11.2. Проектирование
11.2. Проектирование
Архитектура информационной доски
Теперь у нас есть все, чтобы приступить к решению поставленной задачи с использованием метафоры информационной доски. Это классический пример повторного использования "в большом": мы повторно применяем испытанный архитектурный шаблон как основу проекта. Метод информационной доски предполагает следующие объекты верхнего уровня: информационная доска, несколько источников знаний и контроллер. Остается только определить классы и объекты предметной области, которые специализируют эти общие абстракции.
Объекты информационной доски. Объекты на доске образуют иерархию, отражающую иерархичность различных уровней абстракции источников знаний. Таким образом, у нас есть три следующих класса:
• Sentence - Полная криптограмма.
• Word - Отдельное слово в криптограмме.
• CipherLetter - Отдельная буква в слове.
Источники знаний должны пользоваться общей информацией о сделанных в процессе решения предположениях, поэтому в число объектов информационной доски включается следующий класс:
• Assumption - Предположение, сделанное источником знаний.
Наконец, источники знания делают предположения о связи между буквами реального и шифровального алфавитов, так что мы вводим следующий класс:
• Alphabet - Алфавит исходного текста, алфавит криптограммы и соответствие между ними.
Есть ли между этими пятью классами что-либо общее? Ответ однозначно утвердительный: все они соответствуют объектам информационной доски и этим существенно отличаются от других объектов, например, источников знаний и контроллера. Поэтому вводится следующий суперкласс для всех ранее перечисленных объектов:
class BlackboardObject ...
С точки зрения внешнего поведения определим для этого класса две операции:
• register - Добавить объект на доску.
• resign -Удалить объект с доски.
Почему мы определили эти две операции над объектами класса BlackboardObject, а не над самой доской? Это похоже на ситуацию, когда объект должен сам нарисовать себя в некотором окне. "Лакмусовый" тест в таких случаях, это вопрос: "Имеет ли сам объект достаточно знаний и умений, чтобы выполнять такие операции?". Объекты информационной доски как раз лучше всех понимают, как им правильно появляться на доске или удаляться с нее (конечно, они нуждаются при этом в помощи самой доски). Мы уже установили ранее, что объекты, взаимодействующие с доской, по своей сути должны самостоятельно включаться в процесс решения задачи.
Зависимости и подтверждения. Предложения, слова и буквы также связаны определенной общностью: для всех них есть соответствующие источники знаний. Конкретный источник знаний, со своей стороны, может проявлять интерес к одному или нескольким таким объектам (зависеть от них) и поэтому фраза, слово и символ шифра должны поддерживать связь с источником знаний, чтобы при появлении предположения относительно объекта уведомлялись соответствующие источники знаний. Это напоминает механизм зависимостей языка Smalltalk, упомянутый в главе 4. Для реализации этого механизма введем следующий класс-примесь:
class Dependent { public:
Dependent(); Dependent(const Dependent&); virtual ~Dependent();
... protected
UnboundedCollection<KnowledgeSource*> references;
};
Мы забежали несколько вперед и намекнули на возможную реализацию класса, чтобы показать связь с библиотекой фундаментальных классов, описанной в главе 9. В классе определен один внутренний элемент - коллекция указателей на источники знаний [В главе 9 мы отмечали, что неограниченные структуры требуют менеджера памяти. Для простоты мы опускаем этот аргумент шаблона всюду в данной главе. Конечно, полная реализация должна быть согласована с механизмами среды разработки].
Определим для этого класса следующие операции:
• add - Добавить ссылку на источник знаний.
• remove - Удалить ссылку на источник знаний.
• numberOfDependents - Возвратить число зависящих объектов.
• notify - Известить каждого зависимого.
Последняя операция является пассивным итератором: при ее вызове передается как параметр действие, которое надо выполнить над всеми зависящими объектами в коллекции.
Зависимость может примешиваться к другим классам. Например, буква шифра - это объект информационной доски, от которого зависят другие, так что мы можем скомбинировать две этих абстракции для получения нужного поведения. Такое применение примесей поощряет повторное использование и разделение понятий в нашей архитектуре.
Символы шифра и алфавиты имеют еще одно общее свойство: относительно объектов этих классов могут делаться предположения. Вспомните, что предположение (Assumption) является одним из объектов на доске (BlackboardObject). Так, некоторый источник знаний может допустить, что буква K в шифре соответствует букве P исходного текста. По мере решения задачи может абсолютно точно выясниться, что G означает J. Поэтому введен еще один класс:
class Affirmation ...
Этот класс отвечает за высказывания (предположения или утверждения) относительно связанного с ним объекта. Мы используем этот класс не как примесь, а для агрегации. Буква, например, не является предположением, но может иметь предположение о себе.
В нашей системе предположения допускаются только в отношении отдельных букв и алфавитов. Можно, например, предположить, что какая-либо буква шифра соответствует некоторой букве алфавита. Алфавит состоит из набора букв, относительно которых делаются предположения. Определяя Affirmation как независимый класс, мы выражаем в нем сходное поведение этих двух классов, несвязанных наследованием.
Определим следующий набор операций для экземпляров этого класса:
• make - Сделать высказывание.
• retract - Отменить высказывание.
• chiphertext - Вернуть шифрованный эквивалент для заданной буквы исходного текста.
• plaintext - Вернуть исходный текстовый эквивалент для заданной буквы шифра.
Из предыдущего обсуждения видно, что надо ясно различать две роли высказываний: временные предположения о соответствиях между буквами шифра и текста и окончательно доказанные соответствия - утверждена. По мере расшифровки криптограммы может делаться множество различных предположений о соответствии букв шифра и текста, но в конце концов находятся окончательные соответствия для всего алфавита. Чтобы отразить эти роли, уточним ранее выявленный класс Assumption в подклассе Assertion (утверждение). Экземпляры обоих классов управляются объектами класса Affirmation и могут помещаться на доску. Для поддержки введенных ранее операций make и retract нам необходимо определить следующие селекторы:
• isPlainLetterAsserted - определена ли эта буква текста достоверно?
• isCipherLetterAsserted - определена ли эта буква шифра достоверно?
• plainLetterHasAssumptlon - есть ли предположение об этой букве текста?
• cipherLetterHasAssumption - есть ли предположение об этой букве шифра?
Теперь мы можем определить класс Assumption. Поскольку данная абстракция носит исключительно структурный характер, ее состояние можно сделать открытым:
class Assumption : public BlackboardObject { public: ...
BlackboardObject* target; KnowledgeSource* creator; String<char> reason; char plainLetter; char cipherLetter;
};
Отметим, что мы повторно использовали еще один класс среды, описанной в главе 9, а именно, параметризуемый класс String.
Класс Assumption является объектом информационной доски, поскольку информация о сделанных предположениях используется всеми источниками знаний. Отдельные члены класса выражают следующие его свойства:
• target - Объект доски, о котором делается предположение.
• creator - Источник знаний, который сделал предположение.
• reason - Основание для сделанного предположения.
• cipherLetter - Предполагаемое значение буквы исходного текста.
Необходимость каждого из перечисленных свойств в значительной степени объясняется природой предположений: источник знании формирует предполагаемое соответствие "буква исходного текста - буква шифра" на основании каких-то причин (обычно, некоторого правила). Назначение первого свойства target менее очевидно. Оно нужно для отката. Если сделанное предположение не подтвердится, то нужно восстановить состояние объектов на доске, которые воспользовались предположением, а они должны известить источники знаний, что их смысл изменился.
Далее определим подкласс Assertion:
class Assertion : public Assumption ...
Общим для классов Assumption и Assertion является следующий селектор:
• isRetractable - Является ли соответствие потенциально неверным?
Для всех высказанных предположений значение предиката isRetractable является истинным, а для утверждений - ложным. Сделанное утверждение уже нельзя ни изменить ни отвергнуть.
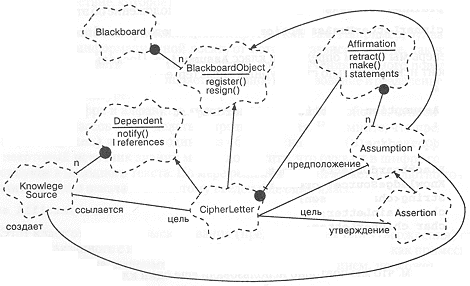
Рис. 11-2. Классы зависимостей и высказываний.
На рис. 11-2 приведена диаграмма, поясняющая связь классов зависимостей и высказываний. Обратите особое внимание на роли, которые играют упомянутые абстракции в различных ассоциациях. Например, класс KnowledgeSource в одном аспекте является создателем (creator) предположения, а в другом - ссылается (referencer) на букву шифра. Из различия ролей естественным образом вытекают различия протоколов взаимодействия.
Проектирование объектов информационной доски. Завершим проектирование, добавив кроме класса алфавита классы для предложения (Sentence), слова (Word) и буквы шифра (cipherLetter). Предложение представляет собой просто объект доски (от которого зависят другие объекты), содержащий список слов, Исходя из этого, запишем:
class Sentence : public BlackboardObject, virtual public Dependent { public: ... protected:
List<Word*> words;
};
Суперкласс Dependent определен виртуальным, поскольку мы ожидаем, что будут подклассы от sentence, которые захотят наследовать также и от Dependent. При этом для всех таких подклассов члены класса Dependent будут общими.
В дополнение к операциям register и resign (определенным в суперклассе BlackboardObject) и четырем операциям, унаследованным от класса Dependent, мы добавляем еще две специфические операции для предложения:
• value - Текущее значение предложения.
• isSolved - Истинно, если о всех словах в предложении сделаны утверждения.
Первоначальное значение value совпадает с текстом криптограммы. Когда isSolved станет истиной, value вернет исходный расшифрованный текст.
Слово является объектом доски и источником зависимости. Оно состоит из букв. Для удобства источников знаний в класс слова введены указатели на все предложение, а также на предыдущее и следующее слова в предложении. Описание класса Word выглядит так:
class Word : public BlackboardObject, virtual public Dependent { public: ...
Sentence& sentence() const; Word* previous() const; Word* next() const;
protected:
List<CipherLetter*> letters;
};
Так же как для предложения, в класс слова введены две дополнительные операции:
• value - Текущее значение слова.
• isSolved - Истинно, если о всех буквах слова сделаны утверждения.
Теперь можно определить класс cipherLetter (буква шифра). Буквы шифра являются объектами информационной доски и порождают зависимости. Кроме того, они имеют значение (буква, как она записывается в шифровке, например, н) и коллекцию возможных предположений и утверждений о соотнесении ее с буквами исходного текста. Для организации коллекции мы используем класс Affirmation. Опишем класс буквы следующим образом:
class CipherLetter : public BlackboardObject, virtual public Dependent { public: ...
char value() const; int isSolved() const;
... protected:
char letter; Affirmation affirmations;
};
Отметим, что и в этот класс добавлена та же пара селекторов по аналогии с классами слова и предложения. Для клиентов этого объекта нужно предусмотреть защищенные операции доступа к предположениям и утверждениям.
Объект affirmations, включенный в этот класс, содержит коллекцию предположений и утверждений в порядке их выдвижения. Последний элемент коллекции содержит текущее предположение или утверждение. Смысл хранения последовательности решения задачи состоит в возможности обучения источников знании на собственных ошибках. Поэтому в класс Affirmation введены два дополнительных селектора:
• mostRecent - возвращает последнее предположение или утверждение;
• statementAt - возвращает n-ое высказывание (предположение или утверждение).
Уточнив поведение класса, мы можем принять правильные решения о его реализации. В частности, нам потребуется ввести в класс следующий защищенный объект:
UnboundedOrderedCollection<Assumption*> statements;
Этот объект также позаимствован нами из библиотеки фундаментальных классов главы 9.
Теперь обратимся к классу Alphabet (алфавит). Он содержит данные об алфавитах исходного текста и шифра, а также о соответствии между ними. Эта информация необходима для того, чтобы источники знаний могли узнать о выявленных соответствиях между буквами шифра и текста и тех, которые еще предстоит найти. Например, если уже доказано, что буква с а шифре соответствует букве и исходного текста, то это соответствие фиксируется в алфавите и источники знаний уже не будут делать других предположений в отношении буквы м исходного текста. Для эффективности обработки полезно получать данные о соответствии букв шифра и текста двумя способами: по букве шифра и по букве исходного текста. Определим класс Alphabet следующим образом:
class Alphabet : public BlackboardObject { public:
char plaintext(char) const; char ciphertext(char) const; int isBound(char) const;
};
Так же, как и в класс CipherLetter, в класс Alphabet необходимо включить защищенный объект affirmations и определить операции доступа к его состоянию.
Наконец, определим класс Blackboard, который является коллекцией экземпляров класса Blackboardobject и его подклассов:
class Blackboard : public DynamicCollection<BlackboardObject*> ...
Поскольку доска есть разновидность коллекции (тест на наследование), мы предпочитаем образовать этот класс методом наследования, а не с помощью включения экземпляра класса DynamicCollectlon. Операции включения в коллекцию и исключения из нее наследуются от класса Collection, а следующие пять операций, специфичных для информационной доски, вводятся нами:
• reset - Очистить доску.
• assertProblem - Поместить на доске начальные условия задачи.
• connect - Подключить к доске источник знании.
• issolved - Истинно, если предложение расшифровано.
• retriaveSolution - Значение расшифрованного текста.
Вторая операция устанавливает зависимость между доской и источником знании. На рис. 11-3 приведена итоговая диаграмма классов, связанных с Blackboard. Она в первую очередь отражает отношения наследования. Отношения использования (например, между Assumption и информационной доской) для простоты опушены.
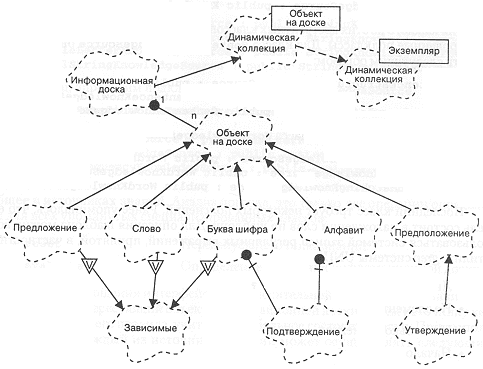
Рис. 11-3. Диаграмма классов информационной доски.
Обратите внимание на то, что класс Blackboard одновременно и инстанцирует от шаблона DynamicCollection, и наследует от него. Кроме того, становится понятным использование класса Dependent в качестве примеси. Не привязывая этот класс жестко к иерархии Blackboard, мы повышаем шансы на его последующее повторное использование.
Проектирование источников знаний
В предыдущем разделе мы выделили тринадцать источников знаний, относящихся к решаемой задаче. Теперь можно приступить к проектированию структур классов для них (как это было сделано для информационной доски) и обобщению их в более абстрактные классы.
Проектирование специализированных источников знаний. Предположим, что существует абстрактный класс KnowledgeSource (по аналогии с классом BlackboardObject). Прежде чем определять все тринадцать источников в качестве подклассов одного общего суперкласса, нужно посмотреть, не группируются ли они каким-нибудь образом. Действительно, такие группы находятся: некоторые источники знаний оперируют целым предложением, другие - словами, фрагментами слов или отдельными буквами. Отразим этот факт в следующих определениях:
class SentenceKnowledgeSource : public KnowledgeSource ... class WordKnowledgeSource : public KnowledgeSource ... class LetterKnowledgeSource : public KnowledgeSource ...
Для каждого из этих абстрактных классов в дальнейшем мы определим специализированные подклассы. Для класса SentenceKnowledgeSource они будут выглядеть следующим образом:
class SentenceStructureKnowledgeSource : public SentenceKnowledgeSource ... class SolvedKnowledgeSource : public SentenceKnowledgeSource ...
Аналогично, подклассы класса WordKnowledgeSource определяются так:
class WordStructureKnowledgeSource : public WordKnowledgeSource ... class SmallWordKnowledgeSource : public WordKnowledgeSource ... class PatternMatchingKnowledgeSource : public WordKnowledgeSource ...
Последний класс требует некоторых пояснений. Ранее упоминалось, что его цель состоит в нахождении слов по шаблону. Для описания шаблона можно воспользоваться системой записи регулярных выражении, принятой, в частности, в утилите grep системы UNIX:
• Любой элемент - ?
• Не элемент - ~
• Несколько элементов - *
• Начало группы - {
• Конец группы - }
Используя такие обозначения, мы можем передать объекту этого класса шаблон ?E~{A E I O U}, чтобы он искал в своем словаре слово из трех букв, начинающееся с некоторой буквы, после которой идет E, а затем - любая буква кроме гласной.
Поскольку проверка по шаблону является методом, полезным как для данной системы в целом, так и в других областях, соответствующий класс целесообразно выделить в качестве самостоятельной абстракции. Поэтому неудивительно, что мы воспользуемся классом из нашей библиотеки (см. главу 9). В результате наш класс для проверки по шаблону будет выглядеть следующим образом:
class PatternMatchingKnowledgeSource : public WordKnowledgeSource { public: ... protected:
static BoundedCollection<Word*> words; REPatternMatching patternMatcher;
};
Все экземпляры этого класса разделяют общий словарь, но каждый из них может иметь собственного агента для сравнения с шаблонами.
На данном этапе проектирования подробности реализации этого класса для нас не существенны, поэтому мы не будем на них подробно останавливаться.
Определим теперь подклассы класса StringKnowledgeSource следующим образом:
class CommonPrefixKnowledgeSource : public StringKnowledgeSource ... class CommonSuffixKnowledgeSource : public StringKnowledgeSource ... class DoubleLetterKnowledgeSource : public StringKnowledgeSource ... class LegalStringKnowledgeSource : public StringKnowledgeSource ...
Наконец, определим подклассы класса LetterKnowledgeSource:
class DirectSubstitutionKnowledgeSource : public LetterKnowledgeSource ... class VowelKnowledgeSource : public LetterKnowledgeSource ... class ConsonantKnowledgeSource : public LetterKnowledgeSource ... class LetterFrequencyKnowledgeSource : public LetterKnowledgeSource ...
Общее в источниках знаний. Анализ показал, что только две операции определены для всех упомянутых специализированных классов:
• Reset - Перезапуск источника знаний.
• evaluate - Определение состояния информационной доски.
Причина упрощения интерфейса - в относительной автономности знаний: мы указываем на интересующий объект информационной доски и даем источнику команду применить его правила, учитывая глобальное состояние доски. При выполнении правил каждый из источников знаний может осуществлять следующие действия:
• Высказать предположение о подстановке.
• Найти противоречие в ранее предложенных подстановках и откатить их.
• Высказать утверждение о подстановке.
• Сообщить контроллеру о своем желании записать на доску что-то интересное.
Все эти действия являются общими для всех источников знаний. Перечисленные операции образуют механизм вывода заключений. Определим механизм вывода (InferenceEngine) как объект, который выполняет известные правила для того, чтобы либо найти новые правила (прямая последовательность рассуждений), либо доказать некоторую гипотезу (обратная последовательность рассуждений). На основании сказанного введем следующий класс:
class InferenceEngine { public:
InferenceEngine(<DynamicSet<Rules*>);
... };
Конструктор класса создает экземпляр объекта и населяет его правилами. Лишь одна операция сделана в этом классе видимой для источников знании:
• evaluate - Выполнить правило механизма вывода.
Теперь о том, как сотрудничают источники знаний: каждый специализированный источник определяет свои собственные правила и возлагает ответственность за их выполнение на класс InferenceEngine. Точнее, операция KnowledgeSource::evaluate вызывает метод InferenceEngine::evaluate, что приводит к выполнению одной из четырех упомянутых выше операций. На рис. 11-4 показан сценарий такого взаимодействия:
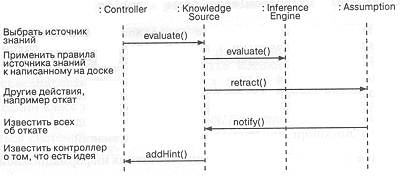
Рис. 11-4. Взаимодействия с источником знаний.
Что такое правило? Для иллюстрации приведем (в формате Lisp) правило, касающееся знаний об общеупотребительных суффиксах:
((* I ? ?) (* I N G) (* I E S) (* I E D))
Это правило означает, что заданному шаблону *I?? (условие - antecedent) могут соответствовать суффиксы ING, IES и IED (заключение - consequent). В C++ можно определить следующий класс для представления правил:
class Rule { public: ...
int bind(String<char>& antecedent, String<char>& consequent); int remove(Strlng<char>& antecedent); int remove(String<char>t antecedent, String<char>& conseiruent); int hasConflict(const String<char>& antecedent) const;
protected:
String<char> antecedent; List<String<char>> consequents;
};
Смысл приведенных операций полностью понятен из их наименований. Мы здесь повторно использовали некоторые классы из главы 9.
С точки зрения строения данного класса можно утверждать, что источники знаний являются разновидностью механизма вывода. Кроме того, они ассоциированы с объектами доски, поскольку находят там приложение своим усилиям. Наконец, каждый источник знаний связан с контроллером и посылает ему свои соображения. Контроллер, в свою очередь, может активизировать источники знаний.
Выразим все сказанное следующим образом:
class KnowledgeSource : public InferenceEngine, public Dependent { public:
KnowledgeSource(Blackboard*, Controller*); void reset(); void evaluate();
protected:
Blackboard* blackboard; Controller* controller; UnboundedOrderedCollection<Assumption*> pastAssumptions;
};
В этот класс введен защищенный элемент данных pastAssumptions, позволяющий сохранять всю историю предположений в целях самообучения.
Экземпляры класса Blackboard служат для хранения объектов информационной доски. По схожим соображениям, необходим также класс KnowledgeSources, охватывающий все источники знаний, относящиеся к решаемой задаче:
class KnowledgeSources : public DynamicCollection<KnowledgeSource*> ...
Одно из свойств этого класса состоит в том, что при создании его экземпляра создаются также 13 специализированных источников знаний. Для объектов этого класса определяются три операции:
• restart - Перезапустить источник знаний.
• StartKnowledgeSource - Задать начальные условия для источника знаний.
• connect - Связать источник знаний с доской или контроллером.
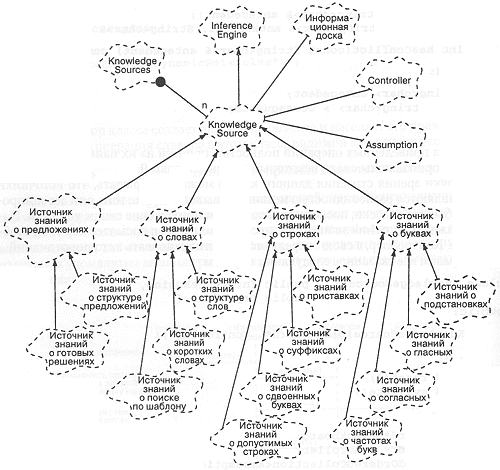
Рис. 11-5. Диаграмма классов источников знаний.
На рис. 11-5 показана структура созданных в процессе проектирования классов источников знаний.
Проектирование контроллера
Рассмотрим более подробно взаимодействие контроллера с отдельными источниками знаний. В процессе поэтапной расшифровки криптограммы отдельные источники знаний выявляют полезную информацию и сообщают ее контроллеру. С другой стороны, может быть обнаружено, что ранее переданная информация оказалась ложной и ее надо устранить. Поскольку все источники знаний имеют равные права, контроллер должен опросить их все, выбрать тот, информация которого кажется наиболее полезной, и разрешить ему внести изменения вызовом его операции evaluate.
Каким образом контроллер определяет, какой из источников знаний следует активизировать? Можно предложить несколько разумных правил:
• Утверждение более приоритетно чем предположение.
• Если кто-то говорит, что решил всю фразу, надо дать ему возможность высказаться.
• Проверка по шаблону более приоритетна, чем источник, анализирующий структуру предложения.
Контроллер действует в качестве агента, ответственного за взаимодействие источников знаний.
Контроллер должен быть в ассоциативной связи с источниками знаний через класс KnowledgeSources. Кроме того, он должен иметь в качестве одного из своих свойств коллекцию высказываний, упорядоченных по приоритету. Тем самым контроллер легко может выбрать для активизации источник знаний с наиболее интересным высказыванием.
После изолированного анализа класса мы предлагаем ввести для класса controller следующие операции:
• reset - Перезапуск контроллера.
• addHint - Добавить высказывание от источника знаний.
• removeHint - Удалить высказывание от источника знаний.
• processNextHint - Разрешить выполнение следующего по приоритету высказывания.
• isSolved - Селектор. Истина, если задача решена.
• UnableToProceed - Селектор. Истина, если источники знаний застряли.
• connect - Устанавливает связь с источником знаний.
Все эти решения можно описать следующим образом:
class Controller { public: ...
void reset(); void connect(Knowledgesource&); void addHint(KnowledgeSource&); void removeHint(KnowledgeSource&); void processNextHint(); int isSolved() const; int unableToProceed() const;
};
Контроллер в некотором смысле управляется источниками знаний, поэтому для описания его поведения наилучшим образом подходит схема конечного автомата.
Рассмотрим диаграмму состояний и переходов на рис. 11-6. Из нее видно, что контроллер может находиться в одном из пяти основных состояний: инициализация (Initializing), выбор (Selecting), вычисление (Evaluating), тупик (Stuck) и решение (Solved). Наибольший интерес для нас представляет поведение контроллера при переходе от выбора к вычислению. В состоянии selecting контроллер переходит от создания стратегии (CreatingStrategy) к вычислению высказывания (ProcessingHint) и, в конце концов, выбирает источник знаний (SelectingKS).
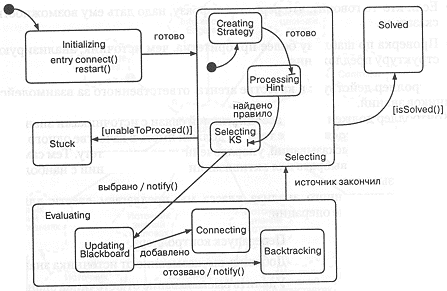
Рис. 11-6. Контроллер как конечный автомат.
Дав одному из источников возможность высказаться, контроллер переходит в состояние Evaluating, где прежде всего изменяет состояние информационной доски. Это вызывает переход в состояние Connecting при добавлении источника знании или к Backtracking, если предположение не оправдалось и надо откатить его, оповестив при этом все зависимые источники знаний.
Конечной точкой работы нашего механизма является solved (задача решена) или stuck (тупиковая ситуация).
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
8.2. Проектирование
8.2. Проектирование Архитектурный каркас Каждая программная система должна иметь простую и в то же время всеобъемлющую организационную философию. Система мониторинга погоды не является в этом смысле исключением. На следующем этапе нашей работы мы должны четко
9.2. Проектирование
9.2. Проектирование Тактические вопросы В соответствии с законом разработки программ Коггинса "прагматизм всегда должен быть предпочтительней элегантности, ведь Природу все равно ничем не удивить". Следствие: проектирование никогда не будет полностью независимым от
10.2. Проектирование
10.2. Проектирование Формулируя подходы к архитектуре системы складского учета, мы должны помнить о трех моментах организационного характера: разделение функций между клиентской и серверной частью, механизм управления транзакциями, стратегия реализации клиентской
11.2. Проектирование
11.2. Проектирование Архитектура информационной доски Теперь у нас есть все, чтобы приступить к решению поставленной задачи с использованием метафоры информационной доски. Это классический пример повторного использования "в большом": мы повторно применяем испытанный
12.2. Проектирование
12.2. Проектирование Как уже отмечалось в главе 6, создание архитектуры подразумевает выявление основной структуры классов и спецификацию общих взаимодействий, которые оживляют классы. Сконцентрировав внимание прежде всего на этих механизмах, мы с самого начала выявляем
Проектирование дверей
Проектирование дверей Для создания дверей нужно нажать кнопку палитры инструментов Door (Дверь) – на информационной палитре появятся элементы управления настройкой параметров двери (рис. 6.4). Рис. 6.4. Элементы управления настройкой параметров
Проектирование окон
Проектирование окон Для создания окон предназначена кнопка Window (Окно) расположенная в разделе Design (Проектирование) палитры инструментов. Использование данной кнопки отображает на информационной палитре элементы управления настройками параметров окон (рис. 6.8). Рис. 6.8.
Проектирование балок
Проектирование балок Следующий инструмент проектирования строительных конструкций – балки. Для активизации этого инструмента щелкните на кнопке Beam (Балка) раздела Design (Проектирование) палитры ToolBox (Палитра инструментов). Основные параметры балок отобразятся на
Интерфейсы и проектирование ПО
Интерфейсы и проектирование ПО Архитектура системы должна основываться на содержании, а не на форме. Но проектирование сверху вниз стремится использовать в качестве основы для структуры самый поверхностный аспект системы - ее внешний интерфейс. Такой упор на внешний
У8.3 Проектирование нотации
У8.3 Проектирование нотации Предположим, вы часто используете сравнение в форме x.is_equal (y), и хотите упростить нотацию, используя преимущества инфиксной записи (применимой здесь, поскольку наша функция имеет один аргумент). Для инфиксного компонента используйте некоторый
12.9. ТЕХНИЧЕСКОЕ ПРОЕКТИРОВАНИЕ
12.9. ТЕХНИЧЕСКОЕ ПРОЕКТИРОВАНИЕ Техническое проектирование — это мост между функциональной спецификацией и фактической стадией кодирования. Часто команда разработчиков пытается сократить и объединить стадию разработки функциональной спецификации и техническое
Проектирование
Проектирование Ключевым аспектом развертывания PKI является выбор архитектуры и проектирование. PKI допускает гибкость проектирования независимо от выбранной технологии. Этап проектирования занимает длительное время, так как на этом этапе должна быть сформирована