Процессоры Muskie первого поколения
 Процессоры Muskie первого поколения
Процессоры Muskie первого поколения
Процессор первого поколения, известный под названием Muskie[ 19 ], был разработан в Рочестере в 1995 году как старшая модель процессора для AS/400. На тот момент он был самым быстрым процессором PowerPC и самым быстрым микропроцессором IBM. Первоначально он имел время цикла 6,5 наносекунд, что соответствует тактовой частоте 154 МГц. В 1996 году мы представили еще более быстрые его версии со временем цикла 5,5 наносекунд (182 МГц).
Muskie явно предназначен для использования в системах коммерческих расчетов, а не в технических рабочих станциях. И хотя это не самая последняя наша разработка PowerPC, его стоит рассмотреть подробнее, чтобы понять различия между процес
сорами, предназначенными для коммерческих и научно-технических расчетов. Тогда станет ясно, почему было решено сконцентрировать усилия Рочестера на разработке процессоров для коммерческих вычислений (и для AS/400, и для RS/6000), тогда как Остин занимается процессорами для научно-технических расчетов.
Процессор Muskie — одномодульный, многокристальный, конвейерный, суперскалярный и предназначен для старших RISC-моделей AS/400. Это единственный многокристальный процессор семейства PowerPC. Процессор построен по четырех-канальной (4-way) суперскалярной схеме, то есть может выбирать и исполнять до четырех команд за цикл. Кроме того, поддерживаются и многопроцессорные конфигурации.
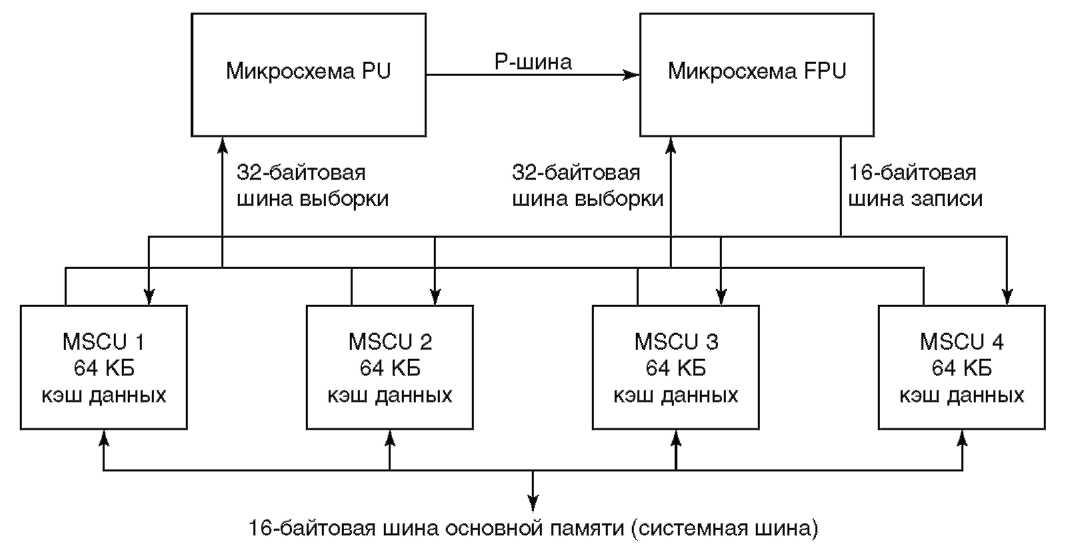
Рисунок 2.4 Структурная схема процессора Muskie
Однокристальные процессоры обычно изготавливаются по технологии КМОП (комплиментарный метал-окисел-полупроводник). Микросхемы КМОП потребляют меньше мощности, чем микросхемы других технологий, то есть рассеивают меньше тепла. В результате, на одном кристалле может быть размещено больше транзисторов. Пока все схемы размещены на одном кристалле, маломощные цепи КМОП работают очень быстро. Иначе обстоит дело со связями между кристаллами. При использовании усилителей КМОП в многокристальном процессоре производительность уменьшается.
Все шесть кристаллов Muskie используют технологию БиКМОП (Биполярный-КМОП). Биполярная технология имеет высокое быстродействие (в этом ее преимущество) и потребляет большую мощность. Недостаток БиКМОП — большое выделение тепла. Из-за объема рассеиваемого тепла биполярные кристаллы не могут использовать столь же высокую плотность упаковки, как кристаллы КМОП. Технология БиКМОП позволяет размещать на одном кристалле как биполярные цепи (для внешних усилителей), так и цепи КМОП (для схем внутри кристалла).
Вместе со всеми вспомогательными схемами процессор Muskie занимает семь кристаллов. Последние упакованы в один многокристальный модуль, насчитывающий более 25 миллионов транзисторов. Один из кристаллов управляет вводом-выводом, то есть технически не является частью процессора. Прочие шесть кристаллов, составляющих процессор, вместе с соединениями между ними показаны на рисунке 2.4.
БиКМОП отлично подходит для многокристального процессора. Например, известный Intel Pentium Pro выполнен в виде двухкристального модуля и использует технологию БиКМОП по тем же причинам, что и Muskie.
Чтобы понять, почему для реализации данной технологии требуется так много транзисторов, рассмотрим микросхемы процессора подробнее.
В состав шести основных кристаллов, составляющих процессор, входят кристалл процессорного блока PU (Processing Unit), кристалл блока плавающей точки FPU (Floating-Point Unit) и четыре одинаковых кристалла блоков управления основной памятью MSCU (Main Store Control Unit). На кристалле PU расположены кэш команд, блок переходов и блок фиксированной точки. Кэш команд размером 8 килобайт имеет ширину 32 байта. Он может выбирать из памяти за один такт 32 байта (8 команд[ 20 ]). Для передачи больших объемов данных за один такт имеются 32-байтовые тракты данных. Даже регистровый стек блока фиксированной точки рассчитан на загрузку или сохранение четырех 64-разрядных регистров за один такт.
FPU размещается на отдельном кристалле и поддерживает стандарт IEEE для операций с плавающей точкой. Он спроектирован так, что способен выдавать результат в каждом такте, обеспечивая очень высокую производительность команд с плавающей точкой. Четыре команды за такт передаются от кристалла PU на кристалл FPU по 16-байтовой P-шине. Все данные, хранимые в памяти, также пересылаются из PU по P-шине в кэш данных. Данные для FPU выбираются из кэша данных со скоростью 32 байта за такт. Данные из FPU и PU пересылаются в кэш данных по 16-байтовой шине сохранения.
MSCU содержит кэш данных, а также интерфейс памяти. Все четыре кристалла совместно реализуют 256-килобайтовый кэш данных и интерфейсы к шинам данных (см. рисунок 2.4). Обращения к кэшу данных выполняются конвейерно, так что за каждый такт считываются 32 и сохраняются 16 байт данных. MSCU поддерживает многопроцессорные конфигурации, обеспечивая когерентность кэшей разных процессоров.
PU и FPU вместе насчитывают 5 конвейеров, однако в каждом цикле может быть распределено только 4 команды, а именно:
команда перехода (включая операцию над содержимым регистра условия);
команда загрузки/сохранения;
команда арифметики с фиксированной точкой;
команда фиксированной точки (логическая, сдвиг или циклический сдвиг; или команда плавающей точки).
Команды плавающей точки исполняются в FPU, но не могут быть выбраны на выполнение одновременно с командами фиксированной точки для логических операций, сдвига или циклического сдвига, выполняемыми в PU. Обратите внимание, что конвейер загрузки/сохранения выполняет выборку и запись данных как с фиксированной, так и с плавающей точкой. Несколько конвейеров выполняют фрагменты нескольких команд одновременно.
Процессор Muskie также может работать с разделяемой памятью, и таким образом поддерживает симметричное мультипроцессирование. Muskie первого поколения поддерживал конфигурации до 4 процессоров.
Будучи самым быстрым RISC-процессором IBM своего времени, Muskie оптимизирован для нужд коммерческих вычислений. Для иллюстрации приведем некоторые характеристики.
Системы и серверы для коммерческих расчетов должны обрабатывать огромные объемы данных. 16-байтовые (128 бит) и 32-байтовые (256 бит) шины позволяют Muskie справляться с этими задачами. Для сравнения: типичные 8-байтовые (64-разрядные) шины, используемые большинством высокопроизводительных RISC-процессоров, предназначены для рабочих станций, где объем обрабатываемых данных гораздо меньше.
Кэш — обычно слабое место большинства RISC-процессоров, даже если система способна перемещать большие объемы данных. Для устранения этого недостатка в Muskie предусмотрен 256-килобайтовый кэш данных, работающий за один цикл.
Поскольку команда перехода может вызвать простой конвейера, современные RISC-процессоры, подобно суперЭВМ, реализуют некоторую разновидность предсказания переходов. Для большинства RISC-процессоров точность предсказания переходов при выполнении технических задач составляет 80-90 процентов, благодаря тому, что в технических задачах процессор многократно повторяет последовательность команд тела цикла. Для программ подобного типа предсказание переходов работает отлично. В программах для коммерческих задач циклов гораздо меньше и точность предсказания переходов может быть ниже 50 процентов (это соответствует точности случайного выбора). Поэтому, вместо того чтобы пытаться угадать место перехода, Muskie выбирает команды из обоих мест перехода и начинает выполнять их. Данный метод, называемый спекулятивным выполнением (speculative execution), требует очень скоростного кэша (чем Muskie обладает), но зато позволяет достичь по сути стопроцентной точности на задачах любого типа.
Еще один важный аспект коммерческих вычислений — высокие требования к целостности данных и коэффициенту готовности. Muskie реализует коды коррекции ошибок для всех связей за переделами кристаллов. Кроме того, большая часть логики управления и передачи данных на каждом кристалле также содержит различные схемы контроля. Типичный же RISC-процессор для рабочей станции вряд ли способен на что-либо подобное в области определения и исправления ошибок.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Процессоры Cobra первого и второго поколения
Процессоры Cobra первого и второго поколения Как и Muskie, процессоры Cobra имеют расширенную 64-разрядную архитектуру PowerPC. Они суперскалярные, что позволяет использовать параллелизм на уровне команд. Функционально оба семейства процессоров исполняют один и тот же набор
Процессоры третьего поколения Apache
Процессоры третьего поколения Apache Модели AS/400 1997 года используют новый дизайн процессора. Этот однокристальный процессор PowerPC, разработанный в Рочестере и названный Apache. Он предназначен для средних и старших моделей AS/400е. Младшие модели серии по-прежнему используют
Процессоры пятого поколения
Процессоры пятого поколения В течение нескольких следующих лет серия AS/400е будет использовать процессоры PowerPC. Как мы уже говорили, третье и четвертое поколение процессоров, разработанных в Рочестере, будет применяться на протяжении всего времени выпуска версии 4 и
5.20 Необходимость следующего поколения протокола IP
5.20 Необходимость следующего поколения протокола IP Внедрение бесклассовых адресов суперсетей и бесклассовой маршрутизации стало последней точкой в совершенствовании и использовании текущей схемы адресации протокола IP.В начале разработки адресов IP никто не мог
7.4.2.4. Создание своего первого LiveCD
7.4.2.4. Создание своего первого LiveCD Теперь у нас все готово, чтобы создать свой первый LiveCD. Для его создания нужно ввести команду (от имени пользователя root):# livecd-creator --repo=cоrе, file:///rpms --расkage=bash --package=kernel --package=grubДанная команда создаст LiveCD, в который будут включены пакеты kernel
Приоритеты прерываний и процессов первого плана
Приоритеты прерываний и процессов первого плана Существует возможность указания системе приоритета для конкретного прерывания. В зависимости от использования прерывания повышение его приоритета может повысить скорость работы компьютера. Можно также указать
§ 90. Пломбир для пассажиров первого класса
§ 90. Пломбир для пассажиров первого класса 7 июня 2002В современном мире без конкурентных преимуществ никак нельзя. Расшибись, а что-нибудь новенькое придумай, чтобы остальные догоняли. В первую очередь это касается производителей техники, электроники и программного
2.1.18. Итоги первого раздела
2.1.18. Итоги первого раздела Мы рассмотрели основные принципы работы со стандартными сокетами. Хотя многое осталось за кадром, того, что здесь было написано, достаточно, чтобы начать создавать разнообразные приложения с использованием сокетов. Для самостоятельного
Создание и запуск вашего первого приложения для iOS
Создание и запуск вашего первого приложения для iOS Прежде чем подробнее познакомиться с возможностями Objective-C, вкратце рассмотрим, как создать простое приложение для iOS в среде Xcode. Xcode — это интегрированная среда разработки (IDE) для работы с Apple, позволяющая создавать,
3.1. Поколения ЭВМ
3.1. Поколения ЭВМ В соответствии с элементной базой и уровнем развития программных средств выделяют четыре реальных поколения ЭВМ, краткая характеристика которых приведена в таблице 1.Таблица 1 ЭВМ первого поколения обладали небольшим быстродействием в несколько
Глава 2 Мозговая пропасть: технологии, разделившие поколения
Глава 2 Мозговая пропасть: технологии, разделившие поколения То, что для одного поколения — верх абсурда, для другого — верх мудрости. Адлай Стивенсон Вы разглядываете коробку, которую муж и дочь-подросток подарили вам на Рождество. На дворе уже День труда[2], но этот