9.3.2. Таблицы кодировки символов
9.3.2. Таблицы кодировки символов
В человеческом мире информация представляется последовательностями символов. Каждый символ имеет каноническое изображение, которое позволяет однозначно идентифицировать данный символ. Шрифты задают разные варианты начертания символов.
В вычислительных машинах для представления информации используются цепочки байтов. Поэтому для перевода информации из машинного представления в человеческий необходимы таблицы кодировки символов - таблицы соответствия между символами определенного языка и кодами символов.
Самой известной таблицей кодировки является код ASCII (Американский стандартный код для обмена информацией), который был разработан для передачи текстов по телеграфу задолго до появления компьютеров. Этот код является 7 битовым, т. е. для кодирования символов английского языка, служебных и управляющих символов используются только 128 7-битовых комбинаций. При этом первые 32 комбинации (кода) служат для кодирования управляющих сигналов (начало текста, конец строки, перевод каретки, звонок, конец текста и т. д.).
При разработке первых компьютеров фирмы IBM этот код был использован для представления символов в компьютере. Поскольку в исходном коде ASCII было всего 128 символов, для их кодирования хватило тех однобайтовых кодов, у которых 8-й бит равен 0. Во второй половине кодовой таблицы (значения байта с 8-м битом равным 1) фирма IBM разместила символы псевдографики, математические знаки и некоторые символы из языков, отличных от английского (немецкие умляуты, французские диакритические знаки, символы греческого алфавита и т.п.). Эту кодовую таблицу стали называть кодировкой IBM.
Когда IBM-совместимые персональные компьютеры стали использовать в других странах, потребовалось обеспечить обработку информации на языках, отличных от английского. Для того, чтобы полноценно поддерживать другие языки, фирма IBM ввела в употребление несколько кодовых таблиц, ориентированных на конкретные страны. Так для скандинавских стран была предложена таблица 865 (Nordic), для арабских стран - таблица 864 (Arabic), для Израиля - таблица 862 (Israel) и так далее. В этих таблицах часть кодов из второй половины кодовой таблицы использовалась для представления символов национальных алфавитов (за счет исключения некоторых символов псевдографики). Для представления символов кириллицы была введена кодировка IBM-866.
Однако с русским языком ситуация развивалась особым образом. Очевидно, что замену символов во второй половине кодовой таблицы можно произвести разными способами. В других европейских странах сумели найти единое решение, а для русского языка появилось несколько разных таблиц кодировки символов кириллицы: IBM-866, CP-1251, KOI8-R, ISO-8859-5. Все они одинаково изображают символы первой половины таблицы (от 0 до 127) и различаются представлением символов русского алфавита и псевдографики во второй половине.
Одна из самых известных кодовых таблиц для кириллицы получила название альтернативной (по отношению к кодировке IBM-866, наверное). Она была разработана фирмой Microsoft для MS-DOS. При ее разработке постарались сделать так, чтобы результирующая таблица была насколько это возможно совместима с кодировкой IBM. Поэтому альтернативная кодировка - это кодировка IBM, в которой все специфические европейские символы в верхней половине были заменены на кириллицу, оставляя псевдографические символы нетронутыми. Следовательно, это не портило вид программ, использующих для работы текстовые окна, что было очень существенным фактором для работы в среде MS-DOS, основой которой был именно текстовый режим.
Кодировка KOI-8 была разработана изначально с ориентировкой на UNIX. Так как UNIX в своей основе сетевая ОС, то основной идей при создании KOI-8 была идея об обеспечении перемещения кириллической информации по сети. Но для передачи-то использовался 7-битный стандарт ASCII. Разработчики поместили кириллические символы в верхней части таблицы таким образом, что позиции кириллических символов соответствуют их фонетическим аналогам в английском алфавите в нижней части таблицы. Это означает, что, если в тексте, написанном в KOI-8, мы убираем восьмой бит каждого символа, то мы все еще имеем "читабельный" текст, хотя он и написан английскими символами! Не удивительно, что KOI8-R быстро стал фактически стандартом для кириллицы в Интернет, что и нашло отражение в RFC 1489 ("Registration of a Cyrillic Character Set"). Автором этого документа является Андрей А. Чернов, который проделал огромный объем работы, чтобы превратить KOI-8 в стандарт Интернет.
Международная организация по стандартизации (ISO) внесла свою лепту в создание различных кодировок кириллицы, когда ввела семейство стандартов, известных как ISO 8859-X. Это семейство есть совокупность 8-битных кодировок, где младшая половина каждой кодировки (символы с кодами 0-127) соответствует ASCII, а старшая половина определяет символы для различных языков. Например:
• 8859-0 - новый европейский стандарт (так называемый Latin 0);
• 8859-1 - Европа, Латинская Америка (также известный как Latin 1);
• 8859-2 - Восточная Европа;
• 8859-5 - кириллица;
• 8859-8 - идиш.
Фирма Microsoft еще больше запутала ситуацию с кодировками для русского языка, когда при разработке Windows ввела кодировку CP-1251.
Таблицы кодировок, содержащие 256 символов, стали называть расширенными кодами ASCII (потому что в основе любой из них лежит 128-символьный код ASCII), кодовыми страницами или английским термином character set (который часто сокращают до charset).
Но в мире есть языки, такие как китайский или японский, для которых 256 символов в принципе недостаточно. Кроме того, всегда существует проблема вывода или сохранения в одном файле одновременно текстов на разных языках (например, при цитировании). Поэтому была разработана универсальная кодовая таблица UNICODE, содержащая символы, применяемые в языках всех народов мира, а также различные служебные и вспомогательные символы (знаки препинания, математические и технические символы, стрелки, диакритические знаки и т. д.). Очевидно, что одного байта недостаточно для кодирования такого большого множества символов. Поэтому в UNICODE используются 16-битовые (2-байтовые) коды, что позволяет представить 65 536 символов. К настоящему времени задействовано около 49 000 кодов (последнее значительное изменение - введение символа валюты EURO в сентябре 1998 г.). Для совместимости с предыдущими кодировками первые 128 кодов совпадают со стандартом ASCII. На рис. 9.1 схематично представлено размещение символов разных языков в кодовом пространстве UNICODE.
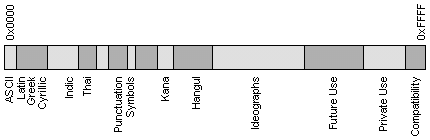
Рис. 9.1. Структура UNICODE.
В стандарте UNICODE кроме определенного двоичного кода (эти коды принято обозначать буквой U, после которой следуют знак + и собственно код в шестнадцатеричном представлении) каждому символу присвоено определенное имя. В следующей таблице приведено несколько примеров кодов и имен символов из стандарта UNICODE.
Таблица 9.2. Примеры именования кодов UNICODE
Символ UNICODE Название символа (Character Name) A U+0041 LATIN CAPITAL LETTER A a U+0061 LATIN SMALL LETTER A Ю U+042E CYRILLIC CAPITAL LETTER YU + U+002B PLUS SIGN 1 U+0031 DIGIT ONE ? U+03A9 GREEK CAPITAL LETTER OMEGA ? U+2569 BOX DRAWINGS DOUBLE UP AND HORIZONTALЕще одним компонентом стандарта UNICODE являются алгоритмы для взаимно-однозначного преобразования кодов UNICODE в последовательности байтов переменной длины. Необходимость таких алгоритмов обусловлена тем, что не все приложения умеют работать с UNICODE. Некоторые приложения понимают только 7-битовые ASCII-коды, другие приложения - 8-битовые (расширенные) ASCII-коды. Для представления символов, не поместившихся, соответственно, в 128 символьный или 256 символьный набор, такие приложения используют цепочки байтов переменной длины. Алгоритм UTF-7 служит для обратимого преобразования кодов UNICODE в цепочки 7-битовых ASCII-кодов, а UTF-8 - для обратимого преобразования кодов UNICODE в цепочки из расширенных 8-битовых ASCII-кодов. Подробнее об алгоритмах UTF-7 и UTF-8 и кодировках вообще вы можете прочитать в [П11.3 - П11.5].
Отметим, что и ASCII, и UNICODE, и другие стандарты кодировки символов не определяют изображения символов, а только состав набора символов и способ его представления в компьютере. Кроме того (что, может быть, не сразу очевидно) они еще задают порядок перечисления символов в наборе, который очень важен, так как он влияет самым существенным образом на алгоритмы сортировки. Именно таблицу соответствия символов из какого-то определенного набора (скажем, символов, применяемых для представления информации на английском языке, или на разных языках, как в случае с UNICODE) и обозначают термином таблица кодировки символов или charset. Каждая стандартная кодировка имеет имя, например, KOI8-R, ISO_8859-1, ASCII. К сожалению, стандарта на имена кодировок не существует.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Преобразование символов из кодировки ASCII в Unicode
Преобразование символов из кодировки ASCII в Unicode Измерения выполнялись для восьми программ, каждая из которых преобразовывала файл размером 12,8 Мбайт в файл размером 25,6 Мбайт. Соответствующие результаты представлены в табл. В.2.1. Программа atou (программа 2.4) сопоставима с
Установка кодировки символов
Установка кодировки символов Для значительных переработок исходных документов важно знать, что можно устанавливать кодировку символов в результирующих документах при помощи атрибута encoding элемента <xsl:output>. Однако нет гарантии, что ваш процессор XSLT будет
Изменение размера шрифта и кодировки
Изменение размера шрифта и кодировки Для начала изучим две очень полезные команды, которые находятся в меню Вид и называются Размер шрифта и Кодировка.С первой проще. Проведя несложные манипуляции мышью (рис. 7.1), вы можете выбрать размер экранных шрифтов в зависимости от
Изучаем мир тви-символов
Изучаем мир тви-символов С. Кара-Мурза в своей книге «Демонтаж народа» описывает мир символов. Он говорит, что «мир символов упорядочивает историю, связывает в нашей коллективной жизни прошлое, настоящее и будущее». Действительно, символы значат для нас чрезвычайно
Поддержка кодировки UNICODE
Поддержка кодировки UNICODE Microsoft ODBC 3.5 определяет два типа драйверов - ANSI и UNICODE. Gemini ODBC-драйвер является по этой классификации драйвером UNICODE. Это дает возможность приложениям, использующим версию UNICODE интерфейса ODBC, обрабатывать данные различных национальных наборов
Вставка символов
Вставка символов При работе с текстом нам часто будет требоваться использовать какой-нибудь специальный символ. Причем это касается не только малоупотребимых символов, которые можно вызвать с помощью Таблицы символов, но и особых знаков, используемых программой Adobe
Настройки символов
Настройки символов Для изменения настроек символов мы будем пользоваться палитрой Character (Символы) (рис. 13.1) и панелью управления (рис. 13.2) в режиме работы с текстом (возможно, ее придется переключить в режим отображения настроек символов с помощью кнопок в левой части
Стили символов
Стили символов Созданием, управлением и использованием стилей символов занимается палитра Character Styles (Стили символов) (рис. 17.1). В начале работы она пуста, в ней присутствует только строка [None] (Нет стиля). Рис. 17.1. Палитра Character Styles (Стили символов) и ее менюНачать работу с уже
3.8. Классы символов
3.8. Классы символов Классы символов — это просто форма перечисления (указание альтернатив), в котором каждая группа состоит из одного символа. В простейшем случае список возможных символов заключается в квадратные скобки:/[aeiou]/ # Соответствует любой из букв а, е, i, о, и;
4.2. Кодировки в пост-ASCII мире
4.2. Кодировки в пост-ASCII мире «Век ASCII» прошел, хотя не все еще осознали этот факт. Многие допущения, которые программисты делали в прошлом, уже несправедливы. Нам необходимо новое мышление.Есть две идеи, которые, на мой взгляд, являются основополагающими, почти аксиомами.
10.3.3. Набор символов и объединение таблицы
10.3.3. Набор символов и объединение таблицы Каждая таблица имеет набор символов таблицы и объединение. Инструкции CREATE TABLE и ALTER TABLE имеют факультативные предложения для определения набора символов таблицы и объединения:CREATE TABLE tbl_name(column_list)[[DEFAULT] CHARACTER SET charset_name][COLLATE
Определение класса символов и преобразование символов
Определение класса символов и преобразование символов Функция Краткое описание isalnum проверка на букву или цифру isalpha проверка на букву isascii проверка на символ из набора кодировки ASCII iscntrl проверка на управляющий символ isdigit проверка на десятичную
Кодировки в XSLT-преобразованиях
Кодировки в XSLT-преобразованиях Несмотря на то, что в логических деревьях, которыми манипулирует XSLT, текстовые узлы представляются в кодировке Unicode, очень часто в обрабатываемых документах бывает необходимо использовать также другие кодировки. К примеру, большинство
23.1.4. Регистр символов
23.1.4. Регистр символов Чаще всего причиной ошибки является неверное использование регистра при работе с переменными. Например, при присваивании переменной применяется верхний регистр, а при ссылке на нее — нижний. Тогда не следует удивляться тому, что присваивания