11.1. Анализ
11.1. Анализ
Определение границ предметной области
Как сказано во врезке, мы намерены заняться криптоанализом - процессом преобразования зашифрованного текста в обычный. В общем случае процесс дешифровки является чрезвычайно сложным и не поддается даже самым мощным научным методам. Существует, например, стандарт шифрования DES (Data Encryption Standard, алгоритм шифрования с закрытым ключом, в котором используются многочисленные подстановки и перестановки), который, по-видимому, свободен от слабых мест и устойчив ко всем известным методам взлома. Но наша задача значительно проще, поскольку мы ограничимся шифрами с одной подстановкой.
В качестве первого шага анализа попробуйте решить (только честно, не заглядывая вперед!) следующую криптограмму записывая, каждый ваш шаг:
Q AZWS DSSC KAS DXZNN DASNN
Подсказка: буква w соответствует букве v исходного текста. Перебор всех возможных вариантов совершенно лишен смысла. Предполагая, что алфавит содержит 26 прописных английских букв, получим 26! (около 4.03х1026) возможных комбинаций. Следовательно, нужно искать другой метод решения, например, использовать знания о структуре слов и предложений и делать правдоподобные допущения. Как только мы исчерпаем явные решения, мы сделаем наиболее вероятное предположение и будем продвигаться дальше. Если обнаружится, что предположение приводит к противоречию или заводит в тупик, мы вернемся назад и сделаем другую попытку.
Требования к системе криптоанализа
Криптография "изучает методы сокрытия данных от посторонних" [3]. Криптографические алгоритмы преобразовывают сообщения (исходный текст) в зашифрованный текст (криптограмму) и наоборот.
Одним из наиболее общеупотребительных (еще со времен Древнего Рима) криптографических алгоритмов является подстановка. Каждая буква в алфавите исходного текста заменяется другой буквой. Например, можно циклически сдвинуть все буквы алфавита: буква A заменяется на B, B на C, a Z на A. Тогда следующий исходный текст:
CLOS is an object-oriented programming language
превращается в криптограмму:
DMPT jt bo pckfdu-psjfoufe qsphsbnnjoh mbohvbhf
Чаще всего замена делается менее тривиальным образом. Например, A заменяется на G, B на J и т.д. Рассмотрим следующую криптограмму:
PDG TBCER CQ TCK AL S NGELCH QZBBR SBAJG
Подсказка: буква C в этой криптограмме соответствует букве O исходного текста.
Существенно упрощает задачу предположение о том, что для шифрования текста использован алгоритм подстановки, поскольку в общем случае процесс дешифровки не будет столь тривиальным. В процессе расшифровки приходится использовать метод проб и ошибок, когда мы делаем предположение о замене и рассматриваем его следствия. Удобно, например, начать расшифровку с предположения о том, что одно- и двухбуквенные слова в криптограмме соответствуют наиболее употребительным словам английского языка (I, a, or, it, in, of, on). Подставляя эти предполагаемые буквы в другие слова, мы можем догадаться о вероятном значении других букв. Например, если трехбуквенное слово начинается с литеры O, то это могут быть слова one, our, off.
Знание фонетики и грамматики также может способствовать дешифровке. Например, следование подряд двух одинаковых литер с очень малой вероятностью может означать qq. Наличие в окончании слова буквы g позволяет сделать предположение о наличии суффикса ing. На еще более высоком уровне абстракции логично предположить, что словосочетание it is более вероятно, чем if is. Необходимо учитывать и структуру предложения: существительные и глаголы. Если выясняется, что в предложении есть глагол, но нет существительного, которое с ним связано, то нужно отвергнуть сделанные ранее предположения н начать поиск заново.
Иногда приходится возвращаться назад, если сделанное предположение вступает в противоречие с другими предположениями. Например, мы допустили, что некоторое двухбуквенное слово соответствует сочетанию or, что в дальнейшем привело к противоречию. В этом случае мы должны вернуться назад и попытаться использовать другой вариант расшифровки этого слова, например, on.
Требования к нашей системе: по данной криптограмме, в предположении, что использована простая подстановка, найти эту подстановку и (главное) восстановить исходный текст.
Вот наше решение, шаг за шагом:
1. Используя подсказку, заменим w на v.
Q AZVS DSSC KAS DXZNN DASNN
2. Первое слово из одной буквы, вероятна, A или I; предположим, что это A:
A AZVS DSEC KAS DXZNN DASNN
3. В третьем слове должны быть гласные звуки и вероятно, что это двойные буквы. Это не могут быть UU или II, а также AA (буква A уже использована). Попробуем вариант EE.
