Вырастим-ка дерево
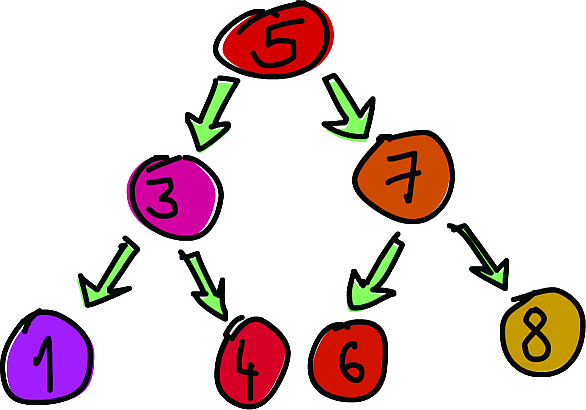
Теперь мы собираемся реализовать бинарное поисковое дерево. Если вам не знакомы поисковые деревья из языков наподобие С, вот что они представляют собой: элемент указывает на два других элемента, один из которых правый, другой – левый. Элемент слева – меньше, чем текущий, элемент справа – больше. Каждый из этих двух элементов также может ссылаться на два других элемента (или на один, или не ссылаться вообще). Получается, что каждый элемент может иметь до двух поддеревьев. Бинарные поисковые деревья удобны тем, что мы знаем, что все элементы в левом поддереве элемента со значением, скажем, пять, будут меньше пяти. Элементы в правом поддереве будут больше пяти. Таким образом, если нам надо найти 8 в нашем дереве, мы начнём с пятёрки, и так как 8 больше 5, будем проверять правое поддерево. Теперь проверим узел со значением 7, и так как 8 больше 7, снова выберем правое поддерево. В результате элемент найдётся всего за три операции сравнения! Если мы бы искали в обычном списке (или в сильно разбалансированном дереве), потребовалось бы до семи сравнений вместо трёх для поиска того же элемента.
ПРИМЕЧАНИЕ. Множества и отображения из модулей Data.Set и Data.Map реализованы с помощью деревьев, но вместо обычных бинарных поисковых деревьев они используют сбалансированные поисковые деревья. Дерево называется сбалансированным, если высоты его левого и правого поддеревьев примерно равны. Это условие ускоряет поиск по дереву. В наших примерах мы реализуем обычные поисковые деревья.
Вот что мы собираемся сказать: дерево – это или пустое дерево, или элемент, который содержит некоторое значение и два поддерева. Такая формулировка идеально соответствует алгебраическому типу данных.
data Tree a = EmptyTree | Node a (Tree a) (Tree a) deriving (Show)
Что ж, отлично. Вместо того чтобы вручную создавать дерево, мы напишем функцию, которая принимает дерево и элемент и добавляет элемент к дереву. Мы будем делать это, сравнивая вставляемый элемент с корневым. Если вставляемый элемент меньше корневого – идём налево, если больше – направо. Эту же операцию продолжаем для каждого последующего узла дерева, пока не достигнем пустого дерева. После этого мы добавляем новый элемент вместо пустого дерева.
В языках, подобных С, мы бы делали это, изменяя указатели и значения внутри дерева. В Haskell мы на самом деле не можем изменять наше дерево – придётся создавать новое поддерево каждый раз, когда мы переходим к левому или правому поддереву. Таким образом, в конце функции добавления мы вернём полностью новое дерево, потому что в языке Haskell нет концепции указателей, есть только значения. Следовательно, тип функции для добавления элемента будет примерно следующим: a –> Tree a – > Tree a. Она принимает элемент и дерево и возвращает новое дерево с уже добавленным элементом. Это может показаться неэффективным, но язык Haskell умеет организовывать совместное владение большей частью поддеревьев старым и новым деревьями.
