Создание монад
В этом разделе мы рассмотрим пример, показывающий, как тип создаётся, опознаётся как монада, а затем для него создаётся подходящий экземпляр класса Monad. Обычно мы не намерены создавать монаду с единственной целью – создать монаду. Наоборот, мы создаём тип, цель которого – моделировать аспект некоторой проблемы, а затем, если впоследствии мы видим, что этот тип представляет значение с контекстом и может действовать как монада, мы определяем для него экземпляр класса Monad.
Как вы видели, списки используются для представления недетерминированных значений. Список вроде [3,5,9] можно рассматривать как одно недетерминированное значение, которое просто не может решить, чем оно будет. Когда мы передаём список в функцию с помощью операции >>=, это просто создаёт все возможные варианты получения элемента из списка и применения к нему функции, а затем представляет эти результаты также в списке.
Если мы посмотрим на список [3,5,9] как на числа 3, 5, и 9, встречающиеся одновременно, то можем заметить, что нет никакой информации в отношении того, какова вероятность встретить каждое из этих чисел. Что если бы нам было нужно смоделировать недетерминированное значение вроде [3,5,9], но при этом мы бы хотели показать, что 3 имеет 50-процентный шанс появиться, а вероятность появления 5 и 9 равна 25%? Давайте попробуем провести эту работу!
Скажем, что к каждому элементу списка прилагается ещё одно значение: вероятность того, что он появится. Имело бы смысл представить это значение вот так:
[(3,0.5),(5,0.25),(9,0.25)]
Вероятности в математике обычно выражают не в процентах, а в вещественных числах между 0 и 1. Значение 0 означает, что чему-то ну никак не суждено сбыться, а значение 1 – что это что-то непременно произойдёт. Числа с плавающей запятой могут быстро создать путаницу, потому что они стремятся к потере точности, но язык Haskell предлагает тип данных для вещественных чисел. Он называется Rational, и определён он в модуле Data.Ratio. Чтобы создать значение типа Rational, мы записываем его так, как будто это дробь. Числитель и знаменатель разделяются символом %. Вот несколько примеров:
ghci> 1 % 4
1 % 4
ghci> 1 % 2 + 1 % 2
1 % 1
ghci> 1 % 3 + 5 % 4
19 % 12
Первая строка – это просто одна четвёртая. Во второй строке мы складываем две половины, чтобы получить целое. В третьей строке складываем одну третью с пятью четвёртыми и получаем девять двенадцатых. Поэтому давайте выбросим эти плавающие запятые и используем для наших вероятностей тип Rational:
ghci> [(3,1 % 2),(5,1 % 4),(9,1 % 4)]
[(3,1 % 2),(5,1 % 4),(9,1 % 4)]
Итак, 3 имеет один из двух шансов появиться, тогда как 5 и 9 появляются один раз из четырёх. Просто великолепно!
Мы взяли списки и добавили к ним некоторый дополнительный контекст, так что это тоже представляет значения с контекстами. Прежде чем пойти дальше, давайте обернём это в newtype, ибо, как я подозреваю, мы будем создавать некоторые экземпляры.
import Data.Ratio
newtype Prob a = Prob { getProb :: [(a, Rational)] } deriving Show
Это функтор?.. Ну, раз список является функтором, это тоже должно быть функтором, поскольку мы только что добавили что-то в список. Когда мы отображаем список с помощью функции, то применяем её к каждому элементу. Тут мы тоже применим её к каждому элементу, но оставим вероятности как есть. Давайте создадим экземпляр:
instance Functor Prob where
fmap f (Prob xs) = Prob $ map ((x, p) –> (f x, p)) xs
Мы разворачиваем его из newtype при помощи сопоставления с образцом, затем применяем к значениям функцию f, сохраняя вероятности как есть, и оборачиваем его обратно. Давайте посмотрим, работает ли это:
ghci> fmap negate (Prob [(3,1 % 2),(5,1 % 4),(9,1 % 4)])
Prob {getProb = [(-3,1 % 2),(-5,1 % 4),(-9,1 % 4)]}
Обратите внимание, что вероятности должны давать в сумме 1. Если все эти вещи могут случиться, не имеет смысла, чтобы сумма их вероятностей была чем-то отличным от 1. Думаю, выпадение монеты на решку 75% раз и на орла 50% раз могло бы происходить только в какой-то странной Вселенной.
А теперь главный вопрос: это монада? Учитывая, что список является монадой, похоже, и это должно быть монадой. Во-первых, давайте подумаем о функции return. Как она работает со списками? Она берёт значение и помещает его в одноэлементный список. Что здесь происходит? Поскольку это должен быть минимальный контекст по умолчанию, она тоже должна создавать одноэлементный список. Что же насчёт вероятности? Вызов выражения return x должен создавать монадическое значение, которое всегда представляет x как свой результат, поэтому не имеет смысла, чтобы вероятность была равна 0. Если оно всегда должно представлять это значение как свой результат, вероятность должна быть равна 1!
А что у нас с операцией >>=? Выглядит несколько мудрёно, поэтому давайте воспользуемся тем, что для монад выражение m >>= f всегда равно выражению join (fmap f m), и подумаем, как бы мы разгладили список вероятностей списков вероятностей. В качестве примера рассмотрим список, где существует 25-процентный шанс, что случится именно 'a' или 'b'. И 'a', и 'b' могут появиться с равной вероятностью. Также есть шанс 75%, что случится именно 'c' или 'd'. То есть 'c' и 'd' также могут появиться с равной вероятностью. Вот рисунок списка вероятностей, который моделирует данный сценарий:
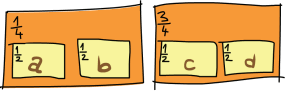
Каковы шансы появления каждой из этих букв? Если бы мы должны были изобразить просто четыре коробки, каждая из которых содержит вероятность, какими были бы эти вероятности? Чтобы узнать это, достаточно умножить каждую вероятность на все вероятности, которые в ней содержатся. Значение 'a' появилось бы один раз из восьми, как и 'b', потому что если мы умножим одну четвёртую на одну четвёртую, то получим одну восьмую. Значение 'c' появилось бы три раза из восьми, потому что три четвёртых, умноженные на одну вторую, – это три восьмых. Значение 'd' также появилось бы три раза из восьми. Если мы сложим все вероятности, они по-прежнему будут давать в сумме единицу.
Вот эта ситуация, выраженная в форме списка вероятностей:
thisSituation :: Prob (Prob Char)
thisSituation = Prob
[(Prob [('a',1 % 2),('b',1 % 2)], 1 % 4)
,(Prob [('c',1 % 2),('d',1 % 2)], 3 % 4)
]
Обратите внимание, её тип – Prob (Prob Char). Поэтому теперь, когда мы поняли, как разгладить вложенный список вероятностей, всё, что нам нужно сделать, – написать для этого код. Затем мы можем определить операцию >>= просто как join (fmap f m), и заполучим монаду! Итак, вот функция flatten, которую мы будем использовать, потому что имя join уже занято:
flatten :: Prob (Prob a) –> Prob a
flatten (Prob xs) = Prob $ concat $ map multAll xs
where multAll (Prob innerxs, p) = map ((x, r) –> (x, p*r)) innerxs
Функция multAll принимает кортеж, состоящий из списка вероятностей и вероятности p, которая к нему приложена, а затем умножает каждую внутреннюю вероятность на p, возвращая список пар элементов и вероятностей. Мы отображаем каждую пару в нашем списке вероятностей с помощью функции multAll, а затем просто разглаживаем результирующий вложенный список.
Теперь у нас есть всё, что нам нужно. Мы можем написать экземпляр класса Monad!
instance Monad Prob where
return x = Prob [(x,1 % 1)]
m >>= f = flatten (fmap f m)
fail _ = Prob []
Поскольку мы уже сделали всю тяжелую работу, экземпляр очень прост. Мы определили функцию fail, которая такова же, как и для списков, поэтому если при сопоставлении с образцом в выражении do происходит неудача, неудача случается в контексте списка вероятностей.
Важно также проверить, что для только что созданной нами монады выполняются законы монад:
1. Первое правило говорит, что выражение return x >>= f должно равняться выражению f x. Точное доказательство было бы довольно громоздким, но нам видно, что если мы поместим значение в контекст по умолчанию с помощью функции return, затем отобразим это с помощью функции, используя fmap, а потом отобразим результирующий список вероятностей, то каждая вероятность, являющаяся результатом функции, была бы умножена на вероятность 1 % 1, которую мы создали с помощью функции return, так что это не повлияло бы на контекст.
2. Второе правило утверждает, что выражение m >> return ничем не отличается от m. Для нашего примера доказательство того, что выражение m >> return равно просто m, аналогично доказательству первого закона.
3. Третий закон утверждает, что выражение f <=< (g <=< h) должно быть аналогично выражению (f <=< g) <=< h. Это тоже верно, потому что данное правило выполняется для списковой монады, которая составляет основу для монады вероятностей, и потому что умножение ассоциативно. 1 % 2 * (1 % 3 * 1 % 5) равно (1 % 2 * 1 % 3) * 1 % 5.
Теперь, когда у нас есть монада, что мы можем с ней делать? Она может помочь нам выполнять вычисления с вероятностями. Мы можем обрабатывать вероятностные события как значения с контекстами, а монада вероятностей обеспечит отражение этих вероятностей в вероятностях окончательного результата.
Скажем, у нас есть две обычные монеты и одна монета, с одной стороны налитая свинцом: она поразительным образом выпадает на решку девять раз из десяти и на орла – лишь один раз из десяти. Если мы подбросим все монеты одновременно, какова вероятность того, что все они выпадут на решку? Во-первых, давайте создадим значения вероятностей для подбрасывания обычной монеты и для монеты, налитой свинцом:
data Coin = Heads | Tails deriving (Show, Eq)
coin :: Prob Coin
coin = Prob [(Heads,1 % 2),(Tails,1 % 2)]
loadedCoin :: Prob Coin
loadedCoin = Prob [(Heads,1 % 10),(Tails,9 % 10)]
И наконец, действие по подбрасыванию монет:
import Data.List (all)
flipThree :: Prob Bool
flipThree = do
a <– coin
b <– coin
c <– loadedCoin
return (all (==Tails) [a,b,c])
При попытке запустить его видно, что вероятность выпадения решки у всех трёх монет не так высока, даже несмотря на жульничество с нашей налитой свинцом монетой:
ghci> getProb flipThree
[(False,1 % 40),(False,9 % 40),(False,1 % 40),(False,9 % 40),
(False,1 % 40),(False,9 % 40),(False,1 % 40),(True,9 % 40)]
Все три приземлятся решкой вверх 9 раз из 40, что составляет менее 25%!.. Видно, что наша монада не знает, как соединить все исходы False, где все монеты не приземляются решкой вверх, в один исход. Впрочем, это не такая серьёзная проблема, поскольку написание функции для вставки всех одинаковых исходов в один исход довольно просто (это упражнение я оставляю вам в качестве домашнего задания).
В этом разделе мы перешли от вопроса («Что если бы списки также содержали информацию о вероятностях?») к созданию типа, распознанию монады и, наконец, созданию экземпляра и выполнению с ним некоторых действий. Думаю, это очаровательно! К этому времени у вас уже должно сложиться довольно неплохое понимание монад и их сути.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК