Модель XML-документа
Модель XML-документа
Описывая основы построения XML-документов, мы отмечали, что иерархическая организация информации в XML лучше всего описывается древовидными структурами. Дерево — это четкая, мощная и простая модель данных и именно она была на концептуальном уровне применена в языках XSLT и XPath. Как пишет Кнут [Кнут 2000], "деревья — это наиболее важные нелинейные структуры, которые встречаются при работе с компьютерными алгоритмами". Добавим, что это без сомнения самая важная структура из тех, которыми оперируют языки XSLT и XPath.
В этих языках документ моделируется как дерево, состоящее из узлов. Узлы дерева соответствуют структурным единицам XML — элементам, атрибутам, тексту и так далее, а дуги, ветки — отношениям между этими единицами. Простейшим примером является принадлежность одних элементов другим. Документ вида
<а>
<b/>
<с/>
</а>
может быть представлен деревом (рис. 3.1).
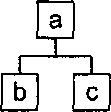
Рис. 3.1. Представление документа в виде дерева
Аналогия совершенно очевидна — элемент а содержит элементы b и с, в то время как в дереве вершина а является родительским узлом для вершин b и с.
Естественно, XML-документы состоят далеко не из одних только элементов и потому для того, чтобы дерево достоверно отражало структуру и содержание документа, в нем выделяются узлы следующих семи типов:
? корневой узел;
? узлы элементов;
? узлы атрибутов;
? текстовые узлы;
? узлы пространств имен;
? узлы инструкций по обработке;
? узлы комментариев.
Каждый узел дерева имеет соответствующее ему строковое значение, которое вычисляется в зависимости от типа. Строковым значением корневого узла и узла элемента является конкатенация (строковое сложение) строковых значений всех их потомков, для остальных типов узлов строковое значение является частью самого узла. Порядок вычисления строковых значений узлов будет более детально определен в описании каждого из типов.
Мы подробно разберем каждый из типов узлов чуть позже, а пока отметим, что дерево в XSLT и XPath является чисто концептуальной моделью. Процессоры не обязаны внутренне представлять документы именно в этой структуре, концептуальная модель означает лишь то, что все операции преобразования над документами будут определяться в терминах деревьев. Для программиста же это означает, что вовсе необязательно вникать в тонкости реализации преобразований в том или ином процессоре. Все равно они должны работать, так, как будто они работают непосредственно с деревьями.
Отметим также и то, что на практике некоторые из процессоров вообще не воссоздают внутреннюю модель документа, экономя, таким образом, ресурсы. Документы могут быть слишком объемными, и это препятствует загрузке их в память в виде древовидной структуры.
Некоторые из процессоров, напротив, используют DOM-модель документа для внутреннего представления обрабатываемой информации. Несмотря на большие требования к ресурсам памяти, такое решение также может иметь свои плюсы, например, универсальность и легкая интеграция в существующие XML-решения на базе DOM.
Но, так или иначе, с воссозданием древовидной структуры документа в памяти или нет, процессоры все равно оперируют одной и той же концептуальной моделью, которой мы сейчас и займемся.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
10.4. Объектная модель документа (DOM)
10.4. Объектная модель документа (DOM) Стандартный набор объектов в HTML-документе, их свойства и способ доступа к ним определяется объектной моделью документа (Document Object Model, сокращенно DOM). DOM позволяет управлять всеми элементами на веб-странице, изменять их свойства и
Объекты Web-обозревателя. Объектная модель документа DOM
Объекты Web-обозревателя. Объектная модель документа DOM Объекты, предоставляемые Web-обозревателем, делятся на две группы:— объекты, представляющие Web-страницу и элементы, созданные с помощью разных тегов (абзац, заголовок, таблица, изображение и др.);— объекты,
Объектная модель документа
Объектная модель документа Надо отметить, что JavaScript поддерживает так называемые внешние классы и объекты, определенные другими программами.Web-страница, которую вы просматриваете в окне Web-обозревателя, может быть описана как набор объектов. Скажем, она включает большой
1.7. Модель OSI
1.7. Модель OSI Распространенным способом описания уровней сети является предложенная Международной организацией по стандартизации (International Standards Organization, ISO) модель взаимодействия открытых систем (open systems interconnection, OSI). Эта семиуровневая модель показана на рис. 1.5, где она
Модель ISO/OSI
Модель ISO/OSI Пожалуй, ключевым понятием в стандартизации сетей и всего, что к ним относится, является модель взаимодействия открытых систем (Open System Interconnection, OSI), разработанная «Международной организацией по стандартизации» (International Standards Organization, ISO). На практике применяется
Объекты Web-обозревателя. Объектная модель документа DOM
Объекты Web-обозревателя. Объектная модель документа DOM Объекты, предоставляемые Web-обозревателем, делятся на две группы:— объекты, представляющие Web-страницу и элементы, созданные с помощью разных тегов (абзац, заголовок, таблица, изображение и др.);— объекты,
8.16.1 Модель EGP
8.16.1 Модель EGP Маршрутизатор EGP конфигурируется с адресом IP для одного или нескольких внешних соседних маршрутизаторов. Обычно внешние соседи соединены с общей сетью с множественным доступом или объединены одной линией "точка-точка".EGP позволяет маршрутизатору
14.3 Модель FTP
14.3 Модель FTP Как видно из приведенного выше диалога, пользователь взаимодействует с локальным клиентом FTP (точнее, с соответствующим процессом). Программное обеспечение локального клиента управляет преобразованием данных для удаленного сервера FTP через управляющее
15.2 Модель RPC
15.2 Модель RPC Приложение клиент/сервер для архитектуры ONC функционирует поверх RPC. Работа RPC моделируется обычными вызовами подпрограмм. Например, в языке программирования С вызов обычной подпрограммы в общем случае имеет форму:код_возврата = имя_процедуры
Открытие документа
Открытие документа В процессе работы пользователю часто приходится не только создавать документы, но и вносить изменения в существующие. Чтобы это сделать, необходимо открыть документ одним из следующих способов.Открытие документа не из WordОткрывать документы не
Форматирование документа
Форматирование документа В этом подразделе рассмотрены следующие темы:• форматирование символов;• форматирование абзацев;• работа со списками;• работа с многоколоночными текстами;• стили и шаблоны.Хотел выделить пробелы подчеркиванием, однако у меня не получилось.
Сохранение документа
Сохранение документа После работы с документом его следует сохранить на жестком диске или ином носителе.Чтобы сохранить документ, нужно нажать Кнопку «Office» и в появившемся меню выполнить команду Сохранить как. В открывшемся диалоговом окне Сохранение документа (рис. 1.17)
Модель
Модель В любом интерьере наибольшее количество объектов — это модели. Модель может иметь произвольную форму: от примитивных сферы или куба до реалистичных форм человеческой фигуры. Модель призвана передавать формы конкретных объектов. Например, создавая интерьер, мы
13.4.3. Свойства документа
13.4.3. Свойства документа Для облегчения поиска рекомендуется заполнить информацию о документе. Для этого выполните команду Файл, Свойства и перейдите на вкладку Документ (рис. 129). Вы можете добавить информацию об авторе, руководителе, учреждении, в котором вы работаете,
13.5.2. Поиск документа
13.5.2. Поиск документа Вы забыли имя документа? Не беда — вам нужно использовать поиск документов, который можно выполнить средствами самого Word, не прибегая к помощи операционной системы. Нажмите кнопку открытия документа, выполните команду Сервис, Найти. Откроется окно
Web-модель
Web-модель Web-модель получила свое название, поскольку базируется на популярных браузерах Netscape Navigator и Microsoft Internet Explorer, используемых как средства навигации во Всемирной Паутине - World Wide Web. Эта модель предусматривает встраивание в готовый браузер набора открытых ключей