Эволюция PowerPC
Эволюция PowerPC
Концепция RISC была разработана Джоном Коком (John Cocke) из IBM Research. Кок установил, что прогресс в области компиляторов достиг той точки, когда можно упростить набор команд процессора, и возложить на компилятор значительную часть работы, ранее выполнявшейся аппаратурой. Впервые идеи Кока были воплощены в миникомпьютере IBM 801. Процессоры PowerPC s прямые наследники 801.
Основным мотивом создания архитектур CISC было желание сократить семантический разрыв между двоичным машинным языком процессора и ЯВУ, используемыми программистами. В двоичный машинный язык вводились команды, соответствующие инструкциям языка высокого уровня. Идея заключалась в том, чтобы процессор исполнял меньшее количество сложных команд, что позволило бы сэкономить память. К несчастью, машинные команды стали настолько сложны, что при создании практически любого процессора приходилось применять микропрограммирование. Накладные расходы микропрограммируемого эмулятора замедляли выполнение часто встречающихся простых команд. Кок доказывал, что при использовании только простых команд, необходимость в микропрограммировании отпадет, а все команды будут выполняться аппаратурой непосредственно. Более того, если бы стоимость памяти не была столь существенна, то компиляторы могли бы напрямую подставлять код для выполнения более сложных функций. Потребности в памяти увеличились бы, но возросла бы и производительность.
Дизайн процессора 801 был заимствован у суперкомпьютеров s самых быстродействующих ЭВМ. Хотя сам термин «суперкомпьютер» до середины 70-х годов не использовался, но конструкторы, стремившиеся раздвинуть пределы возможностей аппаратных технологий, были всегда. Невозможно говорить о суперкомпьютерах, не вспомнив о Сеймуре Крее (Seymour Cray). Если хотите, Крей и суперкомпьютер — это синонимы. Современные архитектуры RISC-процессоров многим обязаны этому первопроходцу[ 10 ].
Значительно повысить производительность процессоров позволил метод конвейерной обработки (pipelining). На протяжении уже многих лет эта технология используется при создании всех компьютеров, от ПК до больших ЭВМ. Суть ее — в параллельном исполнении фрагментов последовательных команд на разных этапах аппаратного конвейера. Первый компьютер общего назначения, использовавший конвейерную обработку, появился еще в 1961 году. Это был IBM 7030, известный также под названием Stretch.

Рисунок 2.1а Конвейерный скалярный процессор — пятиэтапный конвейер команд.
Пример пятиэтапного конвейера команд показан на рисунке 2.1а. Время, необходимое для выполнения каждого этапа выполнения команды, называется временем цикла процессора (processor cycle time).
На рисунке 2.1б показана временная диаграмма пятиэтапного конвейера. В течение первого цикла процессора команда № 1 выбирается из буфера команд аппаратурой первого этапа конвейера. В течение второго цикла команда № 1 декодируется, и содержимое необходимых регистров считывается аппаратурой второго этапа. В то же самое время, аппаратура первого этапа считывает из буфера команд команду № 2. Теперь аппаратура разных стадий конвейера параллельно обрабатывает разные части двух разных команд. Благодаря такому параллелизму и достигается повышенная производительность процессоров с конвейерной обработкой. Обратите внимание: предполагается, что некоторая другая часть аппаратуры процессора обеспечивает заполнение буфера команд.
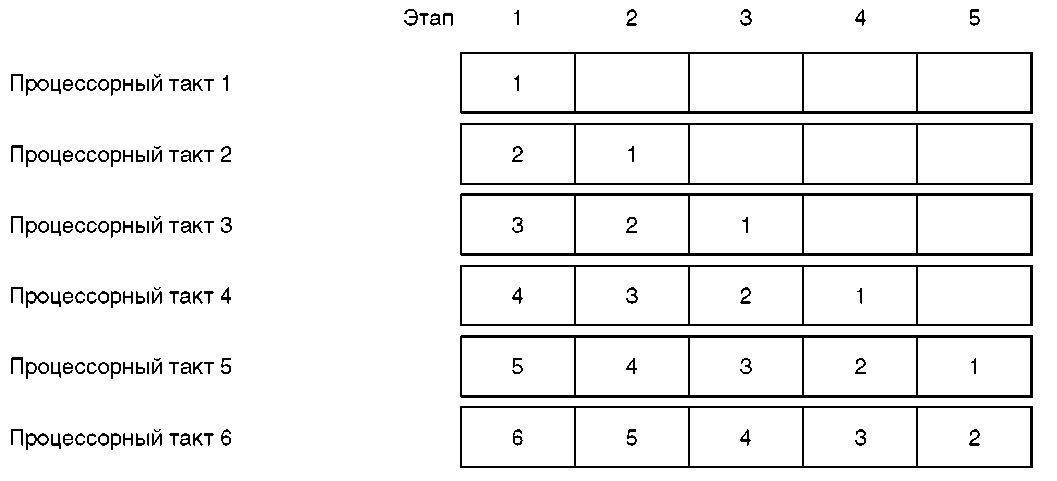
Рисунок 2.1b Пример временной диаграммы
В течение третьего процессорного цикла команда № 1 поступает на стадию выполнения и вычисления эффективного адреса (стадия 3), команда № 2 поступает на стадию 2, а команда № 3 s на стадию 1. Процесс продолжается вплоть до завершения пятого цикла процессора, когда выполнение команды: № 1 заканчивается и она покидает конвейер. Таким образом, выполнение каждой отдельной команды занимает полные пять циклов, но после того, как конвейер заполнен, на каждом цикле процессора завершается выполнение одной команды. Когда говорят, что для выполнения одной команды необходим один цикл процессора, подразумевается, что конвейер заполнен, что, понятно, близко к идеалу[ 11 ].
В начале 60-х годов Сеймур Крей в Control Data Corporation разрабатывал первый в мире суперкомпьютер — CDC 6600. Он планировал использовать конвейерную обработку и добивался, чтобы время выполнения всех команд было одинаковым. Ведь, как видно из приведенного примера, общее время выполнения команд определяется командой, имеющей самое большое время выполнения. Команды, выбирающие операнды из памяти или записывающие их в память, обычно выполняются дольше остальных. Если эти, работающие с памятью, команды выполняют также и логические или арифметические действия над данными, то время выполнения может стать очень большим.
Чтобы максимально сократить общее время выполнения команд, Крей решил, что в его процессоре единственными операциями с памятью будут загрузка в регистр содержимого памяти по некоторому адресу и сохранение содержимого регистра по некоторому адресу в памяти. Любые действия над данными должны производиться только в регистрах.
Тогда это было очень непривычно: ведь большинство других компьютеров позволяли выполнять операции над данными в памяти без использования регистров. Например, команды S/360 позволяют сложить два находящихся в памяти операнда и записать сумму обратно в память. Эта операция занимает очень много времени, но выполняется одной машинной командой. Команды данного типа называются командами память-память.
Для выполнения той же самой операции на машине Крея потребовалось бы пять команд. Сначала две команды загрузки поместили бы данные в два регистра. Затем команда сложения просуммировала бы содержимое этих регистров и поместила бы результат обратно в регистр. И, наконец, команда сохранения переписала бы сумму из регистра в память[ 12 ]. Но если эффективно поместить все эти пять команд на конвейер и выполнять их параллельно, то общее необходимое для этого время будет меньше времени, необходимого для выполнения эквивалентной операции на машине с командами типа память-память. И все же большее число команд, требуемых для выполнения операции, было недостатком машины Крея.
В 1964 году появилась CDC 6600 s первая машина общего назначения с архитектурой загрузка/сохранение (load/store). Крей осознал связь между конвейерной обработкой и архитектурой набора команд, и это привело его к выводу о необходимости упрощения этой архитектуры для повышения эффективности конвейера. Современные RISC-процессоры используют подход Сеймура Крея — в них команды, работающие с памятью, выполняют только загрузку и сохранение. Вот почему RISC-машины быстрее CISC-машин с полным набором команд для работы с памятью. По той же причине и программы, скомпилированные для RISC, больше по размеру.
Вклад Сеймура Крея в разработку высокопроизводительных конвейеров не ограничивается только архитектурой набора команд. В CDC 6600 он применил аппаратуру, которая обеспечивала максимум производительности путем максимально возможной загрузки конвейера, то есть ситуацию, при которой на каждой его стадии выполняется часть некоторой команды. В реальности, между командами в программах существуют зависимости. Если команда на конвейере использует данные, которые сохраняются командой, идущей по конвейеру непосредственно впереди нее, то в определенный момент эти данные могут быть еще недоступны, что не только вызывает простой конвейера, но и останавливает выполнение всех последующих команд. Тем самым уменьшается производительность процессора.
В CDC 6600 было впервые реализовано оборудование, позволяющее процессору просматривать команды, расположенные далее в потоке команд, и определять, могут ли они быть запущены перед той, что ожидает сохранения результата. Идея аппаратного переупорядочивания команд на конвейере, известная как динамическое планирование (dynamic scheduling), служила поддержанию максимально возможной его загрузки и значительно повысила производительность CDC 6600.
