8.1.1. Распределение данных между потоками до начала обработки
Легче всего распараллеливаются такие простые алгоритмы, как std::for_each, которые производят некоторую операцию над каждым элементом набора данных. Чтобы распараллелить такой алгоритм, можно назначить каждому элементу один из обрабатывающих потоков. Каким образом распределить элементы для достижения оптимальной производительности, зависит от деталей структуры данных, как мы убедимся ниже в этой главе.
Простейший способ распределения данных заключается в том, чтобы назначить первые N элементов одному потоку, следующие N — другому и так далее, как показано на рис. 8.1, хотя это и не единственное решение. Как бы ни были распределены данные, каждый поток обрабатывает только назначенные ему элементы, никак не взаимодействуя с другими потоками до тех пор, пока не завершит обработку.
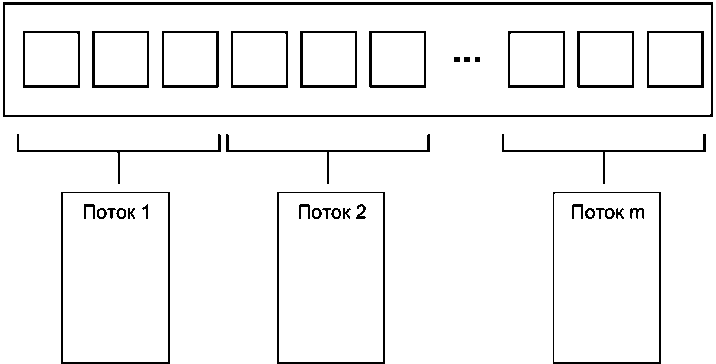
Рис. 8.1. Распределение последовательных блоков данных между потоками
Такая организация программы знакома каждому, кто программировал в системах Message Passing Interface (МРI)[17] или OpenMP[18]: задача разбивается на множество параллельных подзадач, рабочие потоки выполняют их параллельно, а затем результаты объединяются на стадии редукции. Этот подход применён в примере функции accumulate из раздела 2.4; в данном случае и параллельные задачи, и финальный шаг редукции представляют собой аккумулирование. Для простого алгоритма for_each финальный шаг отсутствует, так как нечего редуцировать.
Понимание того, что последний шаг является редукцией, важно; в наивной реализации, представленной в листинге 2.8, финальная редукция выполняется как последовательная операция. Однако часто и ее можно распараллелить; операция accumulate по сути дела сама является редукцией, поэтому функцию из листинга 2.8 можно модифицировать таким образом, чтобы она вызывала себя рекурсивно, если, например, число потоков больше минимального количества элементов, обрабатываемых одним потоком. Или запрограммировать рабочие потоки так, чтобы по завершении задачи они выполняли некоторые шаги редукции, а не запускать каждый раз новые потоки.
Хотя это действенная техника, применима она не в любой ситуации. Иногда данные не удается заранее распределить равномерно, а как это сделать, становится понятно только в процессе обработки. Особенно наглядно это проявляется в таких рекурсивных алгоритмах, как Quicksort; здесь нужен другой подход.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК