Устройство слябового распределителя памяти
Устройство слябового распределителя памяти
Уровень слябового распределения памяти делит объекты на группы, которые называются кэшами (cache). Разные кэши используются для хранения объектов различных типов. Для каждого типа объектов существует свой уникальный кэш. Например, один кэш используется для дескрипторов процессов (список свободных структур struct task_struct), а другой — для индексов файловых систем (struct inode). Интересно, что интерфейс kmalloc() построен на базе уровня слябового распределения памяти и использует семейство кэшей общего назначения.
Далее кэши делятся на слябы (буквально slab — однородная плитка, отсюда и название всей подсистемы). Слябы занимают одну или несколько физически смежных страниц памяти. Обычно сляб занимает только одну страницу памяти. Каждый кэш может содержать несколько слябов.
Каждый сляб содержит некоторое количество объектов, которые представляют собой кэшируемые структуры данных. Каждый сляб может быть в одном из трех состояний: полный (full), частично заполненный (partial) и пустой (empty). Полный сляб не содержит свободных объектов (все объекты сляба выделены для использования). Частично заполненный сляб содержит часть выделенных и часть свободных объектов. Когда некоторая часть ядра запрашивает новый объект, то этот запрос удовлетворяется из частично заполненного сляба, если такой существует. В противном случае запрос выполняется из пустого сляба. Если пустого сляба не существует, то он создается. Очевидно, что полный сляб никогда не может удовлетворить запрос, поскольку в нем нет свободных объектов. Такая политика уменьшает фрагментацию памяти.
В качестве примера рассмотрим структуры inode, которые являются представлением в оперативной памяти индексов дисковых файлов (см. главу 12). Эти структуры часто создаются и удаляются, поэтому есть смысл управлять ими с помощью слябового распределителя памяти. Структуры struct inode выделяются из кэша inode_cachep (такое соглашение по присваиванию названий является стандартом). Этот кэш состоит из одного или более слябов, скорее всего слябов много, поскольку много объектов. Каждый сляб содержит максимально возможное количество объектов типа struct inode. Когда ядро выделяет новую структуру типа struct inode, возвращается указатель на уже выделенную, но не используемую структуру из частично заполненного сляба или, если такого нет, из пустого сляба. Когда ядру больше не нужен объект типа inode, то слябовый распределитель памяти помечает этот объект как свободный. На рис. 11.1 показана диаграмма взаимоотношений между кэшами, слябами и объектами.
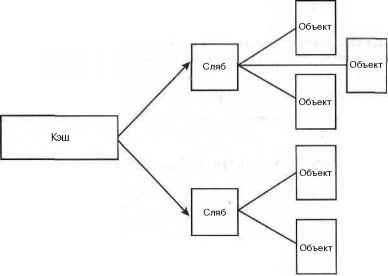
Рис. 11.1. Взаимоотношения между кэшами, слябами и объектами
Каждый кэш представляется структурой kmem_cache_s. Эта структура содержит три списка slab_full, slab_partial и slab_empty, которые хранятся в структуре kmem_list3. Эти списки содержат все слябы, связанные с данным кэшем. Каждый сляб представлен следующей структурой struct slab, которая является дескриптором сляба.
struct slab {
struct list head list; /* список полных, частично заполненных
или пустых слябов */
unsigned long colouroff; /* смещение для окрашивания слябов */
void *s_mem; /* первый объект сляба */
unsigned int inuse; /* количество выделенных объектов */
kmem_bufctl_tfree; /* первый свободный объект, если есть */
};
Дескриптор сляба выделяется или за пределами сляба, в кэше общего назначения, или в начале самого сляба. Дескриптор хранится внутри сляба, либо если общий размер сляба достаточно мал, либо если внутри самого сляба остается достаточно места, чтобы разместить дескриптор.
Слябовый распределитель создает новые слябы, вызывая интерфейс ядра нижнего уровня для выделения памяти __get_free_pages() следующим образом.
static void *kmem_getpages(kmem_cache_t *cachep,
int flags, int nodeid) {
struct page *page;
void *addr;
int i;
flags |= cachep->gfpflags;
if (likely(nodeid == -1)) {
addr = (void*)__get_free_pages(flags, cachep->gfporder);
if (!addr)
return NULL;
page = virt_to_page(addr);
} else {
page = alloc_pages_node(nodeid, flags, cachep->gfporder);
if (!page)
return NULL;
addr = page_address(page);
}
i = (1 << cachep->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_add(i, &slab_reclaim_pages);
add_page_state(nr_slab, i);
while (i-- ) {
SetPageSlab(page);
page++;
}
return addr;
}
Первый параметр этой функции указывает на определенный кэш, для которого нужны новые страницы памяти. Второй параметр содержит флаги, которые предаются в функцию __get_free_pages(). Следует обратить внимание на то, как значения этих флагов объединяются с другими значениями с помощью логической операции ИЛИ. Данная операция дополняет флаги значением флагов кэша, которые используются по умолчанию и которые обязательно должны присутствовать n значении параметра flags. Количество страниц памяти — целая степень двойки — хранится в поле cachep->gfporder. Рассмотренная функция выглядит более сложной, чем это может показаться сначала, поскольку она также рассчитана на NUMA-системы (Non-Uniform Memory Access, системы с неоднородным доступом к памяти). Если параметр nodeid на равен -1, то предпринимается попытка выделить память с того же узла памяти, на котором выполняется запрос. Такое решение позволяет получить более высокую производительность для NUMA-систем. Для таких систем обращение к памяти других узлов приводит к снижению производительности.
Для образовательных целей можно убрать код, рассчитанный на NUMA-системы, и получить более простой вариант функции kmem_getpages() в следующем виде.
static inline void* kmem_getpages(kmem_cache_t *cachep,
unsigned long flags) {
void *addr;
flags |= cachep->gfpflags;
addr = (void*)__get_free_pages(flags, cachep->gfporder);
return addr;
}
Память освобождается с помощью функции kmem_freepages(), которая вызывает функцию free_pages() для освобождения необходимых страниц кэша. Конечно, назначение уровня слябового распределения — это воздержаться от выделения и освобождения страниц памяти. На самом деле слябовый распределитель использует функции выделения памяти только тогда, когда в данном кэше не доступен ни один частично заполненный или пустой сляб. Функция освобождения памяти вызывается только тогда, когда становится мало доступной памяти и система пытается освободить память или когда кэш полностью ликвидируется.
Уровень слябового распределения управляется с помощью простого интерфейса, и это можно делать отдельно для каждого кэша. Интерфейс позволяет создавать или ликвидировать новые кэши, а также выделять или уничтожать объекты в этих кэшах. Все механизмы оптимизации управления кэшами и слябами полностью управляются внутренними элементами уровня слябового распределения памяти. После того как кэш создан, слябовый распределитель памяти работает, как специализированная система создания объектов определенного типа.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
2. Устройство HTML5
2. Устройство HTML5 Эпоха Великой французской революции стала временем огромных политических и социальных перемен. Революционному пылу было подвластно и само время. На короткий период Французская республика ввела десятичную систему измерения времени: каждый день
Уровень слябового распределителя памяти
Уровень слябового распределителя памяти Выделение и освобождение структур данных — это одна из наиболее частых операций, которые выполняются в любом ядре. Для того чтобы облегчить процедуру частого выделения и освобождения данных при программировании, вводятся списки
Интерфейс слябового распределителя памяти
Интерфейс слябового распределителя памяти Новый кэш можно создать с помощью вызова следующей функции.kmem_cache_t * kmem_cache_create(const char *name, size_t size, size_t offset, unsigned long flags,void (*ctor)(void*, kmem_cache_t*, unsigned long),void (*dtor)(void*, kmem_cache_t*, unsigned long));Первый параметр — это строка, которая содержит имя кэша.
Пример использования слябового распределителя памяти
Пример использования слябового распределителя памяти Давайте рассмотрим пример из реальной жизни, связанный с работой со структурами task_struct (дескрипторы процессов). Показанный ниже код в несколько более сложной форме приведен в файле kernel/fork.c.В ядре определена
Глава 7 Постороннее устройство
Глава 7 Постороннее устройство Генри Таттл значительную часть своей жизни провел на посту президента Hush-A-Phone Corporation, производящей устройства для приглушения голоса во время телефонных разговоров. Помимо Таттла, в штате компании числился лишь секретарь. Оба они работали в
Устройство блогов
Устройство блогов На наш взгляд, для понимания социальных сетей, блогов и другого интернет-контента (информационного наполнения), формируемого самими людьми без посредников, логично обратиться к мнению членов интернет-сообщества, в частности к Википедии. В англоязычной
Устройство форума
Устройство форума Каждый новый раздел форума называется веткой, в которой идет обсуждение конкретных вопросов-тем, называемых то?пиками (от англ. topic — тема). Реплика участника форума, поданная им в топике, называется по?стом.На форуме, как правило, имеется свой хозяин,
Устройство ввода-вывода
Устройство ввода-вывода Вообще говоря, существует много способов ведения диалога человека с ЭВМ, но мы будем предполагать, что вы вводите команды при помощи клавиатуры и читаете ответ на экране
Внутреннее устройство Pocket PC
Внутреннее устройство Pocket PC Если не брать в расчет сам факт миниатюрности и отсутствие некоторых привычных на настольном ПК устройств, таких как клавиатура и мышь, то можно считать, что Pocket PC является полноценным компьютером. Мало того, по своим параметрам он является
Координатное устройство
Координатное устройство В современных ноутбуках встречается два вида координатных устройств: сенсорная панель Touchpad и мини-джойстик Trackpoint. Некоторые производители устанавливают в ноутбуки оба эти устройства, предоставляя пользователю возможность работать с тем, с
Устройство жидкокристаллических мониторов
Устройство жидкокристаллических мониторов Если вы не совсем твердо представляете себе, что такое жидкие кристаллы, посмотрите на калькулятор. Он оснащен именно жидкокристаллическим дисплеем. Электронные часы, в которых не стрелки бегают по кругу, а меняются циферки,
Устройство жестких дисков
Устройство жестких дисков Жесткий диск – один из наиболее сложно устроенных компонентов компьютера, хотя принцип его работы достаточно прост: на вращающихся пластинах, покрытых магнитным слоем, записываются концентрические дорожки. Сложности возникают, когда принцип
Принцип работы и устройство flash-памяти
Принцип работы и устройство flash-памяти В основе любой flash-памяти лежит кристалл кремния, на котором сформированы не совсем обычные полевые транзисторы. У такого транзистора есть два изолированных затвора: управляющий (control) и плавающий (floating). Последний способен