A AZVE DEEC KAE DXZNN DAENN
4. Четвертое слово состоит из трех букв и оканчивается на E, это очень похоже на слово THE.
A HZVE DEEC THE DXZNN DHENN
5. Во втором слове нужна гласная, и здесь подходят только I, O, U (буква A уже использована). Только вариант с буквой I дает осмысленное слово.
A HIVE DEEC THE DXINN DHENN
6. Можно найти несколько слов с двойной буквой E из четырех букв (DEER, BEER, SEEN). Грамматика требует, чтобы третье слово было глаголом, поэтому остановимся на SEEN.
A HIVE SEEN THE SXINN SHENN
7. Смысл в полученном предложении отсутствует, поскольку улей (HIVE) не может видеть (SEEN), значит, где-то по дороге мы сделали ошибку. Похоже, что выбор гласной буквы во втором слове был неверен, и приходится вернуться назад, отменив самое первое предположение - первым словом должно быть I. Повторяя все остальные наши рассуждения практически без изменений мы получаем:
I HAVE SEEN THE SXANN SHENN
8. Посмотрим на два последних слова. Двойная буква S в конце не дает осмысленного значения и к тому же уже использована ранее, а вот LL дает осмысленное слово.
I HAVE SEEN THE SXALL SHELL
9. Из грамматических соображений очевидно, что оставшееся слово - прилагательное. Анализируя шаблон S?ALL, находим SMALL.
I HAVE SEEN THE SMALL SHELL
Таким образом, решение найдено. Анализируя процесс решения, мы можем сделать три наблюдения:
• Для решения применялись разнообразные знания: о грамматике, о составе слов, о чередовании согласных и гласных.
• Сделанные предположения регистрировались, потом мы применяли к ним имеющиеся у нас знания и смотрели, что из этого получается.
• Мы подходили к делу наугад, приспосабливаясь к обстановке. Иногда делались выводы от общего к частному (словом из трех букв, оканчивающимся на E будет, вероятно, THE), а иногда от частного к общему (?EE? может соответствовать DEER, BEER, SEEN, но глаголом из них является только SEEN).
Изложенный подход известен как метод информационной доски. Он впервые был предложен Ньюэллом в 1962 году, а позднее был использован Редди и Ерманом в проектах Hearsay и Hearsay II по распознаванию речи [4]. Эффективность метода подтвердилась, и он был использован в других областях, включая интерпретацию сигналов, трехмерное моделирование молекулярных структур, распознавание образов и планирование [5]. Метод показал хорошие результаты в представлении описательных знаний; он более эффективен с точки зрения памяти и времени по сравнению с другими подходами [6].
Информационная доска вполне подходит на роль среды разработки (см. главу 9). Попробуем теперь зафиксировать архитектуру этого метода в виде системы классов и механизмов их взаимодействия.
Архитектура метафоры информационной доски
Энглемор и Морган для пояснения модели информационной доски использовали следующую аналогию с группой людей, собирающей фрагменты головоломки в нужную фигуру:
Вообразим себе комнату с большой доской, рядом с которой находится группа людей, держащих в руках фрагменты изображения. Процесс начинают добровольцы, которые размещают на доске наиболее "вероятные" фрагменты изображения (предположим, что они прилепляются к доске). Далее каждый участник группы смотрит на оставшиеся у него фрагменты и решает, есть ли такие, которые подходят к уже находящимся на доске. Участник, нашедший соответствие, подходит к доске и прилепляет свой кусок. В результате фрагмент за фрагментом занимают нужное место. При этом не существенно, что один из участников может иметь больше фрагментов, чем другой. Все изображение будет полностью собрано без всякого обмена информацией между членами группы. Каждый участник активизируется самостоятельно и знает, когда ему нужно включиться в процесс. Никакого порядка подхода к доске заранее не устанавливается. Совместное поведение регулируется только информацией на доске. Наблюдение за процессом демонстрирует его последовательность (по одному фрагменту за подход) и произвольность (когда возникает возможность, фрагмент устанавливается). Это существенно отличается от строгой систематичности, например, от прохождения с левого верхнего угла и перебора каждого фрагмента [7].
Из рис. 11-1 видно, что основу метода составляют три элемента: информационная доска, совокупность источников знаний и управляющий этими источниками контроллер [8]. Отметим, что следующее определение прямо соответствует принципам объектного подхода. Согласно Ни: "Информационная доска нужна для того чтобы хранить данные о ходе и состоянии решаемой задачи, используемые и формируемые источниками знаний. Доска содержит объекты из пространства решений. Эти объекты иерархически группируются по уровням анализа и вместе со своими атрибутами образуют словарь пространства решений" [9].
Энглемор и Морган уточняют: "необходимые для решения задачи знания о предметной области разделены на несколько независимых источников. Каждый источник знаний старается предложить информацию, полезную для решения за дачи. Текущая информация из каждого источника помещается на доске и модифицируется в соответствии с содержанием знаний. Формой представления источников знаний являются процедуры, наборы правил или логические заключения" [10].
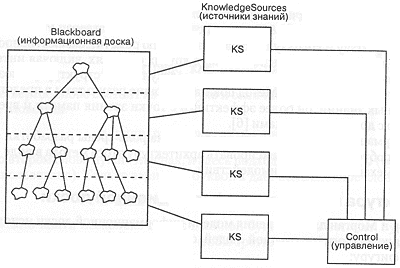
Рис. 11-1. Информационная доска.
Источники знаний зависят от предметной области. В системах распознавания речи нас могут интересовать агенты, поставляющие знания о фонемах, словах и предложениях. В системах распознавания образов ими могут быть сведения об элементарных структурах изображения, таких, как стыки линий, участки одинаковой плотности, и, на более высоком уровне абстракции, объекты, относящиеся к конкретной сцене (дома, дороги, поля, автомобили и люди).
В общем случае источники знаний соответствуют иерархической структуре объектов, размещаемых на информационной доске. Более того, каждый источник использует объекты одного уровня иерархии в качестве входных данных, а в качестве выхода генерирует или изменяет объекты на другом уровне. Например, в системе распознавания речи источник знаний о словах наблюдает за потоком фонем (низкий уровень абстракции), чтобы обнаружить слово (более высокий уровень абстракции). Источник знаний о предложениях может предположить, что здесь нужен глагол (высокий уровень абстракции) и проверить это предположение, перебрав список возможных слов (низкий уровень абстракции).
Эти два подхода к поиску решения называются соответственно прямой и обратной последовательностью рассуждений. Прямая последовательность рассуждений позволяет перейти от более частных предположений к более общим, а обратная последовательность, отталкиваясь от некоторой гипотезы, позволяет проверить ее, сравнив с известными предпосылками. Вот почему управление информационной доской мы охарактеризовали как произвольное: в зависимости от обстоятельств, источники знаний могут активизировать либо прямые, либо обратные последовательности рассуждений.
Источники знаний, как правило, состоят из двух компонент: предусловия и действия. Предусловием называется такое состояние информационной доски, которое представляет "интерес" для конкретного источника знаний (потенциально способно его активизировать). Например, в распознавании образов предусловием может быть наличие прямой линии (которая может означать дорогу). Выполнение предусловий заставляет источник знаний сфокусировать внимание на конкретном участке информационной доски, а затем привести в действие соответствующие правила или процедурные знания.
В этих условиях очередность активизации не имеет значения: если источник знаний обнаруживает данные, полезные для решения задачи, он сигнализирует об этом контроллеру доски, фигурально выражаясь, он как бы поднимает руку, показывая, что желает сделать что-то полезное. Из нескольких источников, делающих такой жест, контроллер вызывает того, кто ему представляется наиболее перспективным.
Анализ источников знаний
Вернемся теперь к поставленной задаче и рассмотрим источники знаний, полезные для ее решения. При построении большинства приложений, основанных на знаниях, лучше всего сесть рядом с экспертом в предметной области и фиксировать те эвристики, которые он использует. В нашем случае придется попытаться расшифровать некоторое количество криптограмм и отметить особенности процесса поиска решений.
Действуя таким образом мы выявили тринадцать источников знаний, относящихся к нашей проблеме:
? Префиксы Наиболее часто используемые начала слов (например, re, anti, un).
? Суффиксы Наиболее часто используемые окончания слов (ly, ing, es, ed).
? Согласные Буквы, не являющиеся гласными.
? Непосредственно известные подстановки Подстановки, известные нам априори, до решения задачи.
? Двойные буквы Наиболее часто сдваиваемые буквы (tt, ll, ss).
? Частота букв Вероятность появления букв в тексте.
? Правильные строки Допустимые и недопустимые сочетания букв (например, qu и zg).
? Сравнение с шаблоном Слова, соответствующие шаблону.
? Структура фраз Грамматика, включая знания об именных и глагольных оборотах.
? Короткие слова Одно-, двух-, трех- и четырехбуквенные слова.
? Решение Найдено ли решение или мы зашли в тупик.
