5.3.3. Упорядочение доступа к памяти для атомарных операций
Существует шесть вариантов упорядочения доступа к памяти, которые можно задавать в операциях над атомарными типами: memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel и memory_order_seq_cst. Если не указано противное, то для любой операции над атомарными типами подразумевается упорядочение memory_order_seq_cst — самое ограничительное из всех. Хотя вариантов шесть, представляют они всего три модели: последовательно согласованное упорядочение (memory_order_seq_cst), упорядочение захват-освобождение (memory_order_consume, memory_order_acquire, memory_order_release и memory_order_acq_rel) и ослабленное упорядочение (memory_order_relaxed).
Эти три модели упорядочения доступа к памяти влекут за собой различные издержки для процессоров с разной архитектурой. Например, в системах с точным контролем над видимостью операций процессорами, отличными от произведшего изменения, могут потребоваться дополнительные команды синхронизации для обеспечения последовательно согласованного упорядочения по сравнению с ослабленным или упорядочением захват-освобождение, а также для обеспечения упорядочения захват-освобождение по сравнению с ослабленным. Если в такой системе много процессоров, то на выполнение дополнительных команд синхронизации может уходить заметное время, что приведет к снижению общей производительности системы. С другой стороны, процессоры с архитектурой x86 или x86-64 (в частности, Intel и AMD, столь распространенные в настольных ПК) не требуют никаких дополнительных команд для обеспечения упорядочения захват-освобождение, помимо необходимых для гарантий атомарности, и даже последовательно согласованное упорядочение не нуждается в каких-то специальных действиях на операциях загрузки, хотя операции сохранения все же требуют некоторых добавочных затрат.
Наличие различных моделей упорядочения доступа к памяти позволяет эксперту добиться повышения производительности за счет более точного управления отношениями упорядочения там, где это имеет смысл, и в то же время использовать последовательно согласованное упорядочение (которое гораздо проще для понимания) в случаях, когда такой выигрыш не критичен.
Чтобы выбрать подходящую модель, нужно понимать, каковы последствия того или иного решения для поведения программы. Поэтому рассмотрим, какое влияние оказывают различные модели на упорядочение операций и отношение синхронизируется-с.
Последовательно согласованное упорядочение
Упорядочение по умолчанию называется последовательно согласованным, потому что оно предполагает, что поведение программы согласовано с простым последовательным взглядом на мир. Если все операции над экземплярами атомарных типов последовательно согласованы, то поведение многопоточной программы такое же, как если бы эти операции выполнялись в какой-то определенной последовательности в одном потоке. Это самое простое для понимания упорядочение доступа к памяти, потому оно и подразумевается по умолчанию: все потоки должны видеть один и тот же порядок операций. Таким образом, становится достаточно легко рассуждать о поведении программы, написанной с использованием атомарных переменных. Можно выписать все возможные последовательности операций, выполняемых разными потоками, отбросить несогласованные и проверить, что в остальных случаях программа ведет себя, как и ожидалось. Это также означает, что порядок операций нельзя изменять; если в каком-то потоке одна операция предшествует другой, то этот порядок должен быть виден всем остальным потокам.
С точки зрения синхронизации, последовательно согласованное сохранение синхронизируется-с последовательно согласованной операцией загрузки той же переменной, в которой читается сохраненное значение. Тем самым мы получаем одно ограничение на упорядочение операций в двух или более потоках. Однако этим последовательная согласованность не исчерпывается. Любая последовательно согласованная операция, выполненная после этой загрузки, должна быть видна всякому другому потоку в системе с последовательно согласованными атомарными операциями именно как следующая за загрузкой. Пример в листинге 5.4 демонстрирует это ограничение на упорядочение в действии. Однако это ограничение не распространяется на потоки, в которых для атомарных операций задано ослабленное упорядочение — они по-прежнему могут видеть операции в другом порядке. Поэтому, чтобы получить пользу от последовательного согласования операций, его надо использовать во всех потоках.
Но за простоту понимания приходится платить. На машине со слабым упорядочением и большим количеством процессоров может наблюдаться заметное снижение производительности, потому что для поддержания согласованной последовательности операций, возможно, придётся часто выполнять дорогостоящие операции синхронизации процессоров. Вместе с тем следует отметить, что некоторые архитектуры процессоров (в частности, такие распространенные, как x86 и x86-64) обеспечивают последовательную согласованность с относительно низкими издержками, так что если вас волнует влияние последовательно согласованного упорядочения на производительность, ознакомьтесь с документацией но конкретному процессору.
В следующем листинге последовательная согласованность демонстрируется на примере. Операции загрузки и сохранения переменных x и y явно помечены признаком memory_order_seq_cst, хотя его можно было бы и опустить, так как он подразумевается по умолчанию.
