10.2. Проектирование
10.2. Проектирование
Формулируя подходы к архитектуре системы складского учета, мы должны помнить о трех моментах организационного характера: разделение функций между клиентской и серверной частью, механизм управления транзакциями, стратегия реализации клиентской части приложения.
Архитектура клиент/сервер
Наиболее важным вопросом реализации архитектуры клиент/сервер является не столько вопрос о том, где будет проведена граница между этими двумя частями, сколько о том, как разумно произвести это разделение. Возвращаясь к первоосновам, ответ на этот вопрос нам известен: нужно сосредоточиться на поведении каждой абстракции, основывающемся на анализе вариантов использования каждой сущности, и только затем принять решение о размещении поведения. После того, как мы проделаем такую работу в отношении нескольких основных объектов, станут ясны общие механизмы, понимание которых поможет нам правильно разместить оставшиеся абстракции.
Для примера рассмотрим поведение классов Order и ProductRecord. Анализ первого из них дает нам следующий перечень необходимых операций:
• construct
• setCustomer
• setOrderAgent
• addItem
• removeItem
• orderID
• customer
• orderAgent
• numberOfItems
• itemAt
• quantityOf
• totalValue
Перечисленные сервисные операции можно сразу выразить на языке C++, предварительно дав два новых определения типов:
// типы идентификационных номеров typedef unsigned int OrderID;
// тип, описывающий местную валюту typedef float Money;
Теперь получаем следующее определение класса:
class Order { public:
Order(); Order(OrderID); Order(const Order&); ~Order(); Orders operator=(const Orders); int operator==(const Orders) const; int operator!=(const Orders) const; void setCustomer(Customer&); void setOrderAgent(OrderAgent&); void addItem(Product&, unsigned int quantity = 1); void removeItem(unsigned int index, unsigned int quantity = 1); OrderID orderID() const; Customer& customer() const; OrderAgent& orderAgent() const; unsigned int numberOfItem() const; Product& itemAt (unsigned int) const; unsigned int quantityOf(unsigned int) const; Money totalValue() const;
protected: ... };
Обратим внимание на наличие нескольких вариантов конструктора. Первый из них используется по умолчанию (Order()) для создания объекта с новым уникальным значением идентификатора OrderID. Копирующий конструктор также создает объект с уникальным идентификатором, но при этом копирует в него состояние объекта, использованного в качестве аргумента.
Последний конструктор принимает в качестве аргумента OrderID, то есть конструирует объект уже существующий в базе данных и извлекает из базы его параметры. Другими словами, в этом случае мы повторно материализуем объект, существующий в базе данных. Такая операция, безусловно, требует выполнения некоторых действий: при восстановлении объекта из базы данных соответствующий SQL-механизм должен либо сделать объект разделяемым, либо синхронизировать состояние двух объектов, созданных в разных приложениях. Детали, конечно, скрыты в реализации и недоступны клиенту, который использует объект, применяя обычный объектный интерфейс.
Реализация описанного подхода не вызывает особых затруднений. Если класс Order спроектирован так, что его состояние полностью определяется идентификатором OrderID, то реализация операций сводится к обычным операторам чтения и записи из базы данных. Копии объектов синхронизируются, поскольку соответствующая таблица в базе служит единым репозиторием состояния для всех представлений одного объекта.
Диаграмма объектов на рис. 10-6 иллюстрирует описанный SQL-механизм на примере сценария выставления счета. В сценарии реализованы следующие события:
• aClient активизирует операцию setCustomer применительно к объекту класса Order; объект класса Customer передается в качестве параметра.
• Объект класса Order вызывает селектор customerID c параметром заказчика, позволяющим получить из базы данных соответствующий первичный ключ.
• Объект, соответствующий заказу, использует SQL-оператор UPDATE, чтобы установить идентификатор заказчика в базе данных заказов.
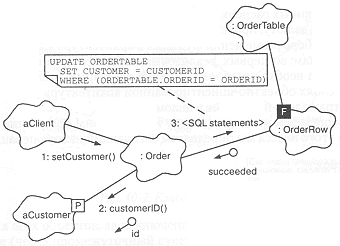
Рис. 10-6. Выставление счета.
Описанный механизм предполагает, что мы можем положиться на существующий в базе данных механизм блокировки записей и взаимного исключения при доступе (представьте себе, что могло бы случиться при одновременном обновлении одной записи из двух приложений). Если этот механизм блокировки должен быть видимым для клиента, то можно воспользоваться тем же подходом, который использовался нами при создании библиотеки классов в главе 9. Ниже мы покажем, что механизм выполнения транзакции позволяет модифицировать за один прием несколько записей в базе, обеспечивая тем самым целостность базы данных.
После реализации описанного механизма вопрос о размещении бизнес-логики имеет скорее тактическое значение. В этом смысле ситуация не отличается от той. которую мы имели бы в не объектно-ориентированной архитектуре. Но в объектно-ориентированной архитектуре можно изменить эти решения, скрыв сам факт изменения от клиента. Таким образом, клиента не затрагивают изменения, которые мы делаем по ходу настройки системы.
Для примера рассмотрим два различных случая. Добавление в базу данных записей о наличии продуктов или удаление их, очевидно, должно согласовываться с бизнес-логикой, поэтому кажется естественным разместить бизнес-логику на сервере. Добавление сведении о новых продуктах в базу данных требует точного их определения и однозначной идентификации. Кроме того, эти данные необходимо сделать доступными для всех клиентов, чтобы обновить их кэшированные таблицы. Удаление продукта из базы также требует проверки на наличие заказов по этому продукту и предупреждения соответствующих клиентов [Для этих семантических отношений как раз и придумали триггеры: они описывают реакцию на некоторые существенные события в базе данных. Приняв объектно-ориентированный взгляд на мир. можно формализовать это соглашение об использовании триггеров, инкапсулируя их как часть семантики операций с объектами базы данных].
Напротив, расчет стоимости заказов является более локальной операцией и его лучше выполнять в клиентской части приложения. Выполняя подсчеты, мы запрашиваем в базе данных расцепки на все элементы заказа, складываем их, пересчитываем в нужную валюту, проверяем на допустимые условия кредитования и т.д.
Итак, при выборе размещения функции в архитектуре клиент/сервер мы следуем двум правилам: во-первых, реализовывать бизнес-правила и алгоритмы там где сосредоточена необходимая информация; во-вторых, размещать эти алгоритмы в нижних слоях объектно-ориентированной архитектуры, чтобы внесение изменении не отражалось на системе в целом.
Теперь вернемся к нашему примеру и рассмотрим более внимательно класс Product. Для этого класса мы определяем следующий набор операций:
• construct
• setDescription
• setQuantity
• setLocation
• setSupplier
• productID
• description
• quantity
• location
• supplier
Эти операции являются общими для всех видов товаров. Однако, анализ частных случаев показывает, что есть продукты, для которых эти характеристики недостаточны. С учетом того, что проектируемая система является открытой, а виды товаров могут быть самыми различными, приведем несколько примеров специфических товаров и их свойств:
• Скоропортящиеся продукты, требующие определенного режима хранения.
• Едкие и токсичные химические вещества, также требующие специального обращения.
• Комплектные товары, которые поставляются в определенных сочетаниях (например, радиопередатчики и приемники) и поэтому взаимозависимы.
• Высокотехнологичные компоненты, поставки которых ограничиваются законодательством стран-экспортеров.
Перечисленные примеры наводят на мысль о необходимости создания некоторой иерархии классов товаров. Однако, перечисленные свойства настолько различны, что не образуют никакой иерархии. В данной ситуации более целесообразно воспользоваться примесями, что иллюстрирует и рис. 10-7. Обратим внимание на использование в этой диаграмме украшений ограничения, уточняющих семантику каждой абстракции.
Каков смысл наследования для абстракций, отражающих сущности реляционной базы данных? Очень большой: построение иерархии наследования сопровождается вычленением общих признаков поведения и отображением их в структуре суперклассов. Эти суперклассы будут ответственны за реализацию общего поведения для всех объектов, за исключением тех подклассов, которые уточняют это поведение (через промежуточный суперкласс) или расширяют его (через суперкласс-примесь). Такой подход не только упрощает построение системы, но и повышает устойчивость к вносимым изменениям за счет сокращения избыточности и локализации общих структур и поведения.
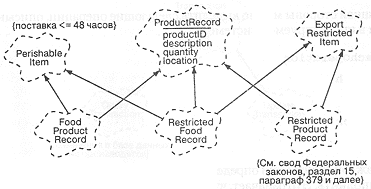
Рис. 10-7. Классы товаров.
Механизм транзакций
Архитектура клиент/сервер построена на взаимодействии клиентской и серверной частей приложения, для реализации которого необходим определенный механизм. Берсон указал, что "существует три базовых вида взаимодействия между процессами в архитектуре клиент/сервер" [20]:
• конвейеры (pipes)
• удаленный вызов процедур (RPC)
• взаимодействие клиент/сервер через SQL.
В нашем примере мы воспользовались только третьим способом. Но, в общем случае, могут использоваться все указанные виды взаимодействия в соответствии с требованиями производительности или в результате выбора программных средств конкретного поставщика. В любом случае наш выбор должен быть скрыт, чтобы не оказывать влияния на абстракции высокого уровня.
Мы ранее уже упомянули о классе транзакции, но не остановились подробно на его семантике. Берсон определяет транзакцию как "единицу обмена и обработки информации между локальной и удаленной программами, которая отражает логически законченную операцию или результат" [21]. Это и есть определение нужной нам абстракции: объект-транзакция является агентом, ответственным за выполнение некоторого удаленного действия, а, следовательно, отчетливо отделяет само действие от механизма его реализации.
Действительно, транзакция является основным высокоуровневым видом взаимодействия сервера и клиента, а также между клиентами. На основе этого понятия можно выполнять конкретный анализ вариантов использования. Принципиально все основные функции в системе складского учета могут рассматриваться как транзакции. Например, размещение нового заказа, подтверждение поступления товаров и изменения информации о поставщиках являются системными транзакциями.
С внешней стороны можно выделить следующие операции, описывающие суть поведения в проектируемой системе:
• attachOperation
• dispatch
• commit
• rollback
• status
Для каждой транзакции определяется полный перечень операций, которые она должна выполнить. Это означает, что для класса Transaction необходимо определить функции-члены, такие как attachOperation, которые предоставляют другим объектам возможность объединить набор SQL-операторов для исполнения в качестве единой транзакции.
Интересно отметить, что такое объектно-ориентированное видение транзакций полностью согласуется с принципами, принятыми в практике работы с базами данных. Дэйт определил, что "транзакция представляет собой последовательность операторов SQL (возможно, не только SQL), которые должны быть неразделимы в смысле произведения отката и управления параллельным доступом" [Date, C.[E 1987], c.32].
Концепция атомарности наиболее существенна в семантике транзакций. Если в некоторой транзакции операция выполняется над несколькими строками таблицы, то либо все действия должны быть выполнены, либо содержимое таблицы должно быть оставлено без изменении. Следовательно, когда мы посылаем транзакцию (dispatch), мы имеем в виду выполнение группы операций как единого целого.
При благополучном завершении транзакции мы должны зафиксировать ее результаты (commit). Невыполнение транзакции может произойти в силу ряда причин, в том числе из-за отказов сети или блокировки информации другими клиентами. В таких ситуациях выполняется откат в исходное состояние (rollback). Селектор status возвращает значение параметра, определяющего успешность транзакции.
Выполнение транзакции несколько усложняется при работе с распределенными базами данных. Как реализовать протокол завершения транзакций при работе с локальной базой достаточно понятно, а что необходимо сделать при работе с данными, размещенными на нескольких серверах? Для этого используется так называемый двухфазный протокол завершения транзакций [23]. В этом случае агент, то есть объект класса Transaction, разделяет транзакцию на несколько фрагментов и раздает их для выполнения различным серверам. Это называется фазой подготовки. Когда все серверы сообщили о том, что готовы к завершению, центральный агент транзакции передает им всем команду commit. Это называется фазой завершения. Только при правильном завершении всех разделенных компонент транзакции основная транзакция считается завершенной. Если хотя бы на одном сервере выполнение операций будет неполным, мы откатим всю транзакцию. Это возможно потому, что каждый экземпляр Transaction знает, как откатить свою транзакцию.
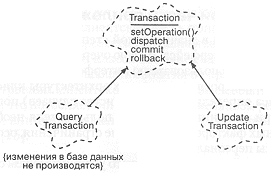
Рис. 10-8. Транзакции.
Изложенное выше представление о классе транзакций показано на рис. 10-8. Мы видим здесь иерархию транзакций. Класс Transaction является базовым для всех транзакций и содержит в себе все ключевые аспекты поведения. Производные специализированные классы вносят в общее поведение свои особенности. Мы различаем, например, классы UpdateTransaction и QueryTransaccion, потому что их семантика очень различна: первый из них модифицирует данные на сервере баз данных, а второй - нет. Различая эти и другие типы транзакций, мы собираем в базовом классе наиболее общие характеристики, и пополняем при этом наш словарь.
В процессе дальнейшего проектирования мы, возможно, обнаружим и другие разновидности транзакций, которые будут представлены собственными подклассами. Например, если мы убедимся, что операции добавления и удаления данных из конкретной базы имеют общую семантику, то введем операции AddTransaction и DeleteTransaction, чтобы отразить эту общность поведения.
Во всяком случае, существование базового класса Transaction позволяет выполнять нам любое атомарное действие. Например, на C++ он мог бы выглядеть так:
public:
Transaction(); virtual ~Transaction(); virtual void setOperation(const UnboundedCollection<SQLStatement>&); virtual int dispatch(); virtual void commit(); virtual void rollback(); virtual int status() const;
protected: ... };
Обратим внимание, что для построения этого класса мы использовали базовые классы, определенные нами в главе 9. В данном случае мы построили транзакцию в форме индексированной коллекции операторов. Для манипулирования этой коллекцией использован параметризованный класс UnboundedCollection.
Принятое архитектурное решение позволяет сложному пользовательскому приложению выполнять наборы SQL-операторов. Все детали реализации механизма управления транзакциями оказываются скрытыми для простых клиентов, которым достаточно выполнять некоторые общие типы транзакции.
Создание клиентской части приложения
Создание клиентской части в значительной степени сводится к построению графического прикладного интерфейса. В свою очередь, построение удобного интуитивного и дружественного пользователю интерфейса - скорее искусство, чем наука. В приложениях, построенных в рамках архитектуры клиент/сервер, именно качество интерфейса определяет (в большинстве случаев) популярность тех или иных программ. При создании интерфейса пользователя необходимо учитывать множество различных факторов: технические ограничения, особенности психологии, традиции, вкусы персонала.
При создании нашей системы складского учета мы можем столкнуться с двумя препятствиями. Во-первых, нужно выяснить, каким должен быть "правильный" интерфейс пользователя. Во-вторых, желательно определить, какие общепринятые подходы мы можем использовать при создании интерфейса.
Ответ на первый вопрос можно получить достаточно просто, но для этого нужно прототипировать, прототипировать и прототипировать. Нужно как можно раньше получить действующую модель системы, чтобы показать ее пользователям и получить от них квалифицированные замечания. Объектно-ориентированный подход существенно поможет нам в этом смысле, поскольку он основан на итерационном развитии проекта. На самых ранних стадиях проекта мы уже сможем показать пользователям прототип системы.
Второй вопрос находится в сфере стратегии проекта, но для его успешного разрешения у нас имеется множество хороших примеров. Существуют коммерческие продукты, например, Х Window System от MIT, Open Look, Windows от Microsoft, MacApp от Apple, NextStep от Next, Presentation Manager от IBM. Все эти продукты существенно различаются: некоторые основываются на сети, а некоторые опираются на концепцию ядра, некоторые позволяют действовать на уровне пикселей, а другие считают примитивами более сложные геометрические фигуры. В любом случае все они позволяют существенно упростить создание графического интерфейса пользователя. Ни один из перечисленных продуктов не родился за одну ночь. Все они постепенно развивались из самых простых систем, прошли путь проб и ошибок. В результате эти системы вобрали в себя набор абстракций, достаточный для построения пользовательского интерфейса. Поскольку нет однозначного ответа на вопрос о лучшем интерфейсе, то существуют несколько вариантов оконной модели.
В главе 9 мы уже упоминали о том, что при работе с большими библиотеками классов (каковыми являются и библиотеки графического интерфейса) важно понять механизмы их построения. Для нашей задачи основным механизмом является реакция GUI-приложений на события. Берсон указывал, что для клиентской части приложения существенны события, связанные со следующими объектами [24]:
• мышь
• клавиатура
• меню
• обновление окна
• изменения размера окна
• активизация/деактивация
• начало/завершение.
Мы добавим к этому перечню сетевые события [Например, механизмы DDE (Dynamic Data Exchange, динамический обмен данными) и OLE (Object Linking and Embedding, связь и внедрение объектов) от Microsoft представляют собой основанные на сообщениях протоколы, обеспечивающие обмен информацией между приложениями Windows]. Для нашей архитектуры они очень существенны, поскольку клиентская часть приложения связана с другими компонентами и приложениями через сеть. Описанная семантика хорошо согласуется с нашим подходом к построению класса Transaction, который может рассматриваться как посредник, пересылающий события от приложения к приложению. С точки зрения построения клиентской части, сетевые события являются разновидностью событий, что позволяет описать единый механизм реакции на события.
Берсон обратил внимание на наличие нескольких альтернативных моделей обработки событий [25]:
? Цикл обработки событий В цикле просматривается очередь событии и для каждого события вызывается соответствующая процедура обработки.
? Обратный вызов Приложение регистрирует функцию обратного вызова для каждого элемента GUI; обратный вызов происходит, когда элемент зарегистрирует событие.
? Гибридная модель Сочетание циклического опроса и функций обратного вызова.
Кроме первичного механизма, нам необходимо реализовать еще множество GUI-механизмов: рисование, прокрутка, работа с мытью, меню, сохранение и восстановление, печать, редактирование, обработка ошибок, распределение памяти. Безусловно, подробное рассмотрение всех этих вопросов находится вне рамок нашего анализа, поскольку каждая конкретная GUI-среда имеет свои собственные реализации этих механизмов.
Мы предлагаем разработчику клиентской части приложения выбрать подходящую GUI-среду разработки, изучить ее основные механизмы и правильно их применить.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
8.2. Проектирование
8.2. Проектирование Архитектурный каркас Каждая программная система должна иметь простую и в то же время всеобъемлющую организационную философию. Система мониторинга погоды не является в этом смысле исключением. На следующем этапе нашей работы мы должны четко
9.2. Проектирование
9.2. Проектирование Тактические вопросы В соответствии с законом разработки программ Коггинса "прагматизм всегда должен быть предпочтительней элегантности, ведь Природу все равно ничем не удивить". Следствие: проектирование никогда не будет полностью независимым от
10.2. Проектирование
10.2. Проектирование Формулируя подходы к архитектуре системы складского учета, мы должны помнить о трех моментах организационного характера: разделение функций между клиентской и серверной частью, механизм управления транзакциями, стратегия реализации клиентской
11.2. Проектирование
11.2. Проектирование Архитектура информационной доски Теперь у нас есть все, чтобы приступить к решению поставленной задачи с использованием метафоры информационной доски. Это классический пример повторного использования "в большом": мы повторно применяем испытанный
12.2. Проектирование
12.2. Проектирование Как уже отмечалось в главе 6, создание архитектуры подразумевает выявление основной структуры классов и спецификацию общих взаимодействий, которые оживляют классы. Сконцентрировав внимание прежде всего на этих механизмах, мы с самого начала выявляем
Проектирование дверей
Проектирование дверей Для создания дверей нужно нажать кнопку палитры инструментов Door (Дверь) – на информационной палитре появятся элементы управления настройкой параметров двери (рис. 6.4). Рис. 6.4. Элементы управления настройкой параметров
Проектирование окон
Проектирование окон Для создания окон предназначена кнопка Window (Окно) расположенная в разделе Design (Проектирование) палитры инструментов. Использование данной кнопки отображает на информационной палитре элементы управления настройками параметров окон (рис. 6.8). Рис. 6.8.
Проектирование балок
Проектирование балок Следующий инструмент проектирования строительных конструкций – балки. Для активизации этого инструмента щелкните на кнопке Beam (Балка) раздела Design (Проектирование) палитры ToolBox (Палитра инструментов). Основные параметры балок отобразятся на
Интерфейсы и проектирование ПО
Интерфейсы и проектирование ПО Архитектура системы должна основываться на содержании, а не на форме. Но проектирование сверху вниз стремится использовать в качестве основы для структуры самый поверхностный аспект системы - ее внешний интерфейс. Такой упор на внешний
У8.3 Проектирование нотации
У8.3 Проектирование нотации Предположим, вы часто используете сравнение в форме x.is_equal (y), и хотите упростить нотацию, используя преимущества инфиксной записи (применимой здесь, поскольку наша функция имеет один аргумент). Для инфиксного компонента используйте некоторый
12.9. ТЕХНИЧЕСКОЕ ПРОЕКТИРОВАНИЕ
12.9. ТЕХНИЧЕСКОЕ ПРОЕКТИРОВАНИЕ Техническое проектирование — это мост между функциональной спецификацией и фактической стадией кодирования. Часто команда разработчиков пытается сократить и объединить стадию разработки функциональной спецификации и техническое
Проектирование
Проектирование Ключевым аспектом развертывания PKI является выбор архитектуры и проектирование. PKI допускает гибкость проектирования независимо от выбранной технологии. Этап проектирования занимает длительное время, так как на этом этапе должна быть сформирована