Несколько примеров
Несколько примеров
Рассмотрим теперь несколько примеров применения каждого метода.
Режим с управлением по запросу (send-driven) — модель «клиент/сервер»
Файловая система, последовательные порты, консоли и звуковые платы — все это примеры применения модели «клиент/сервер». Прикладная программа на языке Си берет на себя роль клиента и посылает запросы этим серверам. Серверы выполняют работу и отвечают клиентам.
Некоторые из этих «обычных» серверов, однако, в действительности могут быть серверами, управляемыми по ответу (reply-driven)! Это возможно, например, в случае, когда по отношению к конечному клиенту они выглядят как стандартные серверы, а вот работу выполняют по методике «сервер/ субсервер». То есть я имею в виду, что клиент по-прежнему посылает сообщение тому, кого считает «серверным процессом», а тот просто передает работу другому процессу (субсерверу).
Режим с управлением по ответу (reply-driven) — модель «сервер/субсервер»
Один из наиболее популярных примеров программы, управляемой по ответу (reply-driven), — это программа фрактальной графики, распределенная по сети. Ведущая программа делит экран на несколько зон — например, на 64 зоны. При старте ведущей программе задается список узлов, которые могут участвовать в работе. Затем ведущая программа запускает рабочие программы (субсерверы), по одной на каждый узел, и ждет от них сообщений.
Затем ведущая программа по очереди берет «незаполненные» зоны (из имеющихся 64) и передает задачу фрактальных вычислений программе-исполнителю на другом узле, отвечая ей на ее сообщение. Когда рабочая программа завершит вычисления, она посылает результаты обратно ведущей, которая выводит их на экран.
Поскольку программа-исполнитель передала результаты ведущей программе путем отправки ей сообщения, она теперь снова готова получить от нее ответ с новым заданием. Ведущая программа так и делает до тех пор, пока все 64 зоны на экране не будут заполнены.
Важная тонкость
Поскольку ведущая программа отвечает за распределение работы между программами-исполнителям, она не может себе позволить быть заблокированной! При традиционном подходе с управлением по запросу (send-driven) ведущая программа должна была бы создать программу-исполнителя и послать ей сообщение. К сожалению, при этом ведущая программа не сможет получить ответ до тех пор, пока программа-исполнитель не выполнит свою работу, а значит, не сможет и передать сообщение другой программе-исполнителю. Это сразу сводит на нет все преимущества наличия нескольких рабочих программ на разных узлах.
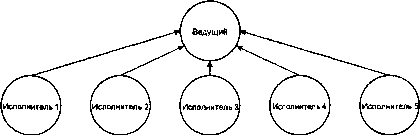
Один ведущий, несколько исполнителей
Решение этой проблемы заключается в том, чтобы исполнители при старте запросили ведущего, есть ли для них работа, послав ему сообщение. Напомним еще раз, что направление стрелок на рисунке указывает направление передачи. Теперь исполнители ждут ответа от ведущего. Когда какой-нибудь клиент «заказывает работу» ведущему, тот отвечает одному или более из исполнителей, что указывает им выйти из ожидания и начать выполнение. Это позволяет исполнителям заботиться о своих делах самостоятельно, а ведущий сохраняет возможность отвечать на новые запросы, поскольку не блокируется в ожидании ответа от исполнителей.
Многопоточный сервер
С позиции клиента многопоточные серверы неотличимы от однопоточных. Фактически, разработчик сервера может запросто «включить многопоточность», запустив еще один или несколько потоков.
В любом случае, сервер может по-прежнему использовать несколько процессоров в SMP-системе, даже если «клиент» у него только один.
Что это означает? Давайте вернемся к примеру о фрактальной графике. Когда субсервер получает от сервера запрос на «вычисления», ему ничто не мешает запустить несколько потоков и начать обработку данного запроса на нескольких процессорах сразу. На самом деле, чтобы приложение лучше масштабировалось в сетях, в которых есть как мультипроцессоры SMP, так и однопроцессорные машины, сервер и субсервер могут сначала обменяться информацией о том, сколько у субсервера имеется в распоряжении процессоров. Это даст серверу знать, сколько запросов субсервер может обслужить одновременно. Тогда сервер сможет перенаправлять многопроцессорным субсерверам больше запросов, чем однопроцессорным, равномерно распределяя нагрузку между вычислительными мощностями.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
ПРИЛОЖЕНИЕ А Использование примеров программ
ПРИЛОЖЕНИЕ А Использование примеров программ На Web-сайте книги (http://www.awprofessional.com/titles/0321256190) находится zip-архив, который содержит исходные тексты всех примеров программ, а также соответствующие заголовочные файлы, служебные функции, файлы проектов и исполняемые файлы. Ряд
17.4.4. Запуск примеров домена Unix
17.4.4. Запуск примеров домена Unix Две предыдущие программы-примера (серверная и клиентская) сконструированы для совместной работы. Запустите сервер с одного терминала, после этого активизируйте клиента из другого терминала (но в том же самом каталоге). При вводе строк в
Скрытие и открытие текста примеров
Скрытие и открытие текста примеров На Web-страницах, описывающих теги HTML и атрибуты стиля CSS, мы поместили текст примеров применения того или иного тега или атрибута стиля. Часто его делают скрывающимся и открывающимся в ответ на щелчок мышью — так можно сделать Web-страницы
1.6. Таблица соответствия примеров технологии клиент-сервер
1.6. Таблица соответствия примеров технологии клиент-сервер Технологии сетевого программирования иллюстрируются в этой книге на двух основных примерах:? клиент-сервер времени и даты (описание которого мы начали в листингах 1.1, 1.2 и 1.5), и? эхо-клиент-сервер (который
4.3.5. Несколько замечаний
4.3.5. Несколько замечаний Для полного понимания процесса создания учетных записей нам нужно познакомиться еще с файлом /etc/login.defs. В нем хранятся настройки, которые будут использоваться при добавлении пользователей. Содержимое файла можно увидеть в листинге 4.1.Листинг 4.1.
Скрытие и открытие текста примеров
Скрытие и открытие текста примеров На Web-страницах, описывающих теги HTML и атрибуты стиля CSS, мы поместили текст примеров применения того или иного тега или атрибута стиля. Часто его делают скрывающимся и открывающимся в ответ на щелчок мышью — так можно сделать Web-страницы
18.8.5 Несколько примеров настройки выхода в сеть
18.8.5 Несколько примеров настройки выхода в сеть Пример 1. Подключение к существующей локальной сети в варианте "Bridged networking"Рассмотрим сначала простейший случай, когда базовый компьютер, работающий под Linux, уже подключен к реальной физической сети. Кроме того, на базовом
ГЛАВА 7. ЕЩЕ НЕСКОЛЬКО ПРИМЕРОВ ПРОГРАММ
ГЛАВА 7. ЕЩЕ НЕСКОЛЬКО ПРИМЕРОВ ПРОГРАММ В каждом разделе этой главы рассматривается некоторое конкретное применение Пролога. Мы советуем вам прочитать все разделы. Не огорчайтесь, если вы не поймете назначение какой-либо программы потому, что незнакомы с данной
10.10. Несколько производителей, несколько потребителей
10.10. Несколько производителей, несколько потребителей Следующее изменение, которое мы внесем в нашу пpoгрaммy, будет заключаться в добавлении возможности одновременной работы нескольких потребителей вместе с несколькими производителями. Есть ли смысл в наличии
10.11. Несколько буферов
10.11. Несколько буферов Во многих программах, обрабатывающих какие-либо данные, можно встретить цикл видаwhile ((n = read(fdin, buff, BUFFSIZE)) > 0) { /* обработка данных */ write(fdout, buff, n);}Например, программы, обрабатывающие текстовые файлы, считывают строку из входного файла, выполняют с ней
Multiple (Несколько)
Multiple (Несколько) Программа AutoCAD выполняет полное сканирование экрана каждый раз, когда происходит выделение объекта. Режим Multiple (Несколько) позволяет выделить несколько объектов без задержки, и при нажатии клавиши Enter все точки будут выбраны за одно сканирование
3.14.9. Еще несколько образцов
3.14.9. Еще несколько образцов Завершим наш список несколькими выражениями из категории «разное». Как обычно, почти все эти задачи можно решить несколькими способами.Пусть нужно распознать двузначный почтовый код американского штата. Проще всего, конечно, взять выражение
Исходный код примеров книги
Исходный код примеров книги Программный код всех примеров из этой книги (с точностью до встречающихся кое-где небольших фрагментов) доступен для загрузки из раздела исходного кода Web-узда издательства. Выполнив поиск по названию книги, перейдите на ее "домашнюю" страницу,
Пример 16-10. Файл с именами "names.data", для примеров выше
Пример 16-10. Файл с именами "names.data", для примеров выше AristotleBelisariusCapablancaEulerGoetheHamurabiJonahLaplaceMaroczyPurcellSchmidtSemmelweissSmithTuringVennWilsonZnosko-Borowski# Это файл с именами для примеров#+ "redir2.sh", "redir3.sh", "redir4.sh", "redir4a.sh", "redir5.sh".Перенаправление stdout для блока кода, может использоваться для сохранения
Подход третий: Несколько product owner’ов - несколько backlog’ов
Подход третий: Несколько product owner’ов - несколько backlog’ов Похоже на второй вариант, по отдельному product backlog на команду, только ещё и с отдельным product owner’ом на каждую команду. Мы не пробовали так делать, и, скорее всего, пробовать не будем.Если два product backlog’а касаются одного и