Пулы потоков
Пулы потоков
Другое существенное дополнение в QNX/Neutrino — это понятие пула потоков. Вы будете часто обращать внимание в ваших программах на то обстоятельство, что вам хотелось бы иметь несколько потоков и управлять их поведением в определенных пределах. Например, для сервера вы можете решить, что первоначально в ожидании сообщения от клиента должен быть блокирован только один поток. Когда этот поток получит сообщение и пойдет обслуживать запрос, вы можете принять решение о том, что хорошо было бы создать другой поток и блокировать его в ожидании на случай поступления другого запроса — тогда этот запрос будет кому обработать. И так далее. Через некоторое время, когда все запросы будут обслужены, у вас может оказаться большое число потоков, бездействующих в ожидании. Чтобы не расходовать ресурсы впустую, вам, возможно, захочется уничтожить некоторые из этих «лишних» потоков.
Подобные операции в жизни — обычное дело, и для задач такого рода QNX/Neutrino предоставляет для этого специальную библиотеку.
 В более ранних (до 2.00) версиях QNX/Neutrino была предусмотрена подобная функциональность, но она была скрыта в библиотеке администратора ресурсов. В версии 2.00 эти функции были вынесены из библиотеки администратора ресурсов в отдельную библиотеку. Мы еще вернемся к функциям работы с пупами потоков в главе «Администраторы ресурсов».
В более ранних (до 2.00) версиях QNX/Neutrino была предусмотрена подобная функциональность, но она была скрыта в библиотеке администратора ресурсов. В версии 2.00 эти функции были вынесены из библиотеки администратора ресурсов в отдельную библиотеку. Мы еще вернемся к функциям работы с пупами потоков в главе «Администраторы ресурсов».
В рамках данного обсуждения важно понять, что следует различать два режима потоков в пулах:
• режим блокирования;
• режим обработки.
В режиме блокирования поток обычно вообще не использует ресурсы процессора. В типовом сервере это соответствует ситуации, когда поток ждет сообщения. Противоположностью этого режима является режим обработки, в котором поток может как использовать, так и не использовать ресурсы процессора — это зависит от структуры процесса. Чуть позже мы рассмотрим функции работы с пулами потоков, и вы увидите, что они дают возможность управлять количеством как блокированных, так и обрабатывающих потоков.
Для работы с пулами потоков в QNX/Neutrino предусмотрены следующие функции:
#include <sys/dispatch.h>
thread_pool_t *thread_pool_create(
thread_pool_attr_t *attr, unsigned flags);
int thread_pool_destroy(thread_pool_t *pool);
int thread_pool_start(void *pool);
Как видно из имен функций, вы в первую очередь создаете пул потоков, используя функцию thread_pool_create(), а затем запускаете этот пул при помощи функции thread_pool_start(). Когда вы закончили свои дела с пулом потоков, вы можете использовать функцию thread_pool_destroy() для его уничтожения. Заметьте, что функция thread_pool_destroy() может вам вообще не понадобиться — например, когда ваша программа суть сервер, который работает «вечно».
Итак, первая функция, на которую следует обратить внимание — это функция thread_pool_create(). У нее два параметра: attr и flags. Параметр attr — атрибутная запись, которая определяет рабочие параметры пула потоков (см. <sys/dispatch.h>):
typedef struct _thread_pool_attr {
// Функции и дескриптор пула потоков
THREAD_POOL_HANDLE_T *handle;
THREAD_POOL_PARAM_T *(*block_func)
(THREAD_POOL_PARAM_T *ctp);
void (*unblock_func)(THREAD_POOL_PARAM_T *ctp);
int (*handler_func) (THREAD_POOL_PARAM_T *ctp);
THREAD_POOL_PARAM_T *(*context_alloc)
(THREAD_POOL_HANDLE_T *handle);
void *(*context_free)(THREAD_POOL_PARAM_T *ctp);
// Параметры пула потоков
pthread_attr_t *attr;
unsigned short lo_water;
unsigned short increment;
unsigned short hi_water;
unsigned short maximum;
} thread_pool_attr_t;
Я разбил определение типа thread_pool_attr_t на два раздела, один из которых содержит функции и дескриптор для потоков в пуле, а в другом — рабочие параметры пула.
Управление числом потоков
Сначала проанализируем «параметры пула потоков», чтобы понять, как можно управлять числом потоков в пуле и их атрибутами. Имейте в виду, что здесь мы будем говорить о «режиме блокирования» и «режиме обработки» (далее, когда мы будем рассматривать функции исходящих вызовов (callout functions), мы увидим, как эти эти режимы соотносятся).
Приведенный ниже рисунок иллюстрирует связи между параметрами lo_water, hi_water и maximum.
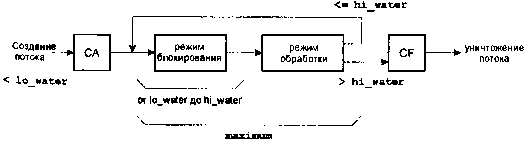
Жизненный цикл потока в пуле потоков.
(Заметьте, что как «CA» здесь обозначается функция context_alloc(), как «CF» — функция context_free(), как «режим блокирования» — функция block_func(), а как «режим обработки» — функция handler_func().
attr Это атрибутная запись, которая применяется при создании потока. Мы уже обсуждали эту структуру ранее (в разделе «Атрибутная запись потока»). Вспомните — это та самая структура, которая задает характеристики нового потока: приоритет, размер стека, и т.д. lo_water (От «Low watermark», буквально — «нижняя ватерлиния» — прим. ред.) Этот параметр задает минимальное количество потоков, которые должны находиться в режиме блокирования. В типовом сервере это было бы количество потоков, например, ждущих запроса. Если число ждущих потоков меньше, чем значение параметра lo_water, (например, потому что мы только что приняли сообщение, и один из ждущих потоков переключился на его обработку), тогда создается дополнительно еще increment потоков. Это представлено на рисунке в виде первого этапа, обозначенного как «создание потока». increment (Буквально — «приращение» — прим. ред.) Этот параметр определяет, сколько потоков должны быть созданы сразу, если число потоков, находящихся в режиме блокирования, становится меньше значения параметра lo_water. В выборе значения для этого параметра вы бы наиболее вероятно начали со значения 1 (единица). Это означало бы, что если бы число потоков в режиме блокирования стало бы меньше значения параметра lo_water, то пулом потоков был бы создан дополнительно ровно один поток. Для более тонкой настройки параметра increment можно понаблюдать за поведением процесса и определить, может ли этому параметру понадобиться принимать значения, отличные от единицы. Например, если ваш процесс периодически получает «всплески» запросов, то из того, что число потоков, находящихся в режиме блокирования, упало ниже значения lo_water, можно было бы сделать вывод как раз о таком «всплеске» и принять решение о создании более чем одного резервного потока. hi_water (От «high watermark», буквально — «верхняя ватерлиния» — прим. ред.) Этот параметр указывает верхний предел числа потоков, которые могут быть в режиме блокирования одновременно. По мере завершения своих операций по обработке данных, потоки обычно будут возвращаться в режим блокирования. Однако, у библиотеки поддержки пулов потоков есть внутренний счетчик числа потоков, находящихся в режиме блокирования, и если его значение превышает значение параметра hi_water, библиотека автоматически уничтожит поток, который вызвал переполнение (то есть тот поток, который только что завершил обработку и намеревался возвратиться в режим блокирования). Это показано на рисунке раздвоением стрелки, исходящей из блока «режим обработки» — одна стрелка ведет к «режиму блокирования», а вторая — к блоку операции «CF» и далее на уничтожение потока. Таким образом, сочетание параметров lo_water и hi_water позволяет вам четко определять диапазон числа потоков, одновременно находящихся в режиме блокирования. maximum Параметр указывает на максимальное число потоков, которые вообще могут работать одновременно в результате действий библиотеки поддержки пулов потоков. Например, при создании новых потоков в случае их нехватки (когда число блокированных потоков падает ниже границы lo_water) общее количество потоков было бы ограничено параметром maximum.Другой ключевой параметр, предназначенный для управления потоками, — это параметр flags, передаваемый функции thread_pool_create(). Он может принимать одно из следующих значений:
POOL_FLAG_EXIT_SELF
Не делать возврат из функции thread_pool_start() и не включать вызывающий поток в пул.
POOL_FLAG_USE_SELF
Не делать возврат из функции thread_pool_start(), но включить вызывающий поток в пул.
0
Функция thread_pool_start() возвратится, новые потоки будут создаваться по мере необходимости.
Приведенное описание может показаться суховатым. Давайте рассмотрим пример.
В управляющей структуре пула потоков сконцентрируем наше внимание только на значениях параметров lo_water, increment и maximum:
/*
* tp1.с
*
* Пример с пулами потоков (1)
*
*/
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <sys/neutrino.h>
#include <sys/dispatch.h>
char *progname = "tp1";
void tag (char *name) {
time_t t;
char buffer[BUFSIZ];
time(&t);
strftime(buffer, BUFSIZ, "%T ", localtime(&t));
printf("%s %3d %-20.20s: ", buffer, pthread_self(), name);
}
THREAD_POOL_PARAM_T* blockfunc(
THREAD_POOL_PARAM_T *ctp) {
tag("blockfunc");
printf("ctp %p ", ctp);
tag("blockfunc");
printf("sleep (%d); ", 15 * pthread_self());
sleep(pthread_self() * 15);
tag("blockfunc");
printf("Выполнили sleep ");
tag("blockfunc");
printf("Возвращаем 0x%08X ",
0x10000000 + pthread_self());
return((void*)(0x10000000 + pthread_self()));
// Передано handlerfunc
}
THREAD_POOL_PARAM_T* contextalloc(
THREAD_POOL_HANDLE_T *handle) {
tag("contextalloc");
printf("handle %p ", handle);
tag("contextalloc");
printf("Возвращаем 0x%08X ",
0x20000000 + pthread_self());
return ((void*)(0x20000000 + pthread_self()));
// Передано blockfunc
}
void contextfree(THREAD_POOL_PARAM_T *param) {
tag("contextfree");
printf("param %p ", param);
}
void unblockfunc(THREAD_POOL_PARAM_T *ctp) {
tag("unblockfunc");
printf("ctp %p ", ctp);
}
int handlerfunc(THREAD_POOL_PARAM_T *ctp) {
static int i = 0;
tag("handlerfunc");
printf("ctp %p ", ctp);
if (i++ > 15) {
tag("handlerfunc");
printf("Более 15 операций, возвращаем 0 ");
return (0);
}
tag("handlerfunc");
printf("sleep (%d) ", pthread_self() * 25);
sleep(pthread_self() * 25);
tag("handlerfunc");
printf("Выполнили sleep ");
tag("handlerfunc");
printf("Возвращаем 0x%08X ",
0x30000000 + pthread_self());
return (0x30000000 + pthread_self());
}
main() {
thread_pool_attr_t tp_attr;
void *tpp;
memset(&tp_attr, 0, sizeof(tp_attr));
tp_attr.handle = (void*)0x12345678;
// Передано contextalloc
tp_attr.block_func = blockfunc;
tp_attr.unblock_func = unblockfunc;
tp_attr.context_alloc = contextalloc;
tp_attr.context_free = contextfree;
tp_attr.handler_func = handlerfunc;
tp_attr.lo_water = 3;
tp_attr.hi_water = 7;
tp_attr.increment = 2;
tp_attr.maximum = 10;
if ((tpp =
thread_pool_create(&tp_attr, POOL_FLAG_USE_SELF)) ==
NULL) {
fprintf(stderr,
"%s: Ошибка thread_pool_create, errno %s ",
progname, strerror(errno));
exit(EXIT_FAILURE);
}
thread_pool_start(tpp);
fprintf(stderr,
"%s: возврат из thread_pool_start; errno %s ",
progname, strerror(errno));
sleep(3000);
exit(EXIT_FAILURE);
}
После установки параметров мы вызываем функцию thread_pool_create() для создания пула потоков. Эта функция возвращает указатель на управляющую структуру пула потоков (tpp), который мы проверяем на равенство NULL (что указало бы на ошибку). И, наконец, мы вызываем функцию thread_pool_start(), передав ей эту самую управляющую структуру tpp.
Я указал флаг POOL_FLAG_USE_SELF, что означает, что поток, вызвавший функцию thread_pool_start(), будет рассматриваться как доступный для ввода в пул. Таким образом, на момент старта пула в нем есть только один поток. Поскольку значение параметра lo_water равно 3, библиотека немедленно создаст еще increment потоков (в нашем случае — 2). С этого момента в пуле будет три (3) потока, и все они будут находиться в режиме блокирования. Условие по параметру lo_water удовлетворено, потому что число потоков в режиме блокирования действительно не меньше lo_water, условие по параметру hi_water удовлетворено, потому что число потоков в режиме блокирования действительно не больше hi_water; и, наконец, также удовлетворено условие по параметру maximum, потому что общее число потоков не превышает его значения. Допустим теперь, что один из потоков, находящихся в режиме блокирования, разблокируется (например, в серверном приложении — при получении сообщения). Это означает, что один из трех потоков перейдет из режима блокирования в режим обработки. Счетчик блокированных потоков уменьшится, и его значение упадет ниже значения параметра lo_water. Это переключит триггер lo_water и заставит библиотеку создать ещё increment (2) потоков. Таким образом, у нас будет всего 5 потоков (4 в режиме блокирования, и 1 — в режиме обработки).
Пусть далее разблокируется еще несколько потоков. Давайте предположим, что на этот момент еще ни один из потоков, находящихся в режиме обработки, еще не завершил свои дела. Ниже приведена таблица, в которой иллюстрируется весь процесс, начиная с исходного состояния:
Событие Режим обработки Режим блокирования Всего потоков Исходное состояние 0 1 1 Срабатывание триггера lo_water 0 3 3 Разблокирование 1 2 3 Срабатывание триггера lo_water 1 4 5 Разблокирование 2 3 5 Разблокирование 3 2 5 Срабатывание триггера lo_water 3 4 7 Разблокирование 4 3 7 Разблокирование 5 2 7 Срабатывание триггера lo_water 5 4 9 Разблокирование 6 3 9 Разблокирование 7 2 9 Срабатывание триггера lo_water 7 3 10 Разблокирование 8 2 10 Разблокирование 9 1 10 Разблокирование 10 0 10Видно, что библиотека проверяет параметр lo_water, и по мере необходимости увеличивает число потоков на значение параметра increment, но только до тех пор, пока число потоков не достигнет предельного значения — параметра maximum (именно поэтому число в столбце «Всего потоков» никогда не превышает 10, даже когда условие по параметру lo_water перестает выполняться).
Это означает, что однажды наступает момент, когда потоков в режиме блокирования больше не остается. Предположим теперь, что потоки, находящиеся в режиме обработки, завершают свои дела. Посмотрим, что при этом произойдет с триггером параметра hi_water.
Событие Режим обработки Режим блокирования Всего потоков Завершение обработки 9 1 10 Завершение обработки 8 2 10 Завершение обработки 7 3 10 Завершение обработки 6 4 10 Завершение обработки 5 5 10 Завершение обработки 4 6 10 Завершение обработки 3 7 10 Завершение обработки 2 8 10 Срабатывание триггера hi_water 2 7 9 Завершение обработки 1 8 9 Срабатывание триггера hi_water 1 7 9 Завершение обработки 0 8 8 Срабатывание триггера hi_water 0 7 7Обратите внимание, что с потоками ничего не происходит до тех пор, пока число блокированных потоков не превышает значение hi_water. Реализация здесь такова: как только поток завершает обработку, он проверяет число блокированных на данный момент потоков, и если их слишком много (то есть больше, чем предусмотрено параметром hi_water), то «совершает самоубийство». Удобство использования параметров lo_water и hi_water в управляющих структурах состоит в том, что ими вы фактически задаете «эффективный диапазон» числа потоков, в пределах которого всегда доступно достаточное число потоков, и потоки без необходимости не создаются и не уничтожаются. В нашем случае, после выполнения действий, перечисленных в вышеупомянутых таблицах, мы имеем систему, которая способна обрабатывать до 4 запросов одновременно без необходимости в создании дополнительных потоков (7-4 = 3, что соответствует значению параметра lo_ water).
Функции работы с пулами потоков
Теперь, когда мы достаточно хорошо владеем методикой управления числом потоков в пуле, давайте обратимся к другим элементам атрибутной записи пула потоков:
// Функции и дескриптор пула потоков
THREAD_POOL_HANDLE_T *handlе;
THREAD_POOL_PARAM_T *(*block_func)(
THREAD_POOL_PARAM_T *ctp);
void (*unblock_func)(THREAD_POOL_PARAM_T *ctp);
int (*handler_func)(THREAD_POOL_PARAM_T *ctp);
THREAD_POOL_PARAM_T *(*context_alloc)(
THREAD_POOL_HANDLE_T *handle);
void (*context_free)(THREAD_POOL_PARAM_T *ctp);
Повторно обратимся к рисунку «Жизненный цикл пула потоков». Из рисунка видно, что при создании потока каждый раз вызывается функция context_alloc(). (Аналогично, при уничтожении потока вызывается функция context_tree()). Элемент атрибутной записи с именем handler передается функции context_alloc() в качестве ее единственного параметра. Функция context_alloc() ответственна за индивидуальные настройки потока и возвращает указатель на контекст (списках параметров называемый ctp). Заметьте, что содержание этого указателя — исключительно ваша забота; библиотеке абсолютно все равно, что вы в него поместите.
Теперь, когда контекст создан функцией context_alloc(), вызывается функция block_func() для перевода потока в режим блокирования. Заметьте, что функция block_func() получает на вход результат работы функции context_alloc(). После того как функция block_func() разблокируется, она возвращает указатель на контекст, который библиотека передает функции handler_func(). Функция handler_func() отвечает за выполнение «работы» — например, в типовом варианте именно она обрабатывает сообщение от клиента. На данный момент принято, что функция handler_func() должна возвращать нуль — ненулевые значения зарезервированы QSSL для будущего функционального расширения. Функция unblock_func() также в настоящее время зарезервирована, поэтому просто оставьте там NULL.
Возможно, ситуацию немного прояснит приведенный ниже пример псевдокода (он основан все на том же рисунке «Жизненный цикл потока в пуле потоков»):
FOREVER DO
IF (#threads < lo_water) THEN
IF (#threads < maximum) THEN
create new thread
context = (*context_alloc)(handle);
ENDIF
ENDIF
retval = (*block_func)(context);
(*handler_func)(retval);
IF (#threads > hi_water) THEN
(*context_free)(context)
kill thread
ENDIF
DONE
Отметим, что приведенная выше программа излишне упрощена. Ее назначение состоит только в том, чтобы продемонстрировать вам поток данных по параметрам ctp и handler и дать вам некоторое представление об алгоритмах, которые обычно применяются для управления числом потоков.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Стеки потоков и допустимые количества потоков
Стеки потоков и допустимые количества потоков Следует сделать еще два предостережения. Во-первых, подумайте о размере стека, который по умолчанию составляет 1 Мбайт. В большинстве случаев этого будет вполне достаточно, но если существуют какие-либо сомнения на сей счет,
Состояния потоков
Состояния потоков Несколько раз небрежно упомянув о «выполнении», «готовности» и «блокировке», давайте теперь формализуем эти состояния потока.Выполнение (RUNNING)Состояние выполнения (RUNNING) в QNX/Neutrino означает, что поток активно использует ресурсы процессора. В системе SMP
Динамический пул потоков
Динамический пул потоков Динамический пул потоков не является каким-то специфическим механизмом, продиктованным именно микроядерной архитектурой QNX. Это удачная искусственная конструкция, все определения которой размещены в файле <sys/dispatch.h>. Удивительно не то, что в
Пулы вспомогательной памяти
Пулы вспомогательной памяти В основе System/38 лежала мысль: локализовать все сведения о дисковых устройствах ниже границы MI. Никакой код выше MI, будь то прикладная программа, или ОС, не должны были владеть какой-либо информацией, даже о том, подключены ли к системе диски.
«Избыточные» пулы
«Избыточные» пулы Избавившись от ставшего ненужным пула, рассмотрим второй вариант — создание пула с зеркальным устройством. Создаём его из двух накопителей одинакового объёма:# zpool create -f exp2 mirror sdf sdg Проверка показывает, что итоговый пул, как и следовало ожидать, равен
10.4.2 Анализ потоков
10.4.2 Анализ потоков Ричи упоминает о том, что им была предпринята попытка создания потоков только с процедурами "вывода" или только с процедурами обслуживания. Однако, процедура обслуживания необходима для управления потоками данных, так как модули должны иногда ставить
Создание потоков
Создание потоков Обеспечить многопоточную обработку в приложении Qt достаточно просто: мы только создаем подкласс QThread и переопределяем его функцию run(). Чтобы показать, как это работает, мы начнем с рассмотрения программного кода очень простого подкласса QThread, который
Синхронизация потоков
Синхронизация потоков Обычным требованием для многопоточных приложений является синхронизация работы нескольких потоков. Для этого в Qt предусмотрены следующие классы: QMutex, QReadWriteLock, QSemaphore и QWaitCondition.Класс QMutex обеспечивает такую защиту переменной или участка
13.1.1. Создание потоков
13.1.1. Создание потоков Создать поток просто: достаточно вызвать метод new и присоединить блок, который будет исполняться в потоке.thread = Thread.new do # Предложения, исполняемые в потоке...endВозвращаемое значение — объект типа Thread. Главный поток программы может использовать его для
13.1.6. Группы потоков
13.1.6. Группы потоков Группа потоков — это механизм управления логически связанными потоками. По умолчанию все потоки принадлежат группе Default (это константа класса). Но если создать новую группу, то в нее можно будет помещать потоки.В любой момент времени поток может
13.2. Синхронизация потоков
13.2. Синхронизация потоков Почему необходима синхронизация? Потому что из-за «чередования» операций доступ к переменным и другим сущностям может осуществляться в порядке, который не удается установить путем чтения исходного текста отдельных потоков. Два и более потоков,
Обзор потоков
Обзор потоков Каждый процесс Win32 имеет один главный "поток", выполняющий функции точки входа в приложение. В следующей главе будет выяснено, как создавать дополнительные потоки и соответствующий программный код, применяя возможности пространства имен System.Threading, но пока
Пул потоков CLR
Пул потоков CLR Заключительной темой нашего обсуждения в этой плаве, посвященной потокам, будет пул потоков CLR. При асинхронном вызове типов с помощью делегатов (посредством метода BeginInvoke()) нельзя сказать, что среда CLR буквально создает совершенно новый поток. В целях
2.2.1.3 Планирование потоков
2.2.1.3 Планирование потоков Сервер осведомлен о степени значимости различных потоков и в соответствии с этим назначает для них приоритеты. Например, потоки ввода-вывода получают приоритеты следующим образом: 1. ввод-вывод логической журнализации - наивысший приоритет;2.
«Избыточные» пулы
«Избыточные» пулы Избавившись от ставшего ненужным пула, рассмотрим второй вариант – создание пула с зеркальным устройством. Создаём его из двух накопителей одинакового объёма:# zpool create -f mypool mirror sdf sdgПроверка показывает, что итоговый пул, как и следовало ожидать, равен