8.3.1. Распределение элементов массива для сложных операций
Допустим, что программа, выполняющая сложные математические расчеты, должна перемножить две больших квадратных матрицы. Элемент в левом верхнем углу результирующей матрицы получается следующим образом: каждый элемент первой строки левой матрицы умножается на соответственный элемент первого столбца правой матрицы и полученные произведения складываются. Чтобы получить элемент результирующей матрицы, расположенный на пересечении второй строки и первого столбца, эта операция повторяется для второй строки левой матрицы и первого столбца правой матрицы. И так далее. На рис. 8.3 показано, что элемент результирующей матрицы на пересечении второй строки и третьего столбца получается суммированием попарных произведений элементов второй строки левой матрицы и третьего столбца правой.
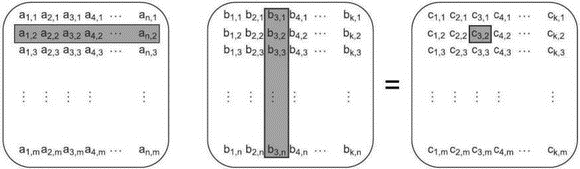
Рис. 8.3. Умножение матриц
Теперь предположим, что матрицы содержат по несколько тысяч строк и столбцов, иначе заводить несколько потоков для оптимизации умножения не имеет смысла. Обычно, если матрица не разрежена, то она представляется большим массивом в памяти, в котором сначала идут все элементы первой строки, потом все элементы второй строки и так далее. Следовательно, для перемножения матриц нам понадобятся три огромных массива. Чтобы добиться оптимальной производительности, мы должны внимательно следить за порядком доступа к данным, а особенно за операциями записи в третий массив.
Существует много способов распределить эту работу между потоками. В предположении, что строк и столбцов больше, чем имеется процессоров, можно поручить каждому потоку вычисление нескольких столбцов или строк результирующей матрицы или даже вычисление какой-то ее прямоугольной части.
В разделах 8.2.3 и 8.2.4 мы видели, что для улучшения использования кэша и предотвращения ложного разделения лучше, когда поток обращается к данным, находящимся в соседних ячейках, а не разбросанным но всей памяти. Если поток вычисляет множество столбцов, то читать ему придётся все значения из первой матрицы и соответственных столбцов второй матрицы, но писать только в назначенные ему столбцы результирующей матрицы. При том, что матрицы хранятся но строкам, это означает, что мы будем обращаться к N элементам первой строки результирующей матрицы, N элементам второй строки и т.д. (N — количество обрабатываемых столбцов). Другие потоки будут обращаться к другим элементам строк, поэтому, чтобы минимизировать вероятность ложного разделения, столбцы, вычисляемые каждым потоком, должны быть соседними, тогда будут соседними и N записываемых элементов в каждой строке. Разумеется, если эти N элементов занимают в точности целое число строк кэша, то ложного разделения вообще не будет, потому что каждый поток работает со своим набором строк кэша.
С другой стороны, если каждый поток вычисляет множество строк, то он должен будет прочитать все значения правой матрицы и значения из соответственных строк левой матрицы, но в результирующую матрицу записывать будет только строки. Поскольку матрицы хранятся но строкам, то поток будет обращаться ко всем элементам N строк. Если поручить потоку вычисление соседних строк, то он окажется единственным потоком, который пишет в эти строки, то есть будет владельцем непрерывного участка памяти, к которому больше никакие потоки не обращаются. Вероятно, это лучше, чем вычисление множества столбцов, потому что ложное разделение, если и может возникнуть, то только для нескольких последних элементов предыдущего и нескольких первых элементов следующего участка. Однако это предположение нуждается в подтверждении путем прямых измерений на целевой платформе.
А как насчет третьего варианта — вычисления прямоугольных блоков матрицы? Можно рассматривать его как комбинацию распределения но столбцам и по строкам. Поэтому шансы на ложное разделение такие же, как при распределении но столбцам. Если выбрать число столбцов так, чтобы минимизировать эту вероятность, то у распределения по блокам будет преимущество в части чтения — исходную матрицу придётся читать не целиком, а только те столбцы и строки, которые соответствуют назначенному потоку прямоугольному блоку. Рассмотрим конкретный пример умножения двух матриц размерностью 1000×1000. Всего в каждой матрице миллион элементов. При наличии 100 процессоров каждый из них сможет вычислить 10 строк, то есть 10 000 элементов. Однако для их вычисления процессору придётся прочитать всю правую матрицу (миллион элементов) плюс 10 000 элементов из соответственных строк левой матрицы, итого — 1 010 000 элементов. С другой стороны, если каждый процессор вычисляет блок 100×100 (те же 10 000 элементов), то нужно будет прочитать значения из 100 строк левой матрицы (100×1000 = 100 000 элементов) и 100 столбцов правой матрицы (еще 100 000). В итоге мы получаем только 200 000 прочитанных элементов, то есть в пять раз меньше по сравнению с первым случаем. Если читается меньше элементов, то сокращается вероятность отсутствия нужного значения в кэше, а, значит, производительность потенциально возрастает.
Поэтому лучше разбить результирующую матрицу на небольшие квадратные или почти квадратные блоки, а не вычислять строки целиком. Конечно, размер блока можно определять на этапе выполнения в зависимости от размерности матриц и числа имеющихся процессоров. Как обычно, если производительность существенна, то важно профилировать разные варианты решения на целевой архитектуре.
Но если вы не занимаетесь умножением матриц, то какую пользу можете извлечь из этого обсуждения? Да просто те же принципы применимы в любой ситуации, где нужно назначать потокам вычисление больших блоков данных. Тщательно изучите все аспекты доступа к данным и выявите потенциальные причины снижения производительности. Не исключено, что ваша задача обладает схожими характеристиками, позволяющими улучшить быстродействие всего лишь за счет изменения способа распределения работы без модификации основного алгоритма.
Итак, мы посмотрели, как порядок доступа к элементам массива может отразиться на производительности. А что можно сказать о других структурах данных?
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК