Потоки ввода/вывода и печать

Программы, написанные нами в предыдущих главах, воспринимали информацию только из параметров командной строки и графических компонентов, а результаты выводили на консоль или в графические компоненты. Однако во многих случаях требуется выводить результаты на принтер, в файл, базу данных или передавать по сети. Исходные данные тоже часто приходится загружать из файла, базы данных или из сети.
Для того чтобы отвлечься от особенностей конкретных устройств ввода/вывода, в Java употребляется понятие потока (stream). Считается, что в программу идет входной поток (input stream) символов Unicode или просто байтов, воспринимаемый в программе методами read (). Из программы методами write () или print (), println () выводится выходной поток (output stream) символов или байтов. При этом неважно, куда направлен поток: на консоль, на принтер, в файл или в сеть, методы write () и print () ничего об этом не знают.
Можно представить себе поток как трубу, по которой в одном направлении последовательно "текут" символы или байты, один за другим. Методы read(), write(), print(), println () взаимодействуют с одним концом трубы, другой конец соединяется с источником или приемником данных конструкторами классов, в которых реализованы эти методы.
Конечно, полное игнорирование особенностей устройств ввода/вывода сильно замедляет передачу информации. Поэтому в Java все-таки выделяется файловый ввод/вывод, вывод на печать, сетевой поток.
Три потока определены в классе System статическими полями in, out и err. Их можно использовать без всяких дополнительных определений, что мы и делали на протяжении всей книги. Они называются соответственно стандартным вводом (stdin), стандартным выводом (stdout) и стандартным выводом сообщений (stderr). Эти стандартные потоки могут быть соединены с разными конкретными устройствами ввода и вывода.
Потоки out и err — это экземпляры класса Printstream, организующего выходной поток байтов. Эти экземпляры выводят информацию на консоль методами print (), println () и write (), которые в классе Printstream перегружены около двадцати раз для разных типов аргументов.
Поток err предназначен для вывода системных сообщений программы: трассировки, сообщений об ошибках или просто о выполнении каких-то этапов программы. Такие сведения обычно заносятся в специальные журналы, так называемые log-файлы, а не выводятся на консоль. В Java есть средства переназначения потока. Можно, например, переназначить поток с консоли в файл.
Поток in — это экземпляр класса Inputstream. Стандартно он назначен на клавиатурный ввод с консоли, который выполняется методами read ( ). Класс Inputstream абстрактный, поэтому реально используется какой-то из его подклассов.
Понятие потока оказалось настолько удобным и облегчающим программирование вво-да/вывода, что в Java предусмотрена возможность создания потоков, направляющих символы или байты не на внешнее устройство, а в массив или из массива, т. е. связывающих программу с областью оперативной памяти. Более того, можно создать поток, связанный со строкой типа string, находящейся опять-таки в оперативной памяти. Кроме того, можно создать канал (pipe) обмена информацией между подпроцессами.
Еще один вид потока — поток байтов, составляющих объект Java. Его можно направить в файл или передать по сети, а потом восстановить в оперативной памяти. Эта операция называется сериализацией (serialization) объектов.
Методы организации потоков собраны в классы пакета j ava. io.
Кроме классов, организующих поток, в пакет java.io входят классы с методами преобразования потока, например можно преобразовать поток байтов, образующих целые числа, в поток этих чисел.
Еще одна возможность, предоставляемая классами пакета j ava. io, — слить несколько потоков в один поток.
Итак, в Java есть целых четыре иерархии классов для создания, преобразования и слияния потоков. Во главе иерархии четыре класса, непосредственно расширяющих класс
Obj ect:
? Reader — абстрактный класс, в котором собраны самые общие методы символьного ввода;
? Writer — абстрактный класс, в котором собраны самые общие методы символьного вывода;
? Inputstream — абстрактный класс с общими методами байтового ввода;
? Outputstream — абстрактный класс с общими методами байтового вывода.
Классы входных потоков Reader и Inputstream определяют по три метода ввода:
? read () — возвращает один символ или байт, взятый из входного потока, в виде целого значения типа int; если поток уже закончился, возвращает -1;
? read (char [ ] buf) — заполняет заранее определенный массив buf символами из входного потока; в классе Inputstream массив типа byte [ ] и заполняется он байтами; метод возвращает фактическое число взятых из потока элементов или -1, если поток уже закончился;
? read (char [ ] buf, int offset, int len) - заполняет часть символьного или байтового
массива buf, начиная с индекса offset, число взятых из потока элементов равно len; метод возвращает фактическое число взятых из потока элементов или -1.
Эти методы выбрасывают исключение класса IOException, если произошла ошибка вво-да/вывода.
Четвертый метод, skip(long n), "проматывает" поток с текущей позиции на n символов или байтов вперед. Эти элементы потока не вводятся методами read(). Метод возвращает реальное число пропущенных элементов, которое может отличаться от n, например поток может закончиться.
Текущий элемент потока можно пометить методом mark(int n), а затем вернуться к помеченному элементу методом reset (), но не более чем через n элементов. Не все подклассы реализуют эти методы, поэтому перед расстановкой пометок следует обратиться к логическому методу markSupported(), который возвращает true, если реализованы методы расстановки и возврата к пометкам.
Классы выходных потоков Writer и Outputstream определяют по три почти одинаковых метода вывода:
? write (char [ ] buf) - выводит массив в выходной поток, в классе Outputstream массив
имеет тип byte [ ];
? write (char[] buf, int offset, int len) — выводит len элементов массива buf, начиная с элемента с индексом offset;
? write (int elem) в классе Writer — выводит 16, а в классе Outputstream 8 младших битов аргумента elem в выходной поток.
В классе Writer есть еще несколько методов:
? write (String s) выводит строку s в выходной поток;
? write (String s, int offset, int len) - выводит len символов строки s, начиная
с символа с номером offset;
? Writer append (char c) — добавляет символ к выходному потоку, возвращая ссылку на этот поток;
? Writer append (CharSequence seq) - добавляет последовательность символов к выход
ному потоку;
? Writer append(CharSequence seq, int offset, int len) — добавляет к потоку len символов последовательности seq, начиная с символа с номером offset.
Многие подклассы классов Writer и Outputstream осуществляют буферизованный вывод. При этом элементы сначала накапливаются в буфере, в оперативной памяти, и выводятся в выходной поток только после того, как буфер заполнится. Это удобно для выравнивания скоростей вывода из программы и вывода потока, но часто надо вывести информацию в поток еще до заполнения буфера. Для этого предусмотрен метод flush(), который сразу же выводит все содержимое буфера в поток.
Наконец, по окончании работы с потоком его необходимо закрыть методом close (). Это настолько важно, что классы, обладающие методом close (), должны реализовать интерфейс Closeable. Начиная с седьмой версии Java даже введена специальная форма блока перехвата исключений try{}catch(){} для автоматического выполнения метода close () после завершения блока, нормального или аварийного. При этом автоматически будут закрываться объекты, реализовавшие интерфейс Autocioseabie. Интерфейс Closeable расширяет интерфейс Autocioseabie, поэтому для объектов типа Closeable всегда возможно автоматическое закрытие. Применение этой разновидности блока try() {}catch(){} вы можете увидеть в листинге 23.4.
. Object.
Writer
—BufferedWriter
— CharArrayWriter
— FilterWriter
—OutputStreamWriter— FileWriter
— PipedWriter
— StringWriter —PrintWriter
Reader
-BufFeredReader- LineNumberReader
- CharArrayReader
-FilterReader -PushbackReader
_ InputStreamReader— FileReader
- PipedReader -StringReader
Рис. 23.1. Иерархия классов символьных потоков
E Buffered I n putStream DatalnputStream PushbacklnputStream
Object
— Inputstream-
-File
—FileDescriptor —RandomAccessFile —ObjectStreamClass —ObjectStreamField
?—ByteAray Inputstream
— FilelnputStream
— FilterlnputStream -
— ObjectlnputStream
— PipedlnputStream
— SequencelnputStream
—Outputstream — —StreamT okenizer
— ByteArrayOutputStream
--BufferedOutputStream
— DataOutputStream
— Printstream
— FileOutputStream
— FilterOutputStream-
— ObjectOutputStream
— PipedOutputStream
Рис. 23.2. Классы байтовых потоков
Классы, входящие в иерархии потоков ввода/вывода, показаны на рис. 23.1 и 23.2.
Все классы пакета j ava. io можно разделить на две группы: классы, создающие поток (data sink), и классы, управляющие потоком (data processing).
Классы, создающие потоки, в свою очередь, можно разделить на пять групп:
? классы, создающие потоки, связанные с файлами:
FileReader FileInputStream
FileWriter FileOutputStream
? классы, создающие потоки, связанные с массивами:
CharArrayReader ByteArrayInputStream
CharArrayWriter ByteArrayOutputStream
? классы, создающие каналы обмена информацией между подпроцессами:
PipedReader PipedInputStream
PipedWriter PipedOutputStream
? классы, создающие символьные потоки, связанные со строкой:
StringReader
StringWriter
? классы, создающие байтовые потоки из объектов Java:
Obj ectInputStream Obj ectOutputStream
Слева перечислены классы символьных потоков, справа — классы байтовых потоков.
Классы, управляющие потоком, получают в своих конструкторах уже имеющийся поток и создают новый, преобразованный поток. Можно представлять их себе как "переходное кольцо", после которого идет труба другого диаметра.
Четыре класса созданы специально для преобразования потоков:
FilterReader FilterInputStream
FilterWriter FilterOutputStream
Сами по себе эти классы бесполезны — они выполняют тождественное преобразование. Их следует расширять, переопределяя методы ввода/вывода. Но для байтовых фильтров есть полезные расширения, которым соответствуют некоторые символьные классы. Перечислим их.
Четыре класса выполняют буферизованный ввод/вывод:
BufferedReader BufferedInputStream
BufferedWriter BufferedOutputStream
Два класса преобразуют поток байтов, образующих восемь простых типов Java, в эти самые типы:
DataInputStream
DataOutputStream
Два класса содержат методы, позволяющие вернуть несколько символов или байтов во входной поток:
PushbackReader PushbackInputStream
Два класса связаны с выводом на строчные устройства — экран дисплея, принтер:
PrintWriter PrintStream
Два класса связывают байтовый и символьный потоки:
? InputStreamReader — преобразует входной байтовый поток в символьный поток;
? OutputStreamWriter — преобразует выходной символьный поток в байтовый поток.
Класс StreamTokenizer позволяет разобрать входной символьный поток на отдельные элементы (tokens) подобно тому, как класс stringTokenizer, рассмотренный нами в главе 5, разбирал строку.
Из управляющих классов выделяется класс SequenceInputStream, сливающий несколько потоков, заданных в конструкторе, в один поток, и класс LineNumberReader, "умеющий" читать входной символьный поток построчно. Строки в потоке разделяются символами ' ' и/или ' '.
