AMD Bulldozer: ждать ли революции? Андрей Луценко
AMD Bulldozer: ждать ли революции?
Андрей Луценко
Опубликовано 18 октября 2011 года
Анонс новых процессоров AMD Bulldozer («Бульдозер») получился неоднозначным. В комментариях и обзорах царит полный скепсис. Тесты показывают отсутствие значимого повышения эффективности в сравнении с предыдущей архитектурой К10 в пересчете на единичное ядро. Долгожданная архитектура процессоров от AMD вызвала всеобщее разочарование. А зря. Незамеченным осталось главное: в архитектуре процессорных систем AMD применила совершенно новый способ повышения производительности.
Чтобы понять суть произошедших революционных изменений в архитектуре нового процессора AMD, нужно абстрагироваться от результатов конкретных тестов. Никто не спорит — технология сырая. Но не будем с водой выбрасывать младенца: главное — концепция.
Посмотрите на блок-схему новых процессоров AMD. Сразу видно, архитектура ориентирована на связное выполнение двух зависимых вычислительных процессов.
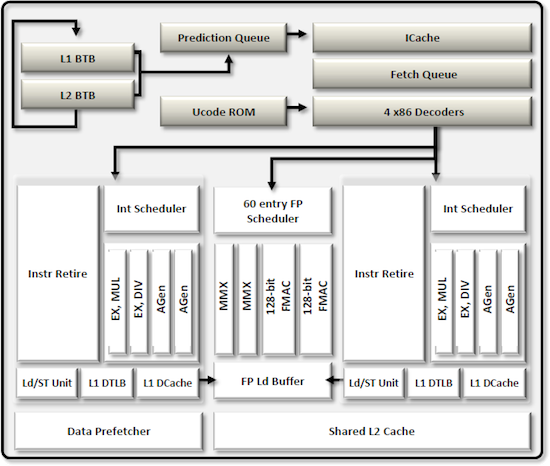
Ранее за производительность боролись тремя способами: наращивали количество ядер в процессоре, повышали число команд, выполняемых за единичный такт, или увеличивали тактовую частоту, упираясь в тепловой пакет на уровне 130-150 Ватт.
"Бульдозер" двинулся другим путём. В борьбу за повышение производительности вступила многопоточная обработка команд. Возникло новое понятие: «тесно связанные вычислительные ядра», или, ещё короче, «процессорный модуль».
И вот с этого места начну поподробнее, хоть и популярно.
Задаче повышения эффективности межпроцессорного взаимодействия до сих пор внимания практически не уделялось; системы межпроцессорных прерываний остаются неизменными на протяжении уже третьего десятилетия. За это время изменилось многое, и главное, на что пока не реагировали разработчики микропроцессорных архитектур, — это совмещение на одном кристалле нескольких процессорных ядер. Нонсенс — процессоры на одном кристалле, а связь между ними организована по внешней шине и по устаревшему протоколу...
Да и программисты наизобретали множество способов облегчить себе жизнь, в то время как эффективность самого вычислительного процесса катастрофически упала.
Их «творения» даже на последних суперскоростных процессорах работают с «тормозами». Почему? Да потому, что оптимальные алгоритмы вычислительных процессов были изменены в угоду удобству поточной индустрии программирования (слово «индус» произошло от слова «индустрия»? или наоборот?).
Базовыми технологиями производства программного продукта на настоящий момент являются объектное программирование и универсальные виртуальные машины.
Следствием такой индустриализации стало использование методов связывания объектов на этапе выполнения и выполнение кода в среде интерпретаторов. Фактически функций компилятора были перенесены в среду исполнения кода. То, что ранее выполнялось один раз на этапе компиляции дистрибутива, теперь выполняется каждый раз во время работы программы у конечного пользователя.
Но не всё так мрачно. Как говорится, «не было счастья, так несчастье помогло». Сейчас весь типовой вычислительный поток состоит из двух компонент, функций компилятора и собственно рабочего тела программы. Этот поток можно разбить на два тесно связанных потока и параллельно выполнять на разных процессорах, но вот беда: архитектура межпроцессорных взаимодействий пока такого не позволяет.
Как бороться с этой бедой? Да очень просто: есть связанные вычислительные потоки, значит, по ассоциации, нужно сделать тесно связанные вычислительные ядра для их эффективной обработки. Бульдозер выбрал этот путь.
Недавно появилась ещё одна область вычислительных задач, на которых явно применяются тесно связанные вычислительные потоки, — виртуализация. В ней используются связанные вычислительные потоки типа «хост-задача».
Да и старая академическая тема спекулятивного выполнения кода сводится к параллельной работе нескольких тесно связанных вычислительных потоков, а как уверяют теоретики, этот метод сулит небывалые уровни производительности в системах с избытком аппаратных ресурсов.
Короче говоря, настало время научить аппаратуру работать со связными вычислительными потоками, это путь к существенному повышению эффективности вычислений. А программистов научить распараллеливать код на тесно связанные потоки.
Подведём итог. Имеется устаревшая технология межпроцессорного взаимодействия, Программисты вовсю явно и неявно используют связные вычислительные потоки. Чего пока не хватает для полного «энергоэффективного» счастья? «Бульдозера», чтобы всё это расчистить под площадку для новой процессорной архитектуры.
Конечно, современное ПО не может реализовать потенциал архитектуры «Бульдозера». Использование зависимых процессорных модулей в независимых вычислительных потоках будет только ухудшать результирующую производительность системы. Но уже анонсирована поддержка данной архитектуры в Windows 8, и это дает, по предварительным оценкам специалистов, около пятнадцати процентов производительности. Даже для такой элементарной оптимизации на уровне диспетчера потоков ОС. Если же заточить под эту архитектуру виртуальные машины и компиляторы, тогда к этим процентам можно смело приписывать ещё один ноль...
Кому-то это утверждение покажется слишком оптимистичным, но с учётом того, что, к примеру, связывание на этапе выполнения требует сначала просмотра таблиц связи и только после этого вычисления адреса требуемой процедуры, то разделение процессов связывания и выполнения как раз и повышает результирующее быстродействие в два раза (минимум).
Кстати, на заре архитектуры К10 бродили слухи о том, что AMD собирается внедрить многопоточность в это ядро, причём эта гипотетичная технология красноречиво называлась «антигипертрединг» (Anti HyperThreading). Теперь понятно, почему. Видимо, на тот момент концепция ещё не созрела, а теперь, похоже, настало её время.
Для реализации всех преимуществ архитектуры «Бульдозера» недостаточно только оптимизаций, обязательно потребуются специализированные системные команды для тонкого управления аппаратурой. Потребуется и дополнительная аппаратура, но это потом, в новых «строительных машинах», которые AMD собирается выпускать каждый год, а пока достаточно и того, что сделано. Удалось бы внедрить оптимизацию на уровне общих кэшей процессорного модуля, и этого уже будет достаточно для начала.
Остается загадкой: изначально авторы данной архитектуры предполагали подобное использование своего детища, или это получилось у них случайно? Типа того, как Колумб плыл в Индию, а открыл Америку?
Будущее покажет, а пока пора застолбить тему несколькими заявками, и пускай у меня с годик эти патенты попылятся...
С Intel у меня получилось угадать. Интересно, получится ли с AMD?
Если и здесь угадаю, то буду менять профессию — пойду в экстрасенсы. Говорят, там больше платят и по телевизору показывают.
К оглавлению
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Глава 12 Радикализм интернет-революции
Глава 12 Радикализм интернет-революции В конце апреля 1963 г. в огромном новом здании под названием Пентагон, в кольце D[56], перед своей пишущей машинкой сидел Дж. Ликлайдер. Он был членом Агентства по перспективным оборонным научно-исследовательским разработкам (ARPA) при
Введение По следам одной революции
Введение По следам одной революции Одно только меня тревожило: как же при таком образе жизни он встретит хорошую девушку? Анна Торвальдс В калейдоскопе революций минувшего века нашлось место и для этой. Почти на излете двадцатого столетия всеобщее внимание в одночасье
Невообразимые последствия воображаемой революции
Невообразимые последствия воображаемой революции Должно быть, тот же ход мыслей, временами заставляющий вспомнить о высокомерии, привел к грубейшей политической ошибке американских дипломатов в разгар иранских акций протеста. Под влиянием комментариев в СМИ и потока
Революции требуются рыцари
Революции требуются рыцари Разумеется, американские дипломаты не могли предугадать, какие последствия будут иметь акции протеста в Иране, и было бы нечестно винить их в том, что “Зеленое движение” оказалось неспособно сместить президента Махмуда Ахмадинежада. Разве
Не заставляйте покупателей ждать
Не заставляйте покупателей ждать У посетителей вашего сайта могут возникнуть вопросы относительно того, что они только что прочитали или увидели. Когда это происходит, сила убеждения ослабевает, поэтому нужно сразу же предоставить все необходимые ответы. Не допускайте,
15. Заключение: жизнь после революции
15. Заключение: жизнь после революции Что мир программного обеспечения будет напоминать, когда переход к открытым текстам закончится?Для того, чтобы исследовать этот вопрос, будет полезно разделить виды программного обеспечения в зависимости от той степени, в которой
АНАЛИЗЫ:Образование будущего: в ожидании революции
АНАЛИЗЫ:Образование будущего: в ожидании революции Современные технологии меняют окружающий мир. За ними почти невозможно угнаться. Постоянное освоение новых инструментов и методов работы - сегодняшняя норма жизни. Проще всего эта нелегкая наука дается, конечно, детям и
Антивирусная защита, Intel и патенты: история длиною в год Андрей Луценко
Антивирусная защита, Intel и патенты: история длиною в год Андрей Луценко Опубликовано 06 октября 2011 года Приблизительно год назад по новостным лентам прошло сообщение о начале процесса покупки фирмой Intel компании McAfee. За туманными заявлениями для
Чего ждать от Firefox 4? Крестников Евгений
Чего ждать от Firefox 4? Крестников Евгений Опубликовано 14 мая 2010 года Об изменении подхода к разработке Firefox стало известно ещё в январе. В Mozilla планируют выпустить Firefox 4 в конце ноября (публичная бета-версия будет доступна уже в июне). От
Голубятня: Осмысление революции Сергей Голубицкий
Голубятня: Осмысление революции Сергей Голубицкий Опубликовано 19 июля 2011 года Мы остановились на младенческих недостатках первого релиза революционного редактора нелинейного монтажа Final Cut Pro X: нехватке тонких настроек в фильтрах и эффектах,
Bobcat и Bulldozer: новые микроархитектуры AMD Олег Нечай
Bobcat и Bulldozer: новые микроархитектуры AMD Олег Нечай Опубликовано 26 августа 2010 года 24 августа 2010 года компания Advanced Micro Deviced (AMD) обнародовала информацию о микроархитектурах нового поколения Bobcat и Bulldozer, которые найдут применение в серийных процессорах
Чего стоит ждать от Windows 8 Андрей Письменный
Чего стоит ждать от Windows 8 Андрей Письменный Опубликовано 01 ноября 2010 года "Самый рискованный продукт Microsoft — это следующий релиз Windows" — заявил глава компании Стив Баллмер. К сожалению, за этими словами не последовало никаких подробностей. Похоже,
Гиперпетля: подробности о грядущей революции наземного транспорта Андрей Васильков
Гиперпетля: подробности о грядущей революции наземного транспорта Андрей Васильков Опубликовано 19 июля 2013 Прототип первой гиперпетли будет представлен 12 августа 2013 года. Однако ещё до официальной презентации стали известны новые подробности об
Чего ждать от Apple в 2013 году: MacBook Air на ARM, приложения Apple TV, новые iPhone и iPad Андрей Письменный
Чего ждать от Apple в 2013 году: MacBook Air на ARM, приложения Apple TV, новые iPhone и iPad Андрей Письменный Опубликовано 06 февраля 2013Не секрет, что компания Apple не любит делиться своими планами на будущее и по возможности никогда не делает этого. Повышенной секретности уже достаточно,