дает нам небольшую аномалию на начальном этапе. После того как потоки отработали этот этап, они оказываются естественным образом синхронизированы по отношению к работе аппаратных средств, так как время передачи данных намного меньше, чем ? времени вычислительного цикла. Если игнорировать эту небольшую аномалию в работе системы на начальном этапе, значения временных интервалов в данной системе можно оценить по формуле:
(Tcompute + Ttx + Twait) ? num_x_lines / num_cpus
Из этой формулы следует, что применение четырех потоков на четырех процессорах обеспечивает сокращение затрат времени приблизительно в 4 раза по сравнению с аналогичным временем в модели с единственным потоком, т.е. по сравнению с данным! примера, с которого мы начали обсуждение этой проблемы.
Суммируя все то, что мы узнали из анализа примера с использованием многопоточного варианта с одиночным процессором, в идеале мы желали бы иметь больше потоков, чем процессоров, чтобы дополнительные потоки могли «подобрать» время простоя процессоров, которое естественным образом возникает из интервалов ожидания подтверждения (а также из интервалов ожидания, связанных с конкуренцией за передатчик) В этом случае у нас бы получилось примерно вот что: (см. рис. «Восемь потоков, четыре процессора»).
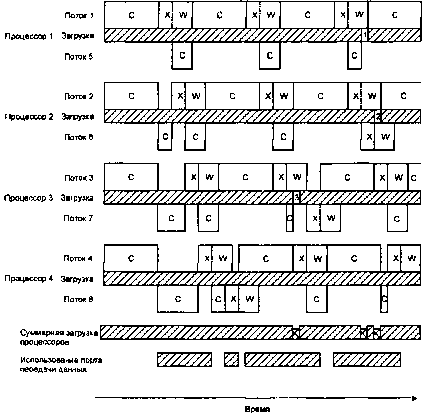
Восемь потоков, четыре процессора.
На этом рисунке предполагается следующее:
• потоки 5, 6, 7 и 8 привязаны к процессорам 1, 2, 3, и 4 (для упрощения);
• передача данных выполняется с более высоким приоритетов чем вычислительные операции;
• прервать передачу нельзя.
Из диаграммы видно, что хоть мы теперь и имеем в два раза больше потоков, чем процессоров, мы по-прежнему сталкиваемся с временными интервалами, в течение которых процессоры «недоиспользованы». На рисунке показаны три таких интервала времени. Эти интервалы обозначены числами, соответствующими номеру процессора, и указаны на временных диаграммах загрузки процессоров в строках «Загрузка»:
1. Поток 1 ожидает подтверждения (состояние «W»), при этом поток 5 завершил вычисления и ждет доступности передатчика.
2. Потоки 2 и 6 ожидают подтверждения.
3. Поток 3 ожидает подтверждения, при этом поток 7 завершил вычисления и ждет доступности передатчика.
Этот пример для нас — важный урок. Бессмысленно просто увеличивать количество процессоров в надежде, что все ваши дела пойдут быстрее, поскольку имеются также и ограничивающие факторы. В некоторых случаях эти ограничивающие факторы определяются просто конструкцией материнской платы мультипроцессорной системы, то есть структурой подсистемы разрешения конфликтов за устройства в память, когда несколько процессоров пытаются обратиться по одному и тому же адресу. В нашем случае обратите внимание, что строка «Использование порта передачи данных» стала все больше заполняться. Если бы мы просто увеличили число процессоров, то в конечном счете столкнулись бы с проблемами, связанными с тем, что соответствующие потоки простаивали бы в ожидании передатчика.
В любом случае, используя потоки-«мусорщики» для сбора неиспользованных ресурсов процессоров, мы сможем обеспечить намного более эффективное использование процессоров. Это время приближенно оценивается по формуле:
(Tcompute + Ttx + Twait) ? num_x_lines / num_cpus
При выполнении только вычислений мы ограничены только количеством процессоров; ни один процессор не будет простаивать в ожидании подтверждения. Впрочем, это был бы идеальный случай. Как вы видели из диаграммы, реально периодически возникают временные интервалы, когда один процессор простаивает. Также, как отмечалось ранее, мы в любом случае ограничены по скорости значением:
Tcompute + Ttx ? num_x_lines.
На что обратить внимание при использовании симметричного мультипроцессора (SMP)
При том, что в общем случае вы можете запросто «игнорировать», работаете вы с SMP-архитектурой или с одиночным процессором, есть ряд обстоятельств, которые определенно добавят вам головной боли. К сожалению, это могут быть такие маловероятные события, которые могут проявиться не на этапе разработки, а на этапе его испытаний, в демонстрационных версиях или даже, что самое неприятное, на стадии эксплуатации. Так вот, следование ряду принципов «защитного программирования» избавит вас от связанной с этими проблемами нервотрепки.
Вот краткий перечень того, что следует четко помнить, имея дело с SMP-системой:
• Потоки действительно могут работать и работают параллельно — ни в коем случае не доверяйте при их синхронизации таким механизмам как диспетчеризация FIFO или система приоритетов.
• Потоки могут также выполняться одновременно с обработчиками прерываний (ISR) — это означает, что вам нужно будет не только защитить поток от обработчика прерываний, но и наоборот — обработчик прерываний от потока. Подробнее об этом см. в главе 4, «Прерывания».
• Некоторые операции, которые по вашему мнению должны быть атомарными, в действительности таковыми не являются — это зависит от операции и от процессора. Отметим из такого списка операции типа «чтение- модификация-запись» (например, ++, --, &=, т.д.). См. файл <atomic.h> для анализа возможных замен. (Заметьте, что это не проблема SMP в чистом виде; код для вышеупомянутых операции может выполняться не как атомарный на большинстве RISC-процессоров).
Потоки в независимых ситуациях
Ранее в разделе «Где хороша многопоточность» говорилось о том, что потокам также находят применение там, где имеет место обработка информации по множеству независимых алгоритмов с разделяемыми структурами данных. При этом, строго говоря, вы могли бы использовать несколько процессов (с одним потоком каждый), явно разделяющих данные, но в некоторых случаях вместо этого гораздо удобнее использовать один многопоточный процесс. Давайте рассмотрим, почему и где здесь можно использовать потоки.
В наших примерах будем отталкиваться от стандартной модели «ввод-обработка-вывод». В наиболее общем случае одна часть этой модели ответственна за получение откуда-либо входных данных, другая часть — за обработку этих данных и преобразование их в некоторые выходные данные (или управляющие воздействия), третья часть — за отправку полученных выходных данных куда надо.
Несколько процессов
Давайте, во-первых, осмыслим, что мы будем иметь в случае нескольких однопоточных процессов. Для нашей модели у нас было бы три процесса — процесс «ввода», процесс «обработки» и процесс «вывода»:
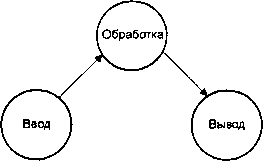
Система 1: Несколько операций, несколько процессов.
В таком виде наша модель в высшей степени абстрактна, но и в такой же степени «слабо связана». Процесс «ввода» не имеет никакой реальной связи ни с процессом «обработки», ни с процессом «вывода» — он просто отвечает за сбор входных данных и передачу их как-нибудь на следующий этап («этап обработки»).
Мы могли бы сказать то же самое о процессах «обработки» и «вывода» — они также не имеют никакой реальной связи друг с другом. Также здесь предполагается, что обмен данными («ввод — обработка» и «обработка — вывод») осуществляется по некоторому стандартному протоколу (например, через программные каналы, очереди сообщений POSIX, обмен сообщениями QNX/Neutrino — что угодно).
Несколько процессов с разделяемой памятью
В зависимости от объема потока данных, мы можем пожелать оптимизировать характер связей. Самый простой путь состоит в том, чтобы связать три процесса «теснее». Попробуем теперь вместо использования универсального протокола соединения выбрать схему с разделяемой памятью (на диаграмме толстые стрелки указывают потоки данных; тонкие стрелки — потоки управления):
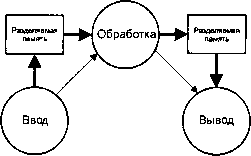
Система 2: Несколько операций, буферы разделяемой памяти между процессами.
