6.2.3. Потокобезопасная очередь с мелкогранулярными блокировками и условными переменными
В листингах 6.2 и 6.3 имеется только один защищаемый элемент данных (data_queue) и, следовательно, только один мьютекс. Чтобы воспользоваться мелкогранулярными блокировками, мы должны заглянуть внутрь очереди и связать мьютекс с каждым хранящимся в ней элементом данных.
Проще всего реализовать очередь в виде односвязного списка, как показано на рис. 6.1. Указатель head направлен на первый элемент списка, и каждый элемент указывает на следующий. Когда данные извлекаются из очереди, в head записывается указатель на следующий элемент, после чего возвращается элемент, который до этого был в начале.
Добавление данных производится с другого конца. Для этого нам необходим указатель tail, направленный на последний элемент списка. Чтобы добавить узел, мы записываем в поле next в последнем элементе указатель на новый узел, после чего изменяем указатель tail, так чтобы он адресовал новый элемент. Если список пуст, то оба указателя head и tail равны NULL.
В следующем листинге показана простая реализация такой очереди с урезанным по сравнению с листингом 6.2 интерфейсом; мы оставили только функцию try_pop() и убрали функцию wait_and_pop(), потому что эта очередь поддерживает только однопоточную работу.
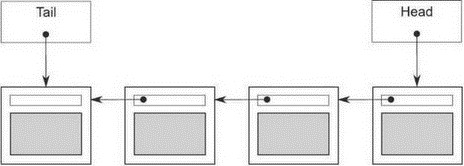
Рис. 6.1. Очередь, представленная в виде односвязного списка
Листинг 6.4. Простая реализация однопоточной очереди
template<typename T>
class queue {
private:
struct node {
T data;
std::unique_ptr<node> next;
node(T data_):
data(std::move(data_)) {}
};
std::unique_ptr<node> head;← (1)
node* tail; ← (2)
public:
queue() {}
queue(const queue& other) = delete;
queue& operator=(const queue& other) = delete;
std::shared_ptr<T> try_pop() {
if (!head) {
return std::shared_ptr<T>();
}
std::shared_ptr<T> const res(
std::make_shared<T>(std::move(head->data)));
std::unique_ptr<node> const old_head = std::move(head);
head = std::move(old_head->next);← (3)
return res;
}
void push(T new_value) {
std::unique_ptr<node> p(new node(std::move(new_value)));
node* const new_tail = p.get();
if (tail) {
tail->next = std::move(p);← (4)
} else {
head = std::move(p); ← (5)
}
tail = new_tail; ← (6)
}
};
Прежде всего отметим, что в листинге 6.4 для управления узлами используется класс std::unique_ptr<node>, потому что он гарантирует удаление потерявших актуальность узлов (и содержащихся в них данных) без явного использования delete. За передачу владения отвечает head, тогда как tail является простым указателем на последний узел.
В однопоточном контексте эта реализация прекрасно работает, но при попытке ввести мелкогранулярные блокировки в многопоточном контексте возникают две проблемы. Учитывая наличие двух элементов данных (head (1) и tail (2)), мы в принципе могли бы использовать два мьютекса — для защиты head и tail соответственно. Но не всё так просто.
Самая очевидная проблема заключается в том, что push() может изменять как head (5), так и tail (6), поэтому придётся захватывать оба мьютекса. Это не очень хорошо, но не трагедия, потому что захватить два мьютекса, конечно, можно. Настоящая проблема возникает из-за того, что и push(), и pop() обращаются к указателю next в узле: push() обновляет tail->next (4), a try_pop() читает head->next (3). Если в очереди всего один элемент, то head==tail, и, значит, head->next и tail->next — один и тот же объект, который, следовательно, нуждается в защите. Поскольку нельзя сказать, один это объект или нет, не прочитав и head, и tail, нам приходится захватывать один и тот же мьютекс в push() и в try_pop(), и получается, что мы ничего не выиграли по сравнению с предыдущей реализацией. Есть ли выход из этого тупика?
Обеспечение параллелизма за счет отделения данных
Решить проблему можно, заранее выделив фиктивный узел, не содержащий данных, и тем самым гарантировать, что в очереди всегда есть хотя бы один узел, отделяющий голову от хвоста. В случае пустой очереди head и tail теперь указывают на фиктивный узел, а не равны NULL. Это хорошо, потому что try_pop() не обращается к head->next, если очередь пуста. После добавления в очередь узла (в результате чего в ней находится один реальный узел) head и tail указывают на разные узлы, так что гонки за head->next и tail->next не возникает. Недостаток этого решения в том, что нам пришлось добавить лишний уровень косвенности для хранения указателя на данные, чтобы поддержать фиктивный узел. В следующем листинге показано, как теперь выглядит реализация.
Листинг 6.5. Простая очередь с фиктивным узлом
template<typename T>
class queue {
private:
struct node {
std::shared_ptr<T> data;← (1)
std::unique_ptr<node> next;
};
std::unique_ptr<node> head;
node* tail;
public:
queue():
head(new node), tail(head.get())← (2)
{}
queue(const queue& other) = delete;
queue& operator=(const queue& other) = delete;
std::shared_ptr<T> try_pop() {
if (head.get() ==tail) ← (3)
{
return std::shared_ptr<T>();
}
std::shared_ptr<T> const res(head->data);← (4)
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next); ← (5)
return res; ← (6)
}
void push(T new_value) {
std::shared_ptr<T> new_data(
std::make_shared<T>(std::move(new_value)));← (7)
std::unique_ptr<node> p(new node); ← (8)
tail->data = new_data; ← (9)
node* const new_tail = p.get();
tail->next = std::move(p);
tail = new_tail;
}
};
Изменения в try_pop() минимальны. Во-первых, мы сравниваем head с tail (3), а не с NULL, потому что благодаря наличию фиктивного узла head никогда не может обратиться в NULL. Поскольку head имеет тип std::unique_ptr<node>, для сравнения необходимо вызывать head.get(). Во-вторых, так как в node теперь хранится указатель на данные (1), то можно извлекать указатель непосредственно (4) без конструирования нового экземпляра T. Наиболее серьезные изменения претерпела функция push(): мы должны сначала создать новый экземпляр T в куче и передать владение им std::shared_ptr<> (7) (обратите внимание на использование функции std::make_shared, чтобы избежать накладных расходов на второе выделение памяти под счетчик ссылок). Вновь созданный узел станет новым фиктивным узлом, поэтому передавать конструктору значение new_value необязательно (8). Вместо этого мы записываем в старый фиктивный узел значение только что созданной копии — new_value (9). Наконец, первоначальный фиктивный узел следует создать в конструкторе (2).
Уверен, теперь вы задаетесь вопросом, что мы выиграли от всех этих изменений и как они помогут сделать код потокобезопасным. Разберемся. Функция push() теперь обращается только к tail, но не к head, и это, безусловно, улучшение. try_pop() обращается и к head, и к tail, но tail нужен только для начального сравнения, так что блокировка удерживается очень недолго. Основной выигрыш мы получили за счет того, что из-за наличия фиктивного узла try_pop() и push() никогда не оперируют одним и тем же узлом, так что нам больше не нужен всеохватывающий мьютекс. Стало быть, мы можем завести по одному мьютексу для head и tail. Но где расставить блокировки?
Мы хотим обеспечить максимум возможностей для распараллеливания, поэтому блокировки должны освобождаться как можно быстрее. С функцией push() всё просто: мьютекс должен быть заблокирован на протяжении всех обращений к tail, а это означает, что мы захватываем его после выделения памяти для нового узла (8) и перед тем, как записать данные в текущий последний узел (9). Затем блокировку следует удерживать до конца функции.
С try_pop() сложнее. Прежде всего, нам нужно захватить мьютекс для head и удерживать его, пока мы не закончим работать с head. По сути дела, этот мьютекс определяет, какой поток производит извлечение из очереди, поэтому захватить его надо в самом начале. После того как значение head изменено (5), мьютекс можно освободить; в момент, когда возвращается результат (6), он уже не нужен. Остается разобраться с защитой доступа к tail. Поскольку мы обращаемся к tail только один раз, то можно захватить мьютекс на время, требуемое для чтения. Проще всего сделать это, поместив операцию доступа в отдельную функцию. На самом деле, поскольку участок кода, в котором мьютекс для head должен быть заблокирован, является частью одной функции-члена, то будет правильнее завести отдельную функцию и для него тоже. Окончательный код приведён в листинге 6.6.