Особняком стоит класс RandomAccessFile, реализующий прямой доступ к файлу. Он не создает поток байтов или символов, а позволяет непосредственно обратиться к любому байту файла.
Еще один особенный класс Console, не создающий поток, выполняет ввод/вывод, связанный с консолью.
Этот обзор классов ввода/вывода немного проясняет положение, но не объясняет, как их использовать. Перейдем к рассмотрению реальных ситуаций.
Консольный ввод/вывод
Для вывода на консоль мы всегда использовали метод println( ) класса Printstream, никогда не определяя экземпляры этого класса. Мы просто использовали статическое поле out класса System, которое является объектом класса Printstream. Исполняющая система Java связывает это поле с консолью.
Кстати, если вам надоело писать System.out.println(), то вы можете определить новую ссылку на System.out, например:
Printstream pr = System.out;
и писать просто pr.println ( ).
Консоль является байтовым устройством, и символы Unicode перед выводом на консоль должны быть преобразованы в байты. Для символов Latin 1 с кодами 'u0000'— 'u00FF' при этом просто откидывается нулевой старший байт и выводятся байты '0x00'—'0xFF'. Для кодов кириллицы, которые лежат в диапазоне 'u0400'—'u04FF' кодировки Unicode, и других национальных алфавитов производится преобразование по кодовой таблице, соответствующей установленной на компьютере локали. Мы уже обсуждали это в главе 5.
Трудности с отображением кириллицы возникают, если вывод на консоль производится в кодировке, отличной от локали. Именно так происходит в русифицированных версиях MS Windows. Обычно в них устанавливается локаль с кодовой страницей CP1251, а вывод на консоль происходит в кодировке CP866.
В этом случае надо заменить Printstream, который не может работать с символьным потоком, на PrintWriter и "вставить переходное кольцо" между потоком символов Unicode и потоком байтов System.out, выводимых на консоль, в виде объекта класса OutputStreamWriter. В конструкторе этого объекта следует указать нужную кодировку, в данном случае CP866. Все это можно сделать одним оператором:
PrintWriter pw = new PrintWriter(
new OutputStreamWriter(System.out, "Cp866"), true);
Класс PrintWriter буферизует выходной поток. Второй аргумент true его конструктора вызывает принудительный сброс содержимого буфера в выходной поток после каждого выполнения метода println(). Но после выполнения метода print() буфер не сбрасывается! Для сброса буфера после каждого обращения к методу print () надо обращаться к методу flush ( ).
Замечание
Методы класса PrintWriter по умолчанию не очищают буфер, а метод print() не очищает его в любом случае. Для очистки буфера используйте метод flush().
После этого можно выводить любой текст методами класса PrintWriter, которые просто дублируют методы класса PrintStream, и писать, например,
pw.println("3TO русский текст");
как показано в листинге 23.1 и на рис. 23.3.
Следует заметить, что конструктор класса PrintWriter, в котором задан байтовый поток, всегда неявно создает объект класса OutputStreamWriter с локальной кодировкой для преобразования байтового потока в символьный поток.
Ввод с консоли производится методами read() класса Inputstream с помощью статического поля in класса System. C консоли идет поток байтов, полученных из scan-кодов клавиатуры. Эти байты должны быть преобразованы в символы Unicode такими же кодовыми таблицами, как и при выводе на консоль. Преобразование идет по той же схеме — для правильного ввода кириллицы удобнее всего определить экземпляр класса BufferedReader, используя в качестве "переходного кольца" объект класса
InputStreamReader:
BufferedReader br = new BufferedReader(
new InputStreamReader(System.in, "Cp866"));
Класс BufferedReader переопределяет три метода read () своего суперкласса Reader. Кроме того, он содержит метод readLine ( ) .
Метод readLine( ) возвращает строку типа String, содержащую символы входного потока, начиная с текущего и заканчивая символом ' ' и/или ' ' . Эти символы-разделители не входят в возвращаемую строку. Если во входном потоке нет символов, то возвращается null.
В листинге 23.1 приведена программа, иллюстрирующая перечисленные методы консольного ввода/вывода. На рис. 23.3 показан вывод этой программы.
Листинг 23.1. Консольный ввод/вывод
import java.io.*; class PrWr{
public static void main(String[] args){ try{
BufferedReader br = new BufferedReader(
new InputStreamReader(System.in, "Cp866"));
PrintWriter pw = new PrintWriter(
new OutputStreamWriter(System.out, "Cp866"), true);
String s = "Это строка с русским текстом"; System.out.println("System.out puts: " + s);
pw.println("PrintWriter puts: " + s);
int c = 0;
pw.println("Посимвольный ввод:");
while ((c = br.read()) != -1) pw.println((char)c);
pw.println("ПострочныIЙ ввод:") ;
do{ s = br.readLine();
pw.println(s);
}while(!s.equals("q"));
}catch(Exception e){
System.out.println(e);
}
}
}
Поясним рис. 23.3. Первая строка выводится потоком System.out. Как видите, кириллица выводится неправильно. Следующая строка предварительно преобразована в поток байтов, записанных в кодировке CP866.
Затем после текста "Посимвольный ввод:" с консоли вводятся символы "Россия" и нажимается клавиша <Enter>. Каждый вводимый символ отображается на экране — операционная система работает в режиме так называемого "эха". Фактический ввод с консоли начинается только после нажатия клавиши <Enter>, потому что клавиатурный ввод буферизуется операционной системой. Символы сразу после ввода отображаются по одному на строке. Обратите внимание на две пустые строки после буквы я. Это выведены символы ' ' и ' ', которые попали во входной поток при нажатии клавиши <Enter>. У них нет никакого графического начертания (glyph).
Потом нажата комбинация клавиш <Ctrl>+<Z>. Она отображается на консоль как "AZ" и означает окончание клавиатурного ввода, завершая цикл ввода символов. Коды этих клавиш уже не попадают во входной поток.
Далее после текста "Построчный ввод:" с клавиатуры набирается строка "Это строка" и, вслед за нажатием клавиши <Enter>, заносится в строку s. Затем строка s выводится обратно на консоль.
Для окончания работы набираем q и нажимаем клавишу <Enter>.
 Рис. 23.3. Консольный ввод/вывод
Рис. 23.3. Консольный ввод/вывод
Форматированный вывод
На технологию Java традиционно переходит очень много программистов, прежде писавших программы на языке С. Им очень не хватает функции printf(), позволяющей самому программисту как-то оформить вывод информации: задать количество цифр при выводе вещественных чисел, точно указать количество пробелов между данными. Начиная с JDK 1.5 методы printf(), очень похожие на одноименные функции языка С, появились в классах Printstream и PrintWriter. Кроме них, в эти классы введены методы format (), выполняющие те же действия. Последние методы заимствованы из класса Formatter, находящегося в пакете j ava. util и специально предназначенного для форматирования.
Заголовки методов форматированного ввода/вывода класса Printstream выглядят так:
Printstream format(Local l, String format, Object ... args);
Printstream format(String format, Object ... args);
Printstream printf(Local l, String format, Object ... args);
Printstream printf(String format, Object ... args);
В классе PrintWriter такие же методы возвращают ссылку на свой экземпляр класса
PrintWriter.
Как видите, при форматировании эти методы могут учесть локальные установки даты, времени, денежных единиц, взятые из объекта класса Locale. Если данный аргумент отсутствует, то соответствующие установки будут взяты из локали по умолчанию.
Строка символов format описывает шаблон для вывода данных, перечисленных в следующих аргументах метода, а также содержит надписи, которые должны появиться на консоли. Например, тот же самый вывод на консоль, который мы до сих пор делали методом
System.out.println("x = " + x + ", y = " + y);
можно сделать методом
System.out.printf("x = %d, y = %d ", x, y);
В строке формата мы пишем поясняющий текст "x = , y = ", который будет просто выводиться на консоль. В текст вставляем спецификации формата "%d". На место этих спецификаций во время вывода будут подставлены значения данных, перечисленных в следующих аргументах метода. Вместо первой спецификации появится значение первой переменной в списке, т. е. х, вместо второй — значение второй переменной, в нашем примере это переменная y, и т. д. Если знак процента надо вывести, а не понимать как начало спецификации, то его следует удвоить, например:
System.out.printf(,,Увеличение на %d%% процентов^", х);
Если спецификаций окажется больше, чем данных в списке, то будет выброшено исключение класса MissingFormatArgumentException, если меньше, то последние данные, для которых "не хватило" спецификаций, просто не станут выводиться.
Если нужно изменить порядок вывода, то в спецификации можно явно написать порядковый номер выводимого аргумента, завершив его знаком доллара: %i$d, %2$d, %3$d. Например, если написать
System.out.printf("x = %2$d, y = %1$d ", x, y);
то на консоль сначала будет выведено значение переменной y, а потом значение переменной x.
Можно несколько раз вывести одно и то же значение, например два раза вывести значение второй переменной:
System.out.printf("x = %2$d, y = %2$d ", x, y);
Каждая спецификация начинается со знака процента, а заканчивается одной или двумя буквами a, A, b, B, c, C, d, e, E, f, g, G, h, H, n, o, s, S, t, T, x, X, показывающими тип выводи
мого данного. Буква d, использованная нами в предыдущем примере, показывает, что соответствующее этой спецификации данное следует выводить на консоль как целое число в десятичной системе счисления.
Как показано ранее, после знака процента можно указать порядковый номер аргумента, завершенный знаком доллара. Между знаком процента или доллара и буквой, обозначающей тип и завершающей спецификацию, могут находиться дополнительные символы, число и вид которых зависит от спецификации.
Спецификации вывода целых чисел
Для спецификации d можно задать количество позиций, выделяемых для выводимого данного, например %i0d или %2$i0d. Если целое число невелико и займет меньше места, то оно будет прижато к правому краю поля из 10 позиций, а слева останутся пробелы. Если оно велико, содержит больше 10 цифр, то поле будет расширено так, чтобы все число было выведено. В спецификации сразу же после знака процента или доллара можно поставить дефис: %-i0d, %2$-i0d, и тогда число будет прижиматься к левому краю отведенного для него поля, а пробелы останутся справа.
Если вместо пробелов вы хотите вывести слева незначащие нули, то напишите нуль в спецификации: %0i0d, %2$0i0d.
В больших числах группы по три цифры: тысячи, сотни тысяч, часто разделяются пробелами или запятыми. Такую разбивку можно указать запятой %,i0d, %2$,i0d, но этот элемент форматирования сильно зависит от локали, и надо проверить, как он действует на вашей машине.
Положительное число обычно выводится без начального плюса. Если поставить знак плюс в спецификации, %+i0d, %2$+i0d, то положительные числа будут выведены с плюсом, а отрицательные по-прежнему с минусом. Если вместо плюса оставить один пробел, то знак плюс у положительного числа не будет выводиться, но вместо него останется пробел. Это удобно для формирования колонок чисел.
Целое число выводится по спецификации d в десятичной системе счисления. Спецификация o выводит целое число в восьмеричной системе счисления, спецификации x и X — в шестнадцатеричной системе счисления. Если написана малая буква x, то шестнадцатеричные цифры будут записаны малыми буквами, например d2cfi0, а если написана заглавная буква X — то заглавными, D2CFi0.
В спецификациях o, x, X знак плюс и пробел можно указывать только для данных типа Biginteger, а запятую вообще нельзя писать. Зато в этих спецификациях можно написать "решетку" (#). Тогда восьмеричное число будет выведено с начальным нулем, а шестнадцатеричное — с начальными символами 0x или 0X, как это принято при записи констант Java.
Спецификации вывода вещественных чисел
Для вывода вещественных чисел предназначены спецификации a, a, e, e, f, g, g. Спецификация f выводит вещественное число в десятичной системе счисления с фиксированной точкой, спецификации e и E — с плавающей точкой. Две последние спецификации отличаются только регистром выводимой буквы E. Спецификации g, G универсальны — они выводят короткие числа с фиксированной точкой, а длинные — с плавающей точкой.
Во всех этих спецификациях можно использовать те же символы, что и при выводе целых чисел. Дополнительно можно записывать точность вывода числа — количество цифр в его дробной части. Точность записывается после точки в конце спецификации, например %.8f, %2$.6e, %+i0.5E, %2$-i0.4g, %2.5G. По умолчанию точность равна 6 цифрам.
Спецификации a, A выводят число в шестнадцатеричной системе счисления с плавающей точкой. В этих спецификациях точность записывать нельзя.
Спецификация вывода символов
Спецификация с выводит один символ в кодировке Unicode. В данной спецификации можно записывать только ширину поля и дефис для вывода символа в левой позиции этого поля. Например: %c, %2$6c, %-i0c, %2$-3с.
Спецификации вывода строк
Спецификации s, S выводят строку символов. Соответствующий аргумент должен быть ссылкой на объект, которая преобразуется в строку своим методом tostring(). Если строка пуста, то выводится слово null. В этих спецификациях можно записывать только ширину поля и дефис для вывода строки в левой позиции этого поля. Если спецификация записана заглавной буквой s, то символы строки преобразуются в верхний регистр. Например: %s, %2$6s, %-i0s, %2$-50s.
Спецификации вывода логических значений
Спецификации b, в выводят логическое значение словом true или false. В данных спецификациях можно записывать только ширину поля и дефис для вывода слов в левой позиции этого поля. Если спецификация записана заглавной буквой B, то слова выводятся заглавными буквами: true, false. Например: %b, %2$6B, %-i0b, %2$-3b.
Спецификации вывода хеш-кода объекта
Спецификации h, H выводят хеш-код объекта в шестнадцатеричной системе счисления. Если написана буква h, то шестнадцатеричные цифры выводятся малыми буквами, если написана буква H, то заглавными буквами. В этой спецификации можно задавать только ширину поля и дефис для вывода кода в левой позиции этого поля. Например: %h, %2$6H, %-i0h, %2$-3h.
Спецификации вывода даты и времени
Спецификации t, T выводят дату и время по правилам заданной локали. Дата и время для вывода по этим спецификациям должны быть заданы в секундах и миллисекундах в виде целого числа типа long или объекта класса Long, а также в виде объекта классов
Calendar или Date.
После буквы t или буквы T обязательно должна быть записана еще одна буква, указывающая объем выводимой информации: дата и время, только дата, только время, только часы и т. д. Например, метод
System.out.printf(,,Местное время: %tT ", Calendar.getInstance() );
выведет только текущее время, без даты, в местной локали. В русской локали получим запись вида 12:36:14.
Метод
System.out.printf(,,Сейчас %tH часовйя", Calendar.getInstance() );
выведет только часы, например 12. Спецификация %tM выведет только минуты, а спецификация %tS — только секунды.
Мы можем отформатировать время по-своему, написав, например, метод
System.out.printf(,,Местное время: %1$tH часов, %1$tM минут ",
Calendar.getInstance());
Кроме этого, по спецификации %ts можно получить время в секундах, начиная с 1 января 1970 года (Epoch), а по спецификации %tQ — в миллисекундах, отсчитанных от той же даты.
Дату в виде 10/24/11 можно получить по спецификации %tD, а в виде 2011-10-24 — по спецификации %tF. Ни та, ни другая форма не соответствует российским стандартам. Привычный для нас вид представления даты — 24.10.11 — можно получить методом
System.out.printf("Сегодня %1$td.%1$tm.%1$ty ", Calendar.getinstance());
Спецификация %td дает день месяца всегда двумя цифрами, например первый день месяца будет записан с начальным нулем: 01. Если вы хотите записать первые дни месяца одной цифрой, то используйте спецификацию %te.
Спецификация %ty записывает только две последние цифры года. Полная запись года четырьмя цифрами получится по спецификации %tY.
Название месяца, записанное полным словом, можно получить по спецификации %tB, а записанное сокращением из первых трех букв — по спецификации %tb или %th.
День недели полным словом можно получить по спецификации %tA, а сокращением из первых трех букв — по спецификации %ta.
Наконец, день недели, дату и время полностью можно получить по спецификации %tc.
Класс Console
Как видно из приведенного ранее текста, связь с консолью средствами классов-потоков весьма сложна. Начиная с Java SE 6 в пакет j ava. io добавлен класс Console, облегчающий эту задачу.
Поскольку программа связывается с той консолью, в которой запущена виртуальная машина Java, единственный объект класса Console создается статическим методом
console () класса System, например:
Console cons = System.console();
Метод возвращает null, если виртуальная машина Java запущена не из консоли, а каким-нибудь приложением. Поэтому обычный метод получения ссылки на объект cons таков:
Console cons;
if ((cons = System.console()) != null){
// Работаем с консолью...
}
Чтение строки символов с консоли выполняется методами
public String readLine();
public String readLine(String format, Object... args);
Ввод пароля можно выполнить методами
public char[] readPassword();
public char[] readPassword(String format, Object... args);
Эти методы возвращают null, если ввод завершен, например, нажатием <Ctrl>+<D> в UNIX или <Ctrl>+<Z> в MS Windows.
Еще один метод,
Reader reader();
возвращает ссылку на объект типа Reader, с помощью которого можно выполнить потоковый ввод символов с консоли.
Для вывода информации на консоль есть метод
Console printf(String format, Object... args);
Кроме того, можно получить ссылку на объект класса PrintWriter:
PrintWriter writer();
Наконец, очистку буфера консоли выполняет метод
void flush();
Упражнения
1. Известная программа "Алиса" отвечает на задаваемые ей вопросы, просто переставляя порядок слов в вопросе. Напишите свой вариант этой программы для консоли.
2. Запишите метод вывода даты в виде "25 декабря 2011 года", записывающем название месяца в правильном падеже.
Файловый ввод/вывод
Поскольку файлы в большинстве современных операционных систем понимаются как последовательность байтов, для файлового ввода/вывода создаются байтовые потоки с помощью классов Fileinputstream и FileOutputStream. Это особенно удобно для бинарных файлов, хранящих байт-коды, архивы, изображения, звук.
Но очень много файлов содержат тексты, составленные из символов. Несмотря на то что символы могут храниться в кодировке Unicode, эти тексты чаще всего записаны в байтовых кодировках. Поэтому и для текстовых файлов можно использовать байтовые потоки. В таком случае со стороны программы придется организовать преобразование байтов в символы и обратно.
Чтобы облегчить это преобразование, в пакет java.io введены классы FileReader и FileWriter. Они организуют преобразование потока: со стороны программы потоки символьные, со стороны файла — байтовые. Это происходит потому, что данные классы расширяют классы InputStreamReader и OutputStreamWriter соответственно, значит, содержат "переходное кольцо" внутри себя.
Несмотря на различие потоков, использование классов файлового ввода/вывода очень похоже.
В конструкторах всех четырех файловых потоков задается имя файла в виде строки типа string или ссылка на объект класса File. Конструкторы не только создают объект, но и отыскивают файл и открывают его. Например:
FileInputStream fis = new FileInputStream("PrWr.java");
FileReader fr = new FileReader("D:jdk1.7.0srcPrWr.java");
При неудаче выбрасывается исключение класса FileNotFoundException, но конструктор класса FileWriter выбрасывает более общее исключение IOException.
После открытия выходного потока типа FileWriter или FileOutputStream содержимое файла, если он был не пуст, стирается. Для того чтобы можно было делать запись в конец файла, и в том и в другом классе предусмотрен конструктор с двумя аргументами. Если второй аргумент равен true, то происходит дозапись в конец файла, если false, то файл заполняется новой информацией. Например:
FileWriter fw = new FileWriter("ch23.txt", true);
FileOutputStream fos = new FileOutputStream("D:samples ewfile.txt");
Внимание!
Содержимое файла, открытого на запись конструктором с одним аргументом, стирается. Сразу после выполнения конструктора можно читать файл:
fis.read(); fr.read();
или записывать в него:
fos.write((char)c); fw.write((char)c);
По окончании работы с файлом поток следует закрыть методом close ().
Преобразование потоков в классах FileReader и FileWriter выполняется по кодовым таблицам установленной на компьютере локали. Для правильного ввода кириллицы надо применять FileReader, а не FileInputStream.
Если файл содержит текст в кодировке, отличной от локальной кодировки, то придется вставлять "переходное кольцо" вручную, как это делалось для консоли, например:
InputStreamReader isr = new InputStreamReader(fis, "KOI8 R"));
Байтовый поток fis определен ранее.
Получение свойств файла
В конструкторах классов файлового ввода/вывода, описанных в предыдущем разделе, указывалось имя файла в виде строки. При этом оставалось неизвестным, существует ли файл, разрешен ли к нему доступ, какова длина файла.
Получить такие сведения можно от предварительно созданного экземпляра класса File, содержащего сведения о файле. В седьмой версии Java методы работы с файлами были переработаны и составили библиотеку классов и интерфейсов NIO2. Речь о ней пойдет в следующем разделе.
В конструкторе класса File,
File(String filename);
указывается путь к файлу или каталогу, записанный по правилам операционной системы. В UNIX имена каталогов разделяются наклонной чертой /, в MS Windows — обратной наклонной чертой , в Apple Macintosh — двоеточием :. Этот символ содержится в системном свойстве file.separator (см. рис. 6.2). Путь к файлу предваряется префиксом. В UNIX это наклонная черта, в MS Windows — три символа: буква раздела диска, двоеточие и обратная наклонная черта. Если префикса нет, то путь считается относительным и к нему прибавляется путь к текущему каталогу, который хранится в системном свойстве user.dir.
Конструктор не проверяет, существует ли файл с заданным именем, поэтому после создания объекта класса File следует это проверить логическим методом exists ().
Класс File содержит около сорока методов, позволяющих узнать и изменить различные свойства файла или каталога.
Прежде всего, логическими методами isFile(), isDirectory() можно выяснить, является ли путь, указанный в конструкторе, путем к файлу или каталогу.