Листинг 5.4. Из последовательной согласованности вытекает полная упорядоченность
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x() {
x.store(true, std::memory_order_seq_cst); ← (1)
}
void write_y() {
y.store(true, std::memory_order_seq_cst); ← (2)
}
void read_x_then_y() {
while (!x.load(std::memory_order_seq_cst));← (3)
if (y.load(std::memory_order_seq_cst))
++z;
}
void read_y_then_x() {
while (!y.load(std::memory_order_seq_cst));← (4)
if (x.load(std::memory_order_seq_cst))
++z;
}
int main() {
x = false;
y = false;
z = 0;
std::thread a(write_x);
std::thread b(write_y);
std::thread с(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load() != 0); ← (5)
}
Утверждение assert (5) не может сработать, потому что первым должно произойти сохранение x (1) или сохранение y (2), пусть даже точно не сказано, какое именно. Если загрузка y в функции read_x_then_y (3) возвращает false, то сохранение x должно было произойти раньше сохранения y, и в таком случае загрузка x в read_y_then_x (4) должна вернуть true, потому что наличие цикла while гарантирует, что в этой точке у равно true. Поскольку семантика memory_order_seq_cst требует полного упорядочения всех операций, помеченных признаком memory_order_seq_cst, то существует подразумеваемое отношение порядка между операцией загрузки y, которая возвращает false (3), и операцией сохранения y (1). Чтобы имело место единственное полное упорядочение в случае, когда некоторый поток сначала видит x==true, затем y==false, необходимо, чтобы при таком упорядочении сохранение x происходило раньше сохранения y.
Разумеется, поскольку всё симметрично, могло бы произойти и ровно наоборот: загрузка x (4) возвращает false, и тогда загрузка y (3) обязана вернуть true. В обоих случаях z равно 1. Может быть и так, что обе операции вернут true, и тогда z будет равно 2. Но ни в каком случае z не может оказаться равным нулю.
Операции и отношения происходит-раньше для случая, когда read_x_then_y видит, что x равно true, а y равно false, изображены на рис. 5.3. Пунктирная линия от операции загрузки y в read_x_then_y к операции сохранения y в write_y показывает наличие неявного отношения порядка, необходимого для поддержания последовательной согласованности: загрузка должна произойти раньше сохранения в глобальном порядке операций, помеченных признаком memory_order_seq_cst, — только тогда получится показанный на рисунке результат.
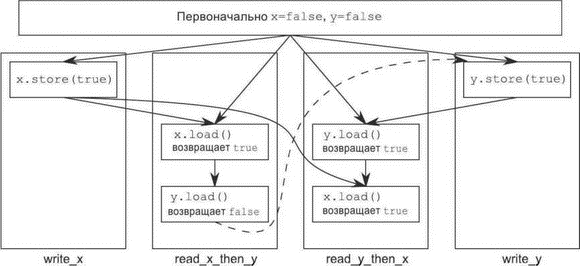
Рис. 5.3. Последовательная согласованность и отношения происходит-раньше
Последовательная согласованность — самое простое и интуитивно понятное упорядочение, но оно же является и самым накладным из- за необходимости глобальной синхронизации между всеми потоками. В многопроцессорной системе это потребовало бы многочисленных и затратных по времени взаимодействий между процессорами. Чтобы избежать затрат на синхронизацию, необходимо выйти за пределы мира последовательной согласованности и рассмотреть другие модели упорядочения доступа к памяти.
Не последовательно согласованное упорядочение доступа к памяти
За пределами уютного последовательно согласованного мирка нас встречает более сложная реальность. И, пожалуй, самое трудное — смириться с тем фактом, что единого глобального порядка событий больше не существует. Это означает, что разные потоки могут по-разному видеть одни и те же операции, и с любой умозрительной моделью, предполагающей, что операции, выполняемые в разных потоках, строго перемежаются, следует распрощаться. Вы должны учитывать не только то, что события могут происходить по-настоящему одновременно, но и то, что потоки не обязаны согласовывать порядок событий между собой. Чтобы написать (или хотя бы понять) код, в котором используется упорядочение, отличное от memory_order_seq_cst, абсолютно необходимо уложить этот факт в мозгу. Мало того что компилятор вправе изменять порядок команд. Даже если потоки исполняют один и тот же код, они могут видеть события в разном порядке, потому что в отсутствие явных ограничений на упорядочение кэши различных процессоров и внутренние буферы могут содержать различные значения для одной и той же ячейки памяти. Это настолько важно, что я еще раз повторю: потоки не обязаны согласовывать порядок событий между собой.
Вы должны отбросить мысленные модели, основанные не только на идее чередования операций, но и на представлении о том, что компилятор или процессор изменяет порядок команд. В отсутствие иных ограничений на упорядочение, единственное требование заключается в том, что все потоки согласны относительно порядка модификации каждой отдельной переменной. Операции над различными переменными могут быть видны разным потокам в разном порядке при условии, что видимые значения согласуются с наложенными дополнительными ограничениями на упорядочение.
Проще всего это продемонстрировать, перейдя от последовательной согласованности к ее полной противоположности — упорядочению memory_order_relaxed для всех операций. Освоив этот случай, мы сможем вернуться к упорядочению захват-освобождение, которое позволяет избирательно вводить некоторые отношения порядка между операциями. Это хоть как-то поможет собрать разлетевшиеся мозги в кучку.
Ослабленное упорядочение
Операции над атомарными типами, выполняемые в режиме ослабленного упорядочения, не участвуют в отношениях синхронизируется-с. Операции над одной и той же переменной в одном потоке по-прежнему связаны отношением происходит-раньше, но на относительный порядок операций в разных потоках не накладывается почти никаких ограничений. Есть лишь одно требование: операции доступа к одной атомарной переменной в одном и том же потоке нельзя переупорядочивать — если данный поток видел определенное значение атомарной переменной, то последующая операция чтения не может извлечь предыдущее значение этой переменной. В отсутствие дополнительной синхронизации порядок модификации отдельных переменных — это единственное, что объединяет потоки, использующие модель memory_order_relaxed.
