Связь Java с технологией XML

В развитии Web-технологии огромную роль сыграл язык HTML (HyperText Markup Language) — язык разметки гипертекста. Любой человек, совсем не знакомый с программированием, мог за полчаса понять принцип разметки текста и за пару дней изучить теги HTML. Пользуясь простейшим текстовым редактором, он мог написать свою страничку HTML, тут же посмотреть ее в своем браузере, испытать чувство глубокого удовлетворения и гордо выставить в Интернете свой шедевр.
Замечательно! Не надо месяцами изучать запутанные языки программирования, явно предназначенные только для яйцеголовых "ботаников", осваивать сложные алгоритмы, возиться с компиляторами и отладчиками, размножать свое творение на дисках. Очень скоро появились текстовые редакторы, размечающие обычный "плоский" текст тегами HTML. Разработчику оставалось только поправлять готовую страницу HTML, созданную таким редактором.
Простота языка HTML привела к взрывному росту числа сайтов, пользователей Интернета и авторов многочисленных Web-страничек. Обычные пользователи компьютеров ощутили себя творцами, получили возможность заявить о себе, высказать собственные мысли и чувства, найти в Интернете единомышленников.
Ограниченные возможности языка HTML быстро перестали удовлетворять поднаторевших разработчиков, почувствовавших себя "профи". Набор тегов языка HTML строго определен и должен одинаково пониматься всеми браузерами. Нельзя ввести дополнительные теги или указать браузеру, как следует отображать на экране содержимое того или иного тега. Введение таблиц стилей CSS (Cascading Style Sheet) и включений на стороне сервера SSI (Server Side Include) лишь ненадолго уменьшило недовольство разработчиков. Профессионалу всегда не хватает средств разработки, он постоянно испытывает потребность добавить к ним какое-то свое средство, позволяющее реализовать все его фантазии.
Такая возможность есть. Еще в 1986 году стал стандартом язык создания языков разметки SGML (Standard Generalized Markup Language), с помощью которого и был создан язык HTML. Основная особенность языка SGML заключается в том, что он позволяет сформировать новый язык разметки, определив его набор тегов. Каждый конкретный набор тегов, созданный по правилам SGML, снабжается описанием DTD (Document Type Definition) — определением типа документа, разъясняющим связь тегов между собой и правила их применения. Специальная программа — драйвер принтера или SGML-браузер — руководствуется этим описанием для печати или отображения документа на экране дисплея.
В это же время выявилась еще одна, самая важная область применения языков разметки — поиск и выборка информации. В настоящее время подавляющее большинство информации хранится в реляционных базах данных. Они удобны для хранения и поиска сведений, представимых в виде таблиц: анкет, ведомостей, списков и т. п., но неудобны для хранения различных документов, планов, отчетов, статей, книг, не представимых в виде таблицы. Тегами языка разметки можно задать структурную, а не визуальную разметку документа, разбить документ на главы, параграфы и абзацы или на какие-то другие элементы, выделить важные для поиска участки документа. Легко написать программу, анализирующую размеченный такими тегами документ и извлекающую из него нужную информацию.
Язык SGML оказался слишком сложным, требующим тщательного и объемистого описания элементов создаваемого с его помощью языка. Он применяется только в крупных проектах, например для создания единой системы документооборота крупной фирмы. Скажем, man-страницы Solaris Operational Environment написаны на специально сделанной реализации языка SGML.
Золотой серединой между языками SGML и HTML стал язык XML (eXtensible Markup Language) — расширяемый язык разметки. Это подмножество языка SGML, избавленное от излишней сложности, но позволяющее разработчику Web-страниц создавать собственные теги. Язык XML достаточно широк, чтобы можно было создать все нужные теги, и достаточно прост, чтобы можно было быстро их описать.
Организуя описание документа на языке XML, надо прежде всего продумать структуру документа. Приведем пример. Пусть мы решили, наконец, упорядочить записную книжку с адресами и телефонами. В ней записаны фамилии, имена и отчества родственников, сослуживцев и знакомых, дни их рождения, адреса, состоящие из почтового индекса, города, улицы, дома и квартиры, и телефоны, если они есть: рабочие и домашние. Мы придумываем теги для выделения каждого из этих элементов, продумываем вложенность элементов и получаем структуру, показанную в листинге 28.1.
Листинг 28.1. Пример XML-документа
<?xml version=,,1.0n encoding=,,Windows-1251n?>
<!DOCTYPE notebook SYSTEM "ntb.dtd">
<notebook>
<person>
<name>
<first-name>MBaH</first-name> <second-name>neTpoBH4</second-name> ^игпате>Сидоров</surname>
</name>
<birthday>25.03.1977</birthday>
<address>
<street>Садовая, 23-15</street>
<с^у>Урюпинск</city> <zip>123456</zip>
</address>
<phone-list>
<work-phone>2654321</work-phone>
<work-phone>2654023</work-phone>
<home-phone>3456781</home-phone>
</phone-list>
</person>
<person>
<name>
<first-name>Мария</first-name> <second-name>neTpoBHa</second-name> <surname>Сидорова</surname>
</name>
<birthday>17.05.1969</birthday> <address>
<street>Ягодная, 17</street> <city>Жмeринка</city>
<zip>234561</zip>
</address>
<phone-list>
<home-phone>2334455</home-phone>
</phone-list>
</person>
</notebook>
Документ XML начинается с необязательного пролога, состоящего из двух частей.
В первой части пролога — объявлении XML (XML declaration), — записанной в первой строке листинга 28.1, указывается версия языка XML, необязательная кодировка документа и отмечается, зависит ли этот документ от других документов XML (standalone="yes"/"no"). По умолчанию принимается кодировка UTF-8.
Все элементы документа XML обязательно должны содержаться в корневом элементе (root element), в листинге 28.1 это элемент <notebook>. Имя корневого элемента считается именем всего документа и указывается во второй части пролога, называемой объявлением типа документа (document type declaration). (Не путайте с определением типа документа DTD!) Имя документа записывается после слова doctype. Объявление типа документа записано во второй строке листинга 28.1. В этой части пролога после слова doctype и имени документа в квадратных скобках идет описание DTD:
<!DOCYPE notebook [ Сюда заносится описание DTD ]>
Очень часто описание DTD составляется сразу для нескольких документов XML. В таком случае его удобно записать отдельно от документа. Если описание DTD отделено от документа, то во второй части пролога вместо квадратных скобок указывается одно из слов: system или public. За словом system идет URI файла с описанием DTD, а за словом public, кроме того, можно записать дополнительную информацию.
Документ XML состоит из элементов. Элемент начинается открывающим тегом, далее идет необязательное тело элемента, потом — закрывающий тег:
<Открывающий тег>Тело элемента</Закрывающий тег>
Закрывающий тег содержит наклонную черту, после которой повторяется имя открывающего тега.
Язык XML, в отличие от языка HTML, требует обязательно записывать закрывающие теги. Если у элемента нет тела и закрывающего тега (empty — пустой элемент), то его открывающий тег должен заканчиваться символами "/>", например:
<br />
Внимание!
Сразу надо сказать, что язык XML, в отличие от HTML, различает регистры букв.
Из листинга 28.1 видно, что элементы документа XML могут быть вложены друг в друга. Надо следить за тем, чтобы элементы не пересекались, а полностью вкладывались друг в друга. Как уже говорилось ранее, все элементы, составляющие документ, вложены в корневой элемент этого документа. Тем самым документ наделяется структурой дерева вложенных элементов. На рис. 28.1 показана структура адресной книжки, описанной в листинге 28.1.
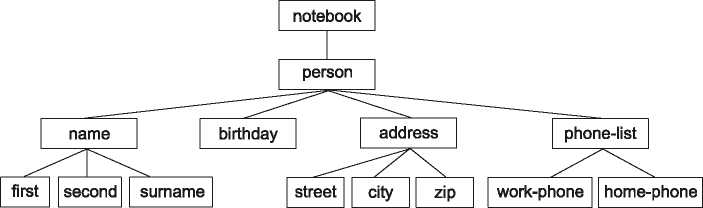 Рис. 28.1. Дерево элементов документа XML
Рис. 28.1. Дерево элементов документа XML
У открывающих тегов XML могут быть атрибуты. Например, имя, отчество и фамилию можно записать как атрибуты first, second и surname тега <name>:
<name first="Иван" second="Пeтрович" surname="Сидоров" />
В отличие от языка HTML в языке XML значения атрибутов обязательно надо заключать в кавычки или в апострофы.
Атрибуты удобны для описания простых значений. У каждого гражданина России, уважающего паспортный режим, обязательно есть одно имя, одно отчество и одна фамилия. Их лучше записывать атрибутами. Но у гражданина России может быть несколько телефонов, поэтому их номера удобнее оформить как элементы <work-phone> и <home-phone>, вложенные в элемент <phone-list>, а не атрибуты открывающего тега <phone-
list>. Заметьте, что элемент <name> с атрибутами пустой, у него нет тела, следовательно, не нужен закрывающий тег. Поэтому тег <name> с атрибутами завершается символами "/>". В листинге 28.2 приведена измененная адресная книжка.
Листинг 28.2. Пример XML-документа с атрибутами в открывающем теге
<?xml version="1.0" encoding="Windows-1251"?>
<!DOCTYPE notebook SYSTEM "ntb.dtd">
<notebook>
<person>
<name first=,,Иван,, second="Пeтрович" surname=,,Сидоров,, /> <birthday>25.03.1977</birthday>
<address>
<street>Садовая, 23-15</street>
<city>Урюпинск</city>
<zip>123456</zip>
</address>
<phone-list>
<work-phone>2654321</work-phone>
<work-phone>2654023</work-phone>
<home-phone>3456781</home-phone>
</phone-list>
</person>
<person>
<name first=,,Мария,, second="Пeтровна" surname=,,Сидорова,, />
<birthday>17.05.1969</birthday>
<address>
<stгeet>Ягодная, 17</street>
<с^у>Жмеринка</ city>
<zip>234561</zip>
</address>
<phone-list>
<home-phone>2334455</home-phone>
</phone-list>
</person>
</notebook>
Атрибуты открывающего тега удобны и для указания типа элемента. Например, мы не уточняем, в городе живет наш родственник, в поселке или в деревне. Можно ввести в тег <city> атрибут type, принимающий одно из значений: город, поселок, деревня. Например:
<city type="город">Москва</city>
Для описания адресной книжки нам понадобились открывающие теги <notebook>,
<person>, <name>, <address>, <street>, <city>, <zip>, <phone-list>, <work-phone>, <home-phone> и
соответствующие им закрывающие теги, помеченные наклонной чертой. Теперь необходимо дать их описание. В описании указываются только самые общие признаки логической взаимосвязи элементов и их тип.
? Элемент <notebook> может содержать ни одного, один или более одного элемента <person> и больше ничего.
? Элемент <person> содержит ровно один элемент <name>, ни одного, один или несколько элементов <address> и ни одного или только один элемент <phone-list>.
? Элемент <name> пустой.
? В открывающем теге <name> три атрибута: first, second, surname, значения которых — строки символов.
? Элемент <address> содержит по одному элементу <street>, <city> и <zip>.
? Элементы <street> и <city> имеют по одной текстовой строке.
? Элемент <zip> содержит одно целое число.
? У открывающего тега <city> есть один необязательный атрибут type, принимающий одно из трех значений: город, поселок или деревня. Значение по умолчанию — город.
? Необязательный элемент <phone-list> содержит ни одного, один или несколько элементов <work-phone> и <home-phone>.
? Элементы <work-phone> и <home-phone> содержат по одной строке, состоящей только из цифр.
Это словесное описание, называемое схемой документа XML, формализуется несколькими способами. Наиболее распространены два способа: можно сделать описание DTD, пришедшее в XML из SGML, или описать схему на языке XSD (XML Schema Definition Language).
Описание DTD
Описание DTD нашей адресной книжки записано в листинге 28.3.
Листинг 28.3. Описание DTD документа XML
<!ELEMENT notebook (person)*>
<!ELEMENT person (name, birthday?, address*, phone-list?)> <!ELEMENT name EMPTY>
<!ATTLIST name
first CDATA #IMPLIED second CDATA #IMPLIED surname CDATA #REQUIRED>
<!ELEMENT birthday (#PCDATA)> <!ELEMENT address (street, city, zip)?>
<!ELEMENT street (#PCDATA)>
<! ELEMENT city (#PCDATA)>
<!ATTLIST city
type (город | поселок | деревня) "город">
<!ELEMENT zip (#PCDATA)>
<!ELEMENT phone-list (work-phone*, home-phone*)>
<!ELEMENT work-phone (#PCDATA)>
<!ELEMENT home-phone (#PCDATA)>
Как видите, описание DTD почти очевидно. Оно повторяет приведенное ранее словесное описание. Первое слово element означает, что элемент может содержать тело с вложенными элементами. Вложенные элементы перечисляются в круглых скобках. Порядок перечисления вложенных элементов в скобках должен соответствовать порядку их появления в документе. Слово empty в третьей строке листинга 28.3 означает пустой элемент.
Слово attlist начинает описание списка атрибутов элемента. Для каждого атрибута указывается имя, тип и обязательность присутствия атрибута. Типов атрибута всего девять, но чаще всего употребляется тип cdata (Character DATA), означающий произвольную строку символов Unicode, или перечисляются значения типа. Так сделано в описании атрибута type тега <city>, принимающего одно из трех значений: город, поселок или деревня. В кавычках показано значение по умолчанию — город.
Обязательность указания атрибута отмечается одним из трех слов:
? #required — атрибут обязателен;
? #implied — атрибут необязателен;
? #fixed — значение атрибута фиксировано, оно задается в DTD.
Первым словом могут быть, кроме слов element или attlist, слова any, mixed или entity. Слова any и mixed означают, что элемент может содержать и простые данные и/или вложенные элементы. Слово entity служит для обозначения или адреса данных, приведенного в описании DTD, так называемой сущности.
После имени элемента в скобках записываются вложенные элементы или тип данных, содержащихся в теле элемента. Тип pcdata (Parsed Character DATA) означает строку символов Unicode, которую надо интерпретировать. Тип cdata — строку символов Unicode, которую не следует интерпретировать.
Звездочка, записанная после имени элемента, означает "нуль или более вхождений" элемента, после которого она стоит, а плюс — "одно или более вхождений". Вопросительный знак означает "нуль или один раз". Если эти символы относятся ко всем вложенным элементам, то их можно указать после круглой скобки, закрывающей список вложенных элементов.
Описание DTD можно занести в отдельный файл, например ntb.dtd, указав его имя во второй части пролога, как показано во второй строке листингов 28.1 и 28.2. Можно включить описание во вторую часть пролога XML-файла, заключив его в квадратные скобки:
<!DOCTYPE notebook [ Описание DTD ]>
После того как создано описание DTD нашей реализации XML и написан документ, размеченный тегами этой реализации, следует проверить правильность их написания. Для этого есть специальные программы — проверяющие анализаторы (validating parsers). Все фирмы, разрабатывающие средства для работы с XML, выпускают бесплатные или коммерческие проверяющие анализаторы.
Проверяющий анализатор корпорации Sun Microsystems содержится в пакете классов JAXP (Java API for XML Processing), входящем в состав Java SE. Кроме того, этот пакет можно загрузить отдельно с адреса http://jaxp.java.net/.
Корпорация Microsoft поставляет проверяющий анализатор MSXML (Microsoft XML Parser), доступный по адресу http://msdn.microsoft.com/xml/.
Есть еще множество проверяющих анализаторов, но лидером среди них является, пожалуй, Apache Xerces2, входящий во многие средства обработки документов XML, выпускаемые другими фирмами. Он свободно доступен по адресу http://xerces.apache.org/ xerces2-j/.
Ограниченные средства DTD не позволяют полностью описать структуру документа XML. В частности, описание DTD не указывает точное количество повторений вложенных элементов, оно не задает точный тип тела элемента. Например, в листинге 28.3 из описания DTD не видно, что в элементе <birthday> содержится дата рождения. Эти недостатки DTD привели к появлению других схем описания документов XML. Наиболее развитое описание дает язык XSD. Мы будем называть описание на этом языке просто схемойXML (XML Schema).
Посмотрим, как создаются схемы XML, но сначала познакомимся еще с одним понятием XML — пространством имен.
Пространства имен XML
Поскольку в разных языках разметок — реализациях XML — могут встретиться одни и те же имена тегов и их атрибутов, имеющие совершенно разный смысл, а в документе XML их часто приходится смешивать, анализатору надо дать возможность их как-то различать. В языке Java мы имена полей класса уточняем именем класса, а имена классов уточняем указанием пакета, что позволяет назвать поле просто именем a, применяя при необходимости полное имя, что-нибудь вроде com.mydomain.myhost.mypack.MyClass.a. При этом рекомендуется пакет для уникальности называть доменным именем сайта разработчика, записывая его справа налево.
В языке XML принята подобная схема: локальное имя уточняется идентификатором. Идентификатор должен быть уникальным во всем Интернете, поэтому им должна быть строка символов, имеющая форму адреса URI. Адрес может соответствовать или не соответствовать какому-то реальному сайту Интернета, это не важно. Важно, чтобы он не повторялся в Интернете, можно записать, например, строку http://some.firm.com/ 2008/ntbml. Все имена с одним и тем же идентификатором образуют одно пространство имен (namespace).
