Бинарный поиск
Бинарный поиск
В случае отсортированного списка можно использовать более эффективный алгоритм бинарного поиска. Сначала рассмотрим его на примере массива, а затем покажем, как его изменить для связных списков.
Алгоритм бинарного поиска применим только для отсортированных контейнеров.
Массивы
Предположим, что у нас имеется отсортированный массив. Как было показано ранее, алгоритм последовательного поиска даже при использовании выхода из цикла в случае отсутствия в списке искомого элемента принадлежит к классу O(n). Каким образом можно улучшить быстродействие?
Ответом может служить бинарный поиск. Он основан на стратегии "разделяй и властвуй": начинаем с большой проблемы, разбиваем ее на маленькие проблемы, которые легче решить, а, затем, следовательно, решаем всю большую проблему.
Бинарный поиск работает следующим образом. Берем средний элемент массива. Равен ли он искомому элементу? Если да, то поиск успешно завершен. В противном случае, если искомый элемент меньше среднего, то можно сказать, что, если элемент присутствует в массиве, он находится в первой половине. С другой стороны, если искомый элемент больше среднего, он должен находиться во второй половине. Таким образом, одним сравнением мы разбили нашу проблему на две части. Теперь мы применяем тот же алгоритм к выбранной части массива: находим средний элемент и определяем, в какой половине (точнее уже в четвертой части) находится искомый элемент. Мы снова делим проблему на две части. Описанные операции продолжаются до тех пор, пока искомый элемент не будет найден (разумеется, если он присутствует в массиве).
Это и есть алгоритм бинарного поиска. Поскольку размер массива при каждом выполнении цикла уменьшается в два раза, быстродействие алгоритма будет выражаться как O(log(n)), т.е. скорость работы алгоритма примерно пропорциональна функции двоичного логарифма log(_2_) от количества элементов в массиве (таким образом, возведение количества элементов массива во вторую степень приведет к увеличению времени поиска только в два раза).
Ниже приведен пример выполнения бинарного поиска в массиве TList (функцию можно найти в файле TDTList.pas на Web-сайте издательства, в разделе сопровождающих материалов).
Листинг 4.9. Бинарный поиск в отсортированном массиве TList
function TDTListSortedIndexOf(aList : TList; aItem : pointer;
aCompare : TtdCompareFunc) : integer;
var
L, R, M : integer;
CompareResult : integer;
begin
{задать значения для индексов первого и последнего элементов}
L := 0;
R := pred(aList.Count);
while (L <= R) do begin
{вычислить индекс среднего элемента}
M := (L + R) div 2;
{сравнить значение среднего элемента с искомым значением}
CompareResult := aCompare(aList.List^[M], aItem);
{если значение среднего элемента меньше искомого значения, переместить левый индекс на позицию до среднего индекса}
if (CompareResult < 0) then
L := succ(M)
{если значение среднего элемента больше искомого значения, переместить правый индекс на позицию после среднего индекса}
else if (CompareResult > 0) then
R := pred(M)
{в противном случае искомый элемент найден}
else begin
Result := M;
Exit;
end;
end;
Result := -1;
end;
Для описания подмассива, рассматриваемого в текущий момент, используются две переменных - L и R, которые хранят, соответственно, левый и правый индексы. Первоначально значения этих переменных устанавливаются равными 0 (первый элемент массива) и Count-1 (последний элемент массива). Затем мы входим в цикл While, из которого выйдем после обнаружения в массиве искомого элемента или когда значение переменной L превысит значение переменной R, что означает, что искомый элемент в массиве отсутствует. При каждом выполнении цикла вычисляется индекс среднего элемента (фактически это среднее значение между L и R). Затем значение элемента со средним индексом сравнивается с искомым значением. Если значение среднего элемента меньше, чем искомое, мы переносим левый индекс на позицию после среднего. В противном случае мы переносим правый индекс на позицию перед средним. Таким образом, мы определяем новый подмассив для поиска. Если же значение среднего элемента равно искомому, поиск завершен.
Для примера на рис. 4.1 приведены шаги, выполняемые при бинарном поиске буквы d в отсортированном массиве, содержащем буквы от a до k. На шаге (а) переменная L указывает на первый элемент (индекс 0), а R - на последний (индекс 10). Это означает, что значение переменной M будет составлять 5. Далее мы выполняем сравнение: значение элемента с индексом 5 равно f, а это больше искомого значения d.
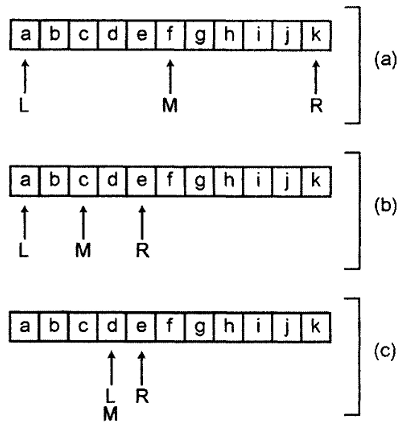
Рисунок 4.1. Бинарный поиск в массиве
Согласно алгоритму, мы устанавливаем значение R равным M-1 (таким образом, правая граница подмассива теперь находится слева от среднего элемента). Это означает, что значение R теперь равно 4. Новое значение среднего индекса будет равно 2, как показано на шаге (b). Выполняем сравнение: буква c (значение элемента с индексом 2) меньше, чем d.
Теперь, в соответствии с алгоритмом, необходимо установить индекс L за индексом M (т.е. M+1 или 3). Новое значение переменной M на шаге (с) равно 3. Выполняем сравнение: элемент с индексом 3 содержит букву d, а это и есть наше искомое значение. Поиск завершен.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Поиск
Поиск В процессе работы в компьютере накапливается большое количество файлов, и зачастую сориентироваться в них самостоятельно и найти нужный оказывается затруднительно. В этом случае вам на помощь придет система поиска. В Windows Vista она была значительно
Поиск на научных сайтах с использованием платформы Flexum «Поиск по научным сайтам»
Поиск на научных сайтах с использованием платформы Flexum «Поиск по научным сайтам» Тема научного поиска не прошла мимо разработчиков персональных поисковиков. Подробному рассказу о возможностях таких поисковых систем посвящена отдельная глава нашей книги (см. главу 6).
RSS-поиск
RSS-поиск Пополнять список своего RSS-агрегатора можно различными способами. Первый и наиболее распространенный – простой поиск сайтов по интересующим темам, а затем подписка на их RSS-ленты, если, конечно таковые имеются. Способ несложный, однако на редкость медленный и
Поиск
Поиск Если вы хотите удалить пункт Поиск (Найти) из меню кнопки Пуск, то откройте разделHKEY_CURRENT_USER SoftwareMicrosoftWindowsCurrentVersionPoliciesExplоrer и создайте параметр NoFind типа DWORD со значением, равным 1.После перезагрузки пункт Поиск исчезнет из меню кнопки Пуск, а также исчезнет команда
Поиск
Поиск Классический видЧтобы использовать классический вид поиска файлов без анимированного персонажа, то присвойте строковому параметру Use Search Asst значение no в разделе HKCUSoftwareMicrosoftWindowsCurrentVersionExplorerCabinetStateОчистка истории раннее вводимых словЕсли вы часто пользуетесь
Поиск
Поиск Строка поискаЧтобы скрыть строку поиска из IE7, в разделе HKCUSoftwarePoliciesMicrosoftInternet ExplorerInfoDeliveryRestrictionsсоздайте параметр типа DWORD ·NoSearchBox· со значением 1. Перезапустите IE7, чтобы изменения вступили в силу. Кнопка Поиск (IE6)Чтобы изменить адрес поисковика, который у вас
Поиск
Поиск На всех страницах сайта обязательно должно быть поле для поиска товаров. Удивительно, но в некоторых интернет-магазинах отсутствует поддержка поиска по сайту. Убедитесь, что на вашем сайте есть поиск. Более того, сделайте функцию поиска максимально заметной. Чаще
Яндекс. Поиск – быстрый поиск документов
Яндекс. Поиск – быстрый поиск документов Документы, как известно, имеют премерзкое свойство накапливаться. И чем больше документов, тем труднее в их залежах найти нужный. Электронные документы здесь не слишком отличаются от бумажных. Проблема места для хранения, правда,
Поиск
Поиск Поиск величины при вводе Каким способом можно производить поиск подходящих величин в момент ввода? Табличный курсор (визуально) должен перемещаться к наиболее подходящему значению при добавлении пользователем новых символов водимой величины.Первоначально код
Поиск
Поиск Управление отображением команды Поиск, которая также по умолчанию входит в состав меню кнопки Пуск, осуществляется в системном реестре в разделе HKEY_CURRENT_USERSoftwareMicrosoftWindowsCurrentVersionPoliciesExplorer с помощью REG_DWORD-параметра NoFind. Чтобы удалить данную функцию, следует присвоить
Линейный и бинарный поиск
Линейный и бинарный поиск Алгоритмы qFind() и qBinaryFind() в качестве параметров получают итераторы диапазона и значение, а возвращают итератор на элемент, который соответствует данному значению, или "end" итератор, если не найдено ни одного элемента. Алгоритм бинарного поиска
Глава 12 Поиск с предпочтением: эвристический поиск
Глава 12 Поиск с предпочтением: эвристический поиск Поиск в графах при решении задач, как правило, невозможен без решения проблемы комбинаторной сложности, возникающей из-за быстрого роста числа альтернатив. Эффективным средством борьбы с этим служит эвристический
Поиск
Поиск Проблема поиска информации существовала всегда. Поиск информации на локальном компьютере напоминает работу поисковых систем Интернета. В данном случае можно также выделить два основных направления поиска: обычный и усложненный. Под обычным подразумевается поиск
Бинарный метод
Бинарный метод Несмотря на наукообразное название, этот метод является самым простым и традиционным. Эксперт просто утверждает, присутствует данный признак в почерке или нет. В первом случае мы скажем, что степень или фактор присутствия принимает значение 1, во втором