14.4.1. Введение в двоичные деревья
14.4.1. Введение в двоичные деревья
Массивы являются почти простейшим видом структурированных данных. Их просто понимать и использовать. Хотя у них есть недостаток, заключающийся в том, что их размер фиксируется во время компиляции. Таким образом, если у вас больше данных, чем помещается в массив, вам не повезло. Если у вас значительно меньше данных, чем размер массива, память расходуется зря. (Хотя на современных системах много памяти, подумайте об ограничениях программистов, пишущих программы для внедренных систем, таких, как микроволновые печи и мобильные телефоны. С другого конца спектра, подумайте о проблемах программистов, имеющих дело с огромными объемами ввода, таких, как прогнозирование погоды.
В области компьютерных наук были придуманы многочисленные динамические структуры данных, структуры, которые увеличивают и уменьшают свой размер по требованию и которые являются более гибкими, чем простые массивы, даже массивы, создаваемые и изменяемые динамически с помощью malloc() и realloc(). Массивы при добавлении или удалении новых элементов требуется также повторно сортировать.
Одной из таких структур является дерево двоичного поиска, которое мы для краткости будем называть просто «двоичным деревом» («binary tree»). Двоичное дерево хранит элементы в сортированном порядке, вводя их в дерево в нужном месте при их появлении. Поиск по двоичному дереву также осуществляется быстро, время поиска примерно такое же, как при двоичном поиске в массиве. В отличие от массивов, двоичные деревья не нужно каждый раз повторно сортировать с самого начала при добавлении к ним элементов.
У двоичных деревьев есть один недостаток. В случае, когда вводимые данные уже отсортированы, время поиска в двоичном дереве сводится ко времени линейного поиска. Техническая сторона этого вопроса должна иметь дело с тем, как двоичные деревья управляются внутренне, что вскоре будет описано.
Теперь не избежать некоторой формальной терминологии, относящейся к структурам данных. На рис. 14.1 показано двоичное дерево. В информатике деревья изображаются, начиная сверху и расширяясь вниз. Чем ниже спускаетесь вы по дереву, тем больше его глубина. Каждый объект внутри дерева обозначается как вершина (node). На вершине дерева находится корень дерева с глубиной 0. Внизу находятся концевые вершины различной глубины. Концевые вершины отличают по тому, что у них нет ответвляющихся поддеревьев (subtrees), тогда как у внутренних вершин есть по крайней мере одно поддерево. Вершины с поддеревьями иногда называют родительскими (parent), они содержат порожденные вершины (children).
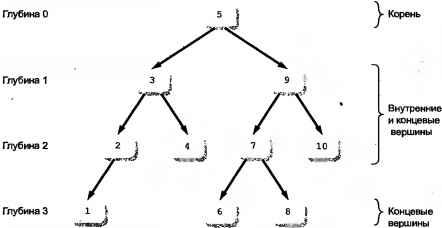
Рис. 14.1. Двоичное дерево
Чистые двоичные деревья отличаются тем, что каждая вершина содержит не более двух порожденных вершин. (Деревья с более чем двумя вершинами полезны, но не существенны для нашего обсуждения.) Порожденные вершины называются в этом случае левой и правой соответственно.
Деревья двоичного поиска отличаются еще и тем, что значения, хранящиеся в левой порожденной вершине, всегда меньше значения в родительской вершине, а значения, хранящиеся в правой порожденной вершине, всегда больше значения в родительской вершине. Это предполагает, что внутри дерева нет повторяющихся значений. Этот факт также объясняет, почему деревья не эффективны при работе с предварительно отсортированными данными: в зависимости от порядка сортировки, каждый новый элемент данных сохраняется либо только слева, либо только справа от находящегося впереди него элемента, образуя простой линейный список.
К двоичным деревьям применяют следующие операции:
Ввод
Добавление к дереву нового элемента.
Поиск
Нахождение элемента в дереве.
Удаление
Удаление элемента из дерева.
Прохождение (traversal)
Осуществление какой-либо операции с каждым хранящимся в дереве элементом. Прохождение дерева называют также обходом дерева (tree walk). Есть разнообразные способы «посещения» хранящихся в дереве элементов. Обсуждаемые здесь функции реализуют лишь один из таких способов. Мы дополнительно расскажем об этом позже.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Деревья и узлы
Деревья и узлы При работе с XSLT следует перестать мыслить в терминах документов и начать — в терминах деревьев. Дерево представляет данные в документе в виде множества узлов — элементы, атрибуты, комментарии и т.д. трактуются как узлы — в иерархии, и в XSLT структура дерева
Деревья с двоичным основанием
Деревья с двоичным основанием Описанный выше метод двоичного поиска можно представить в виде древовидной структуры. Дерево будет содержать два типа узлов: тестовые и окончательные. Каждый тестовый узел дерева проверяет один разряд числа. По тому, равен разряд 1 или 0, в
Абстрактные базы как двоичные интерфейсы
Абстрактные базы как двоичные интерфейсы Оказывается, применение техники разделения интерфейса и реализации может решить и проблемы совместимости транслятора/компоновщика C++. При этом, однако, определение класса интерфейса должно принять несколько иную форму. Как
3.1. Структуры и деревья
3.1. Структуры и деревья Чтобы легче было понять сложную структуру, ее обычно представляют в виде дерева, в котором каждому функтору соответствует вершина, а компонентам соответствуют ветви дерева. Каждая ветвь может указывать на другую структуру, так что мы можем иметь
3.2.1. Двоичные дроби
3.2.1. Двоичные дроби Для начала — немного математики. В школе мы проходим два вида дробей простые и десятичные. Десятичные дроби, по сути дела, представляют собой разложение числа по степеням десяти. Так, запись 13,6704 означает число, равное 1?101 + 3?100 + 6?10-1 + 7?10-2 + 0?10-3 + 4?10-4. Но
3.1.6. Двоичные форматы файлов
3.1.6. Двоичные форматы файлов Если в операционной системе применяются двоичные форматы для важных данных (таких как учетные записи пользователей), вполне вероятно, что традиции использования читабельных текстовых форматов для приложений не сформируются. Более подробно
3.1.6. Двоичные форматы файлов
3.1.6. Двоичные форматы файлов Если в операционной системе применяются двоичные форматы для важных данных (таких как учетные записи пользователей), вполне вероятно, что традиции использования читабельных текстовых форматов для приложений не сформируются. Более подробно о
9.3. Деревья
9.3. Деревья Я не увижу никогда, наверное, Поэму столь прекрасную как дерево. Джойс Килмер, «Деревья»[11] В информатике идея дерева считается интуитивно очевидной (правда, изображаются они обычно с корнем наверху, а листьями снизу). И немудрено, ведь в повседневной жизни мы
ПРИЛОЖЕНИЕ Ж. ДВОИЧНЫЕ И ДРУГИЕ ЧИСЛА
ПРИЛОЖЕНИЕ Ж. ДВОИЧНЫЕ И ДРУГИЕ ЧИСЛА Двоичные числа В основе способа, который мы обычно используем для записи чисел, лежит число 10. Может быть, вы когда-то слышали, что число 3652 имеет 3 в позиции тысяч, 6 в позиции сотен, 5 в позиции десятков и 2 в позиции единиц. Поэтому мы
Двоичные числа
Двоичные числа В основе способа, который мы обычно используем для записи чисел, лежит число 10. Может быть, вы когда-то слышали, что число 3652 имеет 3 в позиции тысяч, 6 в позиции сотен, 5 в позиции десятков и 2 в позиции единиц. Поэтому мы можем представить число 3652 в виде3 ? 1000 + 6 ?
Двоичные числа с плавающей точкой
Двоичные числа с плавающей точкой Числа с плавающей точкой хранятся в памяти в виде двух частей: двоичной дроби и двоичного порядка. Посмотрим, как это делается. Двоичные дроби Обычную дробь .324 можно представить в виде3/10 + 2/100 + 4/1000,где знаменатели - увеличивающиеся
Скошенные деревья
Скошенные деревья Как бы то ни было, ознакомившись с этими операциями простых и спаренных двухсторонних и односторонних поворотов, мы может их использовать в структуре данных, называемой скошенным деревом. Скошенное дерево (splay tree) - это дерево бинарного поиска,
Деревья
Деревья Прежде, чем мы приступим к рассмотрению типов узлов и отношений между ними, необходимо определиться с самой структурой дерева. Древовидная структура задает для своих элементов отношение ветвления, очень похожее на строение обычного дерева — есть корневой узел
9.3. Двоичные справочники: добавление и удаление элемента
9.3. Двоичные справочники: добавление и удаление элемента Если мы имеем дело с динамически изменяемым множеством элементов данных, то нам может понадобиться внести в него новый элемент или удалить из него один из старых. В связи с этим набор основных операций, выполняемых
У15.1 Окна как деревья
У15.1 Окна как деревья Класс WINDOW порожден от TREE [WINDOW]. Поясните суть родового параметра. Покажите, какое новое утверждение появится в связи с этим в инварианте
У15.7 Деревья
У15.7 Деревья Согласно одной из интерпретаций, дерево - это рекурсивная структура, представляющая собой список деревьев. Замените приведенное в этой лекции описание класса TREE как наследника LINKED_LIST и LINKABLE новым вариантомclass TREE [G] inheritLIST [TREE [G]]feature ...endРасширьте это описание до