Улучшение селективности индекса
Улучшение селективности индекса
Вообще говоря, селективность (избирательность) индекса - это оценочное количество строк, которые могут быть выбраны при поиске по каждому значению индекса. Уникальный индекс имеет максимально возможную селективность, потому что он не может выбрать более одной строки для каждого значения, в то время как индекс для столбца BOOLEAN имеет практически самую низкую селективность.
Индексирование столбца, который будет хранить преимущественно одно значение (например, страна рождения в предыдущем примере), будет худшим решением, чем не индексирование такого столбца совсем. Firebird достаточно эффективен при создании образа для неиндексированных сортировок и поисков.
Измерение селективности
Селективность уникального индекса равна I. Все неуникальные индексы имеют значение меньше 1. Селективность (s) вычисляется как[56]
s = n / количество строк в таблице
где n- количество различных экземпляров значения индекса в таблице. Чем меньше количество отличающихся экземпляров, тем меньше селективность. Индексы с более высокой селективностью выполняются лучше, чем индексы с низкой селективностью.
Оптимизатор Firebird отыскивает коэффициент для вычисления селективности при первом обращении к таблице и сохраняет его в памяти для использования при вычислении планов при последующих запросах к этой таблице. Со временем вычисленные коэффициенты для часто изменяемых таблиц становятся устаревшими, возможно влияя на выбор оптимизатором индекса в экстремальных случаях.
Пересчет селективности
Пересчет селективности индекса изменяет статистический множитель, хранящийся в системных таблицах. Оптимизатор читает его один раз при выборе плана- он не является особенно значимым для его выбора. Часто большие операции DML не обязательно повреждают распределение различных значений ключа индекса. Если индексирование разумно, то "демография" распределения значений может изменяться очень незначительно.
Знание наиболее правильной селективности индекса имеет большое значение для разработчика. Это дает основу для определения полезности индекса.
Если эффективность плана со временем снижается по причине большого количества добавлений или изменений ключевого столбца (столбцов), которые изменяют распределение значений ключа, быстродействие запросов может постепенно снижаться. Любой индекс, чья селективность со временем резко падает, должен быть удален, потому что он влияет на производительность.
Работа с неконтролируемым индексом, который ухудшается по мере роста таблицы до того, как он начинает влиять на планы запросов, является важной частью настрой- ки базы данных. При этом большинство критических эффектов использования индекса с фактически низкой селективностью практически не влияют на оптимизатор и оказывают сильное воздействие на геометрию индекса[57].
Почему низкая селективность наносит ущерб
Для индексов Firebird создает двоичное дерево. Он хранит эти структуры на индексных страницах, которые выделяются только для хранения индексных деревьев. Каждое значение в сегменте индекса имеет собственный узел за пределами корня дерева. Когда в индекс добавляется новая запись, она или помещается в новый узел, если ее значение не существует в индексе, или помещается в начало стека существующих дубликатов значений.
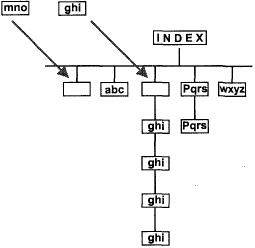
Рис. 18.2 иллюстрирует этот двоичный механизм в простейшей форме
Когда появляются дублирующие значения, они помещаются в первый узел в начало "цепи" других дубликатов - это то, что происходит со значением ghi на нашей диаграмме. Такая структура называется цепочкой дубликатов.
Цепочки дубликатов[58]
Цепочка дубликатов сама по себе является замечательной - все неуникальные индексы имеют ее. Изменение сегмента значения или удаление строки является дорого- стоящим, если цепочка дубликатов очень длинная. Одно из самого плохого, что вы можете сделать в базе данных Firebird - определить таблицу с миллионом строк, каждая из которых имеет одно и то же значение ключа для вторичного индекса, а затем удалить все эти строки. Последний сохраненный дубликат появляется в начале списка, а первый сохраненный дубликат - в конце. Обычно удаление начинается с первой сохраненной строки, затем удаляется вторая и т.д. Код обработки индекса будет проходить через всю цепь дубликатов для каждого удаления, всегда отыскивая нужную запись в самой последней позиции. Цитата Ann Harrison: "Это перемешивает кэш так, как вы никогда не видели".
Затраты на все такие "перемешивания" и "взбалтывания" никогда не связаны с транзакцией, которая удаляет или изменяет все строки в таблице. Изменение значения ключа или его удаление влияет на индекс позже, когда старые версии будут включены в процесс сборки мусора. Затраты проявятся для следующей транзакции, обращающейся к этим строкам и выполняющейся после завершения всех транзакций, которые были активны, когда выполнялось изменение или удаление[59].
Инструментарий для индекса
Стандартная поставка Firebird содержит множество инструментов и приемов для получения состояния индексов и поддержания их в хорошей форме.
* Для получения значения селективности и других значимых характеристик индексов используйте анализатор статистики данных gstat. Позже в этой главе мы рассмотрим, как gstat может рассказать вам о ваших индексах.
* Инструментом для пересчета селективности индекса является оператор SET STATISTICS (обсуждаемый в следующем разделе), SET STATISTICS не пересоздает индекс.
* Лучшей из всех инструментов для чистки индексов является утилита резервного копирования и восстановления gbak. Восстановление базы данных из самой последней резервной копии пересоздает все индексы и заново вычисляет их селективность.
Использование SET STATISTICS
В некоторых таблицах количество дублирующих значений в индексированных столбцах может радикально увеличиваться или уменьшаться как результат относительной "популярности" отдельных значений в индексе по сравнению с другими кандидатами в значения. Например, индексы по датам в системе продаж могут иметь тенденцию становиться менее селективными при резком увеличении деловой активности.
Периодическое вычисление селективности индекса может увеличить производительность индексов, которые являются субъектами значительных изменений в распределении различных значений.
Оператор SET STATISTICS заново вычисляет селективность индекса. Этот оператор может быть выполнен в интерактивной сессии isql или запущен в приложении ESQL. Для выполнения оператора SET STATISTICS вы должны быть соединены с базой данных как пользователь, создавший индекс, как пользователь SYSDBA или (в POSIX) как пользователь с привилегиями операционной системы root.
Синтаксис:
SET STATISTICS INDEX ИМЯ;
Следующий оператор заново вычисляет селективность индекса в базе данных employee.gdb:
SET STATISTICS INDEX MINSALX;
Сам по себе оператор SET STATISTICS не решает текущие проблемы, являющиеся результатом предыдущего использования индекса, которые связаны с устаревшей статистикой селективности, потому что он не пересоздает индекс.
! ! !
СОВЕТ. Для пересоздания индекса используйте ALTER INDEX, или удалите и заново создайте его, или восстановите базу данных с резервной копии.
. ! .
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Пополнение индекса
Пополнение индекса Как говорилось выше, по умолчанию проиндексированными являются только личные папки пользователей. Если попытаться найти файл в неиндексированной папке, появляется всплывающее предложение добавить каталог в список индексируемых. Однако вы можете
Что вам даст улучшение конверсии сайта
Что вам даст улучшение конверсии сайта Наша книга – это, по сути, практическое руководство, которое поможет вам разобраться в методах повышения конверсии и успешно применять их. Хотя мы старались целиком охватить тему убеждения покупателей, но главной нашей целью
Enhancing (Улучшение)
Enhancing (Улучшение) Повышает насыщенность красного, оранжевого и коричневого цветов. При изменении каждого из этих цветов другие цвета изменяются минимально. Фильтр удобно применять для фотографий с изображением осенних пейзажей, архитектурных элементов соответствующих
Image Enhancement (Улучшение изображения)
Image Enhancement (Улучшение изображения) Данная группа фильтров является дополнением к категории Color Effects (Эффекты цвета). Сюда входят фильтры, предназначенные для улучшения качества изображения (рис. 10.12). Используются они чаще всего по отношению к цифровым фотографиям для
Изменение индекса
Изменение индекса Активация/деактивация Оператор ALTER INDEX используется для переключения состояния индекса из активного в неактивное и наоборот. Он может быть применен для отключения индекса перед добавлением или изменением большого пакета строк и устранения при этом
Изменение структуры индекса
Изменение структуры индекса В отличие от большинства операторов ALTER синтаксис ALTER INDEX не может быть использован для изменения структуры данного объекта. Для этого необходимо удалить индекс и заново его создать с использованием оператора CREATE
Удаление индекса
Удаление индекса Оператор DROP INDEX удаляет созданный пользователем индекс из базы данных.Используйте DROP INDEX также в случае необходимости изменения структуры индекса: добавление, удаление сегментов, изменение порядка сегментов или изменение порядка сортировки. Вначале
Улучшение графики
Улучшение графики На данный момент игра достаточно увлекательна, но графика оставляет желать лучшего. Когда объекты проходят друг через друга, можно увидеть ограничивающие прямоугольники объекта. Надо исправить эту ситуацию.Для решения проблемы можно использовать
33 Пошаговое улучшение качества
33 Пошаговое улучшение качества «Тотальное управление качеством» (Total Quality Management), «Непрерывное улучшение рабочего процесса» (Continuous Process Improvement) или ISO — в большинстве современных терминов, касающихся качества процесса и продукта, акцент ставится на стремлении к качеству в
Улучшение характеристик работы SAP
Улучшение характеристик работы SAP Крайне важно определить корректные меры для оценки эффективности компании, ее способности в достижении намеченных целей. Система SAP в значительной степени способствует мониторингу и управлению мерами по улучшению эффективности (Measures of