Листинг 6.6. Потокобезопасная очередь с мелкогранулярными блокировками
template<typename T>
class threadsafe_queue {
private:
struct node {
std::shared_ptr<T> data;
std::unique_ptr<node> next;
};
std::mutex head_mutex;
std::unique_ptr<node> head;
std::mutex tail_mutex;
node* tail;
node* get_tail() {
std::lock_guard<std::mutex> tail_lock(tail_mutex);
return tail;
}
std::unique_ptr<node> pop_head() {
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == get_tail()) {
return nullptr;
}
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return old_head;
}
public:
threadsafe_queue():
head(new node), tail(head.get()) {}
threadsafe_queue(const threadsafe_queue& other) = delete;
threadsafe_queue& operator=(
const threadsafe_queue& other) = delete;
std::shared_ptr<T> try_pop() {
std::unique_ptr<node> old_head = pop_head();
return old_head ? old_head->data : std::shared_ptr<T>();
}
void push(T new_value) {
std::shared_ptr<T> new_data(
std::make_shared<T>(std::move(new_value)));
std::unique_ptr<node> p(new node);
node* const new_tail = p.get();
std::lock_guard<std::mutex> tail_lock(tail_mutex);
tail->data = new_data;
tail->next = std::move(p);
tail = new_tail;
}
};
Давайте взглянем на этот код критически, памятуя о рекомендациях из раздела 6.1.1. Прежде чем искать, где нарушены инварианты, надо бы их точно сформулировать:
• tail->next == nullptr.
• tail->data == nullptr.
• head == tail означает, что список пуст.
• Для списка с одним элементом head->next==tail.
• Для каждого узла x списка, для которого x!=tail, x->data указывает на экземпляр T, a x->next — на следующий узел списка. Если x->next==tail, то x — последний узел списка.
• Если проследовать по указателям next, начиная с головы списка, то рано или поздно мы достигнем его хвоста.
Сама по себе, функция push() очень проста: все модификации данных защищены мьютексом tail_mutex, и инвариант при этом сохраняется, потому что новый хвостовой узел пуст и правильно установлены указатели data и next для старого хвостового узла, который теперь стал настоящим последним узлом списка.
Самое интересное происходит в функции try_pop(). Как выясняется, мьютекс tail_mutex нужен не только для защиты чтения самого указателя tail, но и чтобы предотвратить гонку при чтении данных из головного узла. Не будь этого мьютекса, могло бы получиться, что один поток вызывает try_pop(), а другой одновременно вызывает push(), и эти операции никак не упорядочиваются. Хотя каждая функция-член удерживает мьютекс, но это разные мьютексы, а функции могут обращаться к одним и тем же данным — ведь все данные появляются в очереди только благодаря push(). Раз потоки потенциально могут обращаться к одним и тем же данным без какого бы то ни было упорядочения, то возможна гонка за данными и, как следствие (см. главу 5), неопределенное поведение. К счастью, блокировка мьютекса tail_mutex в get_tail() решает все проблемы. Поскольку внутри get_tail() захватывается тот же мьютекс, что в push(), то оба вызова оказываются упорядоченными. Либо обращение к функции get_tail() происходит раньше обращения к push() — тогда get_tail() увидит старое значение tail — либо после обращения к push() — и тогда она увидит новое значение tail и новые данные, присоединенные к прежнему значению tail.
Важно также, что обращение к get_tail() производится под защитой захваченного мьютекса head_mutex. Если бы это было не так, то между вызовом get_tail() и захватом head_mutex мог бы вклиниться вызов pop_head(), потому что другой поток вызвал try_pop() (и, следовательно, pop_head()) и захватил мьютекс первым, не давая первому потоку продолжить исполнение:
│ Эта реализация
std: :unique_ptr<node> pop_head()←┘ некорректна
{ (1) Старое значение tail
│ получено не
node* const old_tail = get_tail();←┘ под защитой head_mutex
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == old_tail) ← (2)
return nullptr;
}
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);← (3)
return old_head;
}
При такой — некорректной — реализации в случае, когда get_tail() (1) вызывается вне области действия блокировки, может оказаться, что и head, и tail изменились к моменту, когда первому потоку удалось захватить head_mutex, и теперь возвращенный хвост мало того что больше не является хвостом, но и вообще не принадлежит списку. Тогда сравнение head с old_tail (2) не прошло бы, хотя head в действительности является последним узлом. Следовательно, после обновления (3) узел head мог бы оказаться в списке дальше tail, то есть за концом списка, что полностью разрушило бы структуру данных. В корректной реализации, показанной в листинге 6.6, вызов get_tail() производится под защитой head_mutex. Это означает, что больше никакой поток не сможет изменить head, a tail будет только отодвигаться от начала списка (по мере добавления новых узлов с помощью push()) — это вполне безопасно. Указатель head никогда не сможет оказаться дальше значения, возвращенного get_tail(), так что инварианты соблюдаются.
После того как pop_head() удалит узел из очереди, обновив head, мьютекс освобождается, и try_pop() может извлечь данные и удалить узел, если таковой был (или вернуть NULL-экземпляр класса std::shared_ptr<>, если узла не было), твердо зная, что она работает в единственном потоке, который имеет доступ к этому узлу.
Далее, внешний интерфейс является подмножеством интерфейса из листинга 6.2, поэтому ранее выполненный анализ остается в силе: в интерфейсе нет внутренне присущих состояний гонки.
Вопрос об исключениях более интересен. Поскольку мы изменили порядок выделения памяти, исключения могут возникать в других местах. Единственные операции в try_pop(), способные возбудить исключение, — это захваты мьютексов, но пока мьютексы не захвачены, данные не модифицируются. Поэтому try_pop() безопасна относительно исключений. С другой стороны, push() выделяет из кучи память для объектов T и node, и каждая такая операция может возбудить исключение. Однако оба вновь созданных объекта присваиваются интеллектуальным указателям, поэтому в случае исключения память корректно освобождается. После того как мьютекс захвачен, ни одна из последующих операций внутри push() не может возбудить исключение, так что мы снова в безопасности.
Поскольку мы не изменяли интерфейс, то новых внешних возможностей для взаимоблокировки не возникло. Внутренних возможностей также нет; единственное место, где захватываются два мьютекса, — это функция pop_head(), но она всегда захватывает сначала head_mutex, а потом tail_mutex, так что взаимоблокировки не случится.
Осталось рассмотреть только один вопрос — в какой мере возможно распараллеливание. Эта структура данных предоставляет куда больше таких возможностей, чем приведенная в листинге 6.2, потому что гранулярность блокировок мельче, и больше работы выполняется не под защитой блокировок. Например, в push() память для нового узла и нового элемента данных выделяется, когда ни одна блокировка не удерживается. Это означает, что несколько потоков могут спокойно выделять новые узлы и элементы данных в одно и то же время. В каждый момент времени только один поток может добавлять новый узел в список, но выполняющий это действие код сводится к нескольким простым присваиваниям указателей, так что блокировка удерживается совсем недолго по сравнению с реализацией на основе std::queue<>, где мьютекс остается захваченным в течение всего времени, пока выполняются операции выделения памяти внутри std::queue<>.
Кроме того, try_pop() удерживает tail_mutex лишь на очень короткое время, необходимое для защиты чтения tail. Следовательно, почти все действия внутри try_pop() могут производиться одновременно с вызовом push(). Объем операций, выполняемых под защитой мьютекса head_mutex также совсем невелик; дорогостоящая операция delete (в деструкторе указателя на узел) производится вне блокировки. Это увеличивает потенциальное число одновременных обращений к try_pop(); в каждый момент времени только один поток может вызывать pop_head(), зато несколько потоков могут удалять старые узлы и безопасно возвращать данные.
Ожидание поступления элемента
Ну хорошо, код в листинге 6.6 дает в наше распоряжение потокобезопасную очередь с мелкогранулярными блокировками, но он поддерживает только функцию try_pop() (и к тому же всего в одном варианте). А как насчет таких удобных функций wait_and_pop(), которые мы написали в листинге 6.2? Сможем ли мы реализовать идентичный интерфейс, сохранив мелкогранулярные блокировки?
Ответ, разумеется, — да, только вот как это сделать? Модифицировать push() несложно: нужно лишь добавить вызов data_cond.notify_one() в конец функции, как и было в листинге 6.2. Но на самом деле не всё так просто; мы же связались с мелкогранулярными блокировками для того, чтобы увеличить уровень параллелизма. Если оставить мьютекс захваченным на все время вызова notify_one() (как в листинге 6.2), то поток, разбуженный до того, как мьютекс освобожден, должен будет ждать мьютекса. С другой стороны, если освободить мьютекс до обращения к notify_one(), то ожидающий поток сможет захватить его сразу, как проснётся (если, конечно, какой-то другой поток не успеет раньше). Это небольшое улучшение, но в некоторых случаях оно бывает полезно.
Функция wait_and_pop() сложнее, потому что мы должны решить, где поместить ожидание, какой задать предикат и какой мьютекс захватить. Мы ждем условия «очередь не пуста», оно представляется выражением head != tail. Если записать его в таком виде, то придется захватывать и head_mutex, и tail_mutex, но, разбирая код в листинге 6.6, мы уже поняли, что захватывать tail_mutex нужно только для чтения tail, а не для самого сравнения, та же логика применима и здесь. Если записать предикат в виде head != get_tail(), то нужно будет захватить только head_mutex и использовать уже полученную блокировку для защиты data_cond.wait(). Прочий код такой же, как в try_pop().
Второй перегруженный вариант try_pop() и соответствующий ему вариант wait_and_pop() нуждаются в тщательном осмыслении. Если просто заменить возврат указателя std::shared_ptr<>, полученного из old_head, копирующим присваиванием параметру value, то функция перестанет быть безопасной относительно исключений. В этот момент элемент данных уже удален из очереди и мьютекс освобожден, осталось только вернуть данные вызывающей программе. Однако, если копирующее присваивание возбудит исключение (а почему бы и нет?), то элемент данных будет потерян, потому что вернуть его в то же место очереди, где он был, уже невозможно.
Если фактический тип T, которым конкретизируется шаблон, обладает не возбуждающими исключений оператором перемещающего присваивания или операцией обмена (swap), то так поступить можно, но ведь мы ищем общее решение, применимое к любому типу T. В таком случае следует поместить операции, способные возбудить исключения, в защищенную область перед тем, как удалять узел из списка. Это означает, что нам необходим еще один перегруженный вариант pop_head(), который извлекает сохраненное значение до модификации списка.
Напротив, модификация функции empty() тривиальна: нужно просто захватить head_mutex и выполнить проверку head == get_tail() (см. листинг 6.10). Окончательный код очереди приведён в листингах 6.7, 6.8, 6.9 и 6.10.
Листинг 6.7. Потокобезопасная очередь с блокировкой и ожиданием: внутренние данные и интерфейс
template<typename T>
class threadsafe_queue {
private:
struct node {
std::shared_ptr<T> data;
std::unique_ptr<node> next;
};
std::mutex head_mutex;
std::unique_ptr<node> head;
std::mutex tail_mutex;
node* tail;
std::condition_variable data_cond;
public:
threadsafe_queue():
head(new node), tail(head.get()) {}
threadsafe_queue(const threadsafe_queue& other) = delete;
threadsafe_queue& operator=(
const threadsafe_queue& other) = delete;
std::shared_ptr<T> try_pop();
bool try_pop(T& value);
std::shared_ptr<T> wait_and_pop();
void wait_and_pop(T& value);
void push(T new_value);
void empty();
};
Код, помещающий новые узлы в очередь, прост — его реализация (показанная в листинге ниже) близка к той, что мы видели раньше.
Листинг 6.8. Потокобезопасная очередь с блокировкой и ожиданием: добавление новых значений
template<typename T>
void threadsafe_queue<T>::push(T new_value) {
std::shared_ptr<T> new_data(
std::make_shared<T>(std::move(new_value)));
std::unique_ptr<node> p(new node);
{
std::lock_guard<std::mutex> tail_lock(tail_mutex);
tail->data = new_data;
node* const new_tail = p.get();
tail->next = std::move(p);
tail = new_tail;
}
data_cond.notify_one();
}
Как уже отмечалось, вся сложность сосредоточена в части pop. В листинге ниже показана реализация функции-члена wait_and_pop() и относящихся к ней вспомогательных функций.
Листинг 6.9. Потокобезопасная очередь с блокировкой и ожиданием: wait_and_pop
template<typename T>
class threadsafe_queue {
private:
node* get_tail() {
std::lock_guard<std::mutex> tail_lock(tail_mutex);
return tail;
}
std::unique_ptr<node> pop_head() {← (1)
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return old_head;
}
std::unique_lock<std::mutex> wait_for_data() {← (2)
std::unique_lock<std::mutex> head_lock(head_mutex);
data_cond.wait(
head_lock, [&]{return head.get() != get_tail();});
return std::move(head_lock); ← (3)
}
std::unique_ptr<node> wait_pop_head() {
std::unique_lock<std::mutex> head_lock(wait_for_data());← (4)
return pop_head();
}
std::unique_ptr<node> wait_pop_head(T& value) {
std::unique_lock<std::mutex> head_lock(wait_for_data());← (5)
value = std::move(*head->data);
return pop_head();
}
public:
std::shared_ptr<T> wait_and_pop() {
std::unique_ptr<node> const old_head = wait_pop_head();
return old_head->data;
}
void wait_and_pop(T& value) {
std::unique_ptr<node> const old_head = wait_pop_head(value);
}
};
В реализации извлечения из очереди используется несколько небольших вспомогательных функций, которые упрощают код и позволяют устранить дублирование, например: pop_head() (1) (модификация списка в результате удаления головного элемента) и wait_for_data() (2) (ожидание появления данных в очереди). Особенно стоит отметить функцию wait_for_data(), потому что она не только ждет условную переменную, используя лямбда-функцию в качестве предиката, но и возвращает объект блокировки вызывающей программе (3). Тем самым мы гарантируем, что та же самая блокировка удерживается, пока данные модифицируются в соответствующем перегруженном варианте wait_pop_head() (4), (5). Функция pop_head() используется также в функции try_pop(), показанной ниже.
Листинг 6.10. Потокобозопасная очередь с блокировкой и ожиданием: try_pop() и empty()
template<typename T>
class threadsafe_queue {
private:
std::unique_ptr<node> try_pop_head() {
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == get_tail()) {
return std::unique_ptr<node>();
}
return pop_head();
}
std::unique_ptr<node> try_pop_head(T& value) {
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == get_tail()) {
return std::unique_ptr<node>();
}
value = std::move(*head->data);
return pop_head();
}
public:
std::shared_ptr<T> try_pop() {
std::unique_ptr<node> old_head = try_pop_head();
return old_head ? old_head->data : std::shared_ptr<T>();
}
bool try_pop(T& value) {
std::unique_ptr<node> const old_head = try_pop_head(value);
return old_head;
}
void empty() {
std::lock_guard<std::mutex> head_lock(head_mutex);
return (head.get() == get_tail());
}
};
Эта реализация очереди ляжет в основу очереди без блокировок, которую мы будем рассматривать в главе 7. Данная очередь неограниченная, то есть в нее можно помещать и помещать данные, ничего не удаляя, пока не кончится память. Альтернативой является ограниченная очередь, максимальная длина которой задается при создании. Попытка поместить элемент в заполненную очередь либо завершается ошибкой, либо приводит к приостановке потока до тех пор, пока из очереди не будет удален хотя бы один элемент. Ограниченные очереди бывают полезны для равномерного распределения задач между потоками (см. главу 8). Такая дисциплина не дает потоку (или потокам), заполняющему очередь, намного обогнать потоки, читающие из очереди.
Показанную реализацию неограниченной очереди легко преобразовать в очередь с ограниченной длиной, введя ожидание условной переменной в функцию push(). Вместо того чтобы ждать, пока в очереди появятся элементы (как pop()), мы должны будем ждать, когда число элементов в ней окажется меньше максимума. Дальнейшее обсуждение ограниченных очередей выходит за рамки этой книги, мы же перейдём от очередей к более сложным структурам данных.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК