Деревья с двоичным основанием
Деревья с двоичным основанием

Описанный выше метод двоичного поиска можно представить в виде древовидной структуры. Дерево будет содержать два типа узлов: тестовые и окончательные. Каждый тестовый узел дерева проверяет один разряд числа. По тому, равен разряд 1 или 0, в качестве следующего выбирается один из двух узлов следующего уровня. Начиная с вершины дерева[ 55 ], первый узел проверяет первый разряд числа (самый левый). Второй слой дерева содержит два текстовых узла, один из которых выбирается, если первый разряд был равен 0, а другой — если первый разряд был равен 1. На третьем уровне имеется четыре узла, на четвертом — восемь и так далее вплоть до десятого узла, на котором расположено 512 тестовых узлов. Одиннадцатый уровень — последний для данного дерева и содержит 1024 окончательных узла. Окончательный узел содержит точное значение искомого числа.
Итак, для поиска числа мы начинаем с вершины дерева и проверяем разряды: слева направо. На каждом уровне дерева проверяется один из разрядов. После десяти проверок мы оказываемся в одном из окончательных узлов и можем точно назвать число.
Мы только что описали двоичное дерево. Оно сбалансированное, так как присутствуют все узлы. При поиске по таблице могут присутствовать не все узлы, так как в таблице присутствуют не все возможные элементы. Следовательно, и проверяются не все разряды числа, некоторые уровни могут отсутствовать. Такое дерево в отличии от двоичного дерева, где присутствуют все узлы, называется деревом с двоичным основанием (binaryradix tree).
Использование деревьев с двоичным основанием в AS/400 для реализации машинных индексов мы рассмотрим на примере рисунка 6.4. На нем показан простой файл из девяти записей, упорядоченных в порядке поступления. Каждая запись имеет несколько полей, на рисунке показаны лишь некоторые. Одно из полей — поле имени — предназначено для использования в качестве ключа. Для файла построен индекс, который также показан на рисунке. Каждая запись индекса имеет только два поля: поле ключа и логический адрес записи. Девять элементов индекса отсортированы по порядку значений ключа. В данном случае, ключи отсортированы по алфавиту, и первым элементом является Baker, а последним Wu. Поле логического адреса записи задает относительную позицию соответствующей записи в исходном файле, логическая адресация всегда начинается с 0 (для первой записи). Элемент для Baker указывает, что запись Baker является в файле седьмой.
Файл Индекс Адрес Имя Дата рождения Должность Имя логической записи 0 JONES 082140 A BAKER 006 SMITH 122750 K BARNS 007 WU 041259 Z CARSON 008 MARKLY 111163 T JOHNSON 005 PETERS 070457 C JONES 000 JOHNSON 062753 A MARKLY 003 BAKER 031747 C PETERS 004 BARNS 090959 B SMITH 001 CARSON 013147 B WU 002
Рисунок 6.4. Пример простого файла и индекса
Точный формат логического адреса записи изменяется на AS/400 в зависимости от того, как используется индекс. Например, как уже говорилось, каждый элемент сегмента индекса области данных содержит ключ и относительный адрес, в свою очередь включающий в себя номер области данных, идентификацию сегмента области данных записей и порядковый номер записи. Данный относительный адрес уникальным образом идентифицирует запись, соответствующую ключу. В других случаях применения индекса используется иная форма относительных адресов.
Давайте с помощью этого индекса создадим дерево с двоичным основанием. На рисунке 6.5 показан индекс с рисунка 6.4 с представлением поля ключа в коде EBCDIC. Индекс представлен в шестнадцатеричной и двоичной формах. Например, первая буква имени Baker имеет шестнадцатеричное значение С2. В двоичной системе счисления С2 будет 11000010. Вторая буква имени Baker имеет шестнадцатеричное значение С1 (11000001 двоичное). Каждый ключ располагается в памяти в виде цепочки нулей и единиц, как показано на рисунке.
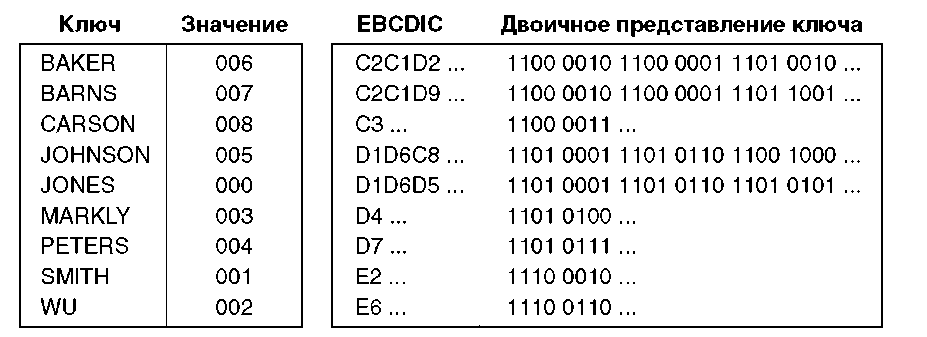
Теперь с помощью двоичного представления ключей можно создать дерево с двоичным основанием. При построении дерева ключи добавляются по одному. Сначала последовательность битов каждого нового ключа просматривается слева направо в поисках первого, отличающего данный ключ от всех ключей, уже вставленных в дерево. Предположим, что единственным элементом дерева является Baker и мы хотим добавить элемент Barns. Взглянув на рисунок 6.5, можно увидеть, что первым отли
чающимся битом (сканирование всегда идет слева направо) будет пятый в третьем байте. Если в дереве только два элемента Baker и Barns, то чтобы отличить один от другого, достаточно проверить пятый разряд третьего байта. Если разряд равен 0, то это элемент Baker, а если 1, то Barns.
Допустим, теперь мы хотим добавить к дереву Carson. Тогда первым битом, отличающимся и от Baker, и от Barns, будет восьмой первого байта.
Последовательность построения дерева показана на рисунке 6.6. На первом шаге в дереве есть единственный окончательный узел для Baker. Окончательный узел содержит некоторый текст (в данном случае «Baker») и логический адрес записи 006. На втором шаге к дереву добавляется Barns. Здесь к дереву непосредственно над Baker добавляется тестовый узел для проверки пятого разряда третьего байта. Тестовый узел содержит общий текст ключей (BA) и номер бита, который должен проверяться в следующем байте. В нашем примере с двумя байтами совпадающего текста (ВА) ясно, что бит, нуждающийся в проверке, находится в следующем (третьем) байте, задавать который явно не обязательно. При выборе следующего узла всегда берется левый, если проверяемый бит равен 0, и правый — в противоположном случае. Справа от первого окончательного узла добавлен второй окончательный узел для Barns с логическим адресом записи 007. Обратите внимание, что после удаления общего текста, терминальные узлы содержат только остатки имен (KER и RNS для Baker и Barns соответственно).
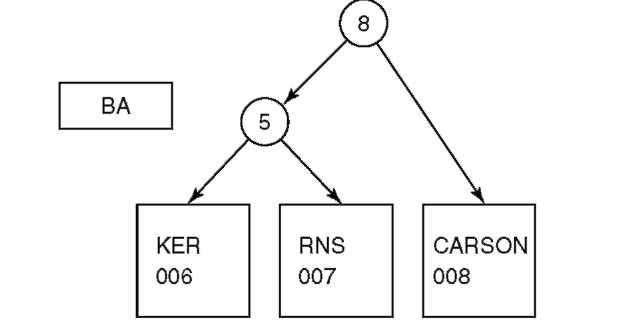
Шаг 1: В дереве только BAKER

Шаг 2: Добавляем BARNES
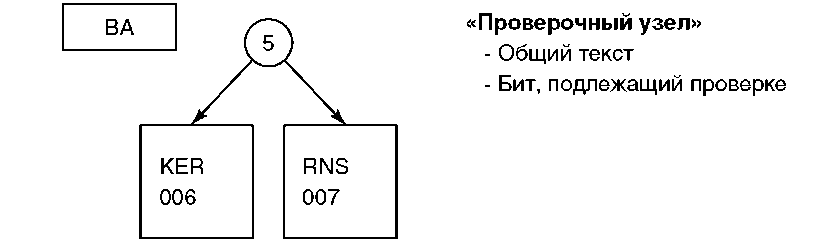
Шаг 3: Добавляем CARSON
Рисунок 6.6. Построение дерева с двоичным основанием
На шаге 3 к дереву добавляется Carson. Создается новый тестовый узел для проверки восьмого бита первого байта. В новом тестовом узле нет общего текста. Если при проверке восьмой бит первого байта равен 0, то далее следует проверить расположенный левее тестовый узел для Baker/Barns. Если же восьмой бит первого байта равен 1, то следующим будет окончательный узел справа для Carson. Данный узел содержит текст (CARSON) и логический адрес записи 008.
На рисунке 6.7 дерево показано полностью, со всеми девятью элементами. Тестовый узел наверху дерева называется корневым узлом. Хотя в данном примере представлен относительно небольшой индекс, он иллюстрирует многие характеристики дерева с двоичным основанием.
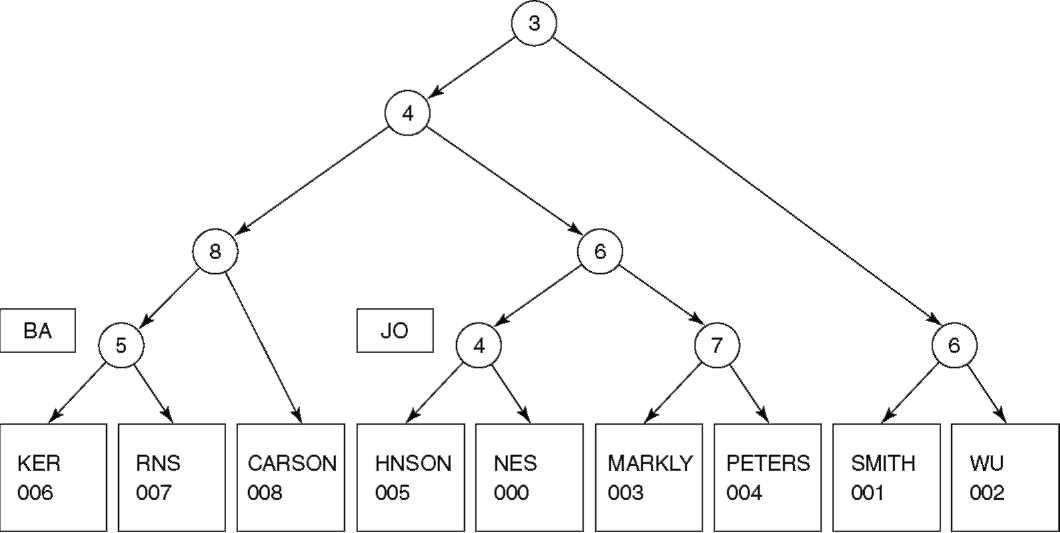
Рисунок 6.7. Пример дерева с двоичным основанием
Любое имя в дереве может быть найдено уже описанным методом. Но как быть с именами, которых в дереве нет? Предположим, что мы пытаемся найти там имя Soltis. Проверяем третий бит первого байта и видим, что он равен 1, затем — шестой бит первого байта, который равен 0. Это приводит нас к окончательному узлу для Smith. Теперь понятна причина хранения текста в окончательных узлах — на один и тот же окончательный узел может отображаться много имен. При достижении окончательного узла необходимо сравнить хранящийся там текст с остатком имени, поиск которого мы ведем. Если они совпали — мы нашли правильный окончательный узел, если нет — искомое имя отсутствует в дереве.
Другая характеристика дерева связана со способом добавления к нему элементов. Мы всегда просматриваем строку битов для каждого нового элемента слева направо в поиске первого бита нового ключа, отличающего его от всех, уже находящихся в дереве. Таким образом, гарантируется, что при проходе по любому пути в дереве биты проверяются слева направо. В тестовом узле никогда не приходится возвращаться к началу имени: мы всегда движемся вперед.
Метод, используемый для вставки элементов, также гарантирует, что дерево всегда будет иметь одну и ту же конфигурацию, независимо от порядка добавления элементов. Более того, окончательные узлы всегда упорядочены в соответствии со значениями ключей слева направо. В нашем примере, окончательные узлы расположены в алфавитном порядке имен в ключевом поле. Это не случайность, а свойство дерева. Дерево само по себе обеспечивает логическую последовательность ключей, так что сортировка физических записей не нужна.
Элемент дерева можно также удалить. Это простая операция, так как на окончательный узел может указывать один и только один тестовый узел. Возьмите имя, подлежащее удалению, отыщите в дереве соответствующий ему окончательный узел, удалите его, вернитесь к расположенному выше тестовому узлу и объедините его со вторым окончательным узлом в новый окончательный узел.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
14.4.1. Введение в двоичные деревья
14.4.1. Введение в двоичные деревья Массивы являются почти простейшим видом структурированных данных. Их просто понимать и использовать. Хотя у них есть недостаток, заключающийся в том, что их размер фиксируется во время компиляции. Таким образом, если у вас больше данных,
Деревья и узлы
Деревья и узлы При работе с XSLT следует перестать мыслить в терминах документов и начать — в терминах деревьев. Дерево представляет данные в документе в виде множества узлов — элементы, атрибуты, комментарии и т.д. трактуются как узлы — в иерархии, и в XSLT структура дерева
Внутренняя организация дерева с двоичным основанием
Внутренняя организация дерева с двоичным основанием Внутренняя форма хранения дерева с двоичным основанием оптимизирована как с точки зрения производительности, так и занимаемого пространства. Первая базовая структура для дерева с двоичным основанием была создана
3.1. Структуры и деревья
3.1. Структуры и деревья Чтобы легче было понять сложную структуру, ее обычно представляют в виде дерева, в котором каждому функтору соответствует вершина, а компонентам соответствуют ветви дерева. Каждая ветвь может указывать на другую структуру, так что мы можем иметь
Глава 9 Деревья и кустарники
Глава 9 Деревья и кустарники В данной главе описываются примеры проектирования всевозможных растительных форм, а также возможности использования библиотек растительных элементов в некоторых программах. Здесь рассмотрены приложения 3D Home Architect Design Suite Deluxe и
9.3. Деревья
9.3. Деревья Я не увижу никогда, наверное, Поэму столь прекрасную как дерево. Джойс Килмер, «Деревья»[11] В информатике идея дерева считается интуитивно очевидной (правда, изображаются они обычно с корнем наверху, а листьями снизу). И немудрено, ведь в повседневной жизни мы
Глава 8. Бинарные деревья.
Глава 8. Бинарные деревья. Подобно массивам и связным спискам, деревья того или иного вида - это структуры данных, которые используются программистами практически повсеместно. В главе 3 были рассмотрены односвязные списки, в которых существовала единственная связь,
Скошенные деревья
Скошенные деревья Как бы то ни было, ознакомившись с этими операциями простых и спаренных двухсторонних и односторонних поворотов, мы может их использовать в структуре данных, называемой скошенным деревом. Скошенное дерево (splay tree) - это дерево бинарного поиска,
Красно-черные деревья
Красно-черные деревья Рассмотрев простые и спаренные двусторонние и односторонние повороты и ознакомившись с реорганизацией деревьев бинарного поиска за счет использования скошенных деревьев, пора приступить к исследованию соответствующего алгоритма
Деревья
Деревья Прежде, чем мы приступим к рассмотрению типов узлов и отношений между ними, необходимо определиться с самой структурой дерева. Древовидная структура задает для своих элементов отношение ветвления, очень похожее на строение обычного дерева — есть корневой узел
Окна - это деревья и прямоугольники
Окна - это деревья и прямоугольники Рассмотрим оконную систему с произвольной глубиной вложения окон: Рис. 15.5. Окна и подокнаВ соответствующем классе WINDOW мы найдем компоненты двух основных видов:[x]. те, что рассматривают окно как иерархическую структуру (список подокон,
Деревья - это списки и их элементы
Деревья - это списки и их элементы Класс дерева TREE - еще один яркий пример множественного наследования.Деревом называется иерархическая структура, составленная из узлов с данными. Обычно ее определяют так: "Дерево либо пусто, либо содержит объект, именуемый его корнем, с
У15.1 Окна как деревья
У15.1 Окна как деревья Класс WINDOW порожден от TREE [WINDOW]. Поясните суть родового параметра. Покажите, какое новое утверждение появится в связи с этим в инварианте
У15.7 Деревья
У15.7 Деревья Согласно одной из интерпретаций, дерево - это рекурсивная структура, представляющая собой список деревьев. Замените приведенное в этой лекции описание класса TREE как наследника LINKED_LIST и LINKABLE новым вариантомclass TREE [G] inheritLIST [TREE [G]]feature ...endРасширьте это описание до
Деревья аннулирования сертификатов
Деревья аннулирования сертификатов Деревья аннулирования сертификатов, ДАС (Certificate Revocation Trees - CRTs) - это технология аннулирования, разработанная американской компанией Valicert. Деревья ДАС базируются на хэш-деревьях Merkle, каждое дерево позволяет отобразить всю известную