Для каталога можно получить его содержимое — список имен файлов и подкаталогов — методом list(), возвращающим массив строк string [ ]. Можно получить такой же список в виде массива объектов класса File[] методом listFiles(). Можно выбрать из списка только некоторые файлы, реализовав интерфейс FileNameFilter и обратившись к методу list(FileNameFilter filter) или listFiles(FileNameFilter filter).
Если каталог с указанным в конструкторе путем не существует, его можно создать логическим методом mkdir(). Этот метод возвращает true, если каталог удалось создать. Логический метод mkdirs () создает еще и все несуществующие каталоги, указанные в пути.
Пустой каталог удаляется методом delete ().
Для файла можно получить его длину в байтах методом length (), время последней модификации в секундах с 1 января 1970 года методом lastModified(). Если файл не существует, эти методы возвращают нуль. Время последней модификации можно изменить методом setLastModified(long time).
Логические методы canRead ( ), canWrite ( ), canExecute () показывают права доступа к файлу или каталогу, а несколько методов — setReadable(), setWritable(), setExecutable() — позволяют установить их для всех пользователей или только для владельца файла или каталога.
Файл можно переименовать логическим методом renameTo (File newName ) или удалить логическим методом delete (). Эти методы возвращают true, если операция прошла удачно.
Если файл с указанным в конструкторе путем не существует, его можно создать логическим методом createNewFile(), возвращающим true, если файл не существовал, и его удалось создать, и false, если файл уже существовал.
Статическими методами
createTempFile(String prefix, String suffix, File tmpDir); createTempFile(String prefix, String suffix);
можно создать временный файл с именем prefix и расширением suffix в каталоге tmpDir или каталоге, указанном в системном свойстве java.io.tmpdir (см. рис. 6.2). Имя prefix должно содержать не менее трех символов. Если suffix == null, то файл получит суффикс .tap.
Перечисленные методы возвращают ссылку типа File на созданный файл. Если обратиться к методу deleteOnExit (), то по завершении работы JVM временный файл будет уничтожен.
Несколько методов getXxx () возвращают имя файла, имя каталога и другие сведения о пути к файлу. Эти методы полезны в тех случаях, когда ссылка на объект класса File возвращается другими методами и нужны сведения о файле.
Методы getTotalSpace (), getFreeSpace(), getUsableSpace() возвращают сведения о размерах пространства на разделе диска в виде длинного числа типа long.
Наконец, метод toURi () возвращает путь к файлу в форме адреса URI.
В листинге 23.2 показан пример использования класса File, а на рис. 23.4 — начало вывода этой программы.
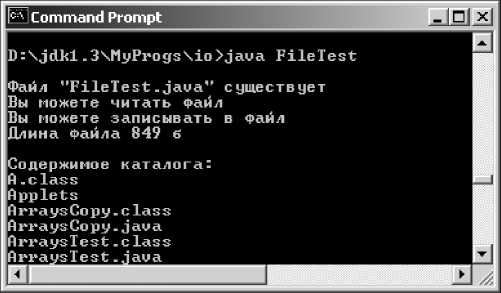 Рис. 23.4. Свойства файла и начало вывода каталога
Рис. 23.4. Свойства файла и начало вывода каталога
Листинг 23.2. Определение свойств файла и каталога
import java.io.*;
class FileTest{
public static void main(String[] args) throws IOException{
PrintWriter pw = new PrintWriter(
new OutputStreamWriter(System.out, nCp866"), true);
File f = new File("FileTest.java");
pw.println();
"" + f.getName() + "" " +
(f.exists()?"":"не ") + "существует"); pw.println("Вы " + (f.canRead()?"":"He ") + "можете читать файл"); pw.println("Вы " + (^сапМг^е()?,,,,:"не ") + "можете записывать в файл"); pw.println(,,Длина файла " + f.length() + " б"); pw.println();
File d = new File("D:jdk1.3MyProgs"); pw.println("Содержимое каталога:"); if (d.exists() && d.isDirectory()){
String[] s = d.list(); for (int i = 0; i < s.length; i++) pw.println(s[i]);
}
}
}
Работа с файлом средствами NIO2
Для того чтобы оптимизировать работу с файлами, начиная с седьмой версии Java введены интерфейсы и классы, записанные в пакеты j ava. nio. file, j ava. nio .file. attribute и j ava. nio .file. spi. Они позволяют в максимальной степени использовать особенности и средства файловой системы, в которой хранятся файлы. Для этого написан абстрактный класс Filesystem, хранящий свойства файловой системы. Полную реализацию всех методов этого класса для конкретной файловой системы предоставляют статические методы класса FileSystems. Одна из файловых систем считается файловой системой по умолчанию, ссылку на нее можно получить статическим методом getDefault() класса
FileSystems.
Свойства отдельного файла собраны в абстрактном классе Path, конкретную реализацию которого можно получить по такой же схеме статическими методами get () класса Paths, если мы хотим получить свойства файла в файловой системе по умолчанию, или методом getPath () класса Filesystem, если нам нужна определенная файловая система. Аргументом этих методов служит абсолютный или относительный путь к файлу, записанный в виде строки по правилам файловой системы. Метод get () перегружен еще и таким образом, что для поиска файла можно задать адрес uri.
Итак, доступ к свойствам файла мы получаем следующим образом:
Path path = Paths.get("pub/file.txt");
Path path = Paths.get("C:docspubfile.txt");
Методы класса Path позволяют работать с путем к файлу и каталогами, встречающимися на этом пути.
Различные компоненты пути к файлу выделяются методами getName(), getParent ( ), getRoot (). Кроме того, метод iterator() возвращает итератор для просмотра компонентов пути к файлу. Каждый компонент тоже представляется объектом типа Path. Простой просмотр можно сделать непосредственно с объектом типа Path. Например,
for (Path name: path) System.out.println(name);
Для приведенного ранее пути path получим компоненты docs, pub, file.txt.
Пути к файлам можно сравнивать друг с другом подобно строкам методами
startsWith (), endsWith (), compareTo (). Можно скомбинировать два пути методом resolve ( ) или создать путь между двумя файлами методом relativize ( ).
Работу с файлом можно организовать методами класса Files. Все методы этого класса статические, ими можно пользоваться без создания экземпляра класса. Методы класса Files похожи на методы класса File, но у них есть параметр — ссылка на объект типа
Path.
Как и для объекта класса File, сначала следует проверить, существует ли файл, логическими методоми exists ( ) или notExists ().
Узнать, файл это, каталог, символическая ссылка, скрытый файл, можно логическими методами isRegularFile(Path), isDirectory(Path), isSymbolicLink(Path), isHidden(Path).
Права доступа к файлу проверяются методами isReadable(Path), isWritable (Path),
isExecutable(Path).
Можно создать файл или каталог методами createFile() и createDirectory( ), скопировать их методами copy(), переместить в другой каталог методом move(), удалить методами delete(Path) и deletelfExists(Path).
Некоторые атрибуты файла — размер, время создания, последнего доступа и модификации файла, файл это, каталог или символическая ссылка — можно узнать методами класса, реализующего интерфейс BasicFileAttributes, или одного из его расширений DosFileAttributes или PosixFileAttributes. Ссылку на объект этого типа можно получить статическим методом readAttributes(Path, Class) класса Files. Метод возвращает ссылку на объект типа BasicFileAttributes или его расширения, класс которого указывается вторым аргументом метода. Атрибуты можно получить методами size(), creationTime ( ),
lastAccessTime(), lastModifiedTime(), isRegularFile(), isDirectory(), isSymbolicLink().
Время последней модификации файла можно сменить статическим методом setLastModifiedTime () класса Files. Другие атрибуты можно установить методом
setAttribute().
Владельца файла в виде объекта типа UserPrincipal дает статический метод getOwner (Path) класса Files. Сменить владельца можно методом setOwner(Path, UserPrincipal).
Если файл на самом деле является каталогом, то обычное действие с ним — это просмотр имен файлов, содержащихся в нем. Для облегчения этой работы класс Files предоставляет объект типа DirectoryStream<Path> методами newDirectoryStream(). Вот как можно получить список имен файлов в каталоге:
DirectoryStream<Path> dir = Files.newDirectoryStream(path); for (Path p: dir) System.out.println(p);
Метод newDirectoryStream( ) выбрасывает исключение типа NotDirectoryException, если path ссылается не на каталог, а на обычный файл. Поэтому предварительно надо убедиться в том, что это действительно путь к каталогу или обработать исключение.
Список файлов можно ограничить, записав во втором аргументе метода newDirectorystream () ссылку на предварительно созданный объект класса, реализующего интерфейс DirectoryStream.Filter. Наконец, методами newInputStream() и newOutputStream() класс Files дает входной и выходной потоки для чтения и записи в файл. Если же надо только прочитать файл, то это можно сделать сразу методом readAllBytes(Path), возвращающим содержимое файла в виде массива байтов. Если файл текстовый и разбит на строки, то удобнее воспользоваться методом readAllLines (), возвращающим список типа List<String>.
Аналогично можно сразу записать массив байтов или список строк в файл методами
write().
Применение системы NIO2 для работы с файлами вы можете увидеть в листинге 23.4. Хорошие примеры приведены в стандартной поставке Java SE, в каталоге $JAVA_HOME/sample/nio.
Буферизованный ввод/вывод
Операции ввода/вывода по сравнению с операциями в оперативной памяти выполняются очень медленно. Для компенсации в оперативной памяти выделяется некоторая промежуточная область — буфер, в которой постепенно накапливается информация. Когда буфер заполнен, его содержимое быстро переносится процессором, буфер очищается и снова заполняется информацией.
Житейский пример буфера — почтовый ящик, в котором накапливаются письма. Мы бросаем в него письмо и уходим по своим делам, не дожидаясь приезда почтовой машины. Почтовая машина периодически очищает почтовый ящик, перенося сразу большое число писем. Представьте себе город, в котором нет почтовых ящиков, и толпа людей с письмами в руках дожидается приезда почтовой машины.
Классы файлового ввода/вывода не занимаются буферизацией. Для этой цели есть четыре специальных класса BufferedXxx, перечисленных ранее.
Они присоединяются к потокам ввода/вывода как "переходное кольцо", например:
BufferedReader br = new BufferedReader(isr);
BufferedWriter bw = new BufferedWriter(fw);
Потоки isr и fw определены ранее.
Программа листинга 23.3 читает текстовый файл, написанный в кодировке CP866, и записывает его содержимое в файл в кодировке KOI8-R. При чтении и записи применяется буферизация. Имя исходного файла задается в командной строке параметром
args [0], имя копии-параметром args [1].
Листинг 23.3. Буферизованный файловый ввод/вывод
import java.io.*;
class DOStoUNIX{
public static void main(String[] args) throws IOException{ if (args.length != 2){
System.err.println("Usage: DOStoUNIX Cp866file KOI8 Rfile");
System.exit(0);
}
BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream(args[0]), "Cp866"));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter( new FileOutputStream(args[1]), "KOI8 R")); int c = 0;
while ((c = br.read()) != -1)
bw.write((char)c); br.close(); bw.close();
System.out.println("Копирование окончено.");
}
}
Каналы буферизованного ввода/вывода
Буферизация — очень мощное средство ускорения ввода и вывода данных. Поэтому во всех системах программирования ей уделяется особое внимание. Технология Java предлагает несколько пакетов java.nio.* (New Input-Output, NIO), обеспечивающих дополнительные средства работы с буферами ввода/вывода. Классы, собранные в эти пакеты, обеспечивают безопасную одновременную работу с буфером нескольких подпроцессов. В седьмой версии Java система NIO существенно расширена, это расширение получило название NIO2.
Основа классов, составляющих систему NIO, — это абстрактный класс Buffer. Он предлагает самые общие методы работы с любым буфером: метод вычисления его емкости capacity (), метод определения текущей позиции в буфере position(), методы изменения текущей позиции reset () и rewind () и другие методы.
Класс Buffer расширяется буферами для хранения данных простых типов — абстрактными классами ByteBuffer, CharBuffer, ShortBuffer, IntBuffer, LongBuffer, FloatBuffer и DoubleBuffer. Они уже могут предложить методы get () получения данных из буфера и методы put () занесения данных в буфер. Кроме этих общих для всех классов методов, каждый класс содержит методы, специфичные для своего типа данных.
Работа с буферами перечисленных классов обеспечивается интерфейсами и классами, собранными в пакеты java.nio.channels и java.nio.channels.spi. Их основу образует интерфейс Channel. Он описывает в самом общем виде открытую связь с источником данных. Такая связь представлена всего двумя методами: isOpen() и close(). Как видите, никакого канала еще не образуется.
Непосредственно канал связи с буфером описывается интерфейсами ReadableByteChannel,
WritableByteChannel, GatheringByteChannel, ScatteringByteChannel и расширяющими интерфейс Channel. Они содержат методы чтения, read(ByteBuffer), и записи, write(ByteBuffer), байтов в буфер. Еще один интерфейс, ByteChannel, объединяет методы интерфейсов
ReadableByteChannel и WritableByteChannel. Он расширен интерфейсом SeekableByteChannel, добавляющим методы position ( ), size ( ) и trancate ( ),
Возможность создания классов асинхронного ввода/вывода обеспечивается интерфейсом AsynchronousChannel и его расширением AsynchronousByteChannel. В пакете j ava. nio. channels есть реализации этих интерфейсов — классы AsynchronousFileChannel, AsynchronousSocketChannel, AsynchronousServerSocketChannel. В стандартной поставке
Java SE, в каталоге SJAVA_HOME/sample/nio/chatserver, приведен пример chat-сервера, использующий асинхронный ввод/вывод.
Сам канал создается методами окончательного (final) класса Channels. В нем собраны статические методы создания потоков классов Inputstream, Outputstream, Reader и Writer, соединенных с буфером каналами типов ReadableByteChannel и WritableByteChannel.
Кроме того, класс Files содержит методы newByteChannel ( ), дающие ссылку на объект типа SeekableByteChannel.
Канал класса Channels соединен с буфером общего типа, связанным с каким угодно источником данных. Он не учитывает специфику источника данных. Для работы с буфером файлового ввода/вывода специально создан абстрактный класс FileChannel. Его методы реализованы в классах FileInputStream и FileOutputStream, которые предоставляют методом getChannel () ссылку типа FileChannel на полностью реализованное расширение
класса FileChannel.
В листинге 23.4 приведены некоторые методы работы с каналами ввода/вывода.
Листинг 23.4. Работа с файлом методами N102
import j ava.nio.*;
import j ava.nio.channels.*;
import j ava.nio.file.*;
import j ava.nio.file.attribute.*;
import j ava.util.*;
import j ava.io.*;
public class PathTest{
public static void main(String[] args){ try{
Path path = Paths.get("C:codePathTest.java"); if (Files.exists(path)){
System.out.println("File is readable: " +
Files.isReadable(path));
BasicFileAttributes attrs = Files.readAttributes(path, BasicFileAttributes.class);
System.out.println("Basic attrs: " + attrs.creationTime() + ", " + attrs.isDirectory());
UserPrincipal owner = Files.getOwner(path); System.out.println("File owner: " + owner.getName()); for (Path d: path) System.out.println("File: " + d); if (attrs.isDirectory()){
try(DirectoryStream<Path> dir =
Files.newDirectoryStream(path)){ for (Path p: dir)
System.out.println("Path: " + p);
}catch(IOException ie){ ie.printStackTrace();
}
}
try(FileChannel fc = (FileChannel)Files.newByteChannel( path, StandardOpenOption.READ,
StandardOpenOption.WRITE)){
ByteBuffer buf = ByteBuffer.allocate((int)fc.size()); int n = fc.read(buf);
System.out.println("n = " + n); byte[] arr = new byte[n]; buf.position(0); buf.get(arr); for(byte b: arr)
System.out.print((char)b);
}catch(IOException ie){ ie.printStackTrace();
}
}
}catch(Exception e){ e.printStackTrace();
}
}
}
Итак, система ввода/вывода Java NIO2 в дополнение к прежним классам предоставляет программисту широкий выбор методов работы с файлами, которые можно разбить на несколько групп от простых к сложным.
1. Самые простые методы Files.readAllBytes(Path), Files.readAllLines(Path, Charset), Files .write (Path, byte [ ]) непосредственно читают файлы и записывают в них массивы байтов или списки строк.
2. Методы Files.newBufferedReader(Path, Charset), Files.newBufferedWriter(Path, Charset) дают ссылку на классы буферизованного ввода/вывода BufferedReader и
BufferedWriter.
3. Методы Files.newInputStream(Path), Files.newOutputStream(Path) возвращают ссылки на потоки ввода/вывода типа InputStream и OutputStream.
4. Методы Files.newByteChannel() с разными параметрами дают ссылку на канал типа
SeekableByteChannel.
5. Наконец, способами, перечисленными в разд. "Прямой доступ к файлу”, можно получить ссылку на объект типа FileChannel, имеющий множество методов работы с файлами через буфер.
Упражнения
3. Напишите программу, подсчитывающую количество символов, слов и строк в заданном текстовом файле.
4. Напишите программу, убирающую лишние пробелы из текстового файла.
Поток простых типов Java
Класс DataOutputstream позволяет записать данные простых типов Java в выходной поток байтов методами writeBoolean(boolean b), writeByte(int b), writeShort(int h), writeChar (int c), writeInt(int n), writeLong(long l), writeFloat(float f), writeDouble(double d).
Кроме того, метод writeBytes (string s) записывает каждый символ строки s в один байт, отбрасывая старший байт кодировки каждого символа Unicode, а метод writeChars(string s) записывает каждый символ строки s в два байта, первый байт — старший байт кодировки Unicode, так же, как это делает метод writeChar ().
Еще один метод writeUTF(string s) записывает строку s в выходной поток в кодировке UTF-8. Надо пояснить эту кодировку.
Кодировка UTF-8
Запись потока в байтовой кодировке вызывает трудности с использованием национальных символов, запись потока в Unicode увеличивает длину потока в два раза. Кодировка UTF-8 (Universal Transfer Format) является компромиссом. Символ в этой кодировке записывается одним, двумя или тремя байтами.
Символы Unicode из диапазона 'u0000'—'u007F', в котором лежит английский алфавит, записываются одним байтом, старший байт просто отбрасывается.
Символы Unicode из диапазона 'u0080' — 'u07FF', в котором лежат наиболее распространенные символы национальных алфавитов, записываются двумя байтами следующим образом: символ Unicode с кодировкой 00000xxxxxyyyyyy записывается как 110xxxxx10yyyyyy.
Остальные символы Unicode из диапазона 'u0800'—'uffff' записываются тремя байтами по следующему правилу: символ Unicode с кодировкой xxxxyyyyyyzzzzzz записывается как 1110xxxx10yyyyyy10zzzzzz.
Такой странный способ распределения битов позволяет по первым битам кода узнать, сколько байтов составляет код символа, и правильно отсчитывать символы в потоке.
Так вот, метод writeUTF (string s) сначала записывает в поток, точнее, в первые два байта потока, длину строки s в кодировке UTF-8, а затем символы строки в этой кодировке. Читать эту запись потом следует парным методом readUTF( ) класса DataInputStream.
Класс DataOutputstream
Класс DataInputStream преобразует входной поток байтов типа Inputstream, составляющих данные простых типов Java, в данные этого типа. Такой поток, как правило, создается методами класса DataOutputstream. Данные из потока можно прочитать методами
readBoolean(), readByte(), readShort(), readChar(), readInt(), readLong(), readFloat(),
readDouble (), возвращающими данные соответствующего типа.
Кроме того, методы readUnsignedByte () и readUnsignedShort () возвращают целое типа int, в котором старшие три или два байта нулевые, а младшие один или два байта заполнены байтами из входного потока.
Метод readUTF ( ), двойственный методу writeUTF( ), возвращает строку типа String, полученную из потока, записанного методом writeUTF( ).
Еще один, статический, метод readUTF(DataInput in) делает то же самое со входным потоком in, записанным в кодировке UTF-8. Этот метод можно применять, не создавая объект класса DataInputStream.
Программа в листинге 23.5 записывает в файл fib.txt числа Фибоначчи, а затем читает этот файл и выводит его содержимое на консоль. Для контроля записываемые в файл числа тоже выводятся на консоль. На рис. 23.5 показан вывод этой программы.
Листинг 23.5. Ввод/вывод данных
import java.io.*; class DataPrWr{
public static void main(String[] args) throws IOException{ DataOutputstream dos = new DataOutputStream( new FileOutputStream ("fib.txt")); int a = 1, b = 1, c = 1; for (int k = 0; k < 40; k++){
System.out.print(b + " "); dos.writeInt(b); a = b; b = c; c = a + b;
}
dos.close();
System.out.println(" ");
DataInputStream dis = new DataInputStream( new FileInputStream("fib.txt"));
while (true) try{
a = dis.readInt();
System.out.print(a + " ");
}catch(IOException e){ dis.close();
System.out.println("End of file");
System.exit(0);
}
}
}
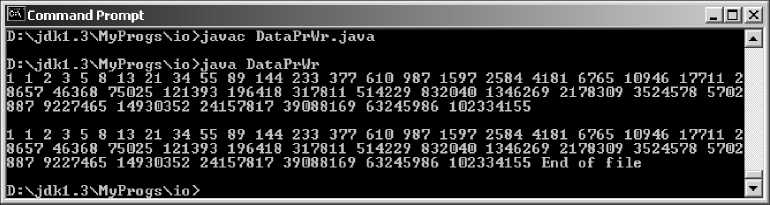 Рис. 23.5. Ввод и вывод данных
Рис. 23.5. Ввод и вывод данных
Обратите внимание на то, что попытка чтения за концом файла выбрасывает исключение класса IOException, в листинге 23.5 его обработка заключается в закрытии файла и завершении программы.