Итак, напишем две функции. Первая будет вспомогательной функцией для создания дерева, состоящего из одного элемента; вторая будет вставлять элемент в дерево.
singleton :: a –> Tree a
singleton x = Node x EmptyTree EmptyTree
treeInsert :: (Ord a) => a –> Tree a –> Tree a
treeInsert x EmptyTree = singleton x
treeInsert x (Node a left right)
| x == a = Node x left right
| x < a = Node a (treeInsert x left) right
| x > a = Node a left (treeInsert x right)
Функция singleton служит для создания узла, который хранит некоторое значение и два пустых поддерева. В функции для добавления нового элемента в дерево мы вначале обрабатываем граничное условие. Если мы достигли пустого поддерева, это значит, что мы в нужном месте нашего дерева, и вместо пустого дерева помещаем одноэлементное дерево, созданное из нашего значения. Если мы вставляем не в пустое дерево, следует кое-что проверить. Первое: если вставляемый элемент равен корневому элементу – просто возвращаем дерево текущего элемента. Если он меньше, возвращаем дерево, которое имеет то же корневое значение и то же правое поддерево, но вместо левого поддерева помещаем дерево с добавленным элементом. Так же (но с соответствующими поправками) обстоит дело, если значение больше, чем корневой элемент.
Следующей мы напишем функцию для проверки, входит ли некоторый элемент в наше дерево или нет. Для начала определим базовые случаи. Если мы ищем элемент в пустом дереве, его там определённо нет. Заметили – такой же базовый случай мы использовали для поиска элемента в списке? Если мы ищем в пустом списке, то ничего не найдём. Если ищем не в пустом дереве, надо проверить несколько условий. Если элемент в текущем корне равен тому, что мы ищем, – отлично. Ну а если нет, тогда как быть?.. Мы можем извлечь пользу из того, что все элементы в левом поддереве меньше корневого элемента. Поэтому, если искомый элемент меньше корневого, начинаем искать в левом поддереве. Если он больше – ищем в правом поддереве.
treeElem :: (Ord a) => a –> Tree a –> Bool
treeElem x EmptyTree = False
treeElem x (Node a left right)
| x == a = True
| x < a = treeElem x left
| x > a = treeElem x right
Всё, что нам нужно было сделать, – переписать предыдущий параграф в коде. Давайте немного «погоняем» наши деревья. Вместо того чтобы вручную задавать деревья (а мы можем!), будем использовать свёртку для того, чтобы создать дерево из списка. Запомните: всё, что обходит список элемент за элементом и возвращает некоторое значение, может быть представлено свёрткой. Мы начнём с пустого дерева и затем будем проходить список справа налево и вставлять элемент за элементом в дерево-аккумулятор.
ghci> let nums = [8,6,4,1,7,3,5]
ghci> let numsTree = foldr treeInsert EmptyTree nums
ghci> numsTree
Node 5
(Node 3
(Node 1 EmptyTree EmptyTree)
(Node 4 EmptyTree EmptyTree)
)
(Node 7
(Node 6 EmptyTree EmptyTree)
(Node 8 EmptyTree EmptyTree)
)
ПРИМЕЧАНИЕ. Если вы вызовете этот код в интерпретаторе GHCi, то в качестве вывода будет одна длинная строка. Здесь она разбита на несколько строк, иначе она бы вышла за пределы страницы.
В этом вызове функции foldr функция treeInsert играет роль функции свёртки (принимает дерево и элемент списка и создаёт новое дерево); EmptyTree – стартовое значение аккумулятора. Параметр nums – это, конечно же, список, который мы сворачиваем.
Если напечатать дерево на консоли, мы получим не очень-то легко читаемое выражение, но если постараться, можно уловить структуру. Мы видим, что корневое значение – 5; оно имеет два поддерева, в одном из которых корневым элементом является 3, а в другом – 7, и т. д.
ghci> 8 `treeElem` numsTree
True
ghci> 100 `treeElem` numsTree
False
ghci> 1 `treeElem` numsTree
True
ghci> 10 `treeElem` numsTree
False
Проверка на вхождение также работает отлично. Классно!
Как вы можете видеть, алгебраические типы данных в языке Haskell нереально круты. Мы можем использовать их для создания чего угодно – от булевских значений и перечислимого типа для дней недели до бинарных поисковых деревьев и даже большего!
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК