4.7 ВЫДЕЛЕНИЕ ДИСКОВЫХ БЛОКОВ
4.7 ВЫДЕЛЕНИЕ ДИСКОВЫХ БЛОКОВ
Когда процесс записывает данные в файл, ядро должно выделять из файловой системы дисковые блоки под информационные блоки прямой адресации и иногда под блоки косвенной адресации. Суперблок файловой системы содержит массив, используемый для хранения номеров свободных дисковых блоков в файловой системе. Сервисная программа mkfs («make file system» — создать файловую систему) организует информационные блоки в файловой системе в виде списка с указателями так, что каждый элемент списка указывает на дисковый блок, в котором хранится массив номеров свободных дисковых блоков, а один из элементов массива хранит номер следующего блока данного списка.
Когда ядру нужно выделить блок из файловой системы (алгоритм alloc, Рисунок 4.19), оно выделяет следующий из блоков, имеющихся в списке в суперблоке. Выделенный однажды, блок не может быть переназначен до тех пор, пока не освободится. Если выделенный блок является последним блоком, имеющимся в кеше суперблока, ядро трактует его как указатель на блок, в котором хранится список свободных блоков. Ядро читает блок, заполняет массив в суперблоке новым списком номеров блоков и после этого продолжает работу с первоначальным номером блока. Оно выделяет буфер для блока и очищает содержимое буфера (обнуляет его). Дисковый блок теперь считается назначенным и у ядра есть буфер для работы с ним. Если в файловой системе нет свободных блоков, вызывающий процесс получает сообщение об ошибке.
Если процесс записывает в файл большой объем информации, он неоднократно запрашивает у системы блоки для хранения информации, но ядро назначает каждый раз только по одному блоку. Программа mkfs пытается организовать первоначальный связанный список номеров свободных блоков так, чтобы номера блоков, передаваемых файлу, были рядом друг с другом. Благодаря этому повышается производительность, поскольку сокращается время поиска на диске и время ожидания при последовательном чтении файла процессом. На Рисунке 4.18 номера блоков даны в настоящем формате, определяемом скоростью вращения диска. К сожалению, очередность номеров блоков в списке свободных блоков перепутана в связи с частыми обращениями к списку со стороны процессов, ведущих запись в файлы и удаляющих их, в результате чего номера блоков поступают в список и покидают его в случайном порядке. Ядро не предпринимает попыток сортировать номера блоков в списке.
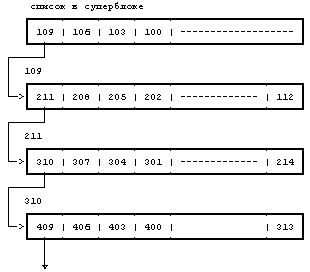
Рисунок 4.18. Список номеров свободных дисковых блоков с указателями
Алгоритм освобождения блока free — обратный алгоритму выделения блока. Если список в суперблоке не полон, номер вновь освобожденного блока включается в этот список. Если, однако, список полон, вновь освобожденный блок становится связным блоком; ядро переписывает в него список из суперблока и копирует блок на диск. Затем номер вновь освобожденного блока включается в список свободных блоков в суперблоке. Этот номер становится единственным номером в списке.
На Рисунке 4.20 показана последовательность операций alloc и free для случая, когда в исходный момент список свободных блоков содержал один элемент. Ядро освобождает блок 949 и включает номер блока в список. Затем оно выделяет этот блок и удаляет его номер из списка. Наконец, оно выделяет блок 109 и удаляет его номер из списка. Поскольку список свободных блоков в суперблоке теперь пуст, ядро снова наполняет список, копируя в него содержимое блока 109, являющегося следующей связью в списке с указателями. На Рисунке 4.20(г) показан заполненный список в суперблоке и следующий связной блок с номером 211.
