Сжатие с минимальной избыточностью
Сжатие с минимальной избыточностью
Теперь, когда в нашем распоряжении имеется класс потока битов, им можно воспользоваться при рассмотрении алгоритмов сжатия и восстановления данных. Мы начнем с исследования алгоритмов кодирования с минимальной избыточностью, а затем рассмотрим более сложное сжатие с применением словаря.
Мы приведем подробное описание трех алгоритмов кодирования с минимальной избыточностью: кодирование Шеннона-Фано (Shannon-Fano), кодирование Хаффмана (Huffman) и сжатие с применением скошенного дерева (splay tree compression), однако рассмотрим реализации только последних двух алгоритмов (алгоритм кодирования Хаффмана ни в чем не уступает, а кое в чем даже превосходит алгоритм кодирования Шеннона-Фано). При использовании каждого из этих алгоритмов входные данные анализируются как поток байтов, и различным значениям байтов тем или иным способом присваиваются различные последовательности битов.
Кодирование Шеннона-Фано
Первый алгоритм сжатия, который мы рассмотрим - кодирование Шеннона-Фано, названное так по имени двух исследователей, которые одновременно и независимо друг от друга разработали этот алгоритм: Клода Шеннона (Claude Shannon) и Р. М. Фано (R. М. Fano). Алгоритм анализирует входные данные и на их основе строит бинарное дерево минимального кодирования. Используя это дерево, затем можно выполнить повторное считывание входных данных и закодировать их.
Чтобы проиллюстрировать работу алгоритма, выполним сжатие предложения "How much wood could a woodchuck chuck?" ("Сколько дров мог бы заготовить дровосек?") Прежде всего, предложение необходимо проанализировать. Просмотрим данные и вычислим, сколько раз в предложении встречается каждый символ. Занесем результаты в таблицу (см. таблицу 11.1).
Таблица 11.1. Частота появления символов в примере предложения
Символ - Количество появлений
Пробел - 6
c - 6
o - 6
u - 4
d - 3
h - 3
w - 3
k - 2
H - 1
a - 1
l - 1
m - 1
? - 1
Теперь разделим таблицу на две части, чтобы общее число появлений символов в верхней половине таблицы приблизительно равнялось общему числу появлений в нижней половине. Предложение содержит 38 символов, следовательно, верхняя половина таблицы должна отражать приблизительно 19 появлений символов. Это просто: достаточно поместить разделительную линию между строкой о и строкой и. В результате этого верхняя половина таблицы будет отражать появление 18 символов, а нижняя - 20. Таким образом, мы получаем таблицу 11.2.
Таблица 11.2. Начало построения дерева Шеннона-Фано
Символ - Количество появлений
Пробел - 6
c - 6
o - 6
------------------------------------ разделительная линия 1
u - 4
d - 3
h - 3
w - 3
k - 2
H - 1
a - 1
l - 1
m - 1
? - 1
Теперь проделаем то же с каждой из частей таблицы: вставим линию между строками так, чтобы разделить каждую из частей. Продолжим этот процесс, пока все буквы не окажутся разделенными одна от другой. Результирующее дерево Шеннона-Фано представлено в таблице 11.3.
Таблица 11.3. Завершенное дерево Шеннона-Фано Символ Количество появлений
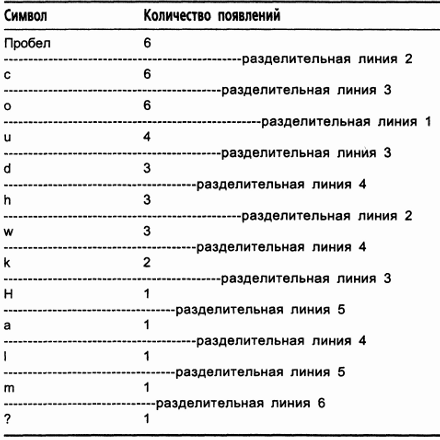
Я намеренно изобразил разделительные линии различными по длине, чтобы разделительная линия 1 была самой длинной, разделительная линия 2 немного короче и так далее, вплоть до самой короткой разделительной линии 6. Этот подход обусловлен тем, что разделительные линии образуют повернутое на 90° бинарное дерево (чтобы убедиться в этом, поверните таблицу на 90° против часовой стрелки). Разделительная линия 1 является корневым узлом дерева, разделительные линии 2 - двумя его дочерними узлами и т.д. Символы образуют листья дерева. Результирующее дерево в обычной ориентации показано на рис. 11.1
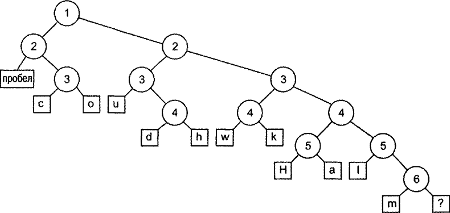
Рисунок 11.1. Дерево Шеннона-Фано
Все это очень хорошо, но как оно помогает решить задачу кодирования каждого символа и выполнения сжатия? Что ж, чтобы добраться до символа пробела, мы начинаем с коневого узла, перемещаемся влево, а затем снова влево. Чтобы добраться до символа с, мы смещаемся влево из корневого узла, затем вправо, а затем влево. Для перемещения к символу о потребуется сместиться влево, а затем два раза вправо. Если принять, что перемещение влево эквивалентно нулевому биту, а вправо - единичному, можно создать таблицу кодирования, приведенную в таблице 11.4.
Таблица 11.4. Коды Шеннона-Фано для примера предложения

Сейчас мы можем вычислить код для всей фразы. Он начинается с
11100011110000111110100010101100...
и содержит всего 131 бит. Если мы предполагаем, что исходная фраза закодирована кодом ASCII, т.е. один байт на символ, то оригинальная фраза заняла бы 256 байт, т.е. мы получаем коэффициент сжатия 54%.
Для декодирования сжатого потока битов мы строим то же дерево, которое было построено на этапе сжатия. Мы начинаем с корневого узла и выбираем из сжатого потока битов по одному биту. Если бит является нулевым, мы перемещаемся влево, если единичным - вправо. Мы продолжаем этот процесс до тех пор, пока не достигнем листа, т.е. символа, после чего выводим символ в поток восстановленных данных. Затем мы снова начинаем процесс с корневого узла дерева с целью извлечения следующего бита. Обратите внимание, что поскольку символы расположены только в листьях дерева, код одного символа не образует первую часть кода другого символа. Благодаря этому, неправильное декодирование сжатых данных невозможно. (Бинарное дерево, в котором данные размещены только в листьях, называется префиксным деревом (prefix tree).)
Однако при этом возникает небольшая проблема: как распознать конец потока битов? В конце концов, внутри класса мы будем объединять восемь битов в байт, после чего выполнять запись байта. Маловероятно, чтобы поток битов содержал количество битов строго кратное 8. Существует два возможных решения этой дилеммы. Первое - закодировать специальный символ, отсутствующий в исходных данных, и назвать его символом конца файла. Второе - записать в сжатый поток длину несжатых данных перед тем, как приступить к сжатию самих данных. Первое решение вынуждает нас найти отсутствующий в исходных данных символ и использовать его (это предполагает передачу этого символа в составе сжатых данных программе восстановления, чтобы она знала, что следует искать). Или же можно было бы принять, что хотя символы данных имеют размер, равный размеру одного байта, символ конца файла имеет длину, равную длину слова (и заданное значение, например 256). Однако мы будем использовать второе решение. Перед сжатыми данными мы будем сохранять длину несжатых данных, и таким образом во время восстановления будет в точности известно, сколько символов нужно декодировать.
Еще одна проблема применения кодирования Шеннона-Фано, на которую до сих пор мы не обращали внимания, связана с деревом. Обычно сжатие данных выполняется в целях экономии объема памяти или уменьшения времени передачи данных. Как правило, сжатие и восстановление данных разнесено во времени и пространстве. Однако алгоритм восстановления требует использования дерева. В противном случае невозможно декодировать закодированный поток. Нам доступны две возможности. Первая - сделать дерево статическим. Иначе говоря, одно и то же дерево будет использоваться для сжатия всех данных. Для некоторых данных результирующее сжатие будет достаточно оптимальным, для других - весьма далеким от приемлемого. Вторая возможность состоит в том, чтобы тем или иным способом присоединить само дерево к сжатому потоку битов. Конечно, присоединение дерева к сжатым данным ведет к снижению коэффициента сжатия, но с этим ничего нельзя поделать. Вскоре, при рассмотрении следующего алгоритма сжатия, мы покажем, как можно добавить дерево к сжатым данным.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Отправка с минимальной MTU
Отправка с минимальной MTU При работе в режиме детектирования транспортной MTU пакеты фрагментируются по MTU исходящего интерфейса или по транспортной MTU в зависимости от того, какое значение оказывается меньше. IPv6 требует минимального значения MTU 1280 байт. Это значение
4.7.1 Сжатие в PPP
4.7.1 Сжатие в PPP Может показаться не очень разумным включение одних и тех же октетов адреса и управления в каждый кадр. Партнеры на каждом конце связи PPP могут работать в режиме сжатия (compression) для исключения этих полей.Значения в поле протокола указывают, является ли
2.4.5.6. Сжатие данных
2.4.5.6. Сжатие данных Данные, сохраненные в пространстве таблиц Falcon сжаты на диске, но сохранены в несжатом формате в памяти. Сжатие происходит автоматически, когда данные переданы на
Глава 11. Сжатие данных.
Глава 11. Сжатие данных. Думая о данных, обычно мы представляем себе ни что иное, как передаваемую этими данными информацию: список клиентов, мелодию на аудио компакт-диске, письмо и тому подобное. Как правило, мы не слишком задумываемся о физическом представлении данных.
Сжатие данных
Сжатие данных Думая о данных, обычно мы представляем себе ни что иное, как передаваемую этими данными информацию: список клиентов, мелодию на аудио компакт-диске, письмо и тому подобное. Как правило, мы не слишком задумываемся о физическом представлении данных. Заботу об
Сжатие с использованием словаря
Сжатие с использованием словаря Вплоть до 1977 года, основные усилия в области исследования алгоритмов сжатия концентрировались вокруг алгоритмов кодирования с минимальной избыточностью, подобных алгоритмам Шеннона-Фано или Хаффмана, и были посвящены либо
Сжатие звука
Сжатие звука Формат WAVE достаточно точно сохраняет данные исходного аналогового сигнала, но является очень расточительным в отношении объема, занимаемого информацией. Тем не менее этот формат предпочтителен для первоначальной записи звуковых данных, которые
Форматы графических файлов. Сжатие изображения
Форматы графических файлов. Сжатие изображения Работая с изображениями в Photoshop, можно хранить файл в одном из нескольких графических форматов. Наиболее популярными из них являются JPEG, TIFF и PSD.JPEG – это формат, позволяющий создать минимальный по размерам файл с наименьшей
3.2. Размеры и сжатие файлов
3.2. Размеры и сжатие файлов Для чего нужно сжимать изображение Картинка, полученная с помощью шестимегапиксельной камеры, должна занять 18 Мбайт памяти. Если изображение записывать в память в таком виде, то даже в запоминающее устройство большой емкости удастся уместить
Сжатие данных
Сжатие данных Редко используемые файлы, которые хочется все-таки держать на жестком диске, следует хранить в сжатом виде, чтобы они занимали меньше места. Сжатие файлов данных также может потребоваться, если в обычном виде они не помещаются на какой-либо носитель.При
Сжатие видео во Flash. Кодеки On2 VP6 и Sorenson Spark
Сжатие видео во Flash. Кодеки On2 VP6 и Sorenson Spark В главе 1 мы уже говорили о видео. Давайте кратко повторим все, что уже успели узнать и, возможно, уже забыли.Итак, видеоинформация, хранящаяся в файле, практически всегда сжимается. Иначе и не получится: данные, содержащие
Сжатие файлов NTFS
Сжатие файлов NTFS При использовании разделов с файловой системой NTFS вы можете задействовать ее возможности для сжатия файлов. При этом происходит более слабое сжатие, чем при использовании архивов ZIP или RAR, но выполняется оно гораздо быстрее. Файлы, сжатые с помощью NTFS,
Сжатие данных
Сжатие данных Любой идеальный метод сжатия не должен допускать заметных потерь качества, то есть сокращение объема данных не должно приводить к потере информации. Это означает, что все изменения звукового сигнала должны быть ниже порога слышимости. Это особенно важно
Спецификация минимальной функциональной совместимости
Спецификация минимальной функциональной совместимости В 1996 г. институт NIST совместно с рядом поставщиков продуктов, лидирующих на рынке PKI - AT&T, IREBBN, Motorola Certicom, Nortel (Entrust), Cylink, Spyrus, DynCorp и VeriSign, - выступил с инициативой разработки спецификации минимальной функциональной