Прямой доступ к файлу
Если необходимо интенсивно работать с файлом, записывая в него данные разных типов Java, изменяя их, отыскивая и читая нужную информацию, то лучше всего воспользоваться методами класса FileChannel из пакета j ava. nio. channels или класса RandomAccessFile из пакета java.io. Эти классы не порождают поток байтов. Они могут читать файл или записывать в него информацию, начиная с любого байта файла, реализуя прямой доступ к файлу.
Поскольку объект типа FileChannel тесно связан с файловой системой, как и все классы NIO, его нельзя создать конструктором, а можно получить из пути к файлу типа Path по такой схеме:
Path path = Paths.get("pub/file.txt");
FileChannel fc = (FileChannel)Files.newByteChannel(path,
StandardOpenOption.READ,
StandardOpenOption.WRITE);
Как видите, с помощью аргументов — констант перечисления StandardOpenOption — файл можно открыть на чтение, на запись или на чтение и запись. Другие возможности описываются константами append, create, create_new, trancate_existing, delete_on_close,
SPARSE, SYNC, DSYNC.
Используя Path можно также получить объект типа FileChannel статическим методом open (), например,
FileChannel fc = FileChannel.open(path, StandardOpenOption.CREATE, StandardOpenOption.APPEND);
Третий способ получить объект типа FileChannel — это извлечь его из открытого потока типа FileInputStream или FileOutputStream, или из объекта типа RandomAccessFile методом getChannel():
RandomAccessFile ras = new RandomAccessFile("pub/file.txt", "rw");
FileChannel fc = ras.getChannel();
Как видно из этого примера, объект типа RandomAccessFile создается конструктором. В конструкторах этого класса
RandomAccessFile(File file, String mode);
RandomAccessFile(String fileName, String mode);
вторым аргументом, mode, задается режим открытия файла. Это может быть строка "r" — открытие файла только для чтения, "rw" — открытие файла для чтения и записи, "rwd" — чтение и запись с немедленным обновлением источника данных и "rws" — чтение и запись с немедленным обновлением не только данных, но и метаданных.
Этот класс собрал все полезные методы работы с файлом. Он содержит все методы классов DataInputStream и DataOutputStream, кроме того, позволяет прочитать сразу целую строку методом readLine () и отыскать нужные данные в файле.
Байты файла нумеруются начиная с 0, подобно элементам массива. Файл снабжен неявным указателем (file pointer) текущей позиции. Чтение и запись производится с текущей позиции файла. При открытии файла конструктором указатель стоит на начале файла, в позиции 0. Каждое чтение или запись перемещает указатель на длину прочитанного или записанного данного. Всегда можно переместить указатель в новую позицию pos методом seek(long pos). Метод seek(0) перемещает указатель на начало файла.
Текущую позицию файла можно узнать методом getFilePointer( ).
В классе RandomAccessFile нет методов преобразования символов в байты и обратно по кодовым таблицам, поэтому он не приспособлен для работы с кириллицей.
Класс FileChannel определяет текущую позицию методом position (), а изменяет ее методом position(long pos).
Для чтения и записи класс FileChannel предлагает методы read ( ) и write ( ). Как у всякого канала, чтение или запись производятся в буфер или из буфера типа ByteBuffer, который должен быть подготовлен заранее. Вот схема чтения файла и вывода его содержимого на консоль:
ByteBuffer buf = ByteBuffer.allocate((int)fc.size());
int n = fc.read(buf);
byte[] arr = new byte[n];
buf.position(0);
buf.get(arr);
for (byte b: arr) System.out.print((char)b); fc.close();
Упражнение
5. Выполните упражнение 4 с помощью прямого доступа к файлу.
Каналы обмена информацией
В предыдущей главе мы видели, каких трудов стоит организовать правильный обмен информацией между подпроцессами. В пакете java.io есть четыре класса PipedXxx, облегчающие эту задачу.
В одном подпроцессе — источнике информации — создается объект класса PipedWriter+ или PipedOutputstream, в который записывается информация методами write () этих классов.
В другом подпроцессе — приемнике информации — формируется объект класса PipedReader или PipedInputStream. Он связывается с объектом-источником с помощью конструктора или специальным методом connect () и читает информацию методами
read().
Источник и приемник можно создать и связать в обратном порядке.
Так создается однонаправленный канал (pipe) информации. На самом деле это некоторая область оперативной памяти, к которой организован совместный доступ двух или более подпроцессов. Доступ синхронизируется, записывающие процессы не могут помешать чтению.
Если надо организовать двусторонний обмен информацией, то создаются два канала.
В листинге 23.6 метод run() класса Source генерирует информацию, для простоты просто целые числа k, и передает ее в канал методом pw.write (k). Метод run () класса Target читает информацию из канала методом pr. read (). Концы канала связываются с помощью конструктора класса Target. На рис. 23.6 видна последовательность записи и чтения информации.
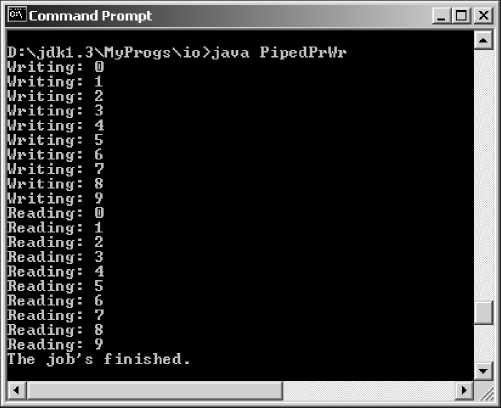 Рис. 23.6. Данные, передаваемые между подпроцессами
Рис. 23.6. Данные, передаваемые между подпроцессами
Листинг 23.6. Канал обмена информацией
import java.io.*;
class Target extends Thread{
private PipedReader pr;
Target(PipedWriter pw){ try{
pr = new PipedReader(pw);
}catch(IOException e){
System.err.println("From Target(): " + e);
}
}
PipedReader getStream(){ return pr;}
public void run(){ while(true) try{
System.out.println("Reading: " + pr.read()); }catch(IOException e){
System.out.println("The job’s finished.");
System.exit(0);
}
}
}
class Source extends Thread{ private PipedWriter pw;
Source(){
pw = new PipedWriter();
}
PipedWriter getStream(){ return pw;}
public void run(){
for (int k = 0; k < 10; k++) try{
pw.write(k);
System.out.println("Writing: " + k);
}catch(Exception e){
System.err.println("From Source.run(): " + e);
}
}
}
class PipedPrWr{
public static void main(String[] args){
Source s = new Source();
Target t = new Target(s.getStream()); s.start(); t.start();
}
}
Сериализация объектов
Методы классов ObjectInputStream и ObjectOutputStream позволяют прочитать из входного байтового потока или записать в выходной байтовый поток данные сложных типов —
объекты, массивы, строки- подобно тому, как методы классов DataInputStream и
DataOutputstream читают и записывают данные простых типов.
Сходство усиливается тем, что классы Objectxxx содержат методы как для чтения, так и записи простых типов. Впрочем, эти методы предназначены не для использования в программах, а для записи/чтения полей объектов и элементов массивов.
Процесс записи объекта в выходной поток получил название сериализации (serialization), а чтения объекта из входного потока и восстановления его в оперативной памяти — десериализации (deserialization).
Сериализация объекта нарушает его безопасность, поскольку зловредный процесс может сериализовать объект в массив, переписать некоторые элементы массива, представляющие private-поля объекта, обеспечив себе, например, доступ к секретному файлу, а затем десериализовать объект с измененными полями и совершить с ним недопустимые действия.
Поэтому сериализации можно подвергнуть не каждый объект, а только тот, который реализует интерфейс Serializable. Этот интерфейс не содержит ни полей, ни методов. Реализовать в нем нечего. По сути дела запись
class A implements Serializable{...}
это только пометка, разрешающая сериализацию класса а.
Как всегда в Java, процесс сериализации максимально автоматизирован. Достаточно создать объект класса ObjectOutputStream, связав его с выходным потоком, и выводить в этот поток объекты методом writeObject ( ) :
MyClass mc = new MyClass("abc", -12, 5.67e-5); int[] arr = {10, 20, 30};
ObjectOutputStream oos = new ObjectOutputStream( new FileOutputStream("myobjects.ser"));
oos.writeObject(mc); oos.writeObj ect(arr); oos.writeObj ect("Some string"); oos.writeObject(new Date()); oos.flush();
В выходной поток выводятся все нестатические поля объекта, независимо от прав доступа к ним, а также сведения о классе этого объекта, необходимые для его правильного восстановления при десериализации. Байт-коды методов класса не сериализуются.
Если в объекте присутствуют ссылки на другие объекты, то они тоже сериализуются, а в них могут быть ссылки на другие объекты, которые опять-таки сериализуются, и получается целое множество причудливо связанных между собой сериализуемых объектов. Метод writeObj ect () распознает две ссылки на один объект и выводит его в выходной поток только один раз. К тому же, он распознает ссылки, замкнутые в кольцо, и избегает зацикливания.
Все классы объектов, входящих в такое сериализуемое множество, а также все их внутренние классы должны реализовать интерфейс Serializable, в противном случае будет выброшено исключение класса NotserializableException и процесс сериализации прервется. Многие классы J2SE JDK реализуют этот интерфейс. Учтите также, что все потомки таких классов наследуют реализацию. Например, класс java.awt.Component реализует интерфейс Serializable, значит, все графические компоненты можно сериализовать.
Не реализуют этот интерфейс обычно классы, тесно связанные с выполнением программ, например java.awt.Toolkit. Состояние экземпляров таких классов нет смысла сохранять или передавать по сети. Не реализуют интерфейс Serializable и классы, содержащие внутренние сведения Java "для служебного пользования".
Десериализация происходит так же просто, как и сериализация:
ObjectInputStream ois = new ObjectInputStream( new FileInputStream("myobj ects.ser"));
MyClass mc1 = (MyClass)ois.readObject(); int[] a = (int[])ois.readObj ect();
String s = (String)ois.readObject();
Date d = (Date)ois.readObject();
Нужно только соблюдать порядок чтения элементов потока.
В листинге 23.7 мы создаем объект класса GregorianCalendar с текущей датой и временем, сериализуем его в файл date.ser, через три секунды десериализуем обратно и сравниваем с текущим временем. Результат показан на рис. 23.7.
Листинг 23.7. Сериализация объекта
import java.io.*;
import java.util.*;
class SerDate{
public static void main(String[] args) throws Exception{ GregorianCalendar d = new GregorianCalendar();
ObjectOutputStream oos = new ObjectOutputStream( new FileOutputStream("date.ser"));
oos.writeObj ect(d);
oos.flush(); oos.close();
Thread.sleep(3000);
ObjectInputStream ois = new ObjectInputStream( new FileInputStream("date.ser"));
GregorianCalendar oldDate = (GregorianCalendar)ois.readObject(); ois.close();
GregorianCalendar newDate = new GregorianCalendar();
System.out.println("Old time = " +
oldDate.get(Calendar.HOUR) + ":" + oldDate.get(Calendar.MINUTE) + ":" + oldDate.get(Calendar.SECOND) + " New time = " + newDate.get(Calendar.HOUR) + ":" + newDate.get(Calendar.MINUTE) + ":" + newDate.get(Calendar.SECOND));
}
}
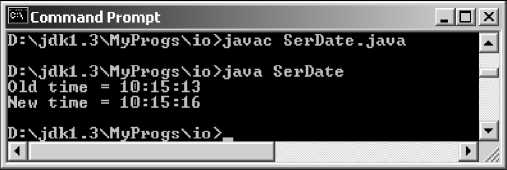 Рис. 23.7. Сериализация объекта
Рис. 23.7. Сериализация объекта
Если не нужно сериализовать какое-то поле, то достаточно пометить его служебным словом transient, например:
transient MyClass mc = new MyClass("abc", -12, 5.67e-5);
Метод writeObject() не записывает в выходной поток поля, помеченные static и transient. Впрочем, это положение можно изменить, переопределив метод writeObject() или задав список сериализуемых полей.
Вообще процесс сериализации можно полностью настроить под свои нужды, переопределив методы ввода/вывода и воспользовавшись вспомогательными классами. Можно даже взять весь процесс на себя, реализовав не интерфейс serializable, а интерфейс
Externalizable, но тогда придется реализовать методы readExternal () и writeExternal(), выполняющие ввод/вывод.
Эти действия выходят за рамки книги. Если вам необходимо полностью освоить процесс сериализации, то обратитесь к спецификации Java Object Serialization Specification, расположенной среди документации Java SE в каталоге docs/platform/serialization/spec/. В каталоге docs/technotes/guides/serialization/examples/ есть много примеров программ, реализующих эту спецификацию.
Печать в Java
Поскольку принтер — устройство графическое, вывод на печать очень похож на вывод графических объектов на экран. Поэтому в Java средства печати входят в графическую библиотеку AWT и в систему Java 2D. Кроме того, в пакетах javax.print.* есть средства работы с сервером печати, но они выходят за рамки нашей книги.
В графическом компоненте кроме графического контекста — объекта класса Graphics — создается еще "печатный контекст". Это тоже объект класса Graphics, но реализующий интерфейс PrintGraphics и полученный из другого источника — объекта класса PrintJob, входящего в пакет java.awt. Сам же этот объект создается с помощью класса Toolkit пакета j ava. awt.
На практике это выглядит так:
PrintJob pj = getToolkit().getPrintJob(this, "Job Title", null);
Graphics pg = pj.getGraphics();
Метод getPrintJob () сначала выводит на экран стандартное окно Печать (Print) операционной системы. Когда пользователь выберет в этом окне параметры печати и начнет печать кнопкой ОК, создается объект pj. Если пользователь отказывается от печати при помощи кнопки Отмена (Cancel), то метод возвращает null.
В классе Toolkit два метода getPrintJob( ):
getPrintJob(Frame frame, String jobTitle, JobAttributes jobAttr,
PageAttributes pageAttr);
getPrintJob(Frame frame, String jobTitle, Properties prop);
Аргумент frame указывает на окно верхнего уровня, управляющее печатью. Этот аргумент не может быть null. Строка jobTitle формирует заголовок задания, который не печатается, она может быть равна null. Аргумент prop зависит от реализации системы печати, часто это просто null, в данном случае задаются стандартные параметры печати.
Аргумент jobAttr задает параметры печати. Класс JobAttributes, экземпляром которого является этот аргумент, устроен сложно. В нем пять подклассов, содержащих статические константы — параметры печати, которые используются в конструкторе класса. Впрочем, есть конструктор по умолчанию, задающий стандартные параметры печати.
Аргумент pageAttr определяет параметры страницы. Класс PageProperties тоже содержит пять подклассов со статическими константами, которые задают параметры страницы и используются в конструкторе класса. Если для печати достаточно стандартных параметров, то можно воспользоваться конструктором по умолчанию.
Мы не будем рассматривать эти десять подклассов с десятками констант, чтобы не загромождать книгу мелкими подробностями. К тому же система Java 2D предлагает более удобный набор классов для печати, который мы рассмотрим в следующем разделе.
После того как "печатный контекст" — объект pg класса Graphics — определен, можно вызывать метод print(pg) или printAll (pg) класса Component. Этот метод устанавливает связь с принтером по умолчанию и вызывает метод paint (pg). На печать выводится все то, что задано этим методом.
Например, чтобы распечатать текстовый файл, надо в процессе ввода разбить его текст на строки и в методе paint(pg) вывести строки методом pg.drawString( ) так же, как мы выводили их на экран в главе 9. При этом следует учесть, что в "печатном контексте" нет шрифта по умолчанию, всегда следует устанавливать шрифт методом pg.setFont ().
После выполнения всех методов print() применяется метод pg.dispose(), вызывающий прогон страницы, и метод pj. end (), заканчивающий печать.
В листинге 23.8 приведен простой пример печати текста и окружности, заданных в методе paint (). Этот метод работает два раза: первый раз — вычерчивая текст и окружность на экране, второй раз — точно так же на листе бумаги, вставленной в принтер. Все методы печати собраны в один метод simplePrint ( ).
Листинг 23.8. Печать средствами AWT
import java.awt.*; import java.awt.event.*;
class PrintTest extends Frame{
PrintTest(String s){ super(s);
setSize(400, 400); setVisible(true);
}
public void simplePrint(){
PrintJob pj =
getToolkit().getPrintJob(this, "Job Title", null); if (pj != null){
Graphics pg = pj.getGraphics(); if (pg != null){ print(pg);
pg.dispose();
}else System.err.println("Graphics’s null");
pj.end();
}else System.err.println("Job’s null");
}
public void paint(Graphics g){
g.setFont(new Font("Serif", Font.ITALIC, 30)); g.setColor(Color.black); g.drawArc(100, 100, 200, 200, 0, 360); g.drawString("CTpaH^a 1", 100, 100);
}
public static void main(String[] args){
PrintTest pt = new PrintTest(" Простой пример печати"); pt.simplePrint();
pt.addWindowListener(new WindowAdapter(){
public void windowClosing(WindowEvent ev){
System.exit(0);
}
});
}
}
Печать средствами Java 2D
Расширенная графическая система Java 2D предлагает новые интерфейсы и классы для печати, собранные в пакет java.awt.print. Эти классы полностью перекрывают все стандартные возможности печати библиотеки AWT. Более того, они удобнее в работе и предлагают дополнительные возможности. Если этот пакет установлен в вашей вычислительной системе, то, безусловно, нужно применять его, а не стандартные средства печати AWT.
Как и стандартные средства AWT, методы классов Java 2D выводят на печать содержимое графического контекста, заполненного методами класса Graphics или класса
Graphics2D.
Всякий класс Java 2D, собирающийся печатать хотя бы одну страницу текста, графики или изображения, называется классом, рисующим страницы (page painter). Такой класс должен реализовать интерфейс Printable. В этом интерфейсе описаны две константы и только один метод print (). Класс, рисующий страницы, должен реализовать этот метод. Метод print () возвращает целое типа int и имеет три аргумента:
print(Graphics g, PageFormat pf, int ind);
Первый аргумент g — это графический контекст, выводимый на лист бумаги, второй аргумент pf — экземпляр класса PageFormat, определяющий размер и ориентацию страницы, третий аргумент ind — порядковый номер страницы, начинающийся с нуля.
Метод print () класса, рисующего страницы, заменяет собой метод paint (), использовавшийся стандартными средствами печати AWT. Класс, рисующий страницы, не обязан расширять класс Frame и переопределять метод paint (). Все заполнение графического контекста методами класса Graphics или Graphics2D теперь выполняется в методе
print().
Когда печать страницы будет закончена, метод print () должен возвратить целое значение, заданное константой page_exists. Будет сделано повторное обращение к методу print () для печати следующей страницы. Аргумент ind при этом возрастет на 1. Когда ind превысит количество страниц, метод print () должен возвратить значение no_such_page, что служит сигналом окончания печати.
Следует помнить, что система печати может несколько раз обратиться к методу paint () для печати одной и той же страницы. При этом аргумент ind не меняется, а метод print () должен создать тот же графический контекст.
Класс PageFormat определяет параметры страницы. На странице вводится система координат с единицей длины 1/72 дюйма, начало которой и направление осей определяется одной из трех констант:
? portrait — начало координат расположено в левом верхнем углу страницы, ось Ox направлена вправо, ось Oy — вниз;
? landscape — начало координат в левом нижнем углу, ось Ox идет вверх, ось Oy — вправо;
? reverse_landscape — начало координат в правом верхнем углу, ось Ox идет вниз, ось Oy — влево.
Большинство принтеров не может печатать без полей, на всей странице, а осуществляет вывод только в некоторой области печати (imageable area), координаты левого верхнего угла которой возвращаются методами getImageableX() и getImageableY(), а ширина и высота — методами getImageableWidth ( ) и getImageableHeight ( ).
Эти значения надо учитывать при расположении элементов в графическом контексте, например при размещении строк текста методом drawstring(), как это сделано в листинге 23.10.
В классе только один конструктор по умолчанию PageFormat (), задающий стандартные параметры страницы, определенные для принтера по умолчанию вычислительной системы.
Читатель, добравшийся до этого места книги, уже настолько поднаторел в Java, что у него возникает вопрос: "Как же тогда задать параметры страницы?" Ответ простой: "С помощью стандартного окна операционной системы".
Метод pageDialog (PageDialog pd) открывает на экране стандартное окно Параметры страницы (Page Setup) операционной системы, в котором уже заданы параметры, определенные в объекте pd. Если пользователь выбрал в этом окне кнопку Отмена (Cancel), то возвращается ссылка на объект pd; если кнопку ОК, то создается и возвращается ссылка на новый объект. Объект pd в любом случае не меняется. Он обычно создается конструктором.
Можно задать параметры страницы и из программы, но тогда следует сначала определить объект класса Paper конструктором по умолчанию:
Paper p = new Paper();
Затем методами
p.setSize(double width, double height);
p.setImageableArea(double x, double y, double width, double height);
задать размер страницы и области печати.
Потом определить объект класса PageFormat с параметрами по умолчанию:
PageFormat pf = new PageFormat();
и задать новые параметры методом
pf.setPaper(p);
Теперь вызывать на экран окно Параметры страницы методом pageDialog () уже не обязательно, и мы получим молчаливый (silent) процесс печати. Так делается в тех случаях, когда печать выполняется "на фоне" отдельным подпроцессом.
Итак, параметры страницы определены, метод print() — тоже. Теперь надо дать задание на печать (print job) — указать количество страниц, их номера, порядок печати страниц, количество копий. Все эти сведения собираются в классе PrinterJob.
Система печати Java 2D различает два вида заданий. В более простых заданиях — Printable Job — есть только один класс, рисующий страницы, поэтому у всех страниц одни и те же параметры, страницы печатаются последовательно с первой по последнюю или с последней страницы по первую, это зависит от системы печати.
Второй, более сложный вид заданий — Pageable Job — определяет для печати каждой страницы свой класс, рисующий страницы, поэтому у каждой страницы могут быть собственные параметры. Кроме того, можно печатать не все, а только выбранные страницы, выводить их в обратном порядке, печатать на обеих сторонах листа. Для осуществления этих возможностей определяется экземпляр класса Book или создается класс, реализующий интерфейс Pageable.
В классе Book, опять-таки, один конструктор, создающий пустой объект:
Book b = new Book();
После создания в данный объект добавляются классы, рисующие страницы. Для этого в классе Book есть два метода:
? append(Printable p, PageFormat pf) — добавляет объект p в конец;
? append(Printable p, PageFormat pf, int numPages) — добавляет numPages экземпляров p в конец; если число страниц заранее неизвестно, то задается константа
UNKNOWN_NUMBER_OF_PAGES.
При составлении задания на печать, т. е. после создания экземпляра класса PrinterJob, надо указать вид задания одним и только одним из трех методов этого класса
setPrintable(Printable pr), setPrintable(Printable pr, PageFormat pf) или setPageble(Pageable pg).
Заодно задаются один или несколько классов pr, рисующих страницы в этом задании.
Остальные параметры задания можно определить в стандартном диалоговом окне Печать (Print) операционной системы, которое открывается на экране при выполнении логического метода printDialog(). Указанный метод не имеет аргументов. Он возвратит true, когда пользователь щелкнет по кнопке ОК, и false после нажатия кнопки Отмена (Cancel).
Остается задать число копий, если оно больше 1, методом setcopies(int n), и задание сформировано.
Еще один полезный метод defaultPage() класса PrinterJob возвращает объект класса PageFormat по умолчанию. Этот метод можно использовать вместо конструктора класса
PageFormat .
Осталось сказать, как создается экземпляр класса PrinterJob. Поскольку этот класс тесно связан с системой печати компьютера, его объекты создаются не конструктором, а статическим методом getPrinterJob ( ), имеющимся в том же самом классе PrinterJob.
Начало печати задается методом print () класса PrinterJob. Этот метод не имеет аргументов. Он последовательно вызывает методы print(g, pf, ind) классов, рисующих страницы, для каждой страницы.
Соберем все сказанное вместе в листинге 23.9. В нем средствами Java 2D печатается то же самое, что и в листинге 23.8. Обратите внимание на п. 6. После окончания печати программа не заканчивается автоматически, для ее завершения мы обращаемся к методу System.exit(0).
Листинг 23.9. Простая печать методами Java 2D
import java.awt.*; import java.awt.geom.*; import java.awt.print.*;
class Print2Test implements Printable{
public int print(Graphics g, PageFormat pf, int ind)
throws PrinterException{
// Печатаем не более 5 страниц. if (ind > 4) return Printable.NO SUCH PAGE;
Graphics2D g2 = (Graphics2D)g; g2.setFont(new Font("Serif", Font.ITALIC, 30)); g2.setColor(Color.black);
g2.drawString("Page " + (ind + 1), 100, 100); g2.draw(new Ellipse2D.Double(100, 100, 200, 200)); return Printable.PAGE_EXISTS;
}
public static void main(String[] args){
// 1. Создаем экземпляр задания.
PrinterJob pj = PrinterJob.getPrinterJob();
// 2. Открываем диалоговое окно "Параметры страницы".
PageFormat pf = pj.pageDialog(pj.defaultPage());
// 3. Задаем вид задания, объект класса, рисующего страницу,
// и выбранные параметры страницы. pj.setPrintable(new Print2Test(), pf);
// 4. Если нужно напечатать несколько копий, то: pj.setCopies(2); // По умолчанию печатается одна копия.
// 5. Открываем диалоговое окно "Печать" (необязательно) if (pj.printDialog()){ // Если ОК...
try{
pj.print(); // Обращается к print(g, pf, ind).
}catch(Exception e){
System.err.println(e);
}
// 6. Завершаем задание.
System.exit(0);
}
}
Печать файла
Печать текстового файла заключается в размещении его строк в графическом контексте методом drawstring (). При этом необходимо проследить за правильным размещением строк в области печати и разбиением файла на страницы.
В листинге 23.10 приведен упрощенный пример печати текстового файла, имя которого задается в командной строке. Из файла читаются готовые строки, программа не сравнивает их длину с шириной области печати, не выделяет абзацы. Вывод производится в локальной кодировке.
Листинг 23.10. Печать текстового файла
import java.awt.*; import java.awt.print.*; import java.io.*;
public class Print2File{
public static void main(String[] args){ if (args.length < 1){
System.err.println("Usage: Print2File path"); System.exit(0);
}
PrinterJob pj = PrinterJob.getPrinterJob(); PageFormat pf = pj.pageDialog(pj.defaultPage()); pj.setPrintable(new FilePagePainter(args[0]), pf); if (pj.printDialog()){
try{
pj.print();
}catch(PrinterException e){}
}
System.exit(0);
}
}
class FilePagePainter implements Printable{
private BufferedReader br; private String file; private int page = -1; private boolean eof; private String[] line; private int numLines;
public FilePagePainter(String file){ this.file = file;
try{
br = new BufferedReader(new FileReader(file));
}catch(IOException e){ eof = true; }
}
public int print(Graphics g, PageFormat pf, int ind)
throws PrinterException{
g.setColor(Color.black);
g.setFont(new Font("Serif", Font.PLAIN, 10)); int h = (int)pf.getImageableHeight(); int x = (int)pf.getImageableX() + 10; int y = (int)pf.getImageableY() + 12;
try{
// Если система печати запросила эту страницу первый раз: if (ind != page){
if (eof) return Printable.NO SUCH PAGE; page = ind;
line = new String[h/12]; // Массив строк на странице.
numLines = 0; // Число строк на странице.
// Читаем строки из файла и формируем массив строк. while (y + 48 < pf.getImageableY() + h){ line[numLines] = br.readLine(); if (line[numLines] == null){ eof = true; break;
}
numLines++;
y += 12;
}
}
// Размещаем колонтитул. y = (int)pf.getImageableY() + 12;
g.drawString("Файл: " + file + ", страница " + (ind + 1), x, y); // Оставляем две пустыю строки.
y += 36;
// Размещаем строки текста текущей страницы. for (int i = 0; i < numLines; i++){ g.drawString(line[i], x, y);
y += 12;
}
return Printable.PAGE_EXISTS;
}catch(IOException e){
return Printable.NO SUCH PAGE;
}
}
Печать страниц с разными параметрами
Печать вида Printable Job не совсем удобна — у всех страниц должны быть одинаковые параметры, нельзя задать число страниц и порядок их печати, в окне Параметры страницы не видно число страниц, выводимых на печать.
Все эти возможности предоставляет печать вида Pageable Job с помощью класса Book.
Как уже говорилось, сначала создается пустой объект класса Book, затем к нему добавляются разные или одинаковые классы, рисующие страницы. При этом определяются объекты класса PageFormat, задающие параметры этих страниц, и число страниц. Если число страниц заранее неизвестно, то вместо него указывается константа unknown_number_of_pages. В таком случае страницы будут печататься в порядке возрастания их номеров до тех пор, пока метод print () не возвратит no_such_page.
Метод
setPage(int pageIndex, Printable p, PageFormat pf);
заменяет объект в позиции pageIndex на новый объект p.
В программе листинга 23.11 создаются два класса, рисующие страницы: Cover и Content. Эти классы очень просты — в них только реализован метод print (). Класс Cover рисует титульный лист крупным полужирным шрифтом. Текст печатается снизу вверх вдоль длинной стороны листа на его правой половине. Класс Content выводит обыкновенный текст обычным образом.
Параметры титульного листа определяются в классе pf1, параметры других страниц задаются в диалоговом окне Параметры страницы и содержатся в классе pf2.
В объект bk класса Book занесены три страницы: первая страница — титульный лист, на двух других печатается один и тот же текст, записанный в методе print () класса Content.
Листинг 23.11. Печать страниц с разными параметрами
import java.awt.*; import java.awt.print.*;
public class Print2Book{
public static void main(String[] args){
PrinterJob pj = PrinterJob.getPrinterJob();
// Для титульного листа выбирается альбомная ориентация. PageFormat pfl = pj.defaultPage(); pfl.setOrientation(PageFormat.LANDSCAPE);
// Параметры1 других страниц задаются в диалоговом окне. PageFormat pf2 = pj.pageDialog(new PageFormat());
Book bk = new Book();
// Первая страница — титульный лист. bk.append(new Cover(), pfl);
// Две другие страницы. bk.append(new Content(), pf2, 2);
// Определяется вид печати — Pageable Job. pj.setPageable(bk);
if (pj.printDialog()){
try{
pj.print();
}catch(Exception e){}
}
System.exit(0);
}
}
class Cover implements Printable{
public int print(Graphics g, PageFormat pf, int ind)
throws PrinterException{
g.setFont(new Font("Helvetica-Bold", Font.PLAIN, 40));
g.setColor(Color.black);
int y = (int)(pf.getImageableY() +
pf.getImageableHeight()/2); g.drawString("Это заголовок.", 72, y); g.drawString("Он печатается вдоль длинной", 72, y+60); g.drawString(,,стороныI листа бумаги.", 72, y+120);
return Printable.PAGE_EXISTS;
}
}
class Content implements Printable{
public int print(Graphics g, PageFormat pf, int ind)
throws PrinterException{
Graphics2D g2 = (Graphics2D)g; g2.setFont(new Font("Serif", Font.PLAIN, 12)); g2.setColor(Color.black);
int x = (int)pf.getImageableX() + 30; int y = (int)pf.getImageableY();
g2.drawString(,,Это строки обы1чного текста.", x, y += 16); g2.drawString(,,Они печатаются с параметрами,", x, y += 16); g2.drawString(,,выIбранныIми в диалоговом окне.", x, y += 16);
return Printable.PAGE_EXISTS;
}
}
Вопросы для самопроверки
1. Что называется потоком (stream) данных?
2. Какие потоки ввода/вывода создаются исполняемой системой Java для каждой запущенной программы?
3. Как можно преобразовать поток ввода/вывода?
4. Как изменить кодировку символов в потоке?
5. Можно ли начать чтение файла не с его начала, а с произвольного места?
6. Можно ли вставить новую информацию в середину существующего файла?
7. Что такое буферизация ввода/вывода и для чего она нужна?
8. Что такое сериализация объекта?
9. Почему вопросы, относящиеся к печати, разобраны в этой главе, посвященной вводу/выводу?
ГЛАВА 24
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК