Интерфейс gstat
Интерфейс gstat
В отличие от некоторых других инструментов командной строки gstat не имеет своего интерфейса командной строки. Каждый запрос заключается в вызове gstat с переключателями.
Синтаксис:
gstat [переключатели] имя-базы-данных
где имя-базы-данных- полный путь к базе данных.
Графические инструменты
gstat не является дружественным пользователю инструментом. Некоторые графические инструменты (например, IBAnalyst) четко выполняют ту же работу gstat по выводу результатов, используя Services API. Формы экранов были взяты из утилиты с открытыми кодами IBOConsole[60].
Переключатели
В табл. 18.1 описаны переключатели gstat.
Таблица 18.1. Переключатели gstat
Переключатель
Описание
-user имя-пользователя
Проверяет имя пользователя перед доступом к базе данных
-pa[ssword] пароль
Проверяет пароль перед доступом к базе данных
-header
Выводит информацию заголовочной страницы, затем прекращает работу
-log
Выводит информацию заголовочной страницы и страницы протокола, затем прекращает работу
-index
Отыскивает и отображает статистику по индексам базы данных
-data
Отыскивает и отображает статистику по таблицам пользователя базы данных
-all
Это значение по умолчанию, если вы не запросили -index, -data или -all. Отыскивает и отображает статистику по -index и-data
-system
Как и -all, но дополнительно включает статистику по системным таблицам
-r
Отыскивает и отображает статистику по размеру и версиям записей (включая все версии)
-t список-таблиц
Используется вместе с -data. Ограничивает отображаемые данные таблицами из списка таблиц
-z
Печатает версию утилиты gstat
Рекомендуется назначить вывод результатов в текстовый файл и просматривать его в текстовом редакторе.
! ! !
ПРИМЕЧАНИЕ. Поскольку gstat выполняет собственный анализ на уровне файла, она не выполняется в контексте какой-либо транзакции. Следовательно, статистика по индексам также включает информацию по тем индексам, которые используются в незавершенных транзакциях. Например, не будет предупреждений, если отчет показывает некоторые дублирующие записи в индексе первичного ключа.
. ! .
Переключатель -index
Синтаксис:
gstat -i[ndex] база-данных
Этот ключ отыскивает и отображает статистику по индексам в базе данных: средняя длина ключа (в байтах), общее количество дубликатов и максимальное количество дубликатов одного ключа. Включите переключатель -s[ystem], если вам нужна информация о системных индексах.
К сожалению, не существует способа получить статистику по одному индексу, однако вы можете ограничить результат одной таблицей, используя переключатель -t, за которым следует имя таблицы. Вы можете записать разделенный пробелами список имен таблиц для получения результатов более чем по одной таблице. Если имена ваших таблиц являются чувствительными к регистру - были объявлены идентификаторами, заключенными в кавычки, - то аргументы переключателя -t должны быть записаны в правильном регистре, но не должны заключаться в кавычки. Для таблиц с пробелами в их именах gstat вовсе не работает.
Вы можете добавить переключатель -system, чтобы включить сведения о системных индексах в отчет.
Чтобы запустить утилиту для базы данных employee и направить ее вывод в текстовый файл с именем gstat.index.txt, выполните следующее:
* в POSIX наберите (все в одной строке):
./gstat -index /opt/firebird/examples/employee.fdb -t CUSTOMER -user SYSDBA -password masterkey
> /opt/firebird/examples/gstat.index.txt
* в Win32 наберите (все в одной строке):
gstat -index
"c:Program FilesFirebirdFirebird_1_5examplesemployee.fdb" -t CUSTOMER
-user SYSDBA -password masterkey
> "c:Program FilesFirebirdFirebird_1_5examplesgstat.index.txt"
! ! !
ПРИМЕЧАНИЕ. Двойные кавычки для пути к базе данных требуются в Windows, если ваш путь содержит пробелы.
. ! .
На рис. 18.3 показано, как отображаются данные индексной страницы.
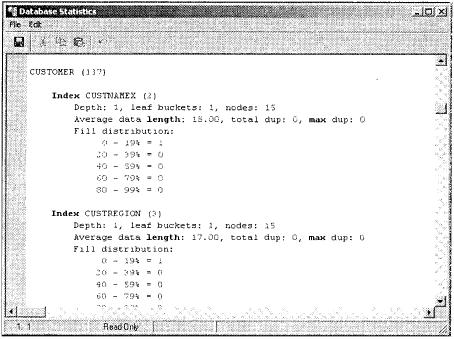
Рис. 18.3. Пример отображения данных индексной страницы
Что все это значит
Вначале появляется итоговая информация об индексе. В табл. 18.2 объясняются записи строка за строкой.
Поскольку утилита gstat выполняет свой анализ на уровне файла, она не использует концепции транзакции. Следовательно, статистика по индексам также включает информацию по тем индексам, которые используются в незавершенных транзакциях.
Таблица 18.2. Вывод gstat -i[ndex]
Элемент
Описание
Index
Имя индекса
Depth
Количество уровней в странице индексного дерева. Если глубина дерева индексной страницы превышает 3, то доступ к записям через индекс не будет максимально эффективным. Для уменьшения глубины дерева индексной страницы увеличьте размер страницы. Если увеличение размера страницы не уменьшает глубины, снова увеличьте размер страницы
Leaf buckets
Количество страниц самого низкого уровня (листовых) в дереве индекса. Это страницы, которые содержат указатели на записи. Страницы высокого уровня содержат косвенные связи
Nodes
Общее количество записей, индексированных в дереве. Должно быть равно количеству индексированных строк в дереве, хотя отчет gstat может включать узлы, которые были удалены, но не вычищены в процессе сборки мусора. Может также включать множество элементов для записей, у которых был изменен индексный ключ
Average data length
Средняя длина каждого ключа в байтах. Обычно имеет много меньшее значение, чем длина объявленного ключа, потому что выполняется сжатие суффикса и префикса
Total dup
Общее количество строк дубликатов индекса
Max dup
Количество дублирующих узлов в "цепочке", имеющих наибольшее количество дубликатов. Всегда будет нулем для уникальных индексов. Если число велико по сравнению с числом в Total dup, то это признак плохой селективности
Average fill
Это гистограмма с пятью 20-процентными полосами, каждая из которых показывает количество индексных страниц, чей средний процент заполнения находится в указанном диапазоне. Процент заполнения определяется соотношением пространства каждой страницы, содержащей данные. Сумма таких чисел дает общее количество страниц, содержащих индексные данные
Глубина индексов
Индекс является древовидной структурой со страницами на одном уровне, ссылающимися на страницы другого уровня и т.д. вплоть до страниц, указывающих на строки данных. Чем больше глубина, тем больше косвенных уровней. Строка Leaf bucket описывает страницы индекса самого низкого уровня, которые указывают на индивидуальные строки.
На рис. 18.4 корневая страница индекса (создаваемая при создании базы данных) хранит указатель для каждого индекса и указатель на другую страницу указателей, которая содержит указатели этого индекса. Такая страница последовательно указывает на страницы, содержащие данные - фактические данные узлов - либо непосредственно (глубина равна 1), либо косвенно (добавляя один уровень для каждого косвенного уровня).
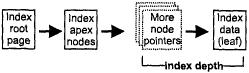
Рис. 18.4. Глубина индекса
Два фактора оказывают влияние на глубину: размеры страницы и ключа. Если глубина больше 3 и размер страницы меньше 8192, то увеличение размера страницы до 8192 или 16 386 должно уменьшить количество косвенных уровней и увеличить скорость.
! ! !
СОВЕТ. Вы можете вычислить приблизительный размер (в страницах) цепочки мах dup на основании статистических данных. Для получения количества узлов на странице разделите узлы (nodes) на количество листьев (leaf buckets). Умножение результата на максимальное количество дублирующих узлов (max dup) дает приблизительное количество страниц.
. ! .
Анализ некоторой статистики
Следующие выдержки являются выводом gstat -index для базы данных с плохой производительностью.
Анализ 1
Первый из поддерживаемых индексов, который был создан автоматически для внешнего ключа:
Index RDB$FOREIGNl4 (3)
Depth: 2, leaf buckets: 109, nodes: 73373
Average data length: 0.00, total dup: 73372, max dup: 32351
Fill distribution:
80 - 99% = 109
Строка Depth: 2, leaf buckets: 109, nodes: 73373 Сообщает нам, что нижний уровень индекса имеет 109 листьев (страниц), количество узлов 73 373. Это может и не быть общим количеством строк таблицы. С одной стороны, утилита gstat ничего не знает о транзакциях, поэтому она не может сообщить, найдены ли подтвержденные или неподтвержденные страницы. С другой - столбцы могут иметь значения NULL и не будут попадать в статистику.
Нижний уровень индекса- где хранятся узлы листьев- имеет всего 109 страниц. Кажется подозрительным наличие малого количества страниц для такого большого количества строк. Следующая статистика объясняет, почему.
В строке Average data length: 0.00, total dup: 73372, max dup: 32351 число max dup указывает длину самой длинной цепочки дубликатов, подсчитанной почти для половины узлов. Число total dup говорит, что каждый узел, за исключением одного, является дубликатом.
Это самый классический случай, когда проектировщик применяет внешний ключ без рассмотрения его распределения. Вероятно, это столбец стиля BOOLEAN или таблица соответствия (lookup) либо с очень небольшим количеством значений, либо практически с одним значением.
Примером этому было приложение формирования списка избирателей, которое сохраняло столбец страны проживания. Избирателей было приблизительно 3 миллиона, а регистрация была принудительной. База данных имела таблицу COUNTRY, содержащую более 300 стран, снабженную ключами в кодах стран CCCIT. Она присутствовала чуть ли не в каждой таблице базы данных в качестве внешнего ключа. Беда была в том, что почти все избиратели жили в одной стране.
Средняя длина данных (Average data length) - это средняя длина хранимого ключа. Здесь мало что можно сделать с объявленной длиной. Нулевое значение средней длины означает лишь то, что в процессе сжатия не осталось "пищи" для вычисления среднего значения.
Строка Fill distribution показывает, что все 109 страниц находятся в диапазоне 80-99 процентов, что является хорошим заполнением. Распределение заполнения является долей пространства каждой страницы, используемой для данных и указателей. От восьмидесяти до девяноста процентов - это хорошо. Меньшее распределение заполнения является весьма серьезным напоминанием, что вы должны пересоздать индекс.
Анализ 2
Следующий пример показывает статистику сгенерированного системой индекса для первичного ключа в той же таблице:
Index RDB$PRIMARY10 (0)
Depth: 3, leaf buckets: 298, nodes: 73373
Average data length: 10.00, total dup: 0, max dup: 0
Fill distribution:
0 - 19% = 1
80 - 99% = 297
Длина ключа 10 означает, что выполнено некоторое сжатие. Это нормально и хорошо. То что одна строка мало заполнена- вполне нормально: количество узлов не соответствует точно страницам.
Анализ 3
Эта база данных имеет маленькую таблицу, хранящую временные данные для проверки достоверности. Она периодически очищается и наполняется снова. Следующая статистика генерируется для внешнего ключа этой таблицы:
Index RDB$FOREIGN263 (1)
Depth: 1, leaf buckets: 10, nodes: 481
Average data length: 0.00, total dup: 480, max dup: 480
Fill distribution:
0 - 19% = 10
Total dup и max dup идентичны - каждая строка имеет одинаковое значение в ключе индекса. Селективность не может быть хуже этой. Уровень заполнения, очень низкий для всех страниц, наводит на мысль о разнородных удалениях. Если бы это не было маленькой таблицей, такой индекс был бы ужасен.
Данная таблица - очередь обработки - очень динамична, она хранит до 1000 новых строк в день. После проверки данных строки переносятся в порождающие таблицы, а строки разрабатываемой таблицы удаляются, приводя к замедлению работы системы. Частое резервное копирование и восстановление базы данных необходимо, чтобы дела шли нормально.
Проблема в том, что в этом случае следует избегать внешних ключей, и если они являются необходимыми, то их можно реализовать с помощью триггеров, созданных пользователем.
Однако, если проектирование базы данных, безусловно, требует ограничений внешних ключей для временных таблиц со столбцами низкой селективности, существуют рекомендованные способы уменьшения накладных расходов и снижения ухудшения состояния индексных страниц, являющихся следствием удаления и дальнейшего наполнения данными таблицы. Отслеживайте уровень заполнения проблемных индексов и принимайте меры, когда он упадет ниже 40%. Выбор действий зависит от ваших требований.
* Если возможно, удаляйте все строки за один раз, а не выполняйте их удаление одну за другой в случайном порядке. Удалите ограничение внешнего ключа, удалите строки и подтвердите транзакцию. Заново создайте ограничение. Поскольку это не длинная транзакция, задерживающая сборку мусора, новый индекс будет полностью пустым.
* Если удаления должны быть последовательными, выберите время, чтобы получить исключительный доступ и использовать ALTER INDEX для пересоздания индекса. Это будет более быстро и предсказуемо, чем инкрементная сборка мусора в огромной цепочке дубликатов.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Интерфейс
Интерфейс …И видим, что на экране вместо обещанных красот спутниковой разведки – обычная карта земной поверхности со знакомыми по школьным атласам и контурным картам схемами континентов! Да, судя по схеме, мы с вами находимся где-то в европейской части России
27.1. Интерфейс dl
27.1. Интерфейс dl Процесс динамической загрузки заключается в открытии библиотеки, поиске любого количества символов, обработке любых возникающих ошибок и закрытии библиотеки. Все функции динамической загрузки объявляются в одном заголовочном файле, <dlfcn.h>, и
7.2 Интерфейс WMI
7.2 Интерфейс WMI Как уже отмечалось, модель CIM определена в рабочей группе DMTF и принята к использованию ассоциацией SNIA. Интерфейс WMI представляет собой реализацию модели CIM от Microsoft. Другими словами, WMI – это «CIM для Windows».Интерфейс WMI был разработан для режима ядра и
Интерфейс
Интерфейс ИНТЕРФЕЙС, графическая «оболочка», с помощью которой мы, пользователи, обращаемся к операционной системе. Интерфейс – это посредник, переводчик, задача которого преобразовать все внутренние «рычаги управления» Windows в понятную людям графическую
Интерфейс
Интерфейс Интерфейс Windows 7 не претерпел каких-либо особых изменений по сравнению с внешним видом Windows Vista. Тем не менее кое-что новое в нем также имеется. Основные изменения коснулись оформления таких элементов и программ, как меню Пуск, Панель задач, область уведомлений,
Интерфейс
Интерфейс В категории Интерфейс (рис. 14.8) задают некоторые настройки, касающиеся интерфейса. Например, включить отображение цветовых каналов в их базовых цветах, включить или выключить появление всплывающих подсказок при подведении курсора к инструментам, режим
4.1. Интерфейс с PHP
4.1. Интерфейс с PHP В этом разделе мы рассмотрим процесс создания веб-приложения на языке PHP, взаимодействующего с базой данных MySQL. Вначале познакомимся с платформами, на которых возможно создание такого приложения, а затем с функциями языка PHP, обеспечивающими работу с
Интерфейс
Интерфейс На самом деле Word – это не просто текстовый редактор (то есть, программа, предназначенная для создания и обработки текстов), а нечто гораздо большее. С помощью Word вы можете не просто набрать текст, но и оформить его по своему вкусу: включить в него таблицы и
gstat
gstat Этот инструмент получения статистики собирает и отображает статистические сведения по индексам и данным базы данных. Подробную информацию об использовании gstat см. в разд. "Темы оптимизации" главы 18.fb_lock_printЭта утилита формирует статистические данные файла блокировок,
Другие переключатели gstat
Другие переключатели gstat Статистика утилиты gstat может предоставить полезную информацию о других действиях с базой данных.Переключатель -headerЭта строкаgstat -header база-данныхотображает суммарную информацию заголовочной страницы базы данных. На рис. 18.5 показан пример.Первая
gstat
gstat Инструмент командной строки gstat, используемый с переключателем -header, показывает различную статистическую информацию базы данных, включая текущее значение идентификатора транзакции для OIT, OAT и для следующей новой транзакции. Для использования gstat соединитесь с базой
Интерфейс
Интерфейс Пример внешнего вида Pinnacle Studio в режиме захвата приведен на рис. 2.1. Рис. 2.1. Studio в режиме захватаВ случае, показанном на рисунке, захват осуществляется с цифровой камеры. Поэтому в левой нижней части окна присутствует панель управления камерой (Контроллер
Веб-интерфейс
Веб-интерфейс Существует еще один способ получения и отправки писем – это веб-интерфейс. Он работает через любой браузер. Его главное преимущество заключается в том, что вы сможете забрать свою почту с абсолютно любого компьютера без настройки почтового клиента.Кроме
Интерфейс
Интерфейс Интерфейс (внешний вид) программы очень схож с Microsoft Word. После запуска программы экран Excel содержит пять областей (по порядку сверху вниз): Внешний вид окна программы ExcelКак вы теперь смогли сами убедиться, основным отличием от Word является присутствие вместо