Перекрестные переключатели
 Перекрестные переключатели
Перекрестные переключатели
В рамках начавшейся в 1995 году десятилетней программы ASCI (Accelerated Strategic Computing Initiative) министерство энергетики США DOE (Department of Energy) запросило у производителей компьютеров предложения по созданию самых мощных на сегодня ЭВМ. Задача ACSI — разработка «триллионных» компьютеров, которые могут быть использованы в том числе для моделирования ядерных испытаний. Предполагается, что триллионные (tera-scale) вычисления (таково официальное название для триллиона операций в секунду) будут широко применяться в коммерческих и научных приложениях в следующем столетии. Такие компьютеры создаются в трех национальных лабораториях DOE, связанных с проектом ASCI.
На первом этапе проекта ASCI — ASCI Option Red — рассматривалась большая конфигурация MPP с процессорами, организованными по традиционной модели распределенной памяти. Intel получил контракт на разработку компьютера с 9 072 процессорами Pentium Pro, 283 гигабайтами памяти и двумя терабайтами дискового пространства. Эта система имеет архитектуру MPP без разделения. Испытания новой системы происходили в национальной лаборатории Сандиа (Sandia), штат Нью-Мехи-ко. Ставилась задача — Сандиа (Sandia), «выжать» из единственного в своем роде компьютера, стоимостью в 55 миллионов долларов, триллион операций с плавающей точкой в секунду (один терафлоп). В декабре 1996 компьютер Intel DOE достиг этой цели.
DOE также хотело устранить ограничения двух распространенных многопроцессорных архитектур (SMP и MPP). Как мы уже говорили, системы SMP использующие шины, не масштабируются больше 32 процессоров, но отлично работают для большинства приложений. Схемы MPP сложнее в программировании и подходят только для некоторых классов приложений. Кроме того, их работа сильно замедляется при необходимости доступа к данным, разбросанным по системе. Поэтому DOE предложила новый проект масштабируемого SMP, названного ASCI Option Blue.
Контракты на создание этих систем к концу 1998 года получили две компании, чьи предложения были самыми обещающими: IBM и Cray Research, которая была приобретена SGI (Silicon Graphics Incorporated). Машина IBM названная ASCI Blue Pacific будет установлена в национальной лаборатории имени. Лоуренса (Lawrence) в Ливер-море (Livermore), штат Калифорния, а машина SGI/Cray, получившая имя ASCI Blue Mountain — в национальной лаборатории в Лос-Аламосе (Los Alamos), штат Нью-Ме-хико. Задача обоих компьютеров Option Blue — достичь производительности более 3 терафлоп.
В проекте IBM используются компактные узлы SMP с восемью процессорами; эти узлы соединяются с помощью переключателей передачи сообщений SP2. Проект SGI/
Cray более сложен и включает в себя комбинацию соединений и технологий операционных систем с целью создания образа единой SMP-подобной машины. И хотя физически данные будут распределены по системе, это будет архитектура NUMA.
Компьютер IBM ASCI Blue Pacific будет содержать 512 8-процессорных узлов SMP, 4 096 сверхвысокопроизводительных процессоров PowerPC. Процессор, предназначенный для версии Belatrix Остина, назван 630. Он имеет высокую производительность для вычислений с плавающей точкой и в точности соответствует типу проблем, решать которые призван компьютер DOE.
Для связи между узлами в ASCI Blue Pacific планируется новый высокоскоростной переключатель передачи сообщений типа SP2. Подсистема памяти, позволяющая процессорам внутри узла эффективно использовать память, будет использовать новый 128-разрядный перекрестный переключатель (cross-bar switch)[ 24 ]. Подсистема памяти на основе таких переключателей позволяет нескольким процессорам обращаться к памяти узла параллельно и обеспечивает конфигурацию UMA, где устранена проблема, присущая шине памяти в большинстве конфигураций SMP.
Я упомянул о проекте DOE для того чтобы рассказать о новой подсистеме памяти, используемой в узлах SMP ASCI Blue Pacific. Первая подсистема UMA, использующая 128-разрядный перекрестный переключатель, была разработана в Рочестере. Аналогичная схема используется в настоящее время в компьютерах SMP Apache. Вместо одной шины между памятью и кэшем второго уровня, как в предыдущих системах SMP AS/400, в Apache применены перекрестные переключатели. Благодаря поддержке нескольких параллельных обращений к памяти за один цикл, возможна пересылка больших объемов данных между кэшем и разделяемой памятью, что позволяет поддерживать загрузку процессоров в больших конфигурациях SMP.
Пример подобной конфигурации с двенадцатью процессорами Вы можете увидеть на рисунке 2.6. На одной плате — четыре процессора Apache вместе с четырьмя кэшами L2. В 12-процессорной конфигурации установлено три таких платы. Размещенные на платах кэши L2 размером 4 или 8 мегабайт обладают цикличностью в 8 наносекунд. Таким образом, за один цикл процессора между кэшем второго уровня и кэшем данных или команд первого уровня в микросхеме Apache может быть передано 16 байтов (см. рисунок 2.5).
Основная память в данной конфигурации может достигать 20 гигабайт, каждая плата памяти — содержать до гигабайта, так что на рисунке 2.6 показаны 20 таких плат. Обратите внимание на наличие четырех банков памяти с одинаковым числом плат в каждом, что позволяет обеспечить прослоенную память (memory interleaving) — технический прием, при котором открывается доступ к последовательным блокам данных памяти через разные банки. Например, если каждая плата памяти имеет 8-байтовый интерфейс, то одновременно из четырех банков памяти может быть считано 32 последовательных байта (байты 0-7 из банка 1, байты 8-15 из банка 2 и т. д.).
Четыре перекрестных переключателя подсистемы памяти UMA обеспечивают соединение между кэшами второго уровня и платами основной памяти. Три шины данных 6хх — по одной на каждую плату процессора — соединяют 12 процессоров с каждым из четырех переключателей. Эти 128-разрядные шины данных имеют время цикла 12 наносекунд (в полтора раза больше времени цикла процессора). Дополнительная шина данных 6хх соединяет с каждым из переключателей памяти подсистему ввода-вывода. У каждого переключателя — два независимых 128-разрядных интерфейса к платам памяти.
В подобной конфигурации в каждом цикле памяти к ней может осуществляться несколько параллельных обращений, что фактически устраняет проблемы, связанные с использованием одной шины памяти на традиционных системах SMP.
Имейте в виду, что здесь представлена лишь одна из возможных конфигураций соединения процессорных плат, переключателей и плат памяти. Другие модели линии AS/400 будут использовать иные комбинации этих компонентов. Например, в 4-процессорной конфигурации SMP может использоваться одна процессорная плата, два переключателя и четыре банка памяти.
Также, обратите внимание, что переключатели используются только линиями данных. Линии адресах всех кэшей второго уровня (показанные на рисунке как адресные линии 6хх) общие, что позволяет обычное отслеживание адресов, иначе называемое снупингом кэша (cache snooping) — прием, при котором каждый контроллер кэша L2 постоянно отслеживает все адреса, передаваемые по общей адресной шине. Кроме того, контроллеры проверяют, содержится ли адрес на шине в их кэше. Если это так, то соответствующие данные кэша становятся недействительными. Таким образом достигается когерентность информации во всех кэшах, ведь общие данные могут быть изменены одновременно не более чем одним процессором.
На рисунке 2.6 также показана общая подсистема ввода-вывода. Для подключения устройства расширения ввода-вывода к корпусу Mako, в котором размещается 12-процессорная конфигурация, используется SAN (System Area Network). Два таких интерфейса показаны на рисунке. В главе 10 мы рассмотрим использование SAN для поддержки разных интерфейсов ввода-вывода в AS/400е и соединения этих систем друг с другом.
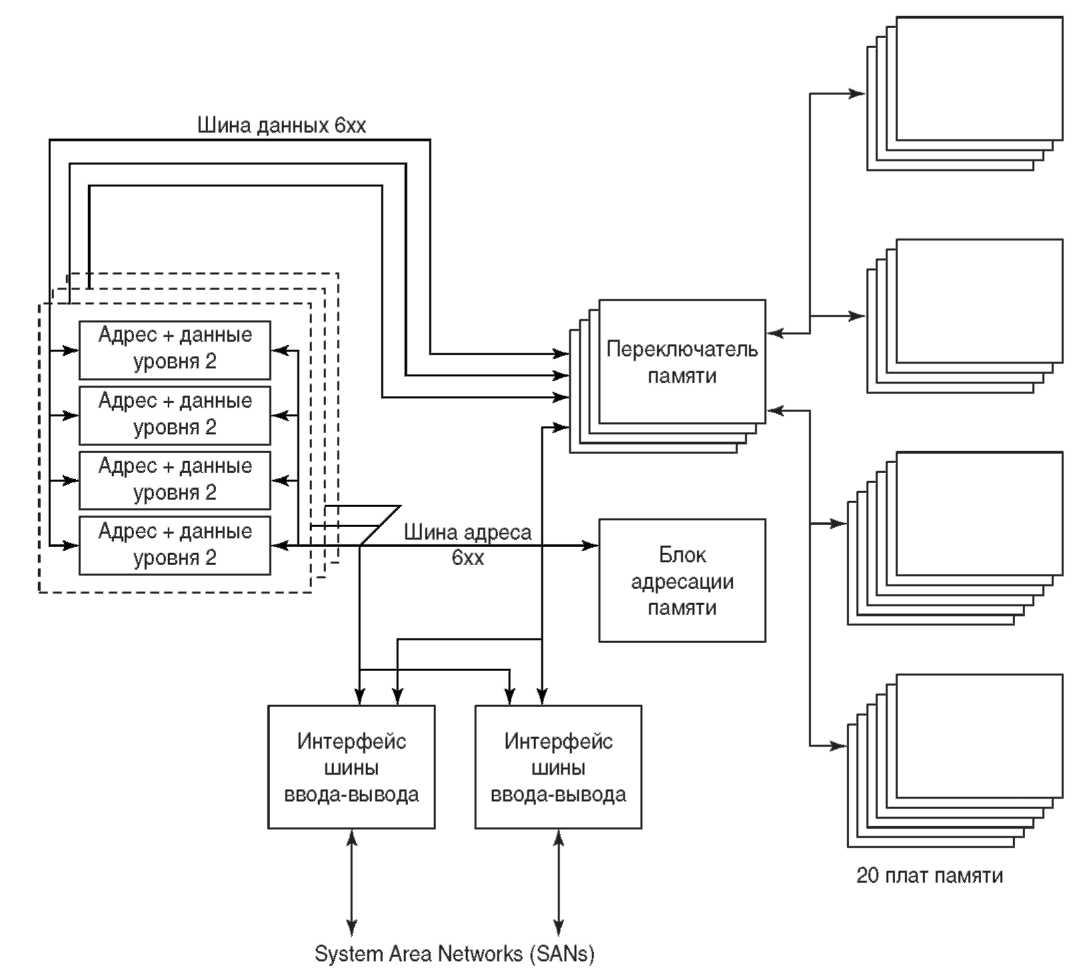
Рисунок 2.6 12-конфигурация SMP
Итак, причина использования перекрестных переключателей — стремление повысить эффективность, или, иначе говоря, процентный рост производительности SMP при добавлении нового процессора в конфигурацию. Во многих системах с разделяемой памятью эта эффективность равна примерно 70 процентам при использовании от четырех до восьми процессоров.[ 25 ] Благодаря новой подсистеме памяти, процессоры Apache должны поднять эффективность до 85—90 процентов.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Переключатели
Переключатели Если вы задаете посетителю вопрос и уверены, что знаете все возможные варианты ответа на него, а также хотите, чтобы посетитель выбрал только один из предложенных вами вариантов, используйте переключатель. Только убедитесь, что действительно предоставили
23.4.3. Переключатели
23.4.3. Переключатели Переключатели бывают двух типов: зависимые (radio buttons) и независимые (checkbuttons). Переключатели являются кнопками, поэтому для них характерны те же события, что и для кнопок.Начнем с независимых переключателей, так как они проще в реализации. Создать такой
Другие переключатели gstat
Другие переключатели gstat Статистика утилиты gstat может предоставить полезную информацию о других действиях с базой данных.Переключатель -headerЭта строкаgstat -header база-данныхотображает суммарную информацию заголовочной страницы базы данных. На рис. 18.5 показан пример.Первая
Перекрестные соединения
Перекрестные соединения Firebird не поддерживает языковых элементов для перекрестного соединения (CROSS JOIN), которое создает набор данных, являющийся декартовым произведением двух таблиц. То есть для каждой строки левого потока выходной поток будет содержать каждую строку из
Переключатели командной строки
Переключатели командной строки Требуются только начальные символы переключателей. Вы также можете набрать любую часть текста в квадратных скобках, показанного в табл. 37.1, включая полное название режима. Например, задание -n, -no, -noauto имеет одинаковый эффект.Таблица 37.1.
Переключатели копирования
Переключатели копирования В табл. 38.1 описаны переключатели, которые могут быть использованы в gbak при выполнении копирования.Таблица 38.1. Переключатели gbak для копирования Переключатель Эффект -b[ackup database] Утилита gbak выполняет копирование указанной базы данных в файл или
Переключатели восстановления
Переключатели восстановления В табл. 38.2 перечисляются и описываются переключатели, которые могут быть использованы в gbak при выполнении восстановления базы данных.Таблица 38.2. Переключатели gbak для выполнения восстановления базы данных Переключатель Эффект -c[reate
Переключатели типов
Переключатели типов Как и раньше, отобразить мастер для выполнения поиска можно с помощью сочетания клавиш Windows+F (рис. 3.2). Обратите внимание на панель Показать только данного мастера. С ее помощью можно выполнить поиск среди файлов определенного расширения. Данная панель
Переключатели
Переключатели Приобретая офсетную тарелку, пользователь обычно желает получать сигнал с нескольких спутников с помощью одной антенны, то есть установить несколько конвертеров на одну антенну. Рассматривая тюнеры, можно заметить, что они имеют всего один вход для