Чтение документов XML при помощи интерфейса DOM
Чтение документов XML при помощи интерфейса DOM
DOM является стандартным программным интерфейсом синтаксического анализа документов XML, который разработан Консорциумом всемирной паутины (W3C). Qt обеспечивает уровень 2 интерфейса DOM для чтения, обработки и записи документов XML без проверки их достоверности.
DOM представляет файл XML в памяти в виде дерева. Мы можем просматривать дерево DOM столько раз, сколько нам нужно, и мы можем модифицировать и записывать его на диск в виде файла XML.
Давайте рассмотрим следующий документ XML:
<doc>
<quote>Ars longa vita brevis</quote>
<translation>Art is long, life is short</translation>
</doc>
Ему соответствует следующее дерево DOM:

Дерево DOM содержит узлы разных типов. Например, узел Element соответствует открывающему тегу и связанному с ним закрывающему тегу. Все, что располагается между этими тегами, представляется в виде дочерних узлов данного элемента Element.
В Qt различные типы таких узлов (как и все другие связанные с DOM классы) имеют префикс QDom. Так, QDomElement представляет узел Element, a QDomText представляет узел Text.
Различные узлы могут иметь дочерние узлы разных типов. Например, узел Element может содержать другие узлы Element, а также узлы EntityReference, Text, CDATASection, ProcessingInstruction и Comment. Рис. 15.3 показывает, какие типы дочерних узлов допустимы для соответствующих родительских узлов. Узлы, показанные серым, не могут иметь дочерних узлов.
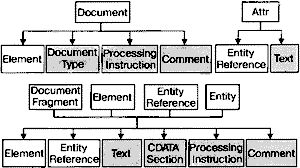
Рис. 15.3. Родственные связи между узлами DOM.
Для иллюстрации применения DOM при чтении файлов XML мы напишем парсер для файла предметного указателя книги, описанного в предыдущем разделе.
01 class DomParser
02 {
03 public:
04 DomParser(QIODevice *device, QTreeWidget *tree);
05 private:
06 void parseEntry(const QDomElement &element,
07 QTreeWidgetItem *parent);
08 QTreeWidget *treeWidget;
09 };
Мы определяем класс с названием DomParser, который выполняет синтаксический анализ предметного указателя книги, представленного в виде документа XML, и отображает результат в виджете QTreeWidget. Этот класс не наследует никакой другой класс.
01 DomParser::DomParser(QIODevice *device, QTreeWidget *tree)
02 {
03 treeWidget = tree;
04 QString errorStr;
05 int errorLine;
06 int errorColumn;
07 QDomDocument doc;
08 if (!doc.setContent(device, true, &errorStr,
09 &errorLine, &errorColumn)) {
10 QMessageBox::warning(0, QObject::tr("DOM Parser"),
11 QObject::tr("Parse error at line %1, column %2: %3")
12 .arg(errorLine).arg(errorColumn).arg(errorStr));
13 return;
14 }
15 QDomElement root = doc.documentElement();
16 if (root.tagName() != "bookindex")
17 return;
18 QDomNode node = root.firstChild();
19 while (!node.isNull()) {
20 if (node.toElement().tagName() == "entry")
21 parseEntry(node.toElement(), 0);
22 node = node.nextSibling();
23 }
24 }
В конструкторе мы создаем объект QDomDocument и вызываем для него функцию setContent(), чтобы с его помощью прочесть документ XML с устройства QIODevice. Функция setContent() автоматически открывает устройство, если оно еще не открыто. Затем мы вызываем функцию documentElement() для объекта QDomDocument, чтобы получить его одиночный дочерний элемент QDomElement, после чего мы проверяем, является ли данный элемент <bookindex>. Мы выполняем цикл по всем дочерним узлам, и если узлом является элемент <entry>, мы вызываем функцию parseEntry() для его синтаксического анализа.
Класс QDomNode может хранить узлы любого типа. Если мы хотим продолжить обработку узла, мы должны сначала преобразовать его в правильный тип данных. В нашем примере нас интересуют только узлы Element, и поэтому мы вызываем функцию toElement() объекта QDomNode для преобразования его в объект QDomElement и затем вызова функции tagName() для получения имени тега элемента. Если данный узел не имеет тип Element, функция toElement() возвращает нулевой объект типа QDomElement, содержащий пустое имя тега.
01 void DomParser::parseEntry(const QDomElement &element,
02 QTreeWidgetItem *parent)
03 {
04 QTreeWidgetItem *item;
05 if (parent) {
06 item = new QTreeWidgetTtem(parent);
07 } else {
08 item = new QTreeWidgetItem(treeWidget);
09 }
10 item->setText(0, element.attribute("term"));
11 QDomNode node = element.firstChild();
12 while (!node.isNull()) {
13 if (node.toElement().tagName() == "entry") {
14 parseEntry(node.toElement(), item);
15 } else if (node.toElement().tagName() == "page") {
16 QDomNode childNode = node.firstChild();
17 while (!childNode.isNull()) {
18 if (childNode.nodeType() == QDomNode::TextNode) {
19 QString page = childNode.toText().data();
20 QString allPages = item->text(1);
21 if (!allPages.isEmpty())
22 allPages += ", ";
23 allPages += page;
24 item->setText(1, allPages);
25 break;
26 }
27 childNode = childNode.nextSibling();
28 }
29 }
30 node = node.nextSibling();
31 }
32 }
В функции parseEntry() мы создаем элемент объекта QTreeWidget. Если тег вложен в другой <entry>, новый тег определяет подэлемент предметного указателя, и мы создаем элемент QTreeWidgetItem как дочерний для внешнего элемента QTreeWidgetItem. В противном случае мы создаем элемент QTreeWidgetItem с treeWidget в качестве его родительского элемента, делая его элементом верхнего уровня. Мы вызываем функцию setText() для установки текста столбца 0 на значение атрибута term тега <entry>.
После инициализации нами элемента QTreeWidgetItem мы выполняем цикл по дочерним узлам элемента QDomElement, который соответствует текущему тегу <entry>.
Если элементом является <entry>, мы вызываем функцию parseEntry(), передавая текущий элемент в качестве второго аргумента. Затем будет создан новый элемент QTreeWidgetItem, в качестве родительского элемента которого выступает внешний элемент QTreeWidgetItem.
Если элементом является <page>, мы просматриваем список дочерних элементов для поиска узла Text. После его обнаружения мы вызываем функцию toText() для преобразования его в объект типа QDomText и функцию data() для получения текста в виде строки типа QString. Затем мы добавляем текст в разделяемый запятыми список номеров страниц в столбце 1 элемента QTreeWidgetItem.
Давайте теперь посмотрим, как мы можем использовать класс DomParser для синтаксического анализа файла:
01 void parseFile(const QString &fileName)
02 {
03 QStringList labels;
04 labels << QObject::tr("Terms") << QObject::tr("Pages");
05 QTreeWidget *treeWidget = new QTreeWidget;
06 treeWidget->setHeaderLabels(labels);
07 treeWidget->setWindowTitle(QObject::tr("DOM Parser"));
08 treeWidget->show();
09 QFile file(fileName);
10 DomParser(&file, treeWidget);
11 }
Мы начинаем с настройки QTreeWidget. Затем мы создаем объекты QFile и DomParser. При выполнении конструктора DomParser осуществляется синтаксический анализ файла и пополняется виджет дерева.
Как и в предыдущем примере, для сборки приложения с библиотекой QtXml в файл .pro необходимо добавить следующую строку:
QT += xml
Как показывает наш пример, проход по дереву DOM может быть достаточно непростым делом. Простая операция по извлечению текста между тегами <page> и </page> требует обработки в цикле элементов списка при помощи функций firstChild() и nextSibling() класса QDomNode. Программисты, которым очень часто приходится использовать интерфейс DOM, создают свои собственные высокоуровневые функции—оболочки для упрощения выполнения таких наиболее распространенных операций, как извлечение текста между открывающими и закрывающими тегами.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Преобразование документов XML при помощи браузеров
Преобразование документов XML при помощи браузеров Поддержка XSLT включена и в Microsoft Internet Explorer, и в Netscape Navigator. Из этих двух браузеров Internet Explorer обладает гораздо большей поддержкой XSLT, и здесь я буду использовать версию 5.5 этого браузера. О поддержке XSLT в Internet Explorer вы можете
Преобразование документов XML при помощи Internet Explorer
Преобразование документов XML при помощи Internet Explorer В нашем обзоре таблиц стилей есть еще одна тема для обсуждения: как использовать таблицы стилей в Internet Explorer. Как мы видели в главе 1, для считывания документов XML и XSL можно использовать JavaScript, и осуществлять преобразование
Отправка писем при помощи PHP
Отправка писем при помощи PHP Отправка писем при помощи PHPРано или поздно каждый владелец сайта сталкивается с необходимостью отправки писем непосредственно с сайта через скрипт, а не через почтовые программы. Это могут быть письма, отправляемые скриптом гостевой книги,
Соединение при помощи OptiConnect
Соединение при помощи OptiConnect Если компьютер работает не в сети, и сами данные, и средства их обработки располагаются на нем самом. Одиночная система AS/400 поддерживает очень большие, в том числе многопроцессорные, конфигурации, что вполне удовлетворяет нужды большинства
6.3. Получение помощи
6.3. Получение помощи При работе с программой Midnight Commander практически в любой момент можно обратиться к интерактивной подсказке, вызов которой осуществляется нажатием клавиши ‹F1›. Подсказка организована как гипертекст, т. е. в ее тексте встречаются гипертекстовые ссылки
Получение помощи
Получение помощи Мы очень старались сделать информацию в этой книге и на прилагающемся к ней компакт-диске максимально точной. Если у вас возникнут проблемы, обратитесь за помощью к указанным ниже
Раздел помощи
Раздел помощи Очень важно, чтобы на сайте был выделен раздел помощи на главной странице и человек знал, что он может посмотреть ответы на типичные вопросы или задать собственный. Это сильно повышает
Рисование при помощи QPainter
Рисование при помощи QPainter Чтобы начать рисовать на устройстве рисования (обычно это виджет), мы просто создаем объект QPainter и передаем ему указатель на устройство. Например:void MyWidget::paintEvent(QPaintEvent *event) { QPainter painter(this); …}Мы можем рисовать различные фигуры, используя функции
Чтение документов XML при помощи интерфейса DOM
Чтение документов XML при помощи интерфейса DOM DOM является стандартным программным интерфейсом синтаксического анализа документов XML, который разработан Консорциумом всемирной паутины (W3C). Qt обеспечивает уровень 2 интерфейса DOM для чтения, обработки и записи документов XML
При помощи сетки
При помощи сетки Если требуется конструировать на плоскостях, отличных от основных сеток, или использовать одну и ту же плоскость во всех окнах проекций, то удобно применять объект Grid (Координатная сетка). Объекты сетки весьма полезны при увеличении сложности модели и
Создание документов при помощи шаблонов
Создание документов при помощи шаблонов Еще один способ упрощения процедуры форматирования – применение шаблонов. В отличие от стиля, кроме видов форматирования, шаблон обычно включает в себя определенные участки текста, которые пользователь просто дополняет своими
Система помощи
Система помощи Вместе с программой ArchiCAD поставляется система интерактивной контекстно зависимой помощи, предназначенная для получения пользователем оперативной справочной информации. Контекстно зависимой принято называть информацию, связанную с активным
Аутентификация при помощи сертификатов
Аутентификация при помощи сертификатов В том случае, когда пользователи имеют сертификаты открытых ключей, необходимость в ЦРК отпадает. Это не означает, что отпадает необходимость в доверии и третьих сторонах; просто доверенной третьей стороной становится УЦ. Однако