В суперкомпьютерах 60-х была реализована и идея предсказания переходов. Команда перехода может разрушить конвейер. Вызванный ею простой затянется до тех пор, пока система не будет в состоянии решить, какая команда должна выполняться следующей. Идея предсказания переходов состоит в том, чтобы на основе опыта угадать, откуда следует выбирать команду, следующую после команды перехода. Использованное в IBM 360/91 сложное аппаратное обеспечение предсказания переходов позволило достичь отличных результатов.
360/91 обладала еще одной интересной аппаратной особенностью. Опираясь на ее опыт, Боб Томасуло (Bob Tomasulo), инженер IBM, усовершенствовал алгоритм Крея, созданный несколькими годами ранее, и создал новый алгоритм динамического планирования. Реализованный аппаратно, алгоритм Томасуло устранил многие случаи простоя конвейера путем выполнения команд не по порядку их следования. Команда, которая должна ожидать получения некоторого результата, более не останавливает команды, следующие за ней. Алгоритм Томасуло требовал невероятно сложной по тем временам аппаратуры, но на деле позволял достичь желаемого роста производительности.
Специализированное оборудование для повышения производительности конвейера повышало не только сложность, но и цену аппаратуры. Для суперкомпьютеров цена не играет особой роли, чего не скажешь об обычных системах.
В конце 60-х годов Джон Кок работал над проектом быстрого компьютера для научных расчетов в IBM Research Laboratory в Сан-Хосе (San Jose), штат Калифорния, и вплотную столкнулся со сложностью оборудования, необходимого для поддержания загрузки конвейера. Кок полагал, что если переложить большую часть ответственности за это на компиляторы, то оборудование значительно упростится и подешевеет. И тогда высокопроизводительная обработка перестанет быть прерогативой суперкомпьютеров. Так родилась идея RISC.
К сожалению, этот исследовательский проект был прерван прежде, чем Кок смог реализовать свои идеи. Еще один шанс сделать это представился ему в 1976 году, в исследовательской лаборатории IBM Yorktown в Нью-Йорке. Коку было поручено спроектировать и построить высокопроизводительный контроллер телекоммуникаций. Именно этот контроллер, получивший кодовое наименование 801 (по номеру здания, в котором работал Кок) обычно считается первым RISC-компьютером.
801 доказал, что планирование загрузки конвейерного процессора может быть возложено на компилятор. Сочетание компилятора, генерировавшего поток команд, оптимизированный для конкретного конвейерного процессора, и упрощенного процессора типа загрузка/сохранение, аналогичного машине Сеймура Крея, до сих пор остается непревзойденным.
Современные RISC-процессоры используют идею Джона Кока s оптимизирующий компилятор, соответствующий аппаратуре процессора. Их производительность обеспечивается технологическими достижениями как аппаратуры, так и компиляторов. Поскольку за последние несколько лет компиляторы очень быстро прогрессируют, то есть даже предложения переименовать RISC в «Relegate Interesting Stuff to Compilers»[ 13 ].
Первым продуктом IBM, в котором использовались идеи 801, был PC RT. Подразделению по созданию продукции для офисов в Остине понадобился новый процессор. В качестве отправной точки для разработки был взят 801. Новый микропроцессор, названный ROMP (Research/Office Products Microprocessor), включал в себя подмножество 801, что обеспечивало низкую себестоимость. Главным архитектором и менеджером разработки PC RT выступал Гленн Хенри. Ранее он был программным менеджером нашего проекта в Рочестере, а после выхода на рынок System/38 перебрался в Остин, где возглавил первый проект IBM по созданию RISC-компьютера.
801 использовался также и другими организациями в качестве базы для создания RISC-процессоров. В начале 80-х исследования по этой теме велись группой Дэвида Паттерсона (David Patterson) в Калифорнийском университете в Беркли (Berkeley) и группой Джона Хеннеси (John Hennessy) в Станфордском университете. Именно Паттерсон и придумал термин «RISC». Выпускники обоих упомянутых университетов работали в IBM Research и знали 801. Проект Паттерсона лег в основу микропроцессора SPARC, использовавшегося компанией SUN, а проект Хеннеси s микропроцессора MIPS. Тем временем, в расположенной по соседству компании HP разработкой архитектуры PA-RISC занимался Джоел Бирнбаум (Joel Birnbaum), ранее возглавлявший группу 801 в IBM Research. Таким образом, PA-RISC также s прямой потомок проекта 801.
Ранние процессоры RISC, как и 801, использовали один конвейер. Кок и другие сотрудники IBM полагали, что повысить производительность можно путем распределения на каждом цикле нескольких команд из обычного линейного потока по нескольким конвейерам. Такой компьютер был создан и назван суперскалярным. Первый суперскалярный RISC-процессор появился в 1990 году в RS/6000. В основе его архитектуры также лежал 801.
Чтобы отметить суперскалярное расширение RISC-процессора, IBM назвала эту архитектуру POWER (Performance Optimization With Enhanced RISC). Архитектура POWER стала стартовой площадкой объединенного проекта Apple, IBM и Motorola.
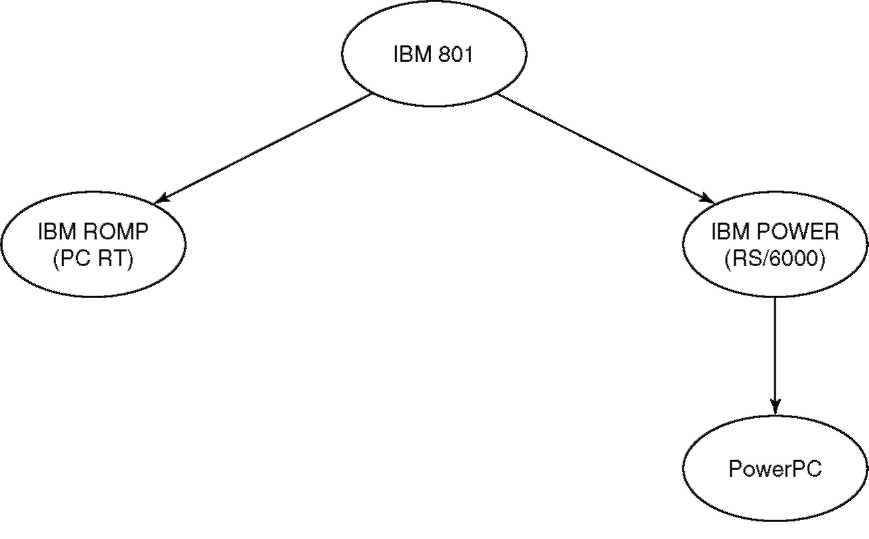
Рисунок 2.2. Эволюция PowerPC
Чтобы удовлетворить будущие потребности всех трех корпораций, архитектуру POWER требовалось несколько изменить. Большинство процессоров POWER были многокристальными. Некоторое упрощение архитектуры сделало возможным создание дешевых однокристальных вариантов (иначе говоря, микропроцессоров). Кроме того, архитектура POWER не поддерживала многопроцессорные системы, так что и здесь понадобились соответствующие добавления. Были также увеличены возможности поддержки предполагаемых будущих приложений. Наконец, 32-разрядная архитектура POWER была расширена путем включения 64-разрядных адресов и операций. В результате всех этих изменений на свет появилась новая архитектура s PowerPC. Ее эволюция, начиная с 801, показана на рисунке 2.2.
Усилиями инженеров Apple, IBM и Motorola был создан новый проектный центр для разработки микропроцессоров PowerPC. Персонал Somerset[ 14 ] Design Center, расположенного в Остине, состоит, в основном, из инженеров IBM и Motorola. В конце 1995 года Somerset стал частью подразделения IBM Microelectronics. Сотрудничающие фирмы имеют право производить и продавать процессоры, разработанные в Сомерсете. Например, Apple покупает микросхемы PowerPC как у IBM, так и у Motorola. Процессоры PowerPC Motorola производятся на заводе этой фирмы в Остине. IBM производит свои микросхемы PowerPC в Барлингтоне (Burlington), штат Вермонт.
Важно отметить, что RISC-процессоры в последние несколько лет неуклонно прогрессируют. Практически каждый их производитель, включая консорциум PowerPC, ныне поставляет на рынок 64-разрядный RISC-процессор, на кристалле которого установлена аппаратура динамического планирования, использующая описанный выше алгоритм Томасуло, а также предсказания переходов. Удивительно, но мы, кажется, совершили полный круг? В современные процессоры снова включена вся аппаратура, для устранения которой и была первоначально предложена RISC-архитектура. Сеймур Крей мог бы гордиться: ведь аппаратные решения, предложенные им впервые в 1964 году, взяли верх над более простыми архитектурами ранних RISC-процессоров. Это определенно не те RISC-процессоры, что раньше!
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
5.4. Эволюция
5.4. Эволюция Теория фреймов предполагает наличие большого числа разнообразных механизмов для манипуляции визуальными и символьными образами. Я не думаю, что большинство этих механизмов может возникнуть в процессе самоорганизации системы; скорее, они зависят от того,
Союз AS/400-PowerPC
Союз AS/400-PowerPC Я возглавлял в Рочестере группу, которая должна была определить требования к новому процессору для AS/400. Тогда мы вместе с архитекторами и разработчиками PowerPC пытались создать 64-разрядный процессор, основанный на архитектуре PowerPC. По нашему мнению, это должно
Технология PowerPC
Технология PowerPC «По сути своей, IBM s компания технологий», — сказал Лу Герстнер (Lou Gerstner) вскоре после того, как возглавил корпорацию в 1993 году. И действительно, чуть ли не все основные технологии компьютерной индустрии s от RISC до реляционных баз данных s вышли из IBM. В прошлом
Альянс PowerPC
Альянс PowerPC В начале 1991 года Apple Computer подыскивала новый процессор для своих компьютеров. Ее специалисты полагали, что будущее процессоров ПК — в RISC-архитектуре. В то время процессоры ПК, производимые Motorola, Intel и другими фирмами, имели архитектуру CISC. Apple тогда использовала
Технология PowerPC для AS/400
Технология PowerPC для AS/400 Президентом IBM в 1991 году был Джек Кюлер (Jack Kuehler). Он привел IBM к соглашению с Apple и Motorola о создании микропроцессоров PowerPC. Джек Кюлер считал, что к концу десятилетия все компьютеры, от самых маленьких, умещающихся на ладони, до суперЭВМ будут
Архитектура PowerPC
Архитектура PowerPC Архитектура PowerPC обладает всеми обычными характеристиками архитектуры RISC: команды фиксированной длины, операции регистр-регистр, простые режимы адресации и большой набор регистров. Но есть и характеристики, отличающие ее отдругих.Как уже упоминалось,
Расширения архитектуры PowerPC
Расширения архитектуры PowerPC Так как первое поколение процессоров PowerPC создавалось специально под AS/400 и не было PowerPC в полном смысле, мы решили дать этим процессорам новое название s PowerPC Optimized for the AS/400 Advanced Series, но так как это труднопроизносимо, решено было остановиться на
8.3. Эволюция
8.3. Эволюция Планирование релизов Рассмотрев несколько сценариев работы системы и убедившись в правильности стратегических решений, можно начинать планирование процесса разработки. Разобьем работу на ряд этапов, результат каждого из которых будет являться основой для
9.3. Эволюция
9.3. Эволюция Проектирование интерфейса классов После того, как выработаны основные принципы построения архитектуры системы, остающаяся работа проста, но зачастую довольно скучна и утомительна. Следующий этап будет состоять в реализации трех или четырех семейств
10.3. Эволюция
10.3. Эволюция Управление релизами Теперь, полностью определив архитектурный каркас системы складского учета, мы можем приступить к последовательному развитию. Выберем сначала наиболее важные транзакции в нашей системе (ее вертикальный срез) и выпустим продукт, который
11.3. Эволюция
11.3. Эволюция Интеграция Теперь, когда ключевые абстракции предметной области выявлены, можно приступить к их соединению в действующее приложение. Мы будем реализовывать и проверять вертикальные срезы системы, а затем последовательно отрабатывать механизмы. Интеграция
12.3. Эволюция
12.3. Эволюция Модульная архитектура Мы уже говорили о том, что модульность для больших систем необходима, но не достаточна; для задач такого масштаба, как система управления движением, нужно сосредоточиться на декомпозиции по подсистемам. На ранних стадиях эволюции мы
17.1. Эволюция С
17.1. Эволюция С Главным фактом практики Unix-программирования всегда была стабильность языка С и небольшого количества служебных интерфейсов, которые всегда ему сопутствовали (особенно стандартная 1/О-библиотека и подобные ей). Тот факт, что i язык, созданный в 1973 году, в
17.1. Эволюция С
17.1. Эволюция С Главным фактом практики Unix-программирования всегда была стабильность языка С и небольшого количества служебных интерфейсов, которые всегда ему сопутствовали (особенно стандартная I/O-библиотека и подобные ей). Тот факт, что язык, созданный в 1973 году, в
ГЛАВА 6: ЭВОЛЮЦИЯ
ГЛАВА 6: ЭВОЛЮЦИЯ Вы накормили и приручили слона. Но со временем он будет расти и развиваться, станет умнее.Ваша система должна меняться, потому что будет меняться ваша жизнь, её ценности и способы реализации ваших целей. Через год вы, может быть, плюнете на GTD и пошлёте