? Гласные Буквы, не являющиеся согласными.
? Структура слова Расположение гласных и типичная структура существительных, глаголов, прилагательных, наречий, предлогов, союзов и т.д.
Исходя из объектно-ориентированного подхода, все эти источники знаний являются потенциальными кандидатами на роль классов, на основе которых создаются объекты, обладающие состоянием (знания), поведением (источник знаний о суффиксах может среагировать на слово с характерным окончанием) и индивидуальностью (знания о коротких словах не зависят от умения сравнивать с шаблоном).
Перечисленные источники знаний можно организовать в иерархию. В частности, существуют группы источников знаний о предложениях, о словах, о группах букв и об отдельных буквах. Такая иерархия соответствует объектам на информационной доске: предложениям, словам, частям слов и буквам.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Анализ схемы
Анализ схемы Чтобы выполнить анализ и получить выходной файл, выберем PSpice, New Simulation Profile из главного меню. В окне New Simulation наберите имя rthrees, затем нажмите на кнопку Create. Появляется окно Simulation Settings с меню в верхней части (рис. 14.4). Выберите позицию Analysis в поле Analysis type: выберите
Измерения и анализ
Измерения и анализ Измерение 1. Выполнение измерений и использование их результатов для определения состояния работ по управлению конфигурацией.Примеры измерений:количество запросов на изменение, обрабатываемое за единицу времени;выполнение этапов работ по
Измерения и анализ
Измерения и анализ Измерение 1. Выполнение измерений и использование их результатов для определения статуса мероприятий по разработке и усовершенствованию производственного процесса организации.Примеры измерений:определение объема выполненных работ по оценке,
Измерения и анализ
Измерения и анализ Измерение 1. Выполнение измерений и использование их результатов для выяснения состояния работ по определению производственного процесса организации.Примеры измерений:статус выполнения этапов календарного плана разработки и сопровождения
Измерения и анализ
Измерения и анализ Измерение 1. Выполнение измерений и использование их результатов для определения статуса мероприятий по обучению.Примеры измерений:фактическая посещаемость каждого учебного курса в сравнении с запланированной,фактическое проведение учебных курсов
Измерения и анализ
Измерения и анализ Измерение 1. Выполнение измерений и использование их результатов для определения эффективности работ по интегрированному управлению разработкой ПО.Примеры измерений:объем выполненных на текущий момент работ по управлению проектом в сравнении с
Измерения и анализ
Измерения и анализ Измерение 1. Выполнение измерений и использование их результатов для определения функциональных возможностей и качества программных продуктов.Примеры измерений:количество, типы и серьезность дефектов, выявленных в программных продуктах,
Измерения и анализ
Измерения и анализ Измерение 1. Выполнение измерений и использование их результатов для определения статуса мероприятий по межгрупповой координации.Примеры фактических измерений:объем трудозатрат и других ресурсов, израсходованных разработчиками на поддержку других
Урок № 96. Анализ счета и анализ субконто
Урок № 96. Анализ счета и анализ субконто Анализ счета также относится к числу популярных отчетов программы "1С". Чтобы сформировать этот отчет, нужно выполнить команду главного меню Отчеты | Анализ счета, затем в открывшемся окне указать отчетный период, счет и
8.1. Анализ
8.1. Анализ Определение границ рассматриваемой задачи Врезка ознакомила вас с требованиями к системе мониторинга погоды. Это довольно простая задача, решение которой позволяет обойтись всего несколькими классами. Инженер, не вполне искушенный во всех особенностях
9.1. Анализ
9.1. Анализ Определение границ проблемной области На врезке представлены детально сформулированные требования к библиотеке базовых классов. К сожалению, эти требования навряд ли практически выполнимы: библиотека, содержащая абстракции, необходимые для всех возможных
10.1. Анализ
10.1. Анализ Определение границ задачи Требования к системе складского учета показаны на врезке. Это достаточно сложная программная система, затрагивающая все аспекты, связанные с движением товара на склад и со склада. Для хранения продукции служит, естественно, реальный
11.1. Анализ
11.1. Анализ Определение границ предметной области Как сказано во врезке, мы намерены заняться криптоанализом - процессом преобразования зашифрованного текста в обычный. В общем случае процесс дешифровки является чрезвычайно сложным и не поддается даже самым мощным
12.1. Анализ
12.1. Анализ Определение границ проблемной области Для большинства люден, живущих в США, поезда являются символом давно ушедшей эпохи. В Европе и странах Востока ситуация совершенно противоположная. В отличие от США, в Европе мало национальных и международных