Чтобы продемонстрировать, до какой степени могут быть «ослаблены» операции в этой модели, достаточно всего двух потоков (см. листинг 5.5).
Листинг 5.5. К ослабленным операциям предъявляются очень слабые требования
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y() {
x.store(true, std::memory_order_relaxed); ← (1)
y.store(true, std::memory_order_relaxed); ← (2)
}
void read_y_then_x() {
while (!y.load(std::memory_order_relaxed));← (3)
if (x.load(std::memory_order_relaxed)) ← (4)
++z;
}
int main() {
x = false;
y = false;
z = 0;
std::thread а(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert (z.load() != 0); ← (5)
}
На этот раз утверждение (5) может сработать, потому что операция загрузки x (4) может прочитать false, даже если загрузка y (3) прочитает true, а сохранение x (1) происходит-раньше сохранения y (2). x и y — разные переменные, поэтому нет никаких гарантий относительно порядка видимости результатов операций над каждой из них.
Ослабленные операции над разными переменными можно как угодно переупорядочивать при условии, что они подчиняются ограничивающим отношениям происходит-раньше (например, действующим внутри одного потока). Никаких отношений синхронизируется-с не возникает. Отношения происходит-раньше, имеющиеся в листинге 5.5, изображены на рис. 5.4, вместе с возможным результатом. Несмотря на то, что существует отношение происходит-раньше отдельно между операциями сохранения и операциями загрузки, не существует ни одного такого отношения между любым сохранением и любой загрузкой, поэтому операция загрузки может увидеть операции сохранения не в том порядке, в котором они происходили.
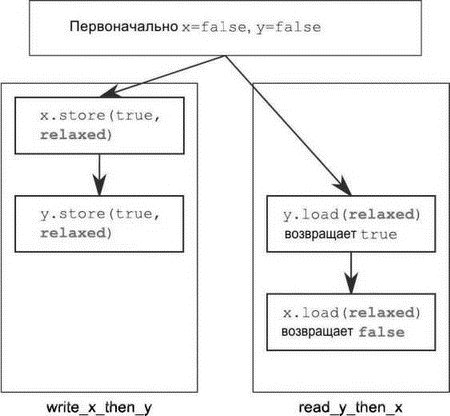
Рис. 5.4. Ослабленные атомарные операции и отношения происходит-раньше
Рассмотрим чуть более сложный пример с тремя переменными и пятью потоками.
Листинг 5.6. Ослабленные операции в нескольких потоках
#include <thread>
#include <atomic>
#include <iostream>
std::atomic<int> x(0), y(0), z(0);← (1)
std::atomic<bool> go(false); ← (2)
unsigned const loop_count = 10;
struct read_values {
int x, y, z;
};
read_values values1[loop_count];
read_values values2[loop_count];
read_values values3[loop_count];
read_values values4[loop_count];
read_values values5[loop_count];
void increment(
std::atomic<int>* var_to_inc, read_values* values) {
while (!go) ← (3) В цикле ждем сигнала
std::this_thread::yield();
for (unsigned i = 0; i < loop_count; ++i) {
values[i].x = x.load(std::memory_order_relaxed);
values[i].y = y.load(std::memory_order_relaxed);
values[i].z = z.load(std::memory_order_relaxed);
var_to_inc->store(i + 1, std::memory_order_relaxed);← (4)
std::this_thread::yield();
}
}
void read_vals(read_values* values) {
while (!go) ← (5) В цикле ждем сигнала
std::this_thread::yield();
for (unsigned i = 0; i < loop_count; ++i) {
values[i].x = x.load(std::memory_order_relaxed);
values[i].y = y.load(std::memory_order_relaxed);
values[i].z = z.load(std::memory_order_relaxed);
std::this_thread::yield();
}
}
void print(read_values* v) {
for (unsigned i = 0; i < loop_count; ++i) {
if (i)
std::cout << ",";
std::cout <<
"(" << v [i] .x << "," << v[i].y << "," << v[i].z << ")";
}
std::cout << std::endl;
}
int main() {
std::thread t1(increment, &x, values1);
std::thread t2(increment, &y, values2);
std::thread t3(increment, &z, values3);
std::thread t4(read_vals, values4);
std::thread t5(read_vals, values5);
go = true; ←┐ Сигнал к началу выполнения
│ (6) главного цикла
t5.join();
t4.join();
t3.join();
t2.join();
t1.join();
print(values1);←┐
print(values2); │ Печатаем получившиеся
print(values3); (7) значения
print(values4);
print(values5);
}
По существу, это очень простая программа. У нас есть три разделяемых глобальных атомарных переменных (1) и пять потоков. Каждый поток выполняет 10 итераций цикла, читая значения трех атомарных переменных в режиме memory_order_relaxed и сохраняя их в массиве. Три из пяти потоков обновляют одну из атомарных переменных при каждом проходе по циклу (4), а остальные два только читают ее. После присоединения всех потоков мы распечатываем массивы, заполненные каждым из них (7).
Атомарная переменная go (2) служит для того, чтобы все потоки начали работу по возможности одновременно. Запуск потока — накладная операция и, не будь явной задержки, первый поток мог бы завершиться еще до того, как последний зачал работать. Каждый поток ждет, пока переменная go станет равна true, и только потом входит в главный цикл (3), (5), а переменная go устанавливается в true только после запуска всех потоков (6).
Ниже показан один из возможных результатов прогона этой прогона:
(0,0,0),(1,0,0),(2,0,0),(3,0,0),(4,0,0),(5,7,0),(6,7,8),(7,9,8),(8,9,8),(9,9,10)
(0,0,0),(0,1,0),(0,2,0),(1,3,5),(8,4,5),(8,5,5),(8,6,6),(8,7,9),(10,8,9),(10,9,10)
(0,0,0),(0,0,1),(0,0,2),(0,0,3),(0,0,4),(0,0,5),(0,0,6),(0,0,7),(0,0,8),(0,0,9)
(1,3,0),(2,3,0),(2,4,1),(3,6,4),(3,9,5),(5,10,6),(5,10,8),(5,10,10),(9,10,10),(10,10,10)
(0,0,0),(0,0,0),(0,0,0),(6,3,7),(6,5,7),(7,7,7),(7,8,7),(8,8,7),(8,8,9),(8,8,9)
Первые три строки относятся к потокам, выполнявшим обновление, последние две — к потокам, которые занимались только чтением. Каждая тройка — это значения переменных x, y, z в порядке итераций цикла. Следует отметить несколько моментов.
• В первом наборе значения x увеличиваются на 1 в каждой тройке, во втором наборе на 1 увеличиваются значения y, а в третьем — значения z.
• Значения x (а равно y и z) увеличиваются только в пределах данного набора, но приращения неравномерны и относительный порядок в разных наборах различен.
• Поток 3 не видит обновлений x и y, ему видны только обновления z. Но это не мешает другим потокам видеть обновления z наряду с обновлениями x и y.
Это всего лишь один из возможных результатов выполнения ослабленных операций. Вообще говоря, возможен любой результат, в котором каждая из трех переменных принимает значения от 0 до 10, и в каждом потоке, обновляющем некоторую переменную, ее значения монотонно изменяются от 0 до 9.
Механизм ослабленного упорядочения
Чтобы попять, как всё это работает, представьте, что каждая переменная — человек с блокнотом, сидящий в отдельном боксе. В блокноте записана последовательность значений. Вы можете позвонить сидельцу и попросить либо прочитать вслух какое-нибудь значение, либо записать новое. Новое значение он записывает в конец последовательности.
При первой просьбе дать значение человек может прочитать любое значение из списка, имеющегося в данный момент. В ответ на следующую просьбу он может прочитать либо то же самое значение, либо значение, расположенное позже него в списке, но никогда — значение, расположенное раньше уже прочитанного. Если вы просили записать значение, а потом прочитать, то он может сообщить либо значение, записанное в ответ на вашу просьбу, либо расположенное позже него в списке.
Теперь представьте, что в начале списка находятся значения 5, 10, 23, 3, 1, 2. Человек может прочитать любое из них. Если он скажет 10, то в следующий раз он может прочитать также 10 или любое последующее число, но не 5. Если вы позвоните пять раз, то может услышать, например, последовательность «10, 10, 1, 2, 2». Если вы попросите записать 42, он добавит это число в конец списка. Если вы затем будете просить прочитать число, то он будет повторять «42», пока в списке не появится новое число и он не захочет назвать его.
Предположим далее, что у Карла тоже есть телефон этого человека. Карл тоже может позволить ему с просьбой либо прочитать, либо записать число. При этом к Карлу применяются те же правила, что и к вам. Телефон только один, поэтому в каждый момент времени человек общается только с одним из вас, так что список в его блокноте растет строго последовательно. Но из того, что вы попросили записать его новое число, вовсе не следует, что он должен сообщить его Карлу. и наоборот. Если Карл попросил назвать число и услышал в ответ «23», то из того, что вы попросили записать число 42, не вытекает, что в следующий раз Карл услышит его. Человек может назвать Карлу любое из чисел 23, 3, 1, 2, 42 или даже 67, если после вас позвонил Фред и попросил записать это число. Он даже может назвать Карлу последовательность «23, 3, 3, 1, 67», и это не будет противоречить тому, что услышали вы. Можно представить себе, что человек запоминает, какое число кому назвал, сдвигая указатели, на которых написано имя спрашивающего, как показано на рис. 5.5.
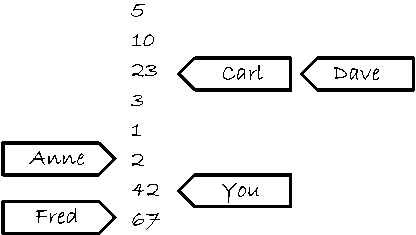
Рис. 5.5. Блокнот человека, сидящего в боксе
Теперь представьте, что имеется целый ряд боксов, в каждом из которых сидит по человеку с блокнотом и телефоном. Это всё наши атомарные переменные. У каждой переменной свой порядок модификации (список значений в блокноте), по между ними нет никакой связи. Если каждый звонящий (вы, Карл, Анна, Дэйв и Фред) представляет поток, то именно такая картина наблюдается, когда все операции работают в режиме memory_order_relaxed. К человеку, сидящему в боксе, можно обращаться и с другими просьбами, например: «запиши это число и скажи мне, что находится в конце списка» (exchange) или «запиши это число, если число в конце списка равно тому, в противном случае скажи мне, что я должен был бы предположить» (compare_exchange_strong), но общий принцип при этом не изменяется.
Применив эту метафору к программе в листинге 5.5, можно сказать, что write_x_then_y означает, что некто позвонил человеку в боксе x, попросил его записать true, а потом позвонил человеку в боксе y и попросил его записать true. Поток, выполняющий функцию read_y_then_x, раз за разом звонит человеку в боксе y и спрашивает значение, пока не услышит true, после чего звонит человеку в боксе x и спрашивает значение у него. Человек в боксе x не обязан сообщать вам какое-то конкретное значение из своего списка и с полным правом может назвать false.
Из-за этого с ослабленными атомарными операциями трудно иметь дело. Чтобы они были полезны для межпоточной синхронизации, их нужно сочетать с атомарными операциями, работающими в режиме с более строгой семантикой упорядочения. Я настоятельно рекомендую вообще избегать ослабленных атомарных операций, если без них можно обойтись, а, если никак нельзя, то использовать крайне осторожно. Учитывая, насколько интуитивно неочевидные результаты получились в листинге 5.5 при наличии всего двух потоков и двух переменных, нетрудно представить себе сложности, с которыми придется столкнуться, когда потоков и переменных станет больше.
Один из способов организовать дополнительную синхронизацию, не прибегая к последовательной согласованности, — воспользоваться упорядочением захват-освобождение.
Упорядочение захват-освобождение
Упорядочение захват-освобождение — шаг от ослабленного упорядочения в сторону большего порядка; полной упорядоченности операций еще нет, но какая-то синхронизация уже возможна. При такой модели атомарные операции загрузки являются операциями захвата (memory_order_acquire), атомарные операции сохранения — операциями освобождения (memory_order_release), а атомарные операции чтения-модификации-записи (например, fetch_add() или exchange()) — операциями захвата, освобождения или того и другого (memory_order_acq_rel). Синхронизация попарная — между потоком, выполнившим захват, и потоком, выполнившим освобождение. Операция освобождения синхронизируется-с операцией захвата, которая читает записанное значение. Это означает, что различные потоки могут видеть операции в разном порядке, но возможны все-таки не любые порядки. В следующем листинге показала программа из листинга 5.4, переработанная под семантику захвата-освобождения вместо семантики последовательной согласованности.
Листинг 5.7. Из семантики захвата-освобождения не вытекает полная упорядоченность
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x() {
x.store(true, std::memory_order_release);
}
void write_y() {
y.store(true, std::memory_order_release);
}
void read_x_then_y() {
while (!x.load(std::memory_order_acquire));
if (y.load(std::memory_order_acquire)) ← (1)
++z;
}
void read_y_then_x() {
while (!y.load(std::memory_order_acquire));
if (x.load(std::memory_order_acquire)) ← (2)
++z;
}
int main() {
x = false;
y = false;
z = 0;
std::thread a(write_x);
std::thread b(write_y);
std::thread с(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load() != 0); ← (3)
}
В данном случае утверждение (3) может сработать (как и в случае ослабленного упорядочения), потому что обе операции загрузки — x (2) и y (1) могут прочитать значение false. Запись в переменные x и y производится из разных потоков, но упорядоченность между освобождением и захватом в одном потоке никак не отражается на операциях в других потоках.
На рис. 5.6 показаны отношения происходит-раньше, имеющие место в программе из листинга 5.7, а также возможный исход, когда два потока-читателя имеют разное представление о мире. Это возможно, потому что, как уже было сказано, не существует отношения происходит-раньше, которое вводило бы упорядочение.
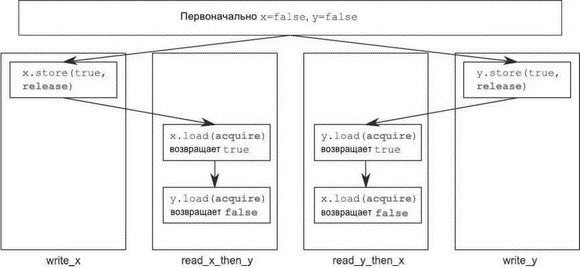
Рис. 5.6. Захват-освобождение и отношения происходит-раньше
Чтобы осознать преимущества упорядочения захват-освобождение, нужно рассмотреть две операции сохранения в одном потоке, как в листинге 5.5. Если при сохранении y задать семантику memory_order_release, а при загрузке y — семантику memory_order_acquire, как в листинге ниже, то операции над x станут упорядоченными.
Листинг 5.8. Операции с семантикой захвата-освобождения могут упорядочить ослабленные операции
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y() {
x.store(true,std::memory_order_relaxed); ← (1)
y.store(true,std::memory_order_release); ← (2)
}
void read_y_then_x() {
while (!y.load(std::memory_order_acquire));← (3)
if (x.load(std::memory_order_relaxed)) ← (4)
++z;
}
int main() {
x = false;
y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load() != 0); ← (5)
}
В конечном итоге операция загрузки y (3) увидит значение true, записанное операцией сохранения (2). Поскольку сохранение производится в режиме memory_order_release, а загрузка — в режиме memory_order_acquire, то сохранение синхронизируется-с загрузкой. Сохранение x (1) происходит-раньше сохранения y (2), потому что обе операции выполняются в одном потоке. Поскольку сохранение y синхронизируется-с загрузкой y, то сохранение x также происходит-раньше загрузки y, и, следовательно, происходит-раньше загрузки x (4). Таким образом, операция загрузки x должна прочитать true, и, значит, утверждение (5) не может сработать. Если бы загрузка y не повторялась в цикле while, то высказанное утверждение могло бы оказаться неверным; операция загрузки y могла бы прочитать false, и тогда не было бы никаких ограничений на значение, прочитанное из x. Для обеспечения синхронизации операции захвата и освобождения должны употребляться парами. Значение, сохраненное операций восстановления, должно быть видно операции захвата, иначе ни та, ни другая не возымеют эффекта. Если бы сохранение в предложении (2) или загрузка в предложении (3) выполнялись в ослабленной операции, то обращения к x не были бы упорядочены, и, значит, нельзя было бы гарантировать, что операция загрузки в предложении (4) прочитает значение true, поэтому утверждение assert могло бы сработать.
К упорядочению захват-освобождение можно применить метафору человека с блокнотом в боксе, если ее немного дополнить. Во-первых, допустим, что каждое сохранение является частью некоторого пакета обновлений, поэтому, обращаясь к человеку с просьбой записать число, вы заодно сообщается ему идентификатор пакета, например: «Запиши 99 как часть пакета 423». Если речь идет о последнем сохранении в пакете, то мы сообщаем об этом: «Запиши 147, отметив, что это последнее сохранение в пакете 423». Человек в боксе честно записывает эту информацию вместе с указанным вами значением. Так моделируется операция сохранения с освобождением. Когда вы в следующий раз попросите записать значение, помер пакета нужно будет увеличить: «Запиши 41 как часть пакета 424».
Теперь, когда вы просите сообщить значение, у вас есть выбор: узнать только значение (это аналог ослабленной загрузки) или значение и сведения о том, является ли оно последним в пакете (это аналог загрузки с захватом). Если информация о пакете запрашивается, по значение не последнее в пакете, то человек ответит: «Число равно 987, и это 'обычное' значение»; если же значение последнее, то ответ прозвучит так: «Число 987, последнее в пакете 956 от Анны». Тут-то и проявляется семантика захвата-освобождения: если, запрашивая значение, вы сообщите человеку номера всех пакетов, о которых знаете, то он найдёт в своем списке последнее значение из всех известных вам пакетов и назовёт либо его, либо какое-нибудь следующее за ним в списке.
Как эта метафора моделирует семантику захвата-освобождения? Взгляните на наш пример — и поймете. В самом начале поток а вызывает функцию write_x_then_y и говорит человеку в боксе x: «Запиши true, как часть пакета 1 от потока а». Затем поток а говорит человеку в боксе y: «Запиши true, как последнюю операцию записи в пакете 1 от потока а». Тем временем поток b выполняет функцию read_y_then_x. Он раз за разом просит человека в боксе y сообщить значение вместе с информацией о пакете, пока не услышит в ответ «true». Возможно, спросить придется много раз, но в конце концов человек обязательно ответит «true». Однако человек в боксе y говорит не просто «true», а еще добавляет: «Это последняя операция записи в пакете 1 от потока а».
Далее поток b просит человека в боксе x назвать значение, но на это раз говорит: «Сообщи мне значение и, кстати, я знаю о пакете 1 от потока а». Человек в боксе x ищет в своем списке последнее упоминание о пакете 1 от потока а. Он находит единственное значение true, которое стоит последним в списке, поэтому он обязан сообщить именно это значение, иначе нарушит правила игры.
Вспомнив определение отношения межпоточно происходит раньше в разделе 5.3.2, вы обнаружите, что одно из его существенных свойств — транзитивность: если А межпоточно происходит-раньше В и В межпоточно происходит-раньше С, то А межпоточно происходит-раньше С. Это означает, что упорядочение захват-освобождение можно использовать для синхронизации данных между несколькими потоками, даже если «промежуточные» потоки на самом деле не обращались к данным.
Транзитивная синхронизация с помощью упорядочения захват-освобождение
Для рассуждений о транзитивном упорядочении нужны по меньшей мере три потока. Первый модифицирует какие-то разделяемые переменные и выполняет операцию сохранения с освобождением в одну из них. Второй читает переменную, записанную операцией сохранения с освобождением, с помощью операции загрузки с захватом и выполняет сохранение с освобождением во вторую разделяемую переменную. Наконец, третий поток выполняет операцию загрузки с захватом для второй разделяемой переменной. При условии, что операции загрузки с захватом видят значения, записанные операциями сохранения с освобождением, и тем самым поддерживают отношения синхронизируется-с, третий поток может прочитать значения других переменных, сохраненные первым потоком, даже если промежуточный поток к ним не обращался. Этот сценарий иллюстрируется в следующем листинге.
Листинг 5.9. Транзитивная синхронизация с помощью упорядочения захват-освобождение
std::atomic<int> data[5];
std::atomic<bool> sync1(false), sync2(false);
void thread_1() {
data[0].store(42, std::memory_order_relaxed);
data[1].store(97, std::memory_order_relaxed);
data[2].store(17, std::memory_order_relaxed);
data[3].store(-141, std::memory_order_relaxed);
data[4].store(2003, std::memory_order_relaxed);←┐ Установить
sync1.store(true, std::memory_order_release); (1)sync1
}
void thread_2() (2)Цикл до
{ │ установки
while (!sync1.load(std::memory_order_acquire));←┘ sync1
sync2.store(true, std::memory_order_release); ←┐ Установить
} (3) sync2
void thread_3() (4)Цикл до
{ │ установки
while (!sync2.load(std::memory_order_acquire));←┘ sync2
assert(data[0].load(std::memory_order_relaxed) == 42);
assert(data[1].load(std::memory_order_relaxed) == 97);
assert(data[2].load(std::memory_order_relaxed) == 17);
assert(data[3].load(std::memory_order_relaxed) == -141);
assert(data[4].load(std::memory_order_relaxed) == 2003);
}
Хотя поток thread_2 обращается только к переменным sync1 (2) и sync2 (3), этого достаточно для синхронизации между thread_1 и thread_3 и, стало быть, гарантии несрабатывания утверждений assert. Прежде всего, операции сохранения в элементы массива data в потоке thread_1 происходят-раньше сохранения sync1 (1), потому что они связаны отношением расположено-перед в одном потоке. Поскольку операция загрузки sync1 (2) находится внутри цикла while, она в конце концов увидит значение, сохраненное в thread_1 и, значит, образует вторую половину пары освобождение-захват. Поэтому сохранение sync1 происходит-раньше последней загрузки sync1 в цикле while. Эта операция загрузки расположена-перед (и, значит, происходит-раньше) операцией сохранения sync2 (3), которая образует пару освобождение-захват вместе с последней операцией загрузки в цикле while в потоке thread_3 (4). Таким образом, сохранение sync2 (3) происходит-раньше загрузки (4), которая происходит-раньше загрузок data. В силу транзитивности отношения происходит-раньше всю эту цепочку можно соединить: операции сохранения data происходят-раньше операций сохранения sync1 (1), которые происходят-раньше загрузки sync1 (2), которая происходит-раньше сохранения sync2 (3), которая происходит-раньше загрузки sync2 (4), которая происходит-раньше загрузок data. Следовательно, операции сохранения data в потоке thread_1 происходят-раньше операций загрузки data в потоке thread_3, и утверждения assert сработать не могут.
В этом случае можно было бы объединить sync1 и sync2 в одну переменную, воспользовавшись операцией чтения-модификации-записи с семантикой memory_order_acq_rel в потоке thread_2. Один из вариантов — использовать функцию compare_exchange_strong(), гарантирующую, что значение будет обновлено только после того, как поток thread_2 увидит результат сохранения в потоке thread_1:
std::atomic<int> sync(0);
void thread_1() {
// ...
sync.store(1, std::memory_order_release);
}
void thread_2() {
int expected = 1;
while (!sync.compare_exchange_strong(expected, 2,
std::memory_order_acq_rel))
expected = 1;
}
void thread_3() {
while(sync.load(std::memory_order_acquire) < 2);
// ...
}
При использовании операций чтения-модификации-записи важно выбрать нужную семантику. В данном случае нам нужна одновременно семантика захвата и освобождения, поэтому подойдет memory_order_acq_rel, но можно было бы применить другие виды упорядочения. Операция fetch_sub с семантикой memory_order_acquire не синхронизируется ни с чем, хотя и сохраняет значение, потому что это не операция освобождения. Аналогично сохранение не может синхронизироваться-с операцией fetch_or с семантикой memory_order_release, потому что часть «чтение» fetch_or не является операцией захвата. Операции чтения-модификации-записи с семантикой memory_order_acq_rel ведут себя как операции захвата и освобождения одновременно, поэтому предшествующее сохранение может синхронизироваться-с такой операцией и с последующей загрузкой, как и обстоит дело в примере выше.
Если вы сочетаете операции захвата-освобождения с последовательно согласованными операциями, то последовательно согласованные операции загрузки ведут себя, как загрузки с семантикой захвата, а последовательно согласованные операции сохранения — как сохранения с семантикой освобождения. Последовательно согласованные операции чтения-модификации-записи ведут себя как операции, наделенные одновременно семантикой захвата и освобождения. Ослабленные операции так и остаются ослабленными, но связаны дополнительными отношениями синхронизируется-с и последующими отношениями происходит-раньше, наличие которых обусловлено семантикой захвата-освобождения.
Несмотря на интуитивно неочевидные результаты, всякий, кто использовал блокировки, вынужденно имел дело с вопросами упорядочения: блокировка мьютекса — это операция захвата, а его разблокировка — операция освобождения. Работая с мьютексами, вы на опыте узнаете, что при чтении значения необходимо захватывать тот же мьютекс, который захватывался при его записи. Точно так же обстоит дело и здесь — для обеспечения упорядочения операции захвата и освобождения должны применяться к одной и той же переменной. Если данные защищены мьютексом, то взаимно исключающая природа блокировки означает, что результат неотличим от того, который получился бы, если бы операции блокировки и разблокировки были последовательно согласованы. Аналогично, если для построения простой блокировки к атомарным переменным применяется упорядочение захват-освобождение, то с точки зрения программы, использующей такую блокировку, поведение кажется последовательно согласованным, хотя внутренние операции таковыми не являются.
Если для выполняемых в вашей программе атомарных операций не нужна строгость последовательно согласованного упорядочения, то попарная синхронизация с помощью упорядочения захват-освобождение может обеспечить синхронизацию со значительно меньшими издержками, чем необходимое для последовательно согласованных операций глобальное упорядочение. Ценой компромисса являются мысленные усилия, необходимые для того, чтобы удостовериться в том, что упорядочение работает правильно, а интуитивно неочевидное поведение нескольких потоков не вызывает проблем.
Зависимости по данным, упорядочение захват-освобождение и семантика memory_order_consume
Во введении к этому разделу я говорил, что семантика memory_order_consume является частью модели упорядочения захват-освобождение, но из предшествующего описания она полностью выпала. Дело в том, что семантика memory_order_consume особая: она связана с зависимостями по данным и позволяет учесть соответствующие нюансы в отношении межпоточно происходит-раньше, о котором шла речь в разделе 5.3.2.
С зависимостями по данным связаны два новых отношения: предшествует-по-зависимости (dependency-ordered-before) и переносит-зависимость-в (carries-a-dependency-to). Как и отношение расположено-перед, отношение переносит-зависимость-в применяется строго внутри одного потока и моделирует зависимость по данным между операциями — если результат операции А используется в качестве операнда операции В, то А переносит-зависимость-в В. Если результатом операции А является значение скалярного типа, например int, то отношение применяется и тогда, когда результат А сохраняется в переменной, которая затем используется в качестве операнда В. Эта операция также транзитивна, то есть если А переносит-зависимость-в В и В переносит-зависимость-в С, то А переносит-зависимость-в С.
С другой стороны, отношение предшествует-по-зависимости может применяться к разным потокам. Оно вводится с помощью атомарных операций загрузки, помеченных признаком memory_order_consume. Это частный случай семантики memory_order_acquire, в котором синхронизированные данные ограничиваются прямыми зависимостями; операция сохранения А, помеченная признаком memory_order_release, memory_order_acq_rel или memory_order_seq_cst, предшествует-по-зависимости операции загрузки В, помеченной признаком memory_order_consume, если потребитель читает сохраненное значение. Это противоположность отношению синхронизируется-с, которое образуется, если операция загрузки помечена признаком memory_order_acquire. Если такая операция В затем переносит-зависимость-в некоторую операцию С, то А также предшествует-по-зависимости С.
Это не дало бы ничего полезного для целей синхронизации, если бы не было связано с отношением межпоточно происходит-раньше. Однако же справедливо следующее утверждение: если А предшествует-по-зависимости В, то А межпоточно происходит-раньше В.
Одно из важных применений такого упорядочения доступа к памяти связано с атомарной операцией загрузки указателя на данные. Пометив операцию загрузки признаком memory_order_consume, а предшествующую ей операцию сохранения — признаком memory_order_release, можно гарантировать, что данные, адресуемые указателем, правильно синхронизированы, даже не накладывая никаких требований к синхронизации с другими независимыми данными. Этот сценарий иллюстрируется в следующем листинге.
Листинг 5.10. Использование std::memory_order_consume для синхронизации данных
struct X {
int i;
std::string s;
};
std::atomic<X*> p;
std::atomic<int> a;
void create_x() {
X* x = new X;
x->i = 42;
x->s = "hello";
a.store(99, std::memory_order_relaxed);← (1)
p.store(x, std::memory_order_release); ← (2)
}
void use_x() {
X* x;
while (!(x = p.load(std::memory_order_consume)))← (3)
std::this_thread::sleep(std::chrono::microseconds(1));
assert(x->i == 42); ← (4)
assert(x->s =="hello"); ← (5)
assert(a.load(std::memory_order_relaxed) == 99);← (6)
}
int main() {
std::thread t1(create_x);
std::thread t2(use_x);
t1.join();
t2.join();
}
Хотя сохранение а (1) расположено перед сохранением p (2) и сохранение p помечено признаком memory_order_release, но загрузка p (3) помечена признаком memory_order_consume. Это означает, что сохранение p происходит-раньше только тех выражений, которые зависят от значения, загруженного из p. Поэтому утверждения о членах-данных структуры x (4), (5) гарантированно не сработают, так как загрузка p переносит-зависимость-в эти выражения посредством переменной x. С другой стороны, утверждение о значении а (6) может как сработать, так и не сработать; эта операция не зависит от значения, загруженного из p, поэтому нет никаких гарантий о прочитанном значении. Это ясно следует из того, что она помечена признаком memory_order_relaxed.
Иногда нам не нужны издержки, которыми сопровождается перенос зависимости. Мы хотим, чтобы компилятор мог кэшировать значения в регистрах и изменять порядок операций во имя оптимизации кода, а не волновался по поводу зависимостей. В таких случаях можно воспользоваться шаблоном функции std::kill_dependency() для явного разрыва цепочки зависимостей. Эта функция просто копирует переданный ей аргумент в возвращаемое значение, но попутно разрывает цепочку зависимостей. Например, если имеется глобальный массив с доступом только для чтения, и вы используете семантику std::memory_order_consume при чтении какого-то элемента этого массива из другого потока, то с помощью std::kill_dependency() можно сообщить компилятору, что ему необязательно заново считывать содержимое элемента массива (см. пример ниже).
int global_data[] = { ... };
std::atomic<int> index;
void f() {
int i = index.load(std::memory_order_consume);
do_something_with(global_data[std::kill_dependency(i)]);
}
Разумеется, в таком простом случае вы вряд ли вообще будете пользоваться семантикой std::memory_order_consume, но в аналогичной ситуации функцией std::kill_dependency() можно воспользоваться и в более сложной программе. Только не забывайте, что это оптимизация, поэтому прибегать к ней следует с осторожностью и только тогда, когда профилирование ясно продемонстрировало необходимость.
Теперь, рассмотрев основы упорядочения доступа к памяти, мы можем перейти к более сложным аспектам отношения синхронизируется-с, которые проявляются в форме последовательностей освобождений (release sequences).
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК