Лекция 17. Работа в IP-сетях
В этой лекции разговор пойдет о программировании баз данных на языке Perl и о средствах взаимодействия с системами управления базами данных, которые имеются в Perl. Основное внимание будет уделено DBI - универсальному интерфейсу доступа к базам данных.
Цель лекции: узнать о средствах работы с базами данных в Perl и научиться применять их в своих программах для доступа к разным типам баз данных - от автономных таблиц до серверов баз данных.
Давно прошли те времена, когда информация хранилась только в простых "плоских" файлах (flat files) в двоичном и текстовом виде. Эволюция систем обработки данных привела к появлению многочисленных баз данных (БД), хранящих информацию в собственных форматах. Основное отличие базы данных от обычного файла с данными заключается в том, что база данных, помимо пользовательской информации, также содержит метаданные, описывающие хранимые в ней сведения. Для работы с большими объемами информации были созданы системы управления базами данных (СУБД), которые теперь работают на серверах баз данных, в настольных и переносных компьютерах - от ноутбуков до карманных компьютеров. Сейчас в большинстве СУБД используются реляционные базы данных, состоящие из таблиц с фиксированным набором колонок (столбцов) и переменным числом строк (записей). Для манипулирования информацией в реляционных базах данных применяется структурированный язык запросов SQL (Structured Query Language). SQL является международным стандартом и поддерживается в большем или меньшем объеме всеми производителями СУБД. Но в последнее время с ними все больше конкурируют объектно-ориентированные и документальные базы данных (например, хранящие информацию в формате XML). Естественно, любая современная система программирования не может обойтись без средств доступа к базам данных. В Perl есть несколько способов работы с базами данных, и мы рассмотрим основные из них: ассоциативные массивы, таблицы-объекты и реляционные базы данных. Примеры работы с базами данных будут основаны на информации о моллюсках, производящих жемчужины (перлы). Каждая запись базы данных будет содержать такие сведения:
[x]. уникальный идентификатор экземпляра (ID) - пятизначное целое число;
[x]. название моллюска по-русски (NAME) - строка длиной до 35 символов;
[x]. латинское название моллюска (LATIN) - строка длиной до 30 символов;
[x]. основные районы обитания (AREA) - строка длиной до 40 символов.
Исходные данные для загрузки в базу данных, которые будут взяты из текстового файла mollusc.txt, имеют такую структуру:
65590;Перловица;Unio pictorum;реки севера России и Скандинавии
56331;Жемчужница речная;Margaritifera margaritifera;север Европы
10616;Морская жемчужница;Pinctada martensii;Японское море
36816;Королевский стромбус;Strombus gigas;Куба
Компактные, простые и быстрые, базы данных в формате Berkeley DB часто используются в операционных системах семейства Unix для хранения системных данных. Существует несколько разновидностей этого формата, которые обобщенно называются файлами DBM (от английского Database Manager). Данные в DBM-файле хранятся в двоичном виде, а логически его можно рассматривать как ассоциативный массив, хранящийся на диске. Средства работы с базами данных этого формата для разных операционных систем можно бесплатно загрузить с сайта www.sleepycat.com. В таких операционных системах, как Linux, FreeBSD или Solaris, Perl часто устанавливается с поддержкой этого формата данных, которая реализована в модуле DB_File. В операционной системе MS Windows этот модуль потребуется установить дополнительно. (О том, как это делается, речь шла в лекции 13. Если используется дистрибутив Active Perl, установка выполняется командой ppm install DB_File.) С помощью этого модуля легко пользоваться базой данных в формате Berkeley DB, потому что с файлом базы данных можно работать как с обычным хэшем. Для этого устанавливается связь между переменной-хэшем и файлом на диске с помощью функции tie(), которой указывается, что для доступа к файлу (например, 'file.db') нужно использовать модуль DB_File. Если указанный файл не существует, он создается. Когда работа с файлом базы данных через хэш-переменную закончена, связь между ними разрывается функцией untie(). Это делается так:
use DB_File; # подключить модуль для работы с Berkeley DB
my %hash; # через этот хэш будет происходить работа с БД
tie %hash, 'DB_File', 'file.db' or die; # установить связь
$hash{'КЛЮЧ'} = 'ЗНАЧЕНИЕ'; # добавить элемент в хэш и БД
untie %hash ; # разорвать связь между хэшем и БД
Формат DBM имеет ограничение, присущее всем ассоциативным массивам: с каждым ключом файла базы данных может ассоциироваться только одно значение. Есть много способов (снова принцип TIMTOWTDI!) обойти это ограничение, и один из них заключается в использовании модуля Storable, который предназначен для организации хранения во внешней памяти массивов, хэшей и других программных объектов. Функция Storable::freeze() "замораживает" данные в двоичном виде, например, перед записью на диск, а функция thaw() "оттаивает" информацию, восстанавливая первоначальную структуру данных. Мы воспользуемся этими функциями для преобразования данных при создании DBM-файла таким образом:
use DB_File; # модули для работы с DBM
use Storable qw(freeze thaw); # и сохранения данных
my %database; # хэш "привязывается"...
tie %database, "DB_File", "mollusc.db" or die; # ...к БД
open my $text, '<', 'mollusc.txt' or die; # файл, откуда
while (my $data = <$text>) { # читаем данные,
chomp($data); # удаляя
# и разбивая строку на поля по разделителю ';':
my ($id, $name, $latin, $area) = split(';', $data);
my %record = ( # заполняем поля записи БД:
ID => $id, # идентификатор экземпляра
NAME => $name, # наименование моллюска
LATIN => $latin, # латинское название
AREA => $area); # ареал обитания
my $serialized = freeze \%record; # "замораживаем"
$database{$id} = $serialized; # и сохраняем запись
}
close $text; # закрываем тестовый файл
untie %database; # и базу данных
После того как база данных DBM создана, мы можем обрабатывать в ней данные, используя функции работы с хэшами, хорошо знакомые нам из лекции 6. Например, так будет выглядеть поиск по ключу:
use DB_File; # модули для работы с DBM
use Storable qw(freeze thaw); # и сохранения данных
my %database; # хэш "привязываем"...
tie %database, "DB_File", "mollusc.db" or die; # ...к БД
my $id = 65590; # ищем "Перловицу"
if (exists $database{$id}) { # по идентификатору
my $serialized = $database{$id}; # считываем и
my %record = %{ thaw($serialized) }; # "размораживаем"
printf "%5d %s %s %s ", # запись БД в хэш
$id, $record{NAME}, $record{LATIN}, $record{AREA};
}
untie %database; # "отвязываем" БД от хэша
# будет выведено: 65590 Перловица Unio pictorum
Для перебора всех записей файла DBM можно пользоваться функциями keys() и each(), а для удаления записи - применить функцию delete().
С широким распространением персональных компьютеров стал популярным формат баз данных, применяемый в "настольных" СУБД dBASE, Clipper и FoxPro, семейство которых обобщенно называется XBase. Базы данных в этом формате хранятся в таблицах с суффиксом DBF (Database File), а для работы с записями такой таблицы широко применяется произвольный доступ к отдельным записям и перебор записей в цикле. (Хотя работать с ними можно также при помощи языка реляционных запросов SQL.) Одно из средств для работы с DBF-таблицами в программах на Perl - это модуль XBase, который можно загрузить из хранилища модулей CPAN. Он предоставляет объектный интерфейс для создания и изменения баз данных в формате XBase. Например, программа создания таблицы DBF будет выглядеть так:
use XBase; # модуль работы с БД в формате DBF
my $table = XBase->create( # метод создания таблицы
"name" => "mollusc.dbf", # имя файла
# имена полей (колонок, столбцов) таблицы:
"field_names" => ["ID", "NAME", "LATIN", "AREA"],
# типы данных (N - число, C - строка, D - дата):
"field_types" => [ "N", "C", "C", "C"],
# максимальные длины полей:
"field_lengths" => [ 5, 35, 30, 45],
# длины дробной части (для чисел):
"field_decimals" => [ 0, undef, undef, undef]
);
$table->close(); # метод закрытия файла БД
Далее потребуется программа добавления данных в созданную таблицу из текстового файла. Например, такая:
use XBase; # модуль работы с БД в формате DBF
my $table = new XBase "mollusc.dbf" # конструктор DBF
or die Xbase->errstr; # обработка ошибок
my $recno = 0; # добавляемые записи нумеруются с нуля
open my $text, '<', 'mollusc.txt' or die; # файл, откуда
while (my $data = <$text>) { # читаем данные,
chomp($data); # удаляя
# и разбивая строку на поля по разделителю ';':
my ($id, $name, $latin, $area) = split(';', $data);
# добавляем запись, указывая поля в порядке создания
$table->set_record($recno, $id, $name, $latin, $area);
$recno++; # и увеличиваем счетчик записей
}
close $text; # закрываем тестовый файл
$table->close(); # и файл базы данных
Модуль XBase предоставляет все необходимые методы для работы с таблицами баз данных. Многие из них основаны на возможности произвольного доступа к любой записи DBF-файла по ее номеру. Например, таким образом можно прочитать, изменить или удалить запись по номеру $record_number:
# считать запись в хэш, с доступом к нему по ссылке:
my $hash_ref = $table->get_record_as_hash($record_number);
# изменить значение поля NAME на
$table->update_record_hash($record_number, 'NAME' => $new);
# пометить запись как логически удаленную
$table->delete_record($record_number);
# восстановить логически удаленную запись
$table->undelete_record($record_number);
По поводу двух последних операций нужно сделать следующее пояснение. Дело в том, что записи в DBF-файле не удаляются физически, а только помечаются как удаленные. "Логически" удаленные записи игнорируются при обработке данных, но существуют в таблице "физически". Поэтому запись, помеченную как удаленная, можно восстановить для дальнейшей обработки. Один из способов прочитать записи таблицы - выбрать их во временный список записей, называемый курсором, откуда последовательно извлекать их в цикле. Это делается так:
my $cursor = $table->prepare_select("NAME", "LATIN", "AREA");
while (my @record = $cursor->fetch) { # прочитать запись
print "@record "; # обработать запись
}
В модуле XBase реализовано много других методов для работы с DBF-файлами и дополняющими их индексными файлами, которые предназначены для организации быстрого поиска записей в таблице.
Но разработчики программного обеспечения давно пришли к выводу, что вместо специфических форматов данных и операций по их обработке (без которых, конечно, иногда нельзя обойтись) гораздо перспективнее применять универсальные подходы, основанные на унифицированном доступе к базам данных на базе языка SQL.
Унификация доступа к реляционным базам данных основана на разделении программного механизма доступа на несколько логических слоев. Первый слой предоставляет программисту стандартный набор операций для подключения к источнику данных и обработки данных из этого источника с помощью запросов на языке SQL. Второй слой отвечает за взаимодействие с конкретными базами данных с учетом их особенностей. Взаимодействие с конкретным источником данных возлагается на драйвер базы данных, который выступает посредником между первым слоем механизма доступа и базой данных, скрывая от программиста технические детали взаимодействия и специфические особенности БД. Драйверы баз данных обычно разрабатывают производители СУБД для своих продуктов. На этих принципах многослойной архитектуры основаны такие широко известные универсальные интерфейсы к базам данных, как ODBC (Open DataBase Connectivity) и JDBC (Java DataBase Connectivity).
Аналогичную архитектуру имеет и DBI (DataBase Interface) - основной интерфейс для доступа к базам данных в Perl. Основным компонентом этого интерфейса является модуль DBI, предоставляющий унифицированные сервисы для взаимодействия с базами данных. Благодаря методам модуля DBI программист получает в свое распоряжение единый инструмент для работы с самыми разными базами данных: и теми, что находятся на этом же компьютере, и теми, что располагаются на удаленном сервере баз данных. Модуль DBI во время работы загружает нужные компоненты, модули драйверов конкретных баз данных (DataBase Driver, DBD), например: DBD::DB2, DBD::InterBase, DBD::mysql, DBD::Oracle, DBD::Sybase. Доступ к любой базе данных при помощи DBI выполняется в несколько этапов. Перечислим основные из них.
1 Соединение с базой данных выполняется конструктором connect() класса DBI, которому передается строка с описанием источника данных, имя пользователя и пароль, а кроме того, дополнительные параметры:
$dbh = DBI->connect($data_source, $user, $password, \%parms);
В описании источника данных (data source) указывается драйвер базы данных и необходимые для его работы параметры. При успешном соединении c СУБД этот метод возвращает манипулятор базы данных (database handler), через который в дальнейшем выполняется взаимодействие с базой данных.
2 Подготовка команды к базе данных выделяется в отдельный этап, поскольку это действие требует значительных ресурсов СУБД. Подготовка команды выполняется методом prepare() манипулятора базы данных, которому передается строка, содержащая команду языка запросов SQL:
$sth = $dbh->prepare($sql_statement);
В команде SQL могут присутствовать слоты (placeholders), в которые при выполнении команды будут подставлены конкретные значения данных. Эта схема похожа на подстановку значений в поледержатели формата отчета. Подготовленная команда доступна через манипулятор команды (statement handler), возвращаемый методом prepare(), и может выполняться многократно.
3 Выполнение команды может производиться несколькими методами. Подготовленную ранее команду выполняет метод командного манипулятора execute(), которому могут передаваться значения для подстановки в выполняемое SQL-предложение:
$sth->execute(@bind_values); # выполнить со списком значений
Или же SQL-команду можно выполнить без предварительной подготовки методом do() манипулятора базы данных:
$dbh->do($sql_statement); # выполнить команду без подготовки
4 Обработка полученных данных может выполняться одной из многочисленных команд, предоставляемых интерфейсом DBI.
5 Отсоединение от базы данных выполняется методом disconnect() манипулятора базы данных, который производит необходимые завершающие действия и освобождает используемые ресурсы:
$dbh->disconnect; # отключиться от БД
Приведенная схема проста и логична, поэтому работа с базами данных через DBI быстро осваивается программистами. Но прежде чем перейти к примерам использования DBI, нужно сделать еще несколько пояснений.
В языке структурированных запросов SQL используется небольшой набор команд, но они позволяют выполнять все необходимые действия над информацией в базе данных. Основные команды SQL: создание базы данных (CREATE), добавление записей (INSERT), их изменение (UPDATE) и удаление (DELETE), а также выборка записей (SELECT) по указанному условию. Изучение языка SQL выходит за рамки этого курса, поэтому в примерах будут применяться только самые простые их формы, и смысл этих команд будет понятен из контекста.
Слоты для подстановки параметров в SQL-команду обозначаются знаками вопроса '?' и выглядят таким образом:
$sth = $dbh->prepare(
'SELECT name, area FROM mollusc WHERE id>? AND id<?');
При выполнении этой команды с параметрами 1000 и 9000 будут выбраны записи со значениями колонки id в заданном диапазоне. При подстановке значений аргументов в команду слоты заполняются слева направо:
$sth->execute(1000, 9000); # подставить числа вместо ?
После подстановки значений будет выполнена команда, означающая "выбрать значения столбцов name и area из таблицы mollusc у тех записей, где значение столбца id больше 1000 и меньше 9000":
SELECT name, area FROM mollusc WHERE id>1000 AND id<9000
Кроме средств выполнения SQL-команд механизм DBI предоставляет множество методов для выборки из базы данных информации в виде массивов или хэшей для более удобной обработки в программе на Perl. Более подробно с ними можно познакомиться, если почитать системную документацию, выведенную по команде
perldoc DBI
Покажем приемы работы с интерфейсом DBI на примере класса доступа к уже знакомым DBF-файлам - модуля DBD::XBase. Этот модуль нужно установить описанным ранее способом прежде, чем работать с базами данных в формате XBase. В первом примере программа создает таблицу базы данных SQL-командой CREATE:
use DBI; # использовать DBI
my $path = '.'; # каталог, где расположены таблицы БД
my $table = 'mollusc'; # DBF-файл
# подсоединиться к БД, используя драйвер DBD::XBase
my $dbh = DBI->connect("dbi:XBase:$path")
or die $DBI::errstr;
# создать таблицу определенной структуры
$dbh->do("CREATE TABLE $table (id INT,
name CHAR(35), latin CHAR(30), area CHAR(45))");
$dbh->disconnect; # отсоединиться от БД
Следующая программа в цикле заполняет созданную таблицу данными из текстового файла, добавляя в нее записи SQL-командой INSERT:
use DBI; # используем DBI
my $path = '.'; # каталог с таблицами БД
my $table = 'mollusc'; # DBF-файл
# подключаемся к БД, используя драйвер DBD::XBase
my $dbh = DBI->connect("dbi:XBase:$path")
or die $DBI::errstr;
# подготовим SQL-команду для многократного выполнения
my $sth = $dbh->prepare("INSERT INTO $table
(id, name, latin, area)
VALUES (?, ?, ?, ?)")
or die $dbh->errstr();
# в цикле читаем строки для загрузки в БД
open my $text, '<', 'mollusc.txt' or die; # файл, откуда
while (my $data = <$text>) { # читаем данные,
chomp($data); # удаляя
# и разбивая строку на поля по разделителю ';':
my ($id, $name, $latin, $area) = split(';', $data);
# добавляем запись, подставляя значения в команду
$sth->execute($id, $name, $latin, $area) or die;
}
close $text; # закрываем тестовый файл
$dbh->disconnect; # отсоединяемся от БД
Далее можно выполнять различные действия с данными в таблице, используя команды SQL, как это сделано в программе, где изменяются значения перечисленных колонок в записи с указанным идентификатором и удаляется запись по уникальному номеру:
use DBI; # использовать DBI
my $path = '.'; # каталог, где расположены таблицы БД
my $table = 'mollusc'; # DBF-файл
# соединиться с БД, используя драйвер DBD::XBase
my $dbh = DBI->connect("dbi:XBase:$path")
or die $DBI::errstr;
# изменить запись с указанным идентификатором,
# заменяя значения перечисленных полей на новые
$dbh->do("UPDATE $table SET name=?,area=? WHERE id=?",
undef, 'Жемчужная пинктада', 'Австралия', 89147) or die;
# удалить запись с идентификатором 93749
$dbh->do("DELETE FROM $table WHERE id=93749") or die;
$dbh->disconnect; # отсоединиться от БД
Для выборки данных из таблицы используется SQL-команда SELECT, в которой можно указывать, данные из каких колонок записи нужно включить в выборку, а также по какому условию отбирать строки таблицы:
use DBI; # использовать DBI
my $path = '.'; # каталог, где расположены таблицы БД
my $table = 'mollusc'; # DBF-файл
# соединиться с БД, используя драйвер DBD::XBase
my $dbh = DBI->connect("dbi:XBase:$path")
or die $DBI::errstr;
# выбрать у всех строк таблицы указанные поля
my $sth =
$dbh->prepare("SELECT name,area FROM $table WHERE id>?")
or die $dbh->errstr;
$sth->execute(1000) or die $sth->errstr(); # выполнить команду
while (my @row = $sth->fetchrow_array) { # и напечатать
print "@row "; # выбранные строки
} # в цикле по одной
$dbh->disconnect; # отсоединиться от БД
Для отображения информации из базы данных можно разработать клиентское приложение с графическим интерфейсом, используя библиотеку Perl/Tk, как это показано на рис. 15.1.
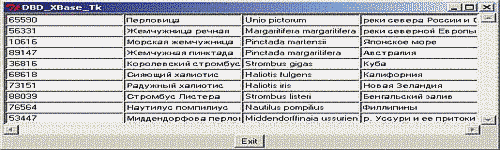
Рис. 15.1.Клиентская программа на Perl/Tk для работы с базой данных
Интерфейс DBI привлекает программистов тем, что время и усилия, потраченные на его изучение, окупаются сторицей, поскольку, научившись работать с одной базой данных, можно применять эти знания при работе со всеми остальными, включая "тяжеловесные" СУБД, которые выполняются на специализированных серверах. Сервер баз данных обычно находится на выделенном компьютере, а взаимодействие с ним строится по технологии "клиент-сервер". Это означает, что сервер принимает запросы, поступающие от пользовательских программ, выполняет указанные в запросе действия по обработке информации в базе данных, а затем отправляет результат обработки клиенту. Для повышения производительности, распределения нагрузки и обеспечения непрерывности работы такие СУБД объединяются в кластеры серверов баз данных, которые могут состоять из большого числа мощных компьютеров. Для работы с конкретной системой управления базой данных потребуется установка драйвера для этой СУБД. В хранилище модулей CPAN найдутся драйверы для всех основных серверов баз данных: IBM DB2, MS SQL Server/Sybase, Oracle, PostgreSQL и многих других. Помимо высокой скорости обработки больших объемов данных, СУБД предоставляют программисту дополнительные возможности по обработке информации. Вот основные из них.
1 Реализация языка манипулирования данными позволяет в запросе использовать объединения нескольких таблиц (JOIN), предусмотренные в стандарте языка SQL.
2 В SQL-запросах можно использовать подзапросы для задания дополнительных условий выборки.
3 Согласованность и непротиворечивость данных при изменении нескольких таблиц достигается при помощи использования механизма транзакций.
4 Часто выполняемые действия над информацией в базе данных можно программировать на встроенном языке базы данных в виде хранимых процедур. Когда такие процедуры вызываются в SQL-команде, то они будут эффективно выполняться на сервере.
5 Для реакции на события, возникающие при обработке информации в базе данных, можно использовать специальные хранимые процедуры - триггеры.
6 Для быстрого поиска и выборки может применяться индексация данных.
7 Доступ к информации в базе данных контролируется системой разграничения доступа СУБД на основе парольной защиты.
Взаимодействие с сервером баз данных с помощью DBI будет показано на примере работы со свободно распространяемой СУБД PostgreSQL Database Server, доступной для всех основных вычислительных платформ, включая Linux и MS Windows. Свежий дистрибутив PostgreSQL всегда можно загрузить с сайта www.postgres.org, а ее установка с помощью программы-мастера не вызовет трудностей даже у начинающего программиста. Далее нужно уже описанным способом установить драйвер DBD::Pg. Кстати, СУБД PostgreSQL демонстрирует еще одно применение языка Perl: она позволяет использовать Perl для программирования хранимых процедур наряду с SQL и рядом других языков.
После установки драйвера можно выполнить предыдущие примеры из этой лекции с использованием СУБД PostgreSQL, внеся в них минимальные изменения. В первую очередь изменятся параметры соединения с базой данных, где мы должны указать другой DBD-драйвер (Pg), имя сервера, имя базы данных, имя пользователя и пароль для доступа к СУБД:
my $host = 'localhost'; # имя сервера
my $dbname = 'postgres'; # имя базы данных
my $user_name = "postgres"; # имя пользователя
my $password = "SECRET"; # пароль пользователя
my $dbh = DBI->connect(
"dbi:Pg:dbname=$dbname;host=$host", # источник данных
$user_name, $password);
После этой модификации программа создания таблицы успешно отработает с СУБД PostgreSQL и создаст в указанной базе данных таблицу 'mollusc'. И другие примеры из этой лекции, использующие интерфейс DBI, также будут работать с PostgreSQL или другой СУБД, после того как их настроят на работу с новым источником данных. Конечно, если применять специфические SQL-команды и другие средства программирования, использующие особенности конкретного сервера баз данных, то адаптация программ для работы с другой СУБД потребует гораздо больше усилий.
С помощью DBI возможно работать не только с традиционными базами данных, но и с файлами в самых разных форматах, в чем можно убедиться, обратившись к хранилищу модулей CPAN. Например, существуют драйверы DBD для работы с электронными таблицами (DBD::Excel), поисковыми системами (DBD::Amazon, DBD::google), иерархическими каталогами LDAP (DBD::LDAP) и универсальными интерфейсами доступа к данным (DBD::ADO, DBD::JDBC, DBD::ODBC).
Часто для преобразования данных из одного формата в другой используется текстовый формат CSV (Сomma-Separated Values), в котором поля данных разделены запятыми, а в первой строке перечислены имена полей. Если установить драйвер DBD::CSV и несколько сопутствующих модулей (DBD::File, SQL::Statement и Text::CSV_XS), то с CSV-файлом можно работать как с таблицей базы данных, что часто бывает очень удобно.
Для преобразования данных также можно использовать модуль DBD::RAM, позволяющий создавать в оперативной памяти таблицы базы данных и импортировать в них информацию из различных источников данных, например: INI-файлы, файлы в формате XML, данные в формате CSV, записи с фиксированными полями и даже каталоги с MP3-композициями. Затем эти таблицы можно обрабатывать с помощью SQL-команд, после чего экспортировать в исходный или другой формат.
При разработке информационных систем средства доступа к базам данных составляют лишь один из уровней программного комплекса. Для работы с данными сложной структуры часто создают специальный класс, за объектным интерфейсом которого от пользователя скрываются конкретный формат хранения данных и возможные преобразования. Если потребуется перейти на хранение информации в другой базе данных, в этом классе изменится только реализация методов доступа к данным, а использующие этот класс программы останутся неизменными. Подобные приемы повышают гибкость программной системы и облегчают ее модификацию.
Работа с базами данных - это будничный труд большинства программистов. Язык Perl помогает им в этом, предоставляя удобные средства доступа ко всем распространенным СУБД, настольным базам данных и многим экзотическим источникам данных.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
11.21. Другая информация о сетях
11.21. Другая информация о сетях В этой главе мы сфокусировали внимание на именах узлов, IP-адресах, именах и номерах портов служб. Если же обобщить полученную информацию, мы увидим, что существует четыре типа данных (имеющих отношение к сетям), которые могут понадобиться
4.14 Уровни в сетях 802
4.14 Уровни в сетях 802 Ознакомимся со взглядом IEEE на сетевой мир. С появлением локальных сетей 802 IEEE разделил сетевой уровень 2 (уровень связи данных) на два подуровня (см. рис. 4.15). Рис. 4.15. Уровни для локальных сетей 802Подуровень MAC обеспечивает правила доступа к носителю —
Продвижение в социальных сетях
Продвижение в социальных сетях Социальные сети не только прочно вошли в нашу жизнь, но и стали важным этапом развития Интернета в целом.Благодаря тому что социальные сети имеют огромную популярность и способны привлекать все больше людей, они обладают большим
10 советов тем, кто собирается открыть корпоративные аккаунты в социальных сетях
10 советов тем, кто собирается открыть корпоративные аккаунты в социальных сетях 1. Определитесь с какой целью вы собираетесь работать — от лица компании или представлять себя как специалиста в сетях.2. В 9 случаях из 10 работа в соцсетях ведет к повышению узнаваемости
10 советов о подаче информации в социальных сетях
10 советов о подаче информации в социальных сетях 1. Возможно это плохая новость для smm-специалистов, но информацию в разных сетях следует размещать разную. И вести себя с читателями разных сетей соответственно придется так, как принято в сообществе, в которое вы
10 советов для новичков или тех, кто хочет обновить свои страницы в сетях
10 советов для новичков или тех, кто хочет обновить свои страницы в сетях 1. Когда вы наполнили аккаунт всей необходимой информацией, можно приступить к ее раскрутке. К этому моменту на странице будет достаточно официальной, полезной и интересной информацией. Теперь
Глава 7. Настройте рекламную кампанию в сетях контекстной рекламы
Глава 7. Настройте рекламную кампанию в сетях контекстной рекламы Какой вид контекстной рекламы использовать для продвижения своего сайта Контекстная реклама считается одним из самых эффективных инструментов привлечения посетителей на сайт, поскольку реклама
23-й час Использование SQL в локальных и глобальных сетях
23-й час Использование SQL в локальных и глобальных сетях В ходе этого урока мы с вами поговорим о том как использовать SQL в сю-виях реального предприятия ичи локачьной сети компании и как испочьзовать SQL в InternetОсновными на этом уроке будут следующие темы• SQL на уровне
5 способов отследить ссылки на сайты в социальных сетях Олег Нечай
5 способов отследить ссылки на сайты в социальных сетях Олег Нечай Опубликовано 28 февраля 2014 Если вы владелец какого-то ресурса в интернете, то для вас не составит труда отследить, кто и как ссылается на ваш сайт в социальных сетях. Google Analytics и
Способы обмана в мобильных сетях Максим Букин
Способы обмана в мобильных сетях Максим Букин Опубликовано 09 июля 2010 года Практически каждый месяц появляются новые способы мобильного мошенничества. В последнее время активизировались любители рассылать SMS-спам по десяткам тысяч номеров в
Установление идентичности в компьютерных сетях
Установление идентичности в компьютерных сетях В отличие от привыкших доверять друг другу людей, проблема установления идентичности в компьютерных сетях основана не на случайных признаках (например, как выглядит человек, каковы его характерные черты и т. д.). Она
Средства выражения эмоций в сетях
Средства выражения эмоций в сетях Одной из проблем при общении посредством электронной почты является необходимость возможно более точно и в максимально краткой форме донести до собеседника эмоции, которые вы вкладываете в письмо. С этой целью на заре существования
АНАЛИЗЫ: Развод по-русски: Мошенничество в сотовых сетях набирает обороты
АНАЛИЗЫ: Развод по-русски: Мошенничество в сотовых сетях набирает обороты Автор: Родион НасакинНа днях мне пришла эсэмэска (стиль и пунктуация сохранены): «Уважаемый абонент! Ваш номер моб. телефона победил в акции „Легион призов“ на Русском радио! Наберите Нашу конт.