Что такое алгоритм?
Что такое алгоритм?
Может показаться странным, но алгоритмы используются при написании любой программы, просто мы не считаем их алгоритмами: "Это вовсе не алгоритм, а просто порядок вычислений".
Алгоритм (algorithm) представляет собой пошаговую инструкцию выполнения вычислений или процесса. Это достаточно вольное определение, но как только читатель поймет, что ему нечего бояться алгоритмов, он легко научиться их идентифицировать.
Вернемся к дням, когда мы учились в начальных классах и рассматривали простое сложение в столбик.
Учитель писал на доске пример сложения:
45
17+
----
а затем просил кого-нибудь из учеников вычислить сумму. Каждый про себя думал, как это сделать: начинаем со столбца единиц, складываем 5 и 7, получаем 12, пишем 2 в столбце единиц, а затем 1 переносим над 4.
1
45
17+
----
62
Затем складываем перенесенную единицу с 4 и еще одну 1, в результате получаем 6, которое и пишем под столбцом десятков. Вот и получился ответ 62.
Обратите внимание, что описанный выше ход мыслей представлял собой алгоритм сложения. Учитель не говорил, как складывать числа 45 и 17, он просто объяснил общий принцип сложения двух чисел. Вскоре любой ученик, применяя тот же алгоритм, мог складывать одновременно несколько чисел, содержащих много цифр. Конечно, в те дни вы не знали, что это был алгоритм, вы просто складывали числа.
В мире программирования мы представляем себе алгоритмы как сложные методы выполнения определенных вычислений. Например, если имеется массив записей покупателей, в котором необходимо найти определенного покупателя (скажем, Джона Смита (John Smith)), то можно действовать следующим образом: считывать каждый элемент массива, пока не будет найдена нужная запись или не будет достигнут конец массива. Для вас это может показаться очевидным методом решения поставленной задачи, тем не менее, в мире алгоритмов он известен как последовательный поиск (sequential search).
Существуют и другие методы поиска элемента "John Smith" в нашем гипотетическом массиве. Например, если элементы в массиве отсортированы по фамилии, то можно воспользоваться алгоритмом бинарного поиска (binary search). Согласно ему, мы берем средний элемент массива. Это "John Smith"? Если да, то поиск закончен. Если элемент меньше чем "John Smith" (под "меньше" здесь понимается, что он стоит "раньше" в алфавитном порядке), то можно сказать, что искомый элемент находится во второй половине массива, если же он больше, то нужный нам элемент находится в первой половине массива. Далее операции повторяются (т.е. мы снова берем средний элемент выбранной части массива, сравниваем его с элементом "John Smith" и выбираем ту часть, в которой этот элемент должен находиться) до тех пор, пока элемент не будет найден, или пока левая часть массива после очередного разбиения не окажется пустой.
Такой алгоритм кажется более сложным, чем первый рассмотренный алгоритм. Последовательный поиск можно очень просто и удобно организовать с помощью цикла For, вызвав в нужный момент оператор Break. Бинарный поиск требует выполнения более сложный операций с локальными переменными. Таким образом, может показаться, что последовательный поиск быстрее только потому, что его реализация проще.
Что ж, добро пожаловать в мир анализа алгоритмов, в котором мы постоянно проводим эксперименты и пытаемся сформулировать законы работы различных алгоритмов!
Анализ алгоритмов
Рассмотрим два возможных варианта поиска в массиве элемента "John Smith": последовательный поиск и бинарный поиск. Мы напишем код для обоих вариантов, а затем определим производительность каждого из них. Реализация простого алгоритма последовательного поиска приведена в листинге 1.1.
Листинг 1.1. Последовательный поиск имени в массиве элементов
function SeqSearch( aStrs : PStringArray;
aCount : integer; const aName : string5): integer;
var
i : integer;
begin
for i := 0 to pred(aCount) do
if CompareText(aStrs^[i], aName) = 0 then begin
Result := i;
Exit;
end;
Result := -1;
end;
В листинге 1.2 содержится код более сложного бинарного поиска. (пока что мы не будем объяснять, что происходит в этом коде. Алгоритм бинарного поиска подробно рассматривается в главе 4.)
Очень трудно оценить быстродействие каждого из приведенных кодов только по самому их виду. Это основной принцип, которому мы должны всегда следовать: нельзя оценивать скорость работы кода по его виду. Единственным методом определения быстродействия должно быть его выполнение. И только. Если есть возможность выбирать между несколькими алгоритмами, как в рассматриваемом случае, то для выбора более эффективного алгоритма с нашей точки зрения нужно оценить время выполнения кода в различных условиях и на различных исходных данных.
Традиционно для оценки времени работы кода используется профилировщик (profiler). Профилировщик загружает тестируемое приложение и точно измеряет время выполнения отдельных подпрограмм. Профилировщик рекомендуется использовать во всех случаях. Только профилировщик поможет определить, на что тратится большая часть времени выполнения кода, а, следовательно, над какими подпрограммами стоит поработать с целью увеличения быстродействия всего приложения.
Листинг 1.2. Бинарный поиск имени в массиве элементов
function BinarySearch( aStrs : PStringArray;
aCount : integer; const aName : string5): integer;
var
L, R, M : integer;
CompareResult : integer;
begin
L := 0;
R := pred(aCount);
while (L <= R) do begin
M := (L + R) div 2;
CompareResult := CompareText(aStrs^[M], aName);
if (CompareResult = 0) then begin
Result := M;
Exit;
end
else
if (CompareResult < 0) then
L :=M + 1
else
R := M - 1;
end;
Result := -1;
end;
В компании TurboPower Software, где работает автор книги, используется профессиональный профилировщик из пакета Sleuth QA Suite. Все коды, приведенные в книге, были протестированы как с помощью StopWatch (название профилировщика из пакета Sleuth QA Suite), так и с помощью Code Watch (название отладчика использования ресурсов и утечки памяти из пакета Sleuth QA Suite). Тем не менее, даже если у вас нет своего профилировщика, вы можете проводить тестирование и определять время выполнения. Просто это не совсем удобно, поскольку в код приходится помещать вызовы функций работы со временем. Нормальные профилировщики не требуют внесения в код изменений, они оценивают время за счет изменения выполняемого файла в памяти компьютера непосредственно в процессе выполнения.
Для тестирования и определения времени выполнения алгоритмов поиска была написана специальная программа. Фактически она определяет системное время вначале перед, а затем и после выполнения кода. По результатам определения времени вычисляется время выполнения. Принимая во внимание, что в настоящее время компьютеры стали достаточно мощными, а часы системного времени характеризуются сравнительно низкой точностью, как правило, для более точной оценки быстродействия код выполняется несколько сот раз, а затем определяется среднее значение. (Кстати, эта программа была написана в среде 32-разрядной Delphi и не будет компилироваться под Delphi1, поскольку она выделяет память для массивов из кучи, которая превышает граничное для Delphi1 значение 64 Кб.)
Эксперименты по оценке быстродействия алгоритмов проводились различными способами. Сначала для обоих алгоритмов было определено время, необходимое для поиска фамилии "Smith" в массивах из 100, 1000, 10000 и 100000 элементов, которые содержали искомый элемент. В следующей серии экспериментов осуществлялся поиск того же элемента в массивах того же размера, но при отсутствии в них искомого элемента. Результаты экспериментов приведены в таблице 1.1.
Таблица 1.1. Времена выполнения последовательного и бинарного поиска
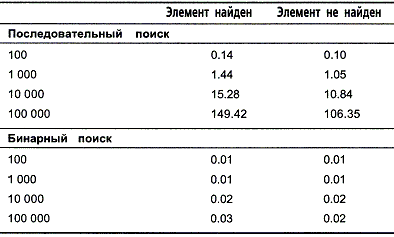
Как видно из таблицы, эксперименты показали очень интересные результаты. Время выполнения последовательного поиска пропорционально количеству элементов в массиве. Таким образом, можно сказать, что характеристики выполнения последовательного поиска линейны.
Результаты выполнения бинарного поиска проанализировать сложнее. Может даже показаться, что из-за очень быстрого выполнения алгоритма при определении времени мы столкнулись с проблемой потери точности. Очевидно, что зависимость между количеством элементов в массиве и временем выполнения алгоритма не является линейной. Но по приведенным данным трудно определить тип зависимости.
Эксперименты были проведены повторно. При этом времена выполнения умножались на коэффициент 100.
Таблица 1.2. Повторное тестирование бинарного поиска

Эти данные более достоверны. Из них видно, что десятикратное увеличение количества элементов в массиве приводит к увеличению времени выполнения на определенную постоянную величину (примерно на 0.5). Это логарифмическая зависимость, т.е. время бинарного поиска пропорционально логарифму количества элементов в массиве.
(Если вы не математик, то вам будет не так легко это понять. Вспомните из своих школьных дней, что для вычисления произведения двух чисел можно вычислить их логарифмы, сложить их, а затем определить антилогарифм суммы. Поскольку в рассматриваемых экспериментах количество элементов умножается на 10, то в логарифмической зависимости это будет эквивалентно прибавлению константы. Как раз это мы и видим в результатах экспериментов: для каждого последующего массива время увеличивается на 0.5.)
Что мы узнали из результатов проведенных экспериментов? Во-первых, теперь мы знаем, что единственным методом определения быстродействия алгоритма является оценка времени его выполнения.
----
В общем случае, единственным методом определения быстродействия отдельной части кода является оценка времени ее выполнения. Это справедливо как в отношении широко известных алгоритмов, так и в отношении алгоритмов, разработанных лично вами. Не нужно предполагать, просто измерьте время выполнения.
----
Во-вторых, мы определили, что по своей природе последовательный поиск является линейным, а бинарный поиск - логарифмическим. Если быть поближе к математике, то можно взять эти статистические результаты и теоретически доказать их справедливость. Тем не менее, в этой книге мы не будет перегружать текст математическими выкладками. Можно найти немало книг, в которых приведены эти выкладки (см., например, тома "Фундаментальные алгоритмы на С++" и "Фундаментальные алгоритмы на С" Роберта Седжвика, вышедшие в свет в издательстве "Диасофт").
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
8.1.1 Алгоритм
8.1.1 Алгоритм Сразу после переключения контекста ядро запускает алгоритм планирования выполнения процессов (Рисунок 8.1), выбирая на выполнение процесс с наивысшим приоритетом среди процессов, находящихся в состояниях "резервирования" и "готовности к выполнению, будучи
Глава 1. Что такое алгоритм?
Глава 1. Что такое алгоритм? Для книги, посвященной алгоритмам, очень важно заранее оговорить, о чем, собственно, пойдет речь. Как мы увидим, одной из самых важных причин для понимания и исследования алгоритмов является ускорение работы приложений. Да, конечно, иногда нужны
Алгоритм max()
Алгоритм max() template class Type const Type&max( const Type &aval, const Type &bval );template class Type, class Compare const Type&max( const Type &aval, const Type &bval, Compare comp );max() возвращает наибольшее из двух значений aval и bval. В первом варианте используется оператор "больше", определенный в классе Type; во втором - операция
Алгоритм min()
Алгоритм min() template class Type const Type&min( const Type &aval, const Type &bval );template class Type, class Compare const Type&min( const Type &aval, const Type &bval, Compare comp );min() возвращает меньшее из двух значений aval и bval. В первом варианте используется оператор “меньше”, определенный для типа Type; во втором - операция
Алгоритм merge()
Алгоритм merge() template class InputIterator1, class InputIterator2,class OutputIterator OutputIteratormerge( InputIterator1 first1, InputIterator1 last1,InputIterator2 first2, InputIterator2 last2,OutputIterator result );template class InputIterator1, class InputIterator2,class OutputIterator, class Compare OutputIteratormerge( InputIterator1 first1, InputIterator1 last1,InputIterator2 first2, InputIterator2 last2,OutputIterator result, Compare comp );merge() объединяет
Алгоритм mismatch()
Алгоритм mismatch() template class InputIterator1, class InputIterator2 pairInputIterator1, InputIterator2mismatch( InputIterator1 first,InputIterator1 last, InputIterator2 first2 );template class InputIterator1, class InputIterator2,class BinaryPredicate pairInputIterator1, InputIterator2mismatch( InputIterator1 first, InputIterator1 last,InputIterator2 first2, BinaryPredicate pred );mismatch() сравнивает две последовательности и находит
Алгоритм nth_element()
Алгоритм nth_element() template class RandomAccessIterator voidnth_element( RandomAccessIterator first,RandomAccessIterator nth,RandomAccessIterator last );template class RandomAccessIterator, class Compare voidnth_element( RandomAccessIterator first,RandomAccessIterator nth,RandomAccessIterator last, Compare comp );nth_element() переупорядочивает последовательность, ограниченную диапазоном [first,last), так что все
Алгоритм partial_sort()
Алгоритм partial_sort() template class RandomAccessIterator voidpartial_sort( RandomAccessIterator first,RandomAccessIterator middle,RandomAccessIterator last );templatepartial_sort() сортирует часть последовательности, укладывающуюся в диапазон [first,middle). Элементы в диапазоне [middle,last) остаются неотсортированными. Например, если дан массивint ia[] =
Алгоритм partial_sum()
Алгоритм partial_sum() template class InputIterator, class OutputIterator OutputIteratorpartial_sum(InputIterator first, InputIterator last,OutputIterator result );template class InputIterator, class OutputIterator,class BinaryOperation OutputIteratorpartial_sum(InputIterator first, InputIterator last,OutputIterator result, BinaryOperation op );Первый вариант partial_sum() создает из последовательности, ограниченной
Алгоритм partition()
Алгоритм partition() template class BidirectionalIterator, class UnaryPredicate BidirectionalIteratorpartition(BidirectionalIterator first,BidirectionalIterator last, UnaryPredicate pred );partition() переупорядочивает элементы в диапазоне [first,last). Все элементы, для которых предикат pred равен true, помещаются перед элементами, для которых он равен false.
Алгоритм random_shuffle()
Алгоритм random_shuffle() template class RandomAccessIterator voidrandom_shuffle( RandomAccessIterator first,RandomAccessIterator last );template class RandomAccessIterator,class RandomNumberGenerator voidrandom_shuffle( RandomAccessIterator first,RandomAccessIterator last,RandomNumberGenerator rand);random_shuffle() переставляет элементы из диапазона [first,last) в случайном порядке. Во втором варианте можно
Алгоритм upper_bound()
Алгоритм upper_bound() templateclass ForwardIterator, class Type ForwardIteratorupper_bound( ForwardIterator first,ForwardIterator last, const Type &value );template class ForwardIterator, class Type, class Compare ForwardIteratorupper_bound( ForwardIterator first,ForwardIterator last, const Type &value,Compare comp );upper_bound() возвращает итератор, указывающий на последнюю позицию в отсортированной