В данной схеме мы «подтянули» связь так, чтобы в результате обеспечить более быстрый и более эффективный обмен данными. В то же время, мы здесь по-прежнему можем применять универсальный протокол для передачи «управляющей» информации, поскольку предполагается, что по сравнению с потоком данных ее не так много.
Несколько потоков
Система с наиболее тесными связями представлена на следующей схеме:
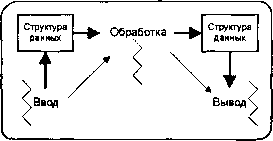
Система 3: Несколько операций, несколько потоков.
Здесь мы наблюдаем один процесс с тремя потоками. Все три потока неявно разделяют области данных. Обмен управляющей информацией может быть реализован аналогично предыдущим примерам или с помощью ряда примитивов синхронизации потоков (мы уже имели дело с мутексами, барьерами и семафорами — скоро рассмотрим и другие).
Сравнение
Давайте теперь сравним эти три метода по ряду критериев и взвесим все «за» и «против».
В системе 1 связь была самой слабой. Это имеет то преимущество, что каждый из трех процессов может быть легко (то есть при помощи командной строки, в противоположность перекомпиляции/переработке) заменен другим модулем. Это следует из самой природы модели, потому что «единицей модульности» здесь является сам функциональный модуль. Система 1 является также единственной, которая из всех трех может быть распределена по узлам сети QNX/Neutrino. Поскольку информационные связи здесь абстрагированы до некоторого универсального протокола, очевидно, что эти три процесса могут быть выполнены на любой машине в сети. Это может быть очень мощным фактором масштабируемости в Вашем проекте — вам может понадобиться расширить свою сеть до сотен узлов, либо разделенных географически, либо как-то иначе — например, для совместимости с другими аппаратными средствами.
Однако, как только мы переходим к применению разделяемой памяти, мы теряем способность распределять модули по сети. QNX/Neutrino не поддерживает распределенные объекты разделяемой памяти. Таким образом, в Системе 2 мы реально ограничили себя выполнением всех трех процессов на одной и той же машине. Мы не потеряли способность легкой замены или исключения модулей, потому что модули все еще представляют собой отдельные процессы, управляемые командной строкой. Но мы добавили ограничение, в соответствии с которым все заменяемые компоненты должны соответствовать модели с разделяемой памятью.
В системе 3 мы теряем все отмеченные ранее проектные возможности. Мы определенно не можем выполнять различные потоки одного процесса на различных узлах (хотя при этом мы можем выполнять их на различных процессорах в SMP-системе). Также мы потеряли наши возможности переконфигурации — теперь нам обязательно понадобится механизм явного доопределения, который из алгоритмов «ввода», «обработки» и «вывода» мы должны использовать (эту проблему можно решить с помощью разделяемых объектов, также известных как динамические библиотеки — DLL).
Так почему же я должен проектировать свою систему, используя многопоточность, как в Системе 3? Почему бы мне для обеспечения максимальной универсальности не выбрать Систему 1?
Ну, даже при том, что Система 3 является наиболее ригидной, она, скорее всего, окажется самой быстродействующей. В ней не будет переключений контекста между потоками в различных процессах, мне не придется настраивать разделяемую память, а также применять абстрактные методы синхронизации типа программных каналов, очередей сообщений POSIX или обмен сообщениями QNX/Neutrino для обеспечения доставки данных или управляющей информации — я смогу использовать базовые примитивы синхронизации потоков на уровне ядра. Другим преимуществом является то, что при запуске системы, состоящей из одного процесса (с тремя потоками), я могу быть уверен, что все, что мне понадобится далее, уже загружено с носителя (то есть потом не выяснится что-то типа «Опа! А нужного-то драйвера на диске и нету...») И, наконец, Система 3 также, скорее всего, будет наиболее компактной, потому что не придется использовать три отдельных копии информации, характерной для процессов (например, дескрипторы файлов).
Мораль: знайте, какое решение сулит какие выгоды и какие потери, и применяйте то, что будет оптимальным для вашего конкретного проекта.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Атрибуты потока
Атрибуты потока В коде реальных приложений очень часто можно видеть простейшую форму вызова, порождающего новый поток, в следующем виде:pthread_create(NULL, NULL, &thread_func, NULL);И для многих целей такого вызова достаточно, так как созданный поток будет обладать свойствами,
Данные потока
Данные потока В реальном коде часто возникает ситуация, когда одновременно исполняются несколько экземпляров потоков, использующих один и тот же код (при создании потоков указывается одна и та же функция потока). При этом некоторые данные (например, статические объекты,
Завершение потока
Завершение потока Как и в случае обсуждавшегося ранее завершения процесса, для потоков мы будем отчетливо различать случаи:• «естественного» завершения выполнения потока из кода самого потока;• завершения потока извне, из кода другого потока или по сигналу. Для этого
Возврат результата потока
Возврат результата потока Выше отмечено, что вызов pthread_exit(), завершающий ожидаемый поток, может передать результат выполнения потока. То же действие может быть выполнено и оператором return потоковой функции, которая из прототипа ее определения должна возвращать значение
Уничтожение (отмена) потока
Уничтожение (отмена) потока Корректное завершение выполняющегося потока «извне», из другого потока (то есть асинхронно относительно прерываемого потока), — задача отнюдь не тривиальная; она намного сложнее аналогичной задачи прерывания процесса. Это связано с
«Легковесность» потока
«Легковесность» потока Вот теперь, завершив краткий экскурс использования процессов и потоков, можно вернуться к вопросу, который вскользь уже звучал по ходу рассмотрения: почему и в каком смысле потоки часто называют «легкими процессами» (LWP — lightweight process)?Выполним ряд
Ожидание завершения потока
Ожидание завершения потока Ожидание родительским потоком завершения одного или нескольких порожденных им «присоединенных» потоков (на вызове pthread_join()) — это простейший и эффективный вариант синхронизации потоков, не требующий для своей реализации каких-либо
Зона потока
Зона потока О сверхпроизводительном состоянии, называемом «потоком» (flow), написано много литературы. Некоторые программисты называют его «зоной». Как бы оно ни называлось, вероятно, вам знакомо это ощущение предельной концентрации сознания, в которое может войти
Создание потока
Создание потока Поток создается при первом открытии с помощью системного вызова специального файла устройства, ассоциированного с драйвером STREAMS. Как правило, процесс создает поток в два этапа: сначала создается элементарный поток, состоящий из нужного драйвера и
Пример: запуск нового потока
Пример: запуск нового потока Альтернативой снятию блокировки сигналом является присваивание sigev_notify значения SIGEV_THREAD, что приводит к созданию нового потока. Функция, указанная в sigev_notify_function, вызывается с параметром sigev_value. Атрибуты нового канала указываются переменной
12.1. Создание потока
12.1. Создание потока ПроблемаТребуется создать поток (thread) для выполнения некоторой задачи, в то время как главный поток продолжает свою работу.РешениеСоздайте объект класса thread и передайте ему функтор, который выполняет данную работу. Создание объекта потока приведет к
Синхронизация вызывающего потока
Синхронизация вызывающего потока Для текущей реализации Main() диапазон времени между вызовом BeginInvoke() и вызовом EndInvoke() явно меньше пяти секунд. Поэтому после вывода на консоль сообщения "В Main() еще есть работа!" поток вызова блокируется и ждет завершения существования
4.2. Отмена потока
4.2. Отмена потока Обычно поток завершается при выходе из потоковой функции или вследствие вызова функции pthread_exit(). Но существует возможность запросить из одного потока уничтожение другого. Это называется отменой, или принудительным завершением, потока.Чтобы отменить
20.7. Состояния потока
20.7. Состояния потока Пользователей библиотеки iostream, разумеется, интересует, находится ли поток в ошибочном состоянии. Например, если мы пишемint ival;cin ival;и вводим слово "Borges", то cin переводится в состояние ошибки после неудачной попытки присвоить строковый литерал целому
8.4.2 Состояния Потока
8.4.2 Состояния Потока Каждый поток (istream или ostream) имеет ассоциированное с ним состояние, и обработка ошибок и нестандартных условий осуществляется с помощью соответствующей установки и проверки этого состояния.Поток может находиться в одном из следующих состояний:enum