алгоритм alloc /* выделение блока файловой системы */
входная информация: номер файловой системы
выходная информация: буфер для нового блока
{
do (пока суперблок заблокирован)
sleep (до того момента, когда с суперблока будет снята блокировка);
удалить блок из списка свободных блоков в суперблоке;
if (из списка удален последний блок) {
заблокировать суперблок;
прочитать блок, только что взятый из списка свободных (алгоритм bread);
скопировать номера блоков, хранящиеся в данном блоке, в суперблок;
освободить блочный буфер (алгоритм brelse);
снять блокировку с суперблока;
возобновить выполнение процессов (после снятия блокировки с суперблока);
}
получить буфер для блока, удаленного из списка (алгоритм getblk);
обнулить содержимое буфера;
уменьшить общее число свободных блоков;
пометить суперблок как «измененный»;
return буфер;
}
Рисунок 4.19. Алгоритм выделения дискового блока
Алгоритмы назначения и освобождения индексов и дисковых блоков сходятся в том, что ядро использует суперблок в качестве кеша, хранящего указатели на свободные ресурсы — номера блоков и номера индексов. Оно поддерживает список номеров блоков с указателями, такой, что каждый номер свободного блока в файловой системе появляется в некотором элементе списка, но ядро не поддерживает такого списка для свободных индексов. Тому есть три причины.
Ядро устанавливает, свободен ли индекс или нет, проверяя: если поле типа файла очищено, индекс свободен. Ядро не нуждается в другом механизме описания свободных индексов. Тем не менее, оно не может определить, свободен ли блок или нет, только взглянув на него. Ядро не может уловить различия между маской, показывающей, что блок свободен, и информацией, случайно имеющей сходную маску. Следовательно, ядро нуждается во внешнем механизме идентификации свободных блоков, в качестве него в традиционных реализациях системы используется список с указателями.
Сама конструкция дисковых блоков наводит на мысль об использовании списков с указателями: в дисковом блоке легко разместить большие списки номеров свободных блоков. Но индексы не имеют подходящего места для массового хранения списков номеров свободных индексов.
Пользователи имеют склонность чаще расходовать дисковые блоки, нежели индексы, поэтому кажущееся запаздывание в работе при просмотре диска в поисках свободных индексов не является таким критическим, как если бы оно имело место при поисках свободных дисковых блоков.
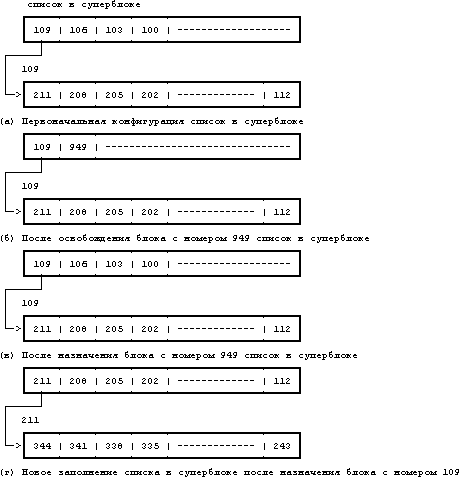
Рисунок 4.20. Запрашивание и освобождение дисковых блоков
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Смещение блоков
Смещение блоков Говорится, что элементу была присвоена позиция, если для свойства position устанавливается значение, отличное от static. Позиционированные элементы порождают позиционированные блоки, положение которых регулируется с помощью следующих четырех свойств.• top –
Сочетание блоков finally и except
Сочетание блоков finally и except Один try-блок может иметь только один блок finally или только один блок except, но не может иметь оба указанных блока одновременно. Поэтому нижеприведенный код вызовет появление ошибок на стадии компиляции. __try { /* Блок контролируемого кода. */} __except
1.3.3 Элементы конструкционных блоков
1.3.3 Элементы конструкционных блоков Как уже говорилось ранее, концепция разработки системы UNIX заключалась в построении операционной системы из элементов, которые позволили бы пользователю создавать небольшие программные модули, выступающие в качестве конструкционных
3.4 ЧТЕНИЕ И ЗАПИСЬ ДИСКОВЫХ БЛОКОВ
3.4 ЧТЕНИЕ И ЗАПИСЬ ДИСКОВЫХ БЛОКОВ Теперь, когда алгоритм выделения буферов нами уже рассмотрен, будет легче понять процедуру чтения и записи дисковых блоков. Чтобы считать дисковый блок (Рисунок 3.13), процесс использует алгоритм getblk для поиска блока в буферном кеше. Если
Редактор блоков
Редактор блоков Редактор блоков вызывается командой BEDIT из падающего меню Tools ? Block Editor или щелчком кнопки мыши на пиктограмме Block Editor на стандартной панели инструментов. При этом сначала загружается диалоговое окно редактирования описания блока Edit Block Definition (рис. 10.6), в
Обзор компоновочных блоков
Обзор компоновочных блоков Утилита Assembly Scout [Разведчик компоновочных блоков), доступная из меню View, предлагает обзор компоновочных блоков, на которые имеются ссылки в проекте. Это средство предлагает информацию в двух панелях, Левая панель предлагает дерево просмотра,
Роль компоновочных блоков .NET
Роль компоновочных блоков .NET Приложения .NET строятся путем связывания произвольного числа компоновочных блоков. С точки зрения упрощенного подхода компоновочный блок является двоичным файлом, включающим свое описание, снабженным номером версии и поддерживаемым средой
Конфигурация общедоступных компоновочных блоков
Конфигурация общедоступных компоновочных блоков Подобно приватным компоновочным блокам, открытый компоновочный блок можно конфигурировать с помощью файла *.config клиента. Конечно, ввиду того, что открытые компоновочные блоки находятся по известному адресу (в структуре
2.2.7.1 . Зеркалирование дисковых областей
2.2.7.1 . Зеркалирование дисковых областей Зеркалирование в INFORMIX-OnLine DS - это дублирование связной дисковой области, выделенной под базу данных, на такую же по размеру область. Исходная область называется первичной, а ее копия - зеркальной. Цели, для которых применяется
8.4. Функции fsync() и fdatasync(): очистка дисковых буферов
8.4. Функции fsync() и fdatasync(): очистка дисковых буферов В большинстве операционных систем при записи в файл данные не передаются на диск немедленно. Вместо этого операционная система помещает их в резидентный кэш-буфер с целью сокращения числа обращений к диску и повышения
Редактор блоков
Редактор блоков Редактор блоков вызывается командой BEDIT из падающего меню Tools ? Block Editor или щелчком на пиктограмме Block Editor на стандартной панели инструментов. При этом сначала загружается диалоговое окно редактирования описания блока Edit Block Definition (рис. 10.5), в котором
Редактор блоков
Редактор блоков Редактор блоков вызывается командой BEDIT из падающего меню Tools ? Block Editor или щелчком на пиктограмме Block Editor на стандартной панели инструментов. При этом сначала загружается диалоговое окно редактирования описания блока Edit Block Definition (рис. 10.17), в котором
Палитры вариаций блоков
Палитры вариаций блоков Загрузка палитр вариаций блоков Block Authoring Palettes осуществляется из редактора блоков щелчком на инструменте Authoring Palettes. Палитры содержат следующие вкладки.Вкладка Parameters включает набор инструментов для определения параметров (рис. 10.20). Рис. 10.20.
16.2. Перенаправление для блоков кода
16.2. Перенаправление для блоков кода Блоки кода, такие как циклы while, until и for, условный оператор if/then, так же могут смешиваться с перенаправлением stdin. Даже функции могут использовать эту форму перенаправления (см. Пример 22-7). Оператор перенаправления <, в таких случаях,
Создание текстовых блоков
Создание текстовых блоков Для перехода в режим ввода и редактирования текста щелкните на кнопке Text (Текст) в разделе Document (Документ) палитры ToolBox (Палитра инструментов). Элементы управления этим инструментом появятся на палитре Info Box (Информационная палитра) (рис. 3.35). Рис.
Трансформация текстовых блоков
Трансформация текстовых блоков Мы можем применять к текстовым блокам те же трансформации, что и к другим фрагментам изображения. Делается это точно так же — выделяем нужный текстовый блок, выбираем в главном инструментарии инструмент "трансформатор" и перемещаем