17.3.2. Типы итераторов классов соответствия и regex
Программа проверки правила "i перед е, кроме как после с" из раздела 17.3.1 выводила только первое соответствие в исходной последовательности. Используя итератор sregex_iterator, можно получить все соответствия. Итераторы класса regex являются адаптерами итератора (см. раздел 9.6), привязанные к исходной последовательности и объекту класса regex. Как было описано в табл. 17.8, для каждого типа исходной последовательности используется специфический тип итератора. Операции с итераторами описаны в табл. 17.9.
Когда итератор sregex_iterator связывается со строкой и объектом класса regex, итератор автоматически позиционируется на первое соответствие в заданной строке. Таким образом, конструктор sregex_iterator() вызывает функцию regex_search() для данной строки и объекта класса regex. При обращении к значению итератора возвращается объект класса smatch, соответствующий результатам самого последнего поиска. При приращении итератора для поиска следующего соответствия в исходной строке вызывается функция regex_search().
Таблица 17.9. Операции с итератором sregex_iterator
Эти операции применимы также к итераторам cregex_iterator, wsregex_iterator и wcregex_iterator sregex_iterator it(b, e, r); it — это итератор sregex_iterator, перебирающий строку, обозначенную итераторами b и е. Вызов regex_search(b, е, r) устанавливает итератор it на первое соответствие во вводе sregex_iterator end; Итератор sregex_iterator, указывающий на позицию после конца *it it-> Возвращает ссылку на объект класса smatch или указатель на объект класса smatch от самого последнего вызова функции regex_search() ++it it++ Вызывает функцию regex_search() для исходной последовательности, начиная сразу после текущего соответствия. Префиксная версия возвращает ссылку на приращенный итератор, а постфиксная возвращает прежнее значение it1 == it2 it1 != it2 Два итератора sregex_iterator равны, если оба они итераторы после конца. Два не конечных итератора равны, если они созданы из той же исходной последовательности и объекта класса regexИспользование итератора sregex_iterator
В качестве примера дополним программу поиска нарушения правила "i перед е, кроме как после с" в текстовом файле. Подразумевается, что file класса string содержит все содержимое исходного файла, на котором осуществляется поиск. Новая версия программы будет использовать ту же схему, что и ранее, но для поиска применим итератор sregex_iterator:
// найти символы ei, следующие за любым символом, кроме с
string pattern("[^с]ei");
// искомая схема должна присутствовать в целом слове
pattern = "[[:alpha:]]*" + pattern + "[[ :alpha:]]*";
regex r(pattern, regex::icase); // игнорируем случай выполнения
// соответствия
// будет последовательно вызывать regex_search() для поиска всех
// соответствий в файле
for (sregex_iterator it(file.begin(), file.end(), r), end_it;
it != end_it; ++it)
cout << it->str() << endl; // соответствующее слово
Цикл for перебирает все соответствия r в строке file. Инициализатор в цикле for определяет итераторы it и end_it. При определении итератора it конструктор sregex_iterator() вызывает функцию regex_search() для позиционирования итератора it на первое соответствие в строке file.
Пустой итератор sregex_iterator, end_it действует как итератор после конца. Приращение в цикле for "перемещает" итератор, вызвав функцию regex_search(). При обращении к значению итератора возвращается объект класса smatch, представляющий текущее соответствие. Для вывода соответствующего слова вызывается функция-член str().
Данный цикл for как бы перепрыгивает с одного соответствия на другое, как показано на рис. 17.1.
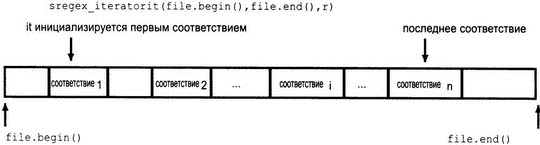
Рис. 17.1. Использование итератора sregex_iterator
Использование данных соответствия
Если запустить этот цикл для строки test_str из первоначальной программы, вывод был бы таким:
freind
theif
Однако вывод только самого слова, соответствующего заданному выражению, не очень полезен. При запуске программы для большой исходной последовательности, например для текста этой главы, имело бы смысл увидеть контекст, в котором встретилось слово. Например:
hey read or write according to the type
>>> being <<<
handled. The input operators ignore whi
Кроме возможности вывода части исходной строки, в которой встретилось соответствие, классы соответствия предоставляют более подробную информацию о соответствии. Возможные операции с этими типами перечислены в табл. 17.10 и 17.11.
Более подробная информация о smatch и ssub_match приведена в следующем разделе, а пока достаточно знать, что они предоставляют доступ к контексту соответствия. У типов соответствия есть функции-члены prefix() и suffix(), возвращающие объект класса ssub_match, представляющий часть исходной последовательности перед и после текущего соответствия соответственно. У класса ssub_match есть функции-члены str() и length(), возвращающие соответствующую строку и ее размер соответственно. Используя эти функции, можно переписать цикл программы проверки правописания:
// тот же заголовок цикла for, что и прежде
for (sregex_iterator it(file.begin(), file.end(), r), end_it;
it != end_it; ++it) {
auto pos = it->prefix().length(); // размер префикса
pos = pos > 40 ? pos - 40 : 0; // необходимо до 40 символов
cout << it->prefix().str().substr(pos) // последняя часть префикса
<< " >>> " << it->str() << " <<< " // соответствующее
// слово
<< it->suffix().str().substr(0, 40) // первая часть суффикса
<< endl;
}
Таблица 17.10. Операции с типом smatch
Эти операции применимы также к типам cmatch, wsmatch, wcmatch и соответствующим типам csub_match, wssub_match и wcsub_match. m.ready() Возвращает значение true, если m был установлен вызовом функции regex_search() или regex_match(), в противном случае — значение false (в этом случае результат операции с m непредсказуем) m.size() Возвращает значение 0, если соответствия не найдено, в противном случае — на единицу больше, чем количество подвыражений в последнем соответствующем регулярном выражении m.empty() Возвращает значение true, если размер нулевой m.prefix() Возвращает объект класса ssub_match, представляющий последовательность перед соответствием m.suffix() Возвращает объект класса ssub_match, представляющий часть после конца соответствия m.format(...) См. табл. 17.12 В функциях, получающих индекс, n по умолчанию имеет значение нуль и должно быть меньше m.size(). Первое соответствие (с индексом 0) представляет общее соответствие. m.length(n) Возвращает размер соответствующего подвыражения номер n m.position(n) Дистанция подвыражения номер n от начала последовательности m.str(n) Соответствующая строка для подвыражения номер n m[n] Объект ssub_match, соответствующий подвыражению номер n m.begin(), m.end() m.cbegin(), m.cend() Итераторы элементов sub_match в m. Как обычно, функции cbegin() и cend() возвращают итераторы const_iteratorБолее подробная информация о smatch и ssub_match приведена в следующем разделе, а пока достаточно знать, что они предоставляют доступ к контексту соответствия. У типов соответствия есть функции-члены prefix() и suffix(), возвращающие объект класса ssub_match, представляющий часть исходной последовательности перед и после текущего соответствия соответственно. У класса ssub_match есть функции-члены str() и length(), возвращающие соответствующую строку и ее размер соответственно. Используя эти функции, можно переписать цикл программы проверки правописания:
// тот же заголовок цикла for, что и прежде
for (sregex_iterator it(file.begin(), file.end(), r), end_it;
it != end_it; ++it) {
auto pos = it->prefix().length(); // размер префикса
pos = pos > 40 ? pos - 40 : 0; // необходимо до 40 символов
cout << it->prefix().str().substr(pos) // последняя часть префикса
<< " >>> " << it->str () << " <<< " // соответствующее
// слово
<< it->suffix().str().substr(0, 40) // первая часть суффикса
<< endl;
}
Сам цикл работает, как и прежде. Изменился процесс в цикле for, представленный на рис. 17.2.

Рис. 17.2. Объект класса smatch, представляющий некое соответствие
Здесь происходит вызов функции prefix(), возвращающий объект класса ssub_match, представляющий часть строки file перед текущим соответствием. Чтобы выяснить, сколько символов находится в части строки file перед соответствием, вызовем функцию length() для этого объекта класса ssub_match. Затем скорректируем значение pos так, чтобы оно было индексом 40-го символа от конца префикса. Если у префикса меньше 40 символов, устанавливаем pos в 0, означая, что выведен весь префикс. Функция substr() (см. раздел 9.5.1) используется для вывода от данной позиции до конца префикса.
После вывода символов, предшествующих соответствию, выводится само соответствие с некоторым дополнительным оформлением, чтобы соответствующее слово выделилось в выводе. После вывода соответствующей части выводится до 40 следующих после соответствия символов строки file.
Упражнения раздела 17.3.2
Упражнение 17.17. Измените свою программу так, чтобы она находила все слова в исходной последовательности, нарушающие правило "i перед е, кроме как после с".
Упражнение 17.18. Пересмотрите свою программу так, чтобы игнорировать слова, содержащие сочетание "ei", но не являющиеся ошибочными, такие как "albeit" и "neighbor".
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК