Выбор вершин со множеством рёбер
Выбор вершин со множеством рёбер
В идеале меш должен содержать грани, которые состоят из только четырех вершин (эти грани обычно именуются quads — четырёхугольники), и у них должны быть относительно одинаковые размеры. Такая конфигурация оптимальна при деформации меша, что часто бывает необходимо в анимации. Конечно, нет ничего действительно ужасного в трехсторонних гранях (tris), но в общих чертах лучше избегать их, поскольку небольшие треугольные грани всё портят при применении модификатора subsurface, заставляя его показывать неприглядную рябь.
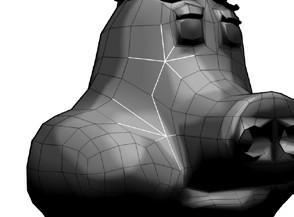
Но даже когда у вас есть меш, состоящий только из четырёхугольников, некоторые вершины являются центром более, чем четырех рёбер. Эти вершины иногда называют полюсами, отсюда и название скриптов в следующих разделах. Если количество рёбер чрезмерное, скажем шесть или больше (как показано в предыдущем скриншоте), такой участок может стать трудным для деформации, и трудным для манипуляций разработчиком модели. В большом и сложном меше эти вершины может быть сложно находить и, следовательно, нам нужно средство выбора таких вершин.
Выбор полюсов
Для того чтобы выбрать вершины с определённого числа шагов, мы можем выполнить следующие шаги:
1. Независимо проверить, что активный объект - это меш.
2. Независимо убедиться, что мы - в режиме объектов.
3. Показать всплывающее меню для ввода минимального количества рёбер.
4. Для каждой вершины:
• Итерация по всем рёбрам, подсчет вхождений вершины
• Если счет - больше или равен минимуму, выбрать вершину
Этот метод - прямой и простой. Функция, которая ответственна за фактическую работу, показана ниже (полный скрипт называется poleselect1.py). Она близко следует нашей схеме. Фактический выбор вершин осуществляется путем присвоения атрибуту вершины sel. Заметим также, что атрибуты v1 и v2 объекта ребра не являются индексами в атрибуте verts нашего меша, а ссылаются на объекты MVert. Вот почему нам нужно извлекать атрибуты index для сравнения.
def poleselect1(me,n=5):
for v in me.verts:
n_edges=0
for e in me.edges:
if e.v1.index == v.index or
e.v2.index == v.index:
n_edges+=1
if n_edges >= n:
v.sel = 1
break
Выбор полюсов, ещё раз
Вы вероятно обратили внимание, что мы повторяли обход списка рёбер по новой для каждой вершины (выделено в предыдущем коде). Это может быть дорого с точки зрения производительности и эта стоимость даже усложнена необходимостью сравнивать индексы, которые нужно извлекать снова и снова. Возможно ли написать более эффективный код, который, тем не менее, останется удобочитаемым? Да, если мы будем следовать этой стратегии:
1. Независимо проверить, что активный объект - это меш.
2. Независимо убедиться, что мы - в режиме объектов.
3. Показать всплывающее меню для ввода минимального количества рёбер.
4. Инициализировать словарь, проиндексированный индексом вершин, который будет содержать счетчики рёбер.
5. Повторять цикл по всем рёбрам (обновлять счет для обеих вершин, на которые ссылается ребро).
6. Повторять цикл по всем элементам словаря (если счет - больше или равен минимуму, выбираем вершину).
Используя эту стратегию, мы просто выполняем две, возможно длительных, итерации ценой памяти, требуемой на хранение словаря (ничто не бесплатно). Увеличение скорости незначительно для небольших мешей, но может быть серьёзным (Я отмечал 1,000-кратное повышение скорости у небольшого меша в 3,000 вершин) для больших мешей, и они - именно тот тип мешей, где кому-нибудь может понадобиться средство, подобное этому.
Наша переделанная функция выбора показана ниже (полный скрипт называется poleselect.py). Сначала отметьте оператор import. Словарь, который мы будем использовать, называется словарь со значением по-умолчанию (default dictionary) и предоставляется модулем Питона collections. словарь по-умолчанию является словарем, который инициализирует отсутствующие элементы при первой ссылке на них. Так как мы хотим увеличивать на 1 значение счетчика каждой вершины, на которую ссылается ребро, мы должны были бы или инициализировать наш словарь нулевыми величинами для каждой вершины в меше заблаговременно, или проверять каждый раз, проиндексирована ли уже вершина, для которой мы хотим увеличить счет, и если нет, инициализировать его. Словарь по умолчанию позволяет забыть о необходимости инициализировать все заранее, и является очень удобочитаемой идиомой.
Мы создаем наш словарь, вызывая функцию defaultdictionary() (функция, возвращающая новый объект, поведение которого настраивается некоторым аргументом, передаваемым в функцию, называется фабрикой в объектно-ориентированных кругах) с аргументом int. Аргумент должен быть функцией, не принимающей никаких аргументов. Встроенная функция int(), которую мы здесь используем, возвращает целую величину, равную нулю, когда вызывается без аргументов. Каждый раз, когда мы обращаемся к нашему словарю по несуществующему ключу, создаётся новый элемент, и его значением будет результат, возвращённый нашей функцией int(), то есть нуль. Существенные строки - те две, где мы увеличиваем счетчик рёбер (выделенная часть следующего кода). Мы могли бы написать это выражение немного другим способом, для иллюстрации, почему нам нужен словарь со значением по-умолчанию:
edgecount[edge.v1.index] = edgecount[edge.v1.index] + 1
Элемент словаря, на который мы ссылаемся с правой стороны выражения, не будет еще существовать всякий раз, когда мы ссылаемся на индекс вершины, с которой мы сталкиваемся впервые. Конечно, мы могли бы проверить это заранее, но это сделало бы код в целом гораздо менее читабельным.
from collections import defaultdict
def poleselect(me,n=5):
n_edges = defaultdict(int)
for e in me.edges:
n_edges[e.v1.index]+=1
n_edges[e.v2.index]+=1
for v in (v for v,c in n_edges.items() if c>=n ):
me.verts[v].sel=1
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
3 Группы вершин и материалы
3 Группы вершин и материалы Сложными мешами бывает трудно манипулировать, когда вершин очень много. В этой главе мы рассмотрим, как мы можем облегчить жизнь конечного пользователя, определяя группы вершины, чтобы пометить их наборы. Мы также изучим несколько видов
Изменение цвета ребер
Изменение цвета ребер Команда редактирования тел SOLIDEDIT дает пользователю возможность перекрашивать ребра трехмерного тела. Для этого команду SOLIDEDIT следует вызывать из падающего меню Modify ? Solid Editing ? Color edges либо щелчком на пиктограммах Color edges на плавающей панели
Копирование ребер
Копирование ребер Команда редактирования тел SOLIDEDIT дает возможность создавать копии ребер трехмерного тела. Для этого команду SOLIDEDIT следует вызывать из падающего меню Modify ? Solid Editing ? Copy edges либо щелчком на пиктограммах Copy edges на плавающей панели инструментов Solid
Массивы вершин
Массивы вершин Если вершин много, то чтобы не вызывать для каждой команду glVertex…(), удобно объединять вершины в массивы, используя командуvoid glVertexPointer(GLint size, GLenum type, GLsizei stride, void *ptr)которая определяет способ хранения и координаты вершин. При этом size определяет число координат
Редактирование вершин
Редактирование вершин Находясь на уровне редактирования Vertex (Вершина), можно изменять форму сплайна, перемещая вершины. Вершины обозначены белыми квадратиками, а начальная вершина – квадратиком желтого цвета. Выделенная вершина имеет красный цвет.Вершины
Интерфейсы с множеством базовых интерфейсов
Интерфейсы с множеством базовых интерфейсов При построении иерархии интерфейсов вполне допустимо создавать интерфейсы, которые оказываются производными от нескольких базовых интерфейсов. Однако напомним, что нельзя строить классы, которые будут производными от
Объекты DataSet с множеством таблиц и объекты DataRelation
Объекты DataSet с множеством таблиц и объекты DataRelation До этого момента во всех примерах данной главы объекты DataSet содержали по одному объекту DataTable. Однако вся мощь несвязного уровня ADO.NET проявляется тогда, когда DataSet содержит множество объектов DataTable. В этом случае вы можете
Операции над множеством для сортированных структур (Set operations on sorted structures)
Операции над множеством для сортированных структур (Set operations on sorted structures) Этот раздел определяет все основные операции над множеством для сортированных структур. Они даже работают с множествами с дубликатами, содержащими множественные копии равных элементов. Семантика
Изменение цвета ребер
Изменение цвета ребер Команда редактирования тел SOLIDEDIT дает пользователю возможность перекрашивать ребра трехмерного тела. Для этого команду SOLIDEDIT следует вызывать из падающего меню Modify ? Solid Editing ? Color edges либо щелчком на пиктограммах Color edges на плавающей панели
Копирование ребер
Копирование ребер Команда редактирования тел SOLIDEDIT дает возможность создавать копииребер трехмерного тела. Для этого команду SOLIDEDIT следует вызывать из падающего меню Modify ? Solid Editing ? Copy edges либо щелчком на пиктограммах Copy edges на плавающей панели инструментов Solid
Изменение цвета ребер
Изменение цвета ребер Команда редактирования тел SOLIDEDIT дает пользователю возможность перекрашивать ребра трехмерного тела. Для этого команду SOLIDEDIT следует вызывать из падающего меню Modify ? Solid Editing ? Color edges либо щелчком на пиктограмме Color edges на плавающей панели
Копирование ребер
Копирование ребер Команда редактирования тел SOLIDEDIT дает возможность создавать копии ребер трехмерного тела. Для этого команду SOLIDEDIT следует вызывать из падающего меню Modify ? Solid Editing ? Copy edges либо щелчком на пиктограмме Copy edges на плавающей панели инструментов Solid
12.5. Моделирование многогранников по координатам вершин
12.5. Моделирование многогранников по координатам вершин В предыдущих разделах рассматривались примеры построения 3D-моделей многогранников, у которых одна из граней или основной формообразующий эскиз (см. пример 12.4) располагается в одной из трех взаимно перпендикулярных
У14.2 Многоугольник с малым числом вершин
У14.2 Многоугольник с малым числом вершин Инвариант класса POLYGON требует, чтобы у каждого многоугольника было, по крайней мере, три вершины; отметим, что функция perimeter не будет работать для пустого многоугольника. Измените определение этого класса так, чтобы он покрывал и