Синхронизация потоков
Синхронизация потоков
Обычным требованием для многопоточных приложений является синхронизация работы нескольких потоков. Для этого в Qt предусмотрены следующие классы: QMutex, QReadWriteLock, QSemaphore и QWaitCondition.
Класс QMutex обеспечивает такую защиту переменной или участка программного кода, что доступ к ним в каждый момент времени может осуществлять только один поток. Этот класс содержит функцию lock(), которая закрывает мьютекс (mutex). Если мьютекс открыт, текущий поток захватывает его и немедленно закрывает; в противном случае работа текущего потока блокируется до тех пор, пока захвативший мьютекс поток не освободит его. В любом случае после вызова lock() текущий поток будет держать мьютекс до вызова им функции unlock(). Класс QMutex содержит также функцию tryLock(), которая сразу же возвращает управление, если мьютекс уже закрыт.
Предположим, что нам нужно обеспечить защиту переменной stopped класса Thread из предыдущего раздела с помощью QMutex. Тогда мы бы добавили к классу Thread следующую переменную—член:
private:
QMutex mutex;
…
};
Функция run() изменилась бы следующим образом:
01 void Thread::run()
02 {
03 forever {
04 mutex.lock();
05 if (stopped) {
06 stopped = false;
07 mutex.unlock();
08 break;
09 }
10 mutex.unlock();
11 cerr << qPrintable(messageStr.ascii);
12 }
13 cerr << endl;
14 }
Функция stop() стала бы такой:
01 void Thread::stop()
02 {
03 mutex.lock();
04 stopped = true;
05 mutex.unlock();
06 }
Блокировка и разблокировка мьютекса в сложных функциях или там, где обрабатываются исключения С++, может иметь ошибки. Qt предлагает удобный класс QMutexLocker, упрощающий обработку мьютексов. Конструктор QMutexLocker принимает в качестве аргумента объект QMutex и блокирует его. Деструктор QMutexLocker разблокирует мьютекс. Например, мы могли бы приведенные выше функции run() и stop() переписать следующим образом:
01 void Thread::run()
02 {
03 forever {
04 {
05 QMutexLocker locker(&mutex);
06 if (stopped) {
07 stopped = false;
08 break;
09 }
10 }
11 cerr << qPrintable(messageStr);
12 }
13 cerr << endl;
14 }
15 void Thread::stop()
16 {
17 QMutexLocker locker(&mutex);
18 stopped = true;
18 }
Одна из проблем применения мьютексов возникает из-за доступности переменной только для одного потока. В программах со многими потоками, пытающимися одновременно читать одну и ту же переменную (не модифицируя ее), мьютекс может серьезно снижать производительность. В этих случаях мы можем использовать QReadWriteLock — класс синхронизации, допускающий одновременный доступ для чтения без снижения производительности.
В классе Thread не имеет смысла заменять мьютекс QMutex блокировкой QReadWriteLock для защиты переменной stopped, потому что в лучшем случае только один поток может пытаться читать эту переменную в любой момент времени. Более подходящий пример мог бы состоять из одного или нескольких считывающих потоков, получающих доступ к некоторым совместно используемым данным, и одного или нескольких записывающих потоков, модифицирующих данные. Например:
01 MyData data;
02 QReadWriteLock lock;
03 void ReaderThread::run()
04 {
05 …
06 lock.lockForRead();
07 access_data_without_modifying_it(&data);
08 lock.unlock();
09 …
10 }
11 void WriterThread::run()
12 {
13 …
14 lock.lockForWrite();
15 modify_data(&data);
16 lock.unlock();
17 …
18 }
Ради удобства мы можем использовать классы QReadLocker и QWriteLocker для блокировки и разблокировки объекта QReadWriteLock.
Класс QSemaphore — это еще одно обобщение мьютекса, но, в отличие от блокировок чтения/записи, он может использоваться для контроля некоторого количества идентичных ресурсов. Следующие два фрагмента программного кода демонстрируют соответствие между QSemaphore и QMutex:
• QSemaphore semaphore(1) — QMutex mutex,
• Semaphore.acquire() — mutex.lock(),
• Semaphore.release() — mutex.unlock().
Передавая 1 конструктору, мы указываем семафору на то, что он управляет работой одного ресурса. Преимущество применения семафора заключается в том, что мы можем передавать конструктору числа, отличные от 1, и затем вызывать функцию acquire() несколько раз для захвата многих ресурсов.
Типичная область применения семафоров — это передача некоторого количества данных (DataSize) при совместном использовании циклического буфера определенного размера (BufferSize):
const int DataSize = 100000;
const int BufferSize = 4096;
char buffer[BufferSize];
Поток, являющийся поставщиком данных, записывает данные в буфер, пока он не заполнится, и затем повторяет эту процедуру сначала, переписывая существующие данные. Поток, принимающий данные, считывает данные по мере их поступления. Это проиллюстрировано на рис. 18.2 для небольшого 16-байтового буфера.
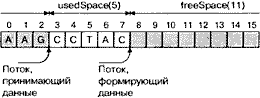
Рис. 18.2. Модель взаимодействия двух потоков: формирующего и принимающего данные.
Необходимость синхронизации для примера взаимодействия потоков, один из которых формирует данные, а другой их считывает, обусловлена двумя причинами: если формирующий данные поток работает слишком быстро, он станет переписывать данные, которые еще не считал поток—приемник; если поток—приемник считывает данные слишком быстро, он перегонит другой поток и станет считывать «мусор».
Грубый способ решения этой проблемы состоит в том, чтобы сначала заполнить буфер и затем ждать, пока поток—приемник не считает буфер целиком и так далее. Однако в многопроцессорных системах это не позволит обоим потокам работать одновременно с разными частями буфера.
Одни из эффективных способов решения этой проблемы заключается в использовании двух семафоров:
QSemaphore freeSpace(BufferSize);
QSemaphore usedSpace(0);
Семафор freeSpace управляет той частью буфера, которая может заполняться потоком, формирующим данные. Семафор usedSpace управляет той областью, которую может считывать поток—приемник. Эти две области взаимно дополняют друг друга. Семафор freeSpace устанавливается на значение переменной BufferSize (4096), то есть он может захватывать именно такое количество ресурсов. Когда приложение запускается, поток, считывающий данные, начинает захватывать «свободные» байты и превращать их в «используемые» байты. Семафор usedSpace инициализируется нулевым значением, чтобы поток—приемник не мог считать «мусор» при запуске приложения.
В этом примере каждый байт рассматривается как один ресурс. В реальном приложении мы, вероятно, использовали бы более крупные блоки памяти (например, по 64 или 256 байт) для снижения затрат, обусловленных применением семафоров.
01 void Producer::run()
02 {
03 for (int i = 0; i < DataSize; ++i) {
04 freeSpace.acquire();
05 buffer[i % BufferSize] = "ACGT"[uint(rand()) % 4];
06 usedSpace.release();
07 }
08 }
Каждая итерация при работе потока, формирующего данные, начинается с захвата одного «свободного» байта. Если весь буфер заполнен данными, которые не считаны потоком—приемником, вызов функции acquire() заблокирует семафор до тех пор, пока поток—приемник не начнет считывать данные. Захватив байт, мы заполняем его некоторым случайным значением («А», «С», «G» или «T») и затем освобождаем байт и помечаем его как «использованный», тем самым указывая на возможность его считывания потоком—приемником.
01 void Consumer::run()
02 {
03 for (int i = 0; i < DataSize; ++i) {
04 usedSpace.acquire();
05 cerr << buffer[i % BufferSize];
06 freeSpace.release();
07 }
08 cerr << endl;
09 }
Работу потока—приемника мы начинаем с захвата одного «использованного» байта. Если буфер не содержит данных для чтения, вызов функции acquire() заблокирует семафор до тех пор, пока первый поток не сформирует какие-то данные. После захвата нами байта мы выводим его на экран и освобождаем байт, помечая его как «свободный», тем самым позволяя первому потоку вновь присвоить ему некоторое значение.
01 int main()
02 {
03 Producer producer;
04 Consumer consumer;
05 producer.start();
06 consumer.start();
07 producer.wait();
08 consumer.wait();
09 return 0;
10 }
Наконец, в функции main() мы запускаем оба потока. После этого происходит следующее: поток, формирующий данные, преобразует некоторое «свободное» пространство в «использованное», после чего поток—приемник может выполнить его обратное преобразование в «свободное» пространство.
Когда программа выполняется, она выводит на консоль случайную последовательность из 100 000 букв «А», «С», «G» и «T» и затем завершает свою работу. Для того чтобы понять, что происходит на самом деле, мы можем отключить вывод указанной последовательности и вместо этого выводить на консоль букву «P» при генерации каждого байта первым потоком и букву «с» при чтении байта вторым потоком. И ради максимального упрощения ситуации мы можем использовать меньшие значения параметров DataSize и BufferSize.
Например, при выполнении программы, когда DataSize равен 10 и BufferSize равен 4, результат может быть таким: «PcPcPcPcPcPcPcPcPcPc». В данном случае поток—приемник считывает байты сразу по мере их формирования первым потоком; оба потока работают на одной скорости. В другом случае первый поток может заполнять буфер целиком еще до начала его считывания вторым потоком: «PPPPccccPPPPccccPPcc». Существует много других вариантов. Семафоры дают большую свободу действий планировщикам потоков в специфических системах, что позволяет им, изучив поведение потоков, выбрать подходящую политику планирования их работы.
Другой подход к решению проблемы синхронизации работы потока, формирующего данные, и потока, принимающего данные, состоит в применении классов QWaitCondition и QMutex. Класс QWaitCondition позволяет одному потоку «пробуждать» другие потоки, когда удовлетворяется некоторое условие. Этим обеспечивается более точное управление, чем путем применения только одних мьютексов. Чтобы показать, как это работает, мы переделаем пример с двумя потоками, используя условия ожидания.
const int DataSize = 100000;
const int BufferSize = 4096;
char buffer[BufferSize];
QWaitCondition bufferIsNotFull;
QWaitCondition bufferIsNotEmpty;
QMutex mutex;
int usedSpace = 0;
Кроме буфера мы объявляем два объекта QWaitCondition, один объект QMutex и одну переменную для хранения количества «использованных» байтов в буфере.
01 void Producer::run()
02 {
03 for (int i = 0; i < DataSize; ++i) {
04 mutex.lock();
05 while (usedSpace == BufferSize)
06 bufferIsNotFull.wait(&mutex);
07 buffer[i % BufferSize] = "ACGT"[uint(rand()) % 4];
08 ++usedSpace;
09 bufferIsNotEmpty.wakeAll();
10 mutex.unlock();
11 }
12 }
Работу потока, формирующего данные, мы начинаем с проверки заполнения буфера. Если он заполнен, мы ждем возникновения условия «буфер не заполнен». Когда это условие удовлетворяется, мы записываем один байт в буфер, увеличиваем на единицу usedSpace и возобновляем работу любого потока, ожидающего возникновения условия «буфер не пустой».
Мы используем мьютекс для контроля любого доступа к переменной usedSpace. Функция QWaitCondition::wait() может принимать в первом своем аргументе заблокированный мьютекс, который она открывает перед блокировкой текущего потока и затем вновь блокирует его перед выходом.
В этом примере мы могли бы заменить цикл while
while (usedSpace == BufferSize)
bufferIsNotFull.wait(&mutex);
на инструкцию if:
if (usedSpace == BufferSize) {
mutex.unlock();
bufferIsNotFull.wait();
mutex.lock();
}
Однако это не будет правильно работать, как только мы станем использовать несколько потоков, формирующих данные, поскольку другой такой поток может захватить мьютекс сразу же после вызова функции wait() и вновь отменить условие «буфер не заполнен».
01 void Consumer::run()
02 {
03 for (int i = 0; i < DataSize; ++i) {
04 mutex.lock();
05 while (usedSpace == 0)
06 bufferIsNotEmpty.wait(&mutex);
07 cerr << buffer[i % BufferSize];
08 --usedSpace;
09 bufferIsNotFull.wakeAll();
10 mutex.unlock();
11 }
12 cerr << endl;
13 }
Поток—приемник работает в точности наоборот относительно первого потока: он ожидает возникновения условия «буфер не пустой» и возобновляет работу любого потока, ожидающего условия «буфер не заполнен».
Во всех приводимых до сих пор примерах наши потоки имеют доступ к одинаковым глобальным переменным. Но для некоторых многопоточных приложений требуется хранить в глобальных переменных неодинаковые данные для разных потоков. Эти переменные часто называют локальной памятью потока (thread-local storage — TLS) или специальными данными потока (thread-specific data — TSD). Мы можем «схитрить» и использовать отображение, в качестве ключей которого применяются идентификаторы потоков (возвращаемые функцией QThread::currentThread()), но более привлекательное решение состоит в использовании класса QThreadStorage<T>.
Обычно класс QThreadStorage<T> используется для кэш—памяти. Имея отдельный кэш для каждого потока, мы избегаем затрат, связанных с блокировкой, разблокировкой и возможным ожиданием освобождения мьютекса. Например:
01 QThreadStorage<QHash<int, double> *> cache;
02 void insertIntoCache(int id, double value)
03 {
04 if (!cache.hasLocalData())
05 cache.setLocalData(new QHash<int, double>);
06 cache.localData()->insert(id, value);
07 }
08 void removeFromCache(int id)
09 {
10 if (cache.hasLocalData())
11 cache.localData()->remove(id);
12 }
Переменная cache содержит указатель на используемое потоком отображение QHash<int, double>. (Из-за проблем с некоторыми компиляторами тип объекта, задаваемый в шаблонном классе QThreadStorage<T>, должен быть указателем.) При применении первый раз кэша в потоке функция hasLocalData() возвращает false, и мы создаем объект типа QHash<int, double>.
Кроме кэширования класс QThreadStorage<T> может использоваться для глобальных переменных, отражающих состояние ошибки (подобных errno), чтобы модификации в одном потоке не влияли на другие потоки.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
ГЛАВА 8 Синхронизация потоков
ГЛАВА 8 Синхронизация потоков Потоки могут упрощать проектирование и реализацию программ и повышать их производительность, но их использование требует принятия мер по защите разделяемых ресурсов от попыток их изменения одновременно несколькими потоками, а также
Синхронизация куч
Синхронизация куч В NT для синхронизации доступа к кучам (глава 5) предусмотрены две функции — HeapLock и HeapUnlock. В каждой из этих функций единственным аргументом является дескриптор. Эти функции удобно применять в тех случаях, когда используется флаг HEAP_NO_SERIALIZE, или когда
Стеки потоков и допустимые количества потоков
Стеки потоков и допустимые количества потоков Следует сделать еще два предостережения. Во-первых, подумайте о размере стека, который по умолчанию составляет 1 Мбайт. В большинстве случаев этого будет вполне достаточно, но если существуют какие-либо сомнения на сей счет,
Синхронизация и параллелизм
Синхронизация и параллелизм Ядро подвержено состояниям конкуренции за ресурсы (race condition). В отличие от однопоточной пользовательской программы, ряд свойств ядра позволяет осуществлять параллельные обращения к ресурсам общего доступа, и поэтому требуется выполнять
Синхронизация
Синхронизация Иногда очень сложно отказаться от работы со старыми программами. По разным причинам – многие «прикипели» к интерфейсу любимого электронного календаря, где-то та или иная программа является корпоративным стандартом… Но это совсем не значит, что от
Синхронизация
Синхронизация Для того чтобы фотографии любого вашего альбома прямо из Picasa появились в Интернете на сервисе Picasa Web Albums, необходимо совершить всего два простых действия. Во-первых, щелкнуть на ссылке «Веб-альбомы» над строкой поиска и ввести данные своей учетной записи
11.2.7. Синхронизация файлов
11.2.7. Синхронизация файлов Когда программа пишет данные в файл, обычно они сохраняются в кэше ядра до тех пор, пока оно не выполнит запись на физический носитель (такой как жесткий диск), но ядро возвращает управление программе сразу после того, как данные скопируются в кэш.
1 Синхронизация данных
1 Синхронизация данных Итак, определимся. Вы перспективный работник успевающей компании. Вам необходимо всегда иметь при себе самые последние версии каких-то документов. Вам часто приходится изменять документы, причем на разных компьютерах. И все это вы обязаны делать
Синхронизация потоков
Синхронизация потоков Обычным требованием для многопоточных приложений является синхронизация работы нескольких потоков. Для этого в Qt предусмотрены следующие классы: QMutex, QReadWriteLock, QSemaphore и QWaitCondition.Класс QMutex обеспечивает такую защиту переменной или участка
А.5. Синхронизация потоков: программы
А.5. Синхронизация потоков: программы Для измерения времени, уходящего на синхронизацию при использовании различных средств, мы создаем некоторое количество потоков (от одного до пяти, согласно табл. А.4 и А.5), каждый из которых увеличивает счетчик в разделяемой памяти
А.6. Синхронизация процессов: программы
А.6. Синхронизация процессов: программы В программах предыдущего раздела счетчик использовался несколькими потоками одного процесса. При этом он представлял собой глобальную переменную. Теперь нам нужно изменить эти программы для измерения скорости синхронизации
Синхронизация вызывающего потока
Синхронизация вызывающего потока Для текущей реализации Main() диапазон времени между вызовом BeginInvoke() и вызовом EndInvoke() явно меньше пяти секунд. Поэтому после вывода на консоль сообщения "В Main() еще есть работа!" поток вызова блокируется и ждет завершения существования
4.4. Синхронизация потоков и критические секции
4.4. Синхронизация потоков и критические секции Программирование потоков — нетривиальная задача, ведь большинство потоков выполняется одновременно. К примеру, невозможно определить, когда система предоставит доступ к процессору одному потоку, а когда — другому.
Синхронизация данных
Синхронизация данных Последствий большинства операций, приводящих к потере данных (случайное или намеренное удаление, форматирование или выход из строя накопителя), обычно можно избежать с помощью резервного копирования. Однако это не единственная опасность,
Синхронизация
Синхронизация При совместном использовании нескольких различных устройств важно обеспечить их полную синхронизацию. Работа всего оборудования должна опираться на одинаковую информацию о времени, а обслуживающие программы – уметь работать с разнообразными типами