Поскольку идентификатор пространства имен получается весьма длинным, было бы очень неудобно всегда записывать его перед локальным именем. В языке Java для сокращения записи имен мы используем оператор import. В XML принят другой подход.
В каждом документе идентификатор пространства имен связывается с некоторым коротким префиксом, отделяемым от локального имени двоеточием. Префикс определяется атрибутом xmlns следующим образом:
<ntb:notebook xmlns:ntb = "http://some.firm.com/2008/ntbml">
Как видите, префикс ntb только что определен, но его уже можно использовать в имени
ntb:notebook.
После такого описания имена тегов и атрибутов, которые мы хотим отнести к пространству имен http://some.firm.com/2008/ntbml, снабжаются префиксом ntb, например:
<ntb:city ntb:type="посeлок">Горeлово</ntb:city>
Имя вместе с префиксом, например ntb:city, называется расширенным или уточненным именем (Qualified Name, QName).
Хотя идентификатор пространства имен записывается в форме адреса URI, такого как http://some.firm.com/2008/ntbml, анализатор документа XML и другие программы, использующие документ, не будут обращаться по этому адресу. Там даже может не быть никакой Web-странички вообще. Просто идентификатор пространства имен должен быть уникальным во всем Интернете, и разработчики рекомендации по применению пространства имен, которую можно посмотреть по адресу http://www.w3.org/TR/REC-xml-names, справедливо решили, что будет удобно использовать для него DNS-имя сайта, на котором размещено определение пространства имен. Смотрите на URI просто как на строку символов, идентифицирующую пространство имен. Обычно указывается URL фирмы, создавшей данную реализацию XML, или имя файла с описанием схемы XML.
Поскольку идентификатор — это строка символов, то и сравниваются они как строки, с учетом регистра символов. Например, идентификатор http://some.firm.com/2008/Ntbml будет считаться XML-анализатором, отличным от идентификатора http://some.firm.com/ 2008/ntbml, введенного нами ранее, и будет определять другое пространство имен.
По правилам SGML и XML двоеточие может применяться в именах как обычный символ, поэтому имя с префиксом — это просто фокус, анализатор рассматривает его как обычное имя. Отсюда следует, что в описании DTD нельзя опускать префиксы имен. Некоторым анализаторам надо специально указать необходимость учета пространства имен. Например, при работе с анализатором Xerces следует применить метод
setNamespaceAware(true).
Атрибут xmlns, определяющий префикс имен, может появиться в любом элементе XML, а не только в корневом элементе. Определенный им префикс можно применять в том элементе, в котором записан атрибут xmlns, и во всех вложенных в него элементах. Больше того, в одном элементе можно определить несколько пространств имен:
<ntb:notebook xmlns:ntb = "http://some.firm.com/2008/ntbml"
xmlns:bk = "http://some.firm.com/2008/bookml">
Появление имени тега без префикса в документе, использующем пространство имен, означает, что имя принадлежит пространству имен по умолчанию (default namespace). Например, язык XHTML допускает применение тегов HTML и XML в одном документе. Допустим, мы определили тег с именем title. Чтобы анализатор не принял его за один из тегов HTML, поступаем следующим образом: <html xmlns = "http://www.w3.org/1999/xhtml"
xmlns:ntb = "http://some.firm.com/2002/ntbml">
<head>
<title>MoH 6H6mHOTeKa</title>
</head>
<body>
<ntb:book>
<ntb:title>Созданиe Java Web Services</ntb:title>
</ntb:book>
</body>
</html>
В этом примере пространством имен по умолчанию становится пространство имен XHTML, имеющее общеизвестный идентификатор http://www.w3.org/1999/xhtml, и теги, относящиеся к этому пространству имен, записываются без префикса.
Атрибуты никогда не входят в пространство имен по умолчанию. Если имя атрибута записано без префикса, то это означает, что атрибут не относится ни к одному пространству имен.
Префикс имени не относится к идентификатору пространства имен и может быть разным в разных документах. Например, в каком-нибудь другом документе мы можем написать корневой элемент
<nb:notebook xmlns:nb = "http://some.firm.com/2008/ntbml">
и записывать элементы с префиксом nb:
<nb:city nb:type="nocemoK,,>ropemoBO</nb: city>
Более того, можно связать несколько префиксов с одним и тем же идентификатором пространства имен даже в одном документе, но это может привести к путанице, поэтому применяется редко.
Теперь, после того как мы ввели понятие пространства имен, можно обратиться к схеме XML.
Схема XML
В мае 2001 года консорциум W3C рекомендовал описывать структуру документов XML на языке описания схем XSD (XML Schema Definition Language). На этом языке составляются схемы XML (XML Schema), описывающие элементы документов XML.
Схема XML сама записывается как документ XML. Его элементы называют компонентами (components), чтобы отличить их от элементов описываемого документа XML. Корневой компонент схемы носит имя <schema>. Компоненты схемы описывают элементы XML и определяют различные типы элементов. Рекомендация схемы XML, которую можно найти по ссылкам, записанным по адресу http://www.w3.org/XML/Schema.html, перечисляет 13 типов компонентов, но наиболее важны компоненты, определяющие простые и сложные типы элементов, сами элементы и их атрибуты.
Язык XSD различает простые и сложные элементы XML. Простыми (simple) элементами описываемого документа XML считаются элементы, не содержащие атрибутов и
вложенных элементов. Соответственно, сложные (complex) элементы содержат атрибуты и/или вложенные элементы. Схема XML описывает простые типы — типы простых элементов, и сложные типы — типы сложных элементов.
Язык описания схем содержит много встроенных простых типов. Они перечислены в следующем разделе.
Встроенные простые типы XSD
Встроенные типы языка описания схем XSD позволяют записывать двоичные и десятичные целые числа, вещественные числа, дату и время, строки символов, логические значения, адреса URI. Рассмотрим их по порядку.
Вещественные числа
Вещественные числа в языке XSD разделены на три типа: decimal, float и double.
Тип decimal составляют вещественные числа, записанные с фиксированной точкой: 123.45, -0.1234567689345 и т. д. Фактически хранятся два целых числа: мантисса и порядок. Спецификация языка XSD не ограничивает количество цифр в мантиссе, но требует, чтобы можно было записать не менее 18 цифр. Этот тип легко реализуется классом java.math.BigDecimal, описанным в главе 4.
Типы float и double соответствуют стандарту IEEE754-85 и одноименным типам Java. Они записываются с фиксированной или с плавающей десятичной точкой.
Целые числа
Основной целый тип integer понимается как подтип типа decimal, содержащий числа с нулевым порядком. Это целые числа с любым количеством десятичных цифр: -34567, 123456789012345 и т. д. Данный тип легко реализуется классом java.math.BigInteger, описанным в главе 4.
Типы long, int, short и byte полностью соответствуют одноименным типам Java. Они понимаются как подтипы типа integer, типы более коротких чисел считаются подтипами более длинных чисел: тип byte — это подтип типа short, оба они подтипы типа int и т. д.
Типы nonPositiveInteger и negativeInteger — подтипы типа integer — составлены из неположительных и отрицательных чисел соответственно с любым количеством цифр.
Типы nonNegativeInteger и positiveInteger — подтипы типа integer — составлены из неотрицательных и положительных чисел соответственно с любым количеством цифр.
У типа nonNegativeInteger есть подтипы беззнаковых целых чисел unsignedLong, unsignedInt, unsignedShort и unsignedByte.
Строки символов
Основной символьный тип string описывает произвольную строку символов Unicode. Его можно реализовать классом java.lang.String.
Тип normalizedString — подтип типа string — это строки, не содержащие символы перевода строки ' ', возврата каретки ' ' и символы горизонтальной табуляции ' '.
В строках типа token — подтипа типа normalizedString — нет, кроме того, начальных и завершающих пробелов и нет нескольких подряд идущих пробелов.
В типе token выделены три подтипа. Подтип language определен для записи названия языка согласно RFC 1766, например: ru, en, de, fr. Подтип nmtoken используется только в атрибутах для записи их перечисляемых значений. Подтип name составляют имена XML — последовательности букв, цифр, дефисов, точек, двоеточий, знаков подчеркивания, начинающиеся с буквы (кроме зарезервированной последовательности букв X, x, м, m, l, l в любом сочетании регистров) или знака подчеркивания. Двоеточие в значениях типа name используется для выделения префикса пространства имен.
Из типа name выделен подтип NCName (Non-Colonized Name) имен, не содержащих двоеточия, в котором, в свою очередь, определены три подтипа: id, entity, idref, описывающие идентификаторы XML, сущности и перекрестные ссылки.
Дата и время
Тип duration описывает промежуток времени, например запись P1Y2M3DT10H30M45S означает один год (1y), два месяца (2м), три дня (3d), десять часов (10h), тридцать минут (30м) и сорок пять секунд (45s). Запись может быть сокращенной, например P120M означает 120 месяцев, а T120M — 120 минут.
Тип dateTime содержит дату и время в формате CCYY-MM-DDThh:mm:ss, например 2008 — 04 — 25Т09:30: 05. Остальные типы выделяют какую-либо часть даты или времени.
Тип time содержит время в обычном формате hh:mm:ss.
Тип date содержит дату в формате ccyy-mm-dd.
Тип gYearMonth выделяет год и месяц в формате CCYY-MM.
Тип gMonthDay содержит месяц и день месяца в формате -mm-dd.
Тип gYear означает год в формате CCYY, тип gMonth- месяц в формате -mm-, тип gDay —
день месяца в формате -dd.
Двоичные типы
Двоичные целые числа записываются либо в шестнадцатеричной форме без всяких дополнительных символов: 0B2F, 356C0A и т. д., это тип hexBinary, либо в кодировке Base64,
это тип base64Binary.
Прочие встроенные простые типы
Еще три встроенных простых типа описывают значения, часто используемые в документах XML.
Адреса URI относятся к типу anyURI.
Расширенное имя тега или атрибута (qualified name), т. е. имя вместе с префиксом, отделенным от имени двоеточием,-это тип QName.
Элемент notation описания DTD выделен как отдельный простой тип схемы XML. Его используют для записи математических, химических и других символов, нот, азбуки Брайля и прочих обозначений.
Определение простых типов
В схемах XML с помощью встроенных типов можно тремя способами определить новые типы простых элементов. Они вводятся как сужение (restriction) встроенного или ранее определенного простого типа, список (list) или объединение (union) простых типов.
Простой тип определяется компонентом схемы <simpleType>, имеющим вид:
<xsd:simpleType name="nw^ типа">Определение TMna</xsd:simpleType>
Сужение
Сужение простого типа определяется компонентом <restriction>, в котором атрибут base указывает сужаемый простой тип, а в теле задаются ограничения, выделяющие определяемый простой тип. Например, почтовый индекс zip можно задать как шесть арабских цифр следующим образом:
<xsd:simpleType name="zip">
<xsd:restriction base="xsd:string">
<xsd:pattern value="[0-9]{6}" />
</xsd:restriction>
</xsd:simpleType>
Можно дать другое определение простого типа zip как целого положительного числа, находящегося в диапазоне от 100 000 до 999 999:
<xsd:simpleType name="zip">
<xsd:restriction base="xsd:positiveInteger">
<xsd:minInclusive value="100000" />
<xsd:maxInclusive value="999999" />
</xsd:restriction>
</xsd:simpleType>
Теги <pattern>, <maxinclusive> и другие теги, задающие ограничения, называются фасетками (facets). Вот их список:
? <maxExclusive> — наибольшее значение, оно уже не входит в определяемый тип;
? <maxinclusive> — наибольшее значение определяемого типа;
? <minExclusive> — наименьшее значение, уже не входящее в определяемый тип;
? <mininclusive> — наименьшее значение определяемого типа;
? <totalDigits> — общее количество цифр в определяемом числовом типе — сужении типа decimal;
? <fractionDigits> — количество цифр в дробной части числа;
? <length> — длина значений определяемого типа;
? <maxLength> — наибольшая длина значений определяемого типа;
? <minLength> — наименьшая длина значений определяемого типа;
? <enumeration> — одно из перечисляемых значений;
? <pattern> — регулярное выражение [8];
? <whiteSpace> — применяется при сужении типа string и определяет способ преобразования пробельных символов ' ', ' ', ' '. Атрибут value этого тега принимает одно из трех значений:
• preserve — не убирать пробельные символы;
• replace — заменить пробельные символы пробелами;
• collapse — после замены пробельных символов пробелами убрать начальные и конечные пробелы, а из нескольких подряд идущих пробелов оставить только один.
В тегах-фасетках можно записывать следующие атрибуты, называемые базисными фасетками (fundamental facets):
? ordered — задает упорядоченность определяемого типа, принимает одно из трех значений:
• false — тип неупорядочен;
• partial — тип частично упорядочен;
• total — тип полностью упорядочен;
? bounded — задает ограниченность или неограниченность типа значениями true или
false;
? cardinality — задает конечность или бесконечность типа значениями finite или
countably infinite;
? numeric — показывает, числовой этот тип или нет, значениями true или false.
Как видно из приведенных ранее и далее примеров, в одном сужении может быть несколько ограничений-фасеток. При этом фасетки <pattern> и <enumeration> задают независимые друг от друга ограничения, их можно мысленно объединить союзом "или". Остальные фасетки задают общие, совместно накладываемые ограничения, их можно мысленно объединить союзом "и".
Список
Простой тип-список — это тип элементов, в теле которых записывается, через пробел, несколько значений одного и того же простого типа. Например, в документе XML может встретиться такой элемент, содержащий список целых чисел:
<days>21 34 55 46</days>
Список определяется компонентом <list>, в котором атрибутом itemType указывается тип элементов определяемого списка. Тип элементов списка можно указать и в теле элемента <list>. Например, показанный ранее элемент документа XML <days> можно определить в схеме так:
<xsd:element name="days" type="listOfInteger" />
а использованный при его определении тип listOfInteger задать как список не более чем из пяти целых чисел следующим образом:
<xsd:simpleType name="listOfInteger">
<xsd:restriction>
<xsd:simpleType>
<xsd:list itemType="xsd:integer" />
</xsd:simpleType>
<xsd:maxLength value="5" />
</xsd:restriction>
</xsd:simpleType>
При определении списка можно применять фасетки <length>, <minLength>, <maxLength>, <enumeration>, <pattern>. В приведенном примере список — тело элемента <days> — не может содержать более пяти чисел.
Объединение
Простой тип-объединение определяется компонентом <union>, в котором атрибутом memberTypes можно указать имена объединяемых типов. Например:
<xsd:union memberTypes="xsd:string xsd:integer listOfInteger" />
Другой способ — записать в теле компонента <union> определения простых типов, входящих в объединение. Например:
<xsd:attribute name="size">
<xsd:simpleType>
<xsd:union>
<xsd:simpleType>
<xsd:restriction base="xsd:positiveInteger">
<xsd:minInclusive value="8"/>
<xsd:maxInclusive value="72"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType>
<xsd:restriction base="xsd:NMTOKEN">
<xsd:enumeration value="small"/>
<xsd:enumeration value="medium"/>
<xsd:enumeration value="large"/>
</xsd:restriction>
</xsd:union>
</xsd:simpleType>
</xsd:attribute>
После этого атрибут size можно использовать, например, так:
<font size^large'XTnaBa 28</font>
<font size=,12,>Простой TeKCT</font>
Описание элементов и их атрибутов
Элементы, которые будут применяться в документе XML, описываются в схеме компонентом <element>:
<xsd:element name="HM^ элемента" type="тип элемента"
minOccurs="наименьшее число появлений элемента в документе" maxOccurs="наибольшее число появлений" />
Значение по умолчанию необязательных атрибутов minOccurs и maxOccurs равно 1. Это означает, что если эти атрибуты отсутствуют, то элемент должен появиться в документе XML ровно один раз. Определение типа элемента можно вынести в тело элемента
<element>:
<xsd:element name="имя элемента" >
Определение типа элемента </xsd:element>
Описание атрибута элемента тоже несложно:
<xsd:attribute name="имя? атрибута" type="тип атрибута"
use="обязательность атрибута" default="значение по умолчанию" />
Необязательный атрибут use принимает три значения:
? optional — описываемый атрибут необязателен (это значение по умолчанию);
? required — описываемый атрибут обязателен;
? prohibited — описываемый атрибут неприменим. Это значение полезно при определении подтипа, чтобы отменить некоторые атрибуты базового типа.
Если описываемый атрибут необязателен, то атрибутом default можно задать его значение по умолчанию.
Определение типа атрибута — а это должен быть простой тип — можно вынести в тело элемента <attribute>:
<xsd:attribute name="имя? атрибута">
Тип атрибута </xsd:attribute>
Определение сложных типов
Напомним, что тип элемента называется сложным, если в элемент вложены другие элементы и/или в открывающем теге элемента есть атрибуты.
Сложный тип определяется компонентом <complexType>, имеющим вид:
<xsd:complexType name=" имя типа" >Определение типа</xsd:complexType>
Необязательный атрибут name задает имя типа, а в теле компонента <complexType> описываются элементы, входящие в сложный тип, и/или атрибуты открывающего тега.
Определение сложного типа можно разделить на определение типа пустого элемента, элемента с простым телом и элемента, содержащего вложенные элементы. Рассмотрим эти определения подробнее.
Определение типа пустого элемента
Проще всего определяется тип пустого элемента — элемента, не имеющего тела, а содержащего только атрибуты в открывающем теге. Таков, например, элемент <name> из листинга 28.2. Каждый атрибут описывается одним компонентом <attribute>, например:
<xsd:complexType name="imageType">
<xsd:attribute name="href" type="xsd:anyURI" />
</xsd:complexType>
После этого определения можно в схеме описать элемент <image> типа imageType:
<xsd:element name="image" type="imageType" />
а в документе XML использовать это описание:
<image href="http://some.com/images/myface.gif" />
Определение типа элемента с простым телом
Немного сложнее описание элемента, содержащего тело простого типа и атрибуты в открывающем теге. Этот тип отличается от простого типа только наличием атрибутов и определяется компонентом <simpleContent>. В теле данного компонента должен быть либо компонент <restriction>, либо компонент <extension>, атрибутом base задающий тип (простой) тела описываемого элемента.
В компоненте <extension> описываются атрибуты открывающего тега описываемого элемента. Все вместе выглядит так, как в следующем примере:
<xsd:complexType name="calcResultType">
<xsd:simpleContent>
<xsd:extension base="xsd:decimal">
<xsd:attribute name="unit" type="xsd:string" />
<xsd:attribute name="precision"
type="xsd:nonNegativeInteger" />
</xsd:extension>
</xsd:simpleContent>
</xsd:complexType>
Эту конструкцию можно описать словами так: "Определяется тип calcResultType элемента, тело которого содержит значения встроенного простого типа xsd:decimal. Простой тип расширяется тем, что к нему добавляются атрибуты unit и precision".
Если в схеме описать элемент <result> этого типа следующим образом:
<xsd:element name="result" type="calcResultType" />
то в документе XML можно написать
<result unit="cM" precision="2">123.25</result>
В компоненте <restriction> кроме атрибутов описывается простой тип тела элемента и/или фасетки, ограничивающие тип, заданный атрибутом base. Например:
<xsd:complexType name="calcResultType">
<xsd:simpleContent>
<xsd:restriction base="xsd:decimal">
<xsd:totalDigits value="8" />
<xsd:attribute name="unit" type="xsd:string" />
<xsd:attribute name="precision"
type="xsd:nonNegativeInteger" />
</xsd:restriction>
</xsd:simpleContent>
</xsd:complexType>
Определение типа вложенных элементов
Если значениями определяемого сложного типа будут элементы, содержащие вложенные элементы, как, например, элементы <address>, <phone-list> листинга 28.2, то перед перечислением описания вложенных элементов надо выбрать модель группы (model group) вложенных элементов. Дело в том, что вложенные элементы, составляющие определяемый тип, могут появляться или в определенном порядке, или в произвольном порядке, кроме того, можно выбирать только один из перечисленных элементов. Эта возможность и называется моделью группы элементов. Она определяется одним из трех компонентов: <sequence>, <all> или <choice>.
Компонент <sequence> применяется в том случае, когда перечисляемые элементы должны записываться в документе в конкретном порядке. Пусть, например, мы описываем книгу. Сначала определяем тип:
<xsd:complexType name="bookType">
<xsd:sequence maxOccurs="unbounded">
<xsd:element name="author" type="xsd:normalizedString" minOccurs="0" />
<xsd:element name="title" type="xsd:normalizedString" />
<xsd:element name="pages" type="xsd:positiveInteger" minOccurs="0" />
<xsd:element name="publisher" type="xsd:normalizedString" minOccurs="0" />
</xsd:sequence>
Потом описываем элемент:
<xsd:element name="book" type="bookType" />
Элементы <author>, <title>, <pages> и <publisher> должны входить в элемент <book> именно в таком порядке. В документе XML надо писать:
<book>
<author>H. Ильф, Е. neTpoB</author>
^^^>Золотой тeлeнок</title>
<publisher>Художeствeнная литература</publisher>
</book>
Если же вместо компонента <xsd:sequence> записать компонент <xsd:all>, то элементы
<author>, <title>, <pages> и <publisher> можно перечислять в любом порядке.
Компонент <choice> применяется в том случае, когда надо выбрать один из нескольких элементов. Например, при описании журнала вместо издательства, описываемого элементом <publisher>, следует записать название журнала. Это можно определить так:
<xsd:complexType name="bookType">
<xsd:sequence maxOccurs="unbounded">
<xsd:element name="author" type="xsd:normalizedString" minOccurs="0" />
<xsd:element name="title" type="xsd:normalizedString" />
<xsd:element name="pages" type="xsd:positiveInteger" minOccurs="0" />
<xsd:choice>
<xsd:element name="publisher" type="xsd:normalizedString" minOccurs="0" />
<xsd:element name="magazine" type="xsd:normalizedString" minOccurs="0" />
</xsd:choice>
</xsd:sequence>
</xsd:complexType>
Как видно из приведенного примера, компонент <choice> можно вложить в компонент <sequence>. Можно, наоборот, вложить компонент <sequence> в компонент <choice>. Такие вложения допустимо проделывать сколько угодно раз. Кроме того, каждая группа в этих моделях может появиться сколько угодно раз, т. е. в компоненте <choice> тоже разрешено записать атрибут maxOccurs="unbounded".
Модель группы <all> отличается в этом от моделей <sequence> и <choice>. В компоненте <all> не допускается применение компонентов <sequence> и <choice>. Обратно, в компонентах <sequence> и <choice> нельзя применять компонент <all>. Каждый элемент, входящий в группу модели <all>, может появиться не более одного раза, т. е. атрибут maxOccurs этого элемента может равняться только единице.
Определение типа со сложным телом
При определении сложного типа можно воспользоваться уже определенным, базовым, сложным типом, расширив его дополнительными элементами или, наоборот, удалив из него некоторые элементы. Для этого надо применить компонент <complexContent>. В этом компоненте, так же как и в компоненте <simpleContent>, записывается либо компонент <extension>, если нужно расширить базовый тип, либо компонент <restriction>, если необходимо сузить базовый тип. Базовый тип указывается атрибутом base, так же как и при записи компонента <simpleContent>, но теперь это должен быть сложный, а не простой тип!
Расширим, например, определенный ранее тип bookType, добавив год издания — элемент <year>:
<xsd:complexType name="newBookType">
<xsd:complexContent>
<xsd:extension base="bookType">
<xsd:sequence>
<xsd:element name="year" type="xsd:gYear">
</xsd:sequence>
</xsd:extension>
</xsd:complexContent>
</xsd:complexType>
При сужении базового типа компонентом <restriction> надо перечислить те элементы, которые останутся после сужения. Например, оставим в типе newbookType только автора и название книги из типа bookType:
<xsd:complexType name="newBookType">
<xsd:complexContent>
<xsd:restriction base="bookType">
<xsd:sequence>
<xsd:element name="author" type="xsd:normalizedString" minOccurs="0" />
<xsd:element name="title" type="xsd:normalizedString" />
</xsd:sequence>
</xsd:restriction>
</xsd:complexContent>
</xsd:complexType>
Это описание выглядит странно. Почему надо заново описывать все элементы, остающиеся после сужения? Не проще ли определить новый тип?
Дело в том, что в язык XSD внесены элементы объектно-ориентированного программирования, которых мы не будем касаться. Расширенный и суженный типы связаны со своим базовым типом отношением наследования, и к ним можно применить операцию подстановки. У всех типов языка XSD есть общий предок базовый тип anyType. От
него наследуются все сложные типы. Это подобно тому, как у всех классов Java есть общий предок — класс Object, а все массивы наследуются от него. От базового типа anyType наследуется и тип anySimpleType — общий предок всех простых типов.
Таким образом, сложные типы определяются как сужение типа anyType. Если строго подходить к определению сложного типа, то определение типа bookType, сделанное в начале предыдущего раздела, надо записать так:
<xsd:complexType name="bookType">
<xsd:complexContent>
<xsd:restriction base="xsd:anyType">
<xsd:sequence maxOccurs="unbounded">
<xsd:element name="author" type="xsd:normalizedString" minOccurs="0" />
<xsd:element name="title" type="xsd:normalizedString" />
<xsd:element name="pages" type="xsd:positiveInteger" minOccurs="0" />
<xsd:element name="publisher" type="xsd:normalizedString" minOccurs="0" />
</xsd:sequence>
</xsd:restriction>
</xsd:complexContent>
</xsd:complexType>
Рекомендация языка XSD позволяет сократить эту запись, что мы и сделали в предыдущем разделе. Это подобно тому, как в Java мы опускаем слова "extends Object" в заголовке описания класса.
Закончим на этом описание языка XSD и перейдем к примерам.
Пример: схема адресной книги
В листинге 28.4 записана схема документа, приведенного в листинге 28.2.
Листинг 28.4. Схема документа XML
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:ntb="http://some.firm.com/2011/ntbNames" targetNamespace="http://some.firm.com/2011/ntbNames">
<xsd:element name="notebook" type="ntb:notebookType" />
<xsd:complexType name="notebookType">
<xsd:element name="person" type="ntb:personType"
minOccurs="0" maxOccurs="unbounded" />
<xsd:complexType name="personType">
<xsd:sequence>
<xsd:element name="name">
<xsd:complexType>
<xsd:attribute name="first" type="xsd:string" use="optional" />
<xsd:attribute name="second" type="xsd:string" use="optional" /> <xsd:attribute name="surname" type="xsd:string" use="required" /> </xsd:complexType>
</xsd:element>
<xsd:element name="birthday" type="ntb:ruDate" minOccurs="0" />
<xsd:element name="address" type="ntb:addressType" minOccurs="0" maxOccurs="unbounded" />
<xsd:element name="phone-list" type="ntb:phone-listType" minOccurs="0" />
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="addressType" >
<xsd:sequence>
<xsd:element name="street" type="xsd:string" />
<xsd:element name="city" type="ntb:cityType" />
<xsd:element name="zip" type="xsd:positiveInteger" />
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name='cityType'>
<xsd:simpleContent>
<xsd:extension base=,xsd:string' >
<xsd:attribute name='type' type='ntb:placeType' default=’город’ /> </xsd:extension>
</xsd:simpleContent>
</xsd:complexType>
<xsd:simpleType name="placeType">
<xsd:restriction base = "xsd:string">
<xsd:enumeration уа1ие="город" />
<xsd:enumeration уа1ие="поселок" />
<xsd:enumeration value^^epeBHH" />
</xsd:restriction>
</xsd:simpleType>
<xsd:complexType name="phone-listType">
<xsd:element name="work-phone" type="xsd:string"
minOccurs="0" maxOccurs="unbounded" />
<xsd:element name="home-phone" type="xsd:string"
minOccurs="0" maxOccurs="unbounded" />
</xsd:complexType> <xsd:simpleType name="ruDate">
<xsd:restriction base="xsd:string">
<xsd:pattern value="[0-9] {2}. [0-9]{2}.[0-9] {4}" /> </xsd:restriction>
</xsd:simpleType>
</xsd:schema>
Листинг 28.4, как обычный документ XML, начинается с пролога, показывающего версию XML и определяющего стандартное пространство имен схемы XML с идентификатором http://www.w3.org/2001/XMLSchema. Этому идентификатору дан префикс xsd. Конечно, префикс может быть другим, часто пишут префикс xs.
Еще не встречавшийся нам атрибут targetNamespace определяет идентификатор пространства имен, в которое попадут определяемые в этом документе имена типов, элементов и атрибутов, так называемое целевое пространство имен (target namespace). Этот идентификатор сразу же связывается с префиксом ntb, который тут же используется для уточнения только что определенных имен в ссылках на них.
Все описание схемы нашей адресной книжки заключено в одной третьей строке, в которой указано, что адресная книга состоит из одного элемента с именем notebook, имеющего сложный тип notebookType. Этот элемент должен появиться в документе ровно один раз. Остаток листинга 28.4 посвящен описанию типа этого элемента и других типов.
Описание сложного типа notebookType несложно (простите за каламбур). Оно занимает три строки листинга, не считая открывающего и закрывающего тега, и просто говорит о том, что данный тип составляют несколько элементов person типа personType.
Описание типа personType немногим сложнее. Оно говорит, что этот тип составляют четыре элемента: name, birthday, address и phone-list. Для элемента name сразу же указаны необязательные атрибуты first и second простого типа string, определенного в пространстве имен xsd. Тип обязательного атрибута surname тоже string.
Далее в листинге 28.4 определяются оставшиеся типы: addressType, phone-listType и ruDate. Необходимость определения простого типа ruDate возникает потому, что встроенный в схему XML тип date предписывает задавать дату в виде 2004-10-22, а в России принят формат 22.10.2004. Тип ruDate определяется как сужение (restriction) типа string с помощью шаблона. Шаблон (pattern) для записи даты в виде дц.мм.гггг задается регулярным выражением.
Безымянные типы
Все описанные в листинге 28.4 типы используются только один раз. Поэтому необязательно давать типу имя. Схема XML, как говорилось ранее, позволяет определять безымянные типы. Такое определение дается внутри описания элемента. Именно так в листинге 28.4 описаны атрибуты элемента name. В листинге 28.5 показано упрощенное описание схемы адресной книги.
Листинг 28.5. Схема документа XML с безымянными типами
<?xml version=,1.0,?>
<xsd:schema xmlns:xsd=’http://www.w3.org/2001/XMLSchema’
targetNamespace='http://some.firm.com/2011/ntbNames'>
<xsd:element name='notebook'>
<xsd:complexType>
<xsd:sequence>
<xsd:element name=iperson’ maxOccurs=iunbounded’>
<xsd:complexType>
<xsd:sequence>
<xsd:element name=’name’>
<xsd:complexType>
<xsd:attribute name=,first' type=’xsd:string’ use=’optional’ /> <xsd:attribute name='second' type=’xsd:string’ use=’optional’ /> <xsd:attribute name='surnamel type=’xsd:string’ use=’required’ /> </xsd:complexType>
</xsd:element>
<xsd:element name=’birthday’>
<xsd:simpleType>
<xsd:restriction base=’xsd:string’>
<xsd:pattern value=’[0-9]{2}.[0-9]{2}.[0-9]{4}’ /> </xsd:restriction>
</xsd:simpleType>
</xsd:element>
<xsd:element name=’address’ maxOccurs=’unbounded’>
<xsd:complexType>
<xsd:sequence>
<xsd:element name=’street’ type=’xsd:string’ />
<xsd:element name=’cityi>
<xsd:complexType>
<xsd:simpleContent>
<xsd:extension base=’xsd:string’>
<xsd:attribute name=’type’ type=’xsd:string’
use=’optional’ default=’gorod’ />
</xsd:extension>
</xsd:simpleContent>
</xsd:complexType>
</xsd:element>
<xsd:element name=’zip’ type=’xsd:positiveIntegeri />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name=’phone-list’>
<xsd:complexType>
<xsd:sequence>
<xsd:element name=’work-phone’ type=’xsd:string’
minOccurs=’0’ maxOccurs=’unbounded’ />
<xsd:element name=’home-phone’ type=’xsd:string’
minOccurs=’0’ maxOccurs=’unbounded’ />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
Еще одно упрощение можно сделать, используя пространство имен по умолчанию. Посмотрим, какие пространства имен применяются в схемах XML.
Пространства имен языка XSD
Имена элементов и атрибутов, используемые при записи схем, определены в пространстве имен с идентификатором http://www.w3.org/200i/XMLSchema. Префикс имен, относящихся к этому пространству, часто называют xs или xsd, как в листингах 28.4 и 28.5. Каждый анализатор "знает" это пространство имен и "понимает" имена из этого пространства.
Можно сделать это пространство имен пространством по умолчанию, но тогда надо обязательно определить префикс идентификатора целевого пространства имен для определяемых в схеме типов и элементов.
В листинге 28.6 для упрощения записи стандартное пространство имен схемы XML с идентификатором http://www.w3.org/2001/XMLSchema сделано пространством имен по умолчанию. Имена, относящиеся к целевому пространству имен, снабжены префиксом ntb, чтобы они не попали в пространство имен по умолчанию.
Листинг 28.6. Схема документа XML с целевым пространством имен
<?xml version=’1.0’?>
<schema xmlns=’http://www.w3.org/2001/XMLSchema’
targetNamespace=’http://some.firm.com/2011/ntbNames’ xmlns:ntb=’http://some.firm.com/2011/ntbNames’>
<element name=’notebook’>
<complexType>
<sequence>
<element name=’person’ maxOccurs=’unbounded’> <complexType>
<sequence>
<element name=’name’>
<complexType>
<attribute name=’first’ type=’string’ use=’optional’ />
<attribute name=’second’ type=’string’ use=’optional’ />
<attribute name=’surname’ type=’string’ use=’required’ />
</complexType>
</element>
<element name=’birthdayi>
<simpleType>
<restriction base=istringi>
<pattern value=i[0-9]{2}.[0-9]{2}.[0-9]{4}i />
</restriction>
</simpleType>
</element>
<element name=iaddressi maxOccurs=iunboundedi>
<complexType>
<sequence>
<element name=istreet type=istringi />
<element name=icityi type=istringi />
<element name=izipi type=ipositiveIntegeri />
</sequence>
</complexType>
</element>
<element name=iphone-lisf>
<complexType>
<sequence>
<element name=iwork-phonei type=istringi
minOccurs=i0i maxOccurs=iunboundedi/>
<element name=ihome-phonei type=istringi
minOccurs=i0i maxOccurs=iunboundedi/>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
Поскольку в листинге 28.6 пространством имен по умолчанию сделано пространство
http://www.w3.org/2001/XMLSchema, префикс xsd не нужен.
Следует заметить, что в целевое пространство имен попадают только глобальные имена, чьи описания непосредственно вложены в элемент <schema>. Это естественно, потому что лишь глобальными именами можно воспользоваться далее в этой или другой схеме. В листинге 28.6 только одно глобальное имя — <notebook>. Вложенные имена name, address и другие всего-навсего ассоциированы с глобальными именами.
В схемах и документах XML часто применяется еще одно стандартное пространство имен. Рекомендация языка XSD определяет несколько атрибутов: type, nil, schemaLocation, noNamespaceSchemaLocation, которые применяются не только в схемах, но и непосредственно в описываемых этими схемами документах XML, называемых экземплярами схем (XML schema instance). Имена этих атрибутов относятся к пространству имен http://www.w3.org/2001/XMLSchema-instance. Данному пространству имен чаще всего приписывают префикс xsi, например:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
Включение файлов схемы в другую схему
В создаваемую схему можно включить файлы, содержащие другие схемы. Для этого есть два элемента схемы: <include> и <import>. Например:
<xsd:include xsi:schemaLocation="names.xsd" />
Включаемый файл задается атрибутом xsi:schemaLocation. В примере он использован для того, чтобы включить в создаваемую схему содержимое файла names.xsd. Файл должен содержать схему с описаниями и определениями из того же пространства имен, что и в создаваемой схеме, или без пространства имен, т. е. в нем не использован атрибут targetNamespace. Это удобно, если мы хотим добавить к создаваемой схеме определения схемы names.xsd или просто хотим разбить большую схему на два файла. Можно представить себе результат включения так, как будто содержимое файла names.xsd просто записано на месте элемента <include>.
Перед включением файла можно изменить некоторые определения, приведенные в нем. Для этого используется элемент <redefine>, например:
<xsd:redefine schemaLocation="names.xsd">
<xsd:simpleType name="nameType">
<xsd:restriction base="xsd:string">
<xsd:maxLength value="40"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:redefine>
Если же включаемый файл содержит имена из другого пространства имен, то надо воспользоваться элементом схемы <import>. Например, пусть файл A.xsd начинается со следующих определений:
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema" targetNamespace="http://some.firm.com/someNames">
а файл B.xsd начинается с определений
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema" targetNamespace="http://some.firm.com/anotherNames">
Мы решили включить эти файлы в новый файл C.xsd. Это делается так:
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema" targetNamespace="http://some.firm.com/yetAnotherNames" xmlns:pr1="http://some.firm.com/someNames" xmlns:pr2="http://some.firm.com/anotherNames">
<xsd:import namespace="http://some.firm.com/someNames" xsi:schemaLocation="A.xsd" />
<xsd:import namespace="http://some.firm.com/anotherNames" xsi:schemaLocation="B.xsd" />
После этого в файле C.xsd можно использовать имена, определенные в файлах A.xsd и B.xsd, снабжая их префиксами pr1 и pr2 соответственно.
Элементы <include> и <import> следует располагать перед всеми определениями схемы.
Значение атрибута xsi:schemaLocation — строка URI, поэтому файл с включаемой схемой может располагаться в любом месте Интернета.
Связь документа XML со своей схемой
Программе-анализатору, проверяющей соответствие документа XML его схеме, надо как-то указать файлы (один или несколько), содержащие схему документа. Это можно сделать разными способами. Во-первых, можно подать необходимые файлы на вход анализатора. Так делает, например, проверяющий анализатор XSV (XML Schema Validator) — ftp://ftp.cogsci.ed.ac.uk/pub/XSV/:
$ xsv ntb.xml ntb1.xsd ntb2.xsd
Во-вторых, можно задать файлы со схемой как свойство анализатора, устанавливаемое методом setProperty(), или значение переменной окружения анализатора. Так делает, например, проверяющий анализатор Xerces.
Эти способы удобны, когда документ в разных случаях нужно связать с различными схемами. Если же схема документа фиксирована, то ее удобнее указать прямо в документе XML. Это делается одним из двух способов.
? Если элементы документа не принадлежат никакому пространству имен и записаны без префикса, то в корневом элементе документа записывается атрибут noNamespaceSchemaLocation, указывающий расположение файла со схемой в фор -ме URI:
<notebook xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="ntb.xsd">
В этом случае в схеме не должно быть целевого пространства имен, т. е. не следует использовать атрибут targetNamespace.
? Если же элементы документа относятся к некоторому пространству имен, то применяется атрибут schemaLocation, в котором через пробел парами перечисляются пространства имен и расположение файла со схемой, описывающей это пространство имен. Продолжая пример предыдущего раздела, можно написать:
<notebook xmlns="http://some.firm.com/2003/ntbNames"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=
"http://some.firm.com/someNames A.xsd http://some.firm.com/anotherNames B.xsd" xmlns:pr1="http://some.firm.com/someNames" xmlns:pr2="http://some.firm.com/anotherNames">
После этого в документе можно использовать имена, определенные в схемах A.xsd и B.xsd, снабжая их префиксами pr1 и pr2 соответственно.
Другие языки описания схем
Даже из приведенного ранее краткого описания языка XSD видно, что он получился весьма сложным и запутанным. Есть уже несколько книг, полностью посвященных этому языку. Их объем ничуть не меньше объема этой книги.
Существуют и другие, более простые языки описания схемы документа XML. Наибольшее распространение получили следующие языки:
? Schematron — http://www.ascc.net/xml/resource/schematron/;
? RELAX NG (Regular Language Description for XML, New Generation), этот язык возник как слияние языков Relax и TREX — http://www.oasis-open.org/committees/ relax-ng/;
? Relax — http://www.xml.gr.jp/relax/;
? TREX (Tree Regular Expressions for XML) — http://www.thaiopensource.com/trex/;
? DDML (Document Definition Markup Language), известный еще как XSchema — http://www.w3.org/TR/NOTE-ddml.
Менее распространены языки DCD (Document Content Description), SOX (One's Schema for Object-Oriented XML), XDR (XML-Data Reduced).
Все перечисленные языки позволяют более или менее полно описывать схему документа. Возможно, они вытеснят язык XSD, возможно, будут существовать совместно.
Инструкции по обработке
Упомянем еще одну конструкцию языка XML — инструкции по обработке (processing instructions). Она позволяет передать анализатору или другой программе-обработчику документа дополнительные сведения для обработки. Инструкция по обработке выглядит так:
<? сведения для анализатора ?>
Первая часть пролога документа XML — первая строка XML-файла — это как раз инструкция по обработке. Она передает анализатору документа версию языка XML и кодировку символов, которыми записан документ.
Первая часть работы закончена. Документы XML и их схемы написаны. Теперь надо подумать о том, каким образом они будут отображаться на экране дисплея, на листе бумаги, на экране сотового телефона, т. е. нужно подумать о визуализации документа XML.
Прежде всего, документ следует разобрать, проанализировать (parse) его структуру.
Анализ документа XML
На первом этапе разбора проводится лексический анализ (lexical parsing) документа XML. Документ разбивается на отдельные неделимые элементы (tokens), которыми являются теги, служебные слова, разделители, текстовые константы. Проводится проверка полученных элементов и их связей между собой. Лексический анализ выполняют специальные программы — сканеры (scanners). Простейшие сканеры — это классы java.util.StringTokenizer и java.io.StreamTokenizer из стандартной поставки Java SE JDK, которые мы рассматривали в предыдущих главах.
Затем осуществляется грамматический анализ (grammar parsing). При этом анализируется логическая структура документа, составляются выражения, выражения объединяются в блоки, блоки — в модули, которыми могут являться абзацы, параграфы, пункты, главы. Грамматический анализ проводят программы-анализаторы, так называемые парсеры (parsers).
Создание сканеров и парсеров — любимое развлечение программистов. За недолгую историю XML написаны десятки, если не сотни XML-парсеров. Многие из них написаны на языке Java. Все парсеры можно разделить на три группы.
В первую группу входят парсеры, проводящие анализ, основываясь на структуре дерева, отражающего вложенность элементов документа (tree-based parsing). Дерево документа строится в оперативной памяти перед просмотром. Такие парсеры проще реализовать, но создание дерева требует большого объема оперативной памяти, ведь размер документов XML не ограничен. Необходимость частого просмотра узлов дерева замедляет работу парсера.
Во вторую группу входят парсеры, проводящие анализ, основываясь на событиях (event-based parsing). Эти парсеры просматривают документ один раз, отмечая события просмотра. Событием считается появление очередного элемента XML: открывающего или закрывающего тега, текста, содержащегося в теле элемента. При возникновении события вызывается соответствующий метод его обработки: startElement(), endElement (), characters () и т. д. Такие парсеры сложнее в реализации, зато они не строят дерево в оперативной памяти и могут анализировать не весь документ, а его отдельные элементы вместе с вложенными в них элементами. Фактическим стандартом здесь стал свободно распространяемый набор классов и интерфейсов SAX (Simple API for XML), созданный Давидом Меггинсоном (David Megginson). Основной сайт данного проекта — http://www.saxproject.org/. Сейчас применяется второе поколение этого набора, называемое SAX2. Набор SAX2 входит во многие парсеры, например Xerces2.
Третью группу образуют потоковые парсеры (stream parsers), которые так же, как и парсеры второй группы, просматривают документ, переходя от элемента к элементу. При каждом переходе парсер предоставляет программе методы getName ( ), getText ( ),
getAttributeName (), getAttributeValue() и т. д., позволяющие обработать текущий элемент.
В стандартную поставку Java и Standard Edition и Enterprise Edition входит набор интерфейсов и классов для создания парсеров и преобразования документов XML, называемый JAXP (Java API for XML Processing). С помощью одной из частей этого набора, называемой DOM API (Document Object Model API), можно создавать парсеры первого типа, формирующие дерево объектов. С помощью второй части набора JAXP, называемой SAX API, можно создавать SAX-парсеры. Третья часть JAXP, предназначенная для создания потоковых парсеров, называется StAX (Streaming API for XML).
Анализ документов XML с помощью SAX2
Интерфейсы и классы SAX2 собраны в пакеты org.xml.sax, org.xml.sax.ext,
org.xml.sax.helpers, javax.xml.parsers. Рассмотрим их подробнее.
Основу SAX2 составляет интерфейс org.xml.sax.ContentHandler, описывающий методы обработки событий: начала документа, появления открывающего тега, появление тела элемента, появление закрывающего тега, окончание документа. При возникновении такого события SAX2 обращается к методу-обработчику события, передавая ему аргументы, содержащие информацию о событии. Дело разработчика — реализовать эти методы, обеспечив правильный анализ документа.
В начале обработки документа вызывается метод
public void startDocument();
В нем можно задать начальные действия по обработке документа.
При появлении символа "<", начинающего открывающий тег, вызывается метод
public void startElement(String uri, String name,
String qname, Attributes attrs);
В метод передаются три имени, два из которых связаны с пространством имен: идентификатор пространства имен uri, локальное имя тега без префикса name и расширенное имя с префиксом qname, а также атрибуты открывающего тега элемента attrs, если они есть. Если пространство имен не определено, то значения первого и второго аргументов равны null. Если нет атрибутов, то передается ссылка на пустой объект attrs.
При появлении символов "</", начинающих закрывающий тег, вызывается метод
public void endElement(String uri, String name, String qname);
При появлении строки символов вызывается метод
public void characters(char[] ch, int start, int length);
В него передается массив символов ch, индекс начала строки символов start в этом массиве и количество символов length.
При появлении в тексте документа инструкции по обработке вызывается метод
public void processingInstruction(String target, String data);
В метод передается имя программы-обработчика target и дополнительные сведения
data.
При появлении пробельных символов, которые должны быть пропущены, вызывается метод
public void ignorableWhitespace(char[] ch, int start, int length);
В него передается массив ch идущих подряд пробельных символов, индекс начала символов в массиве start и количество символов length.
Интерфейс org.xml.sax.ContentHandler реализован классом org.xml.sax.helpers.DefaultHandler. В нем сделана пустая реализация всех методов. Разработчику остается реализовать только те методы, которые ему нужны.
Применим методы SAX2 для обработки нашей адресной книжки. Запись документа на языке XML удобна для выявления структуры документа, но неудобна для работы с документом в объектно-ориентированной среде. Поэтому чаще всего содержимое документа XML представляется в виде одного или нескольких объектов, называемых объектами данных JDO (Java Data Objects). Эта операция называется связыванием данных (data binding) с объектами JDO.
Свяжем содержимое нашей адресной книжки с объектами Java. Для этого сначала опишем классы Java (листинги 28.7 и 28.8), которые представят содержимое адресной книги.
Листинг 28.7. Класс, описывающий адрес
public class Address{
private String street, city, zip, type = "город"; public Address(){}
public String getStreet(){ return street; }
public void setStreet(String street){ this.street = street; }
public String getCity(){ return city; }
public void setCity(String city){ this.city = city; }
public String getZip(){ return zip; }
public void setZip(String zip){ this.zip = zip; }
public String getType(){ return type; }
public void setType(String type){ this.type = type; }
public String toString(){
return "Address: " + street + " " + city + " " + zip;
}
Листинг 28.8. Класс, описывающий запись адресной книжки
public class Person{
private String firstName, secondName, surname, birthday; private Vector<Address> address; private Vector<Integer> workPhone; private Vector<Integer> homePhone;
public Person(){}
public Person(String firstName, String secondName, String surname){ this.firstName = firstName; this.secondName = secondName; this.surname = surname;
}
public String getFirstName(){ return firstName; } public void setFirstName(String firstName){ this.firstName = firstName;
}
public String getSecondName(){ return secondName; } public void setSecondName(String secondName){ this.secondName = secondName;
}
public String getSurname(){ return surname; } public void setSurname(String surname){ this.surname = surname;
}
public String getBirthday(){ return birthday; } public void setBirthday(String birthday){ this.birthday = birthday;
}
public void addAddress(Address addr){
if (address == null) address = new Vector(); address.add(addr);
}
public Vector<Address> getAddress(){ return address; }
public void removeAddress(Address addr){ if (address != null) address.remove(addr);
}
public void addWorkPhone(String phone){
if (workPhone == null) workPhone = new Vector(); workPhone.add(new Integer(phone));
}
public Vector<Integer> getWorkPhone(){ return workPhone; }
public void removeWorkPhone(String phone){
if (workPhone != null) workPhone.remove(new Integer(phone));
}
public void addHomePhone(String phone){
if (homePhone == null) homePhone = new Vector(); homePhone.add(new Integer(phone));
}
public Vector<Integer> getHomePhone(){ return homePhone; }
public void removeHomePhone(String phone){
if (homePhone != null) homePhone.remove(new Integer(phone));
}
public String toString(){
return "Person: " + surname;
}
}
После определения классов Java, в экземпляры которых будет занесено содержимое адресной книжки, напишем программу, читающую адресную книжку и связывающую ее с объектами Java.
В листинге 28.9 приведен пример класса-обработчика NotebookHandler для адресной книжки, описанной в листинге 28.2. Методы класса NotebookHandler анализируют содержимое адресной книжки и помещают его в вектор, составленный из объектов класса Person, описанного в листинге 28.8.
Листинг 28.9. Кпасс-обработник документа XML средствами SAX2
import org.xml.sax.*; import org.xml.sax.helpers.*; import javax.xml.parsers.*; import java.util.*; import java.io.*;
public class NotebookHandler extends DefaultHandler{
static final String JAX P_SCHEMA_LAN GUAGE =
"http://j ava.sun.com/xml/j axp/properties/schemaLanguage";
static final String W3C XML SCHEMA = "http://www.w3.org/2001/XMLSchema";
private Person person; private Address address;
private static Vector<Person> pers = new Vector<>(); boolean inBirthday, inStreet, inCity, inZip, inWorkPhone, inHomePhone;
public void startElement(String uri, String name,
String qname, Attributes attrs)
throws SAXException{ switch (qname){ case "name":
person = new Person(attrs.getValue("first"),
attrs.getValue("second"), attrs.getValue("surname"));
break;
case "birthday":
inBirthday = true; break; case "address":
address = new Address(); break; case "street":
inStreet = true; break; case "city":
inCity = true;
if (attrs != null) address.setType(attrs.getValue("type")); break; case "zip":
inZip = true; break; case "work-phone":
inWorkPhone = true; break; case "home-phone":
inHomePhone = true;
}
public void characters(char[] buf, int offset, int len) throws SAXException{
String s = new String(buf, offset, len);
if (inBirthday){
person.setBirthday(s); inBirthday = false;
}else if (inStreet){
address.setStreet(s); inStreet = false;
}else if (inCity){
address.setCity(s); inCity = false;
}else if (inZip){
address.setZip(s); inZip = false;
}else if (inWorkPhone){ person.addWorkPhone(s); inWorkPhone = false;
}else if (inHomePhone){ person.addHomePhone(s); inHomePhone = false;
}
}
public void endElement(String uri, String name, String qname) throws SAXException{
if (qname.equals("address")){ person.addAddress(address); address = null;
}else if (qname.equals("person")){ pers.add(person); person = null;
}
}
public static void main(String[] args){
if (args.length < 1){
System.err.println("Usage: java NotebookHandler ntb.xml");
System.exit(1);
}
try{
NotebookHandler handler = new NotebookHandler();
SAXParserFactory fact = SAXParserFactory.newInstance();
fact.setNamespaceAware(true); fact.setValidating(true);
SAXParser saxParser = fact.newSAXParser();
saxParser.setProperty(JAXP_SCHEMA_LANGUAGE, W3C_XML_SCHEMA);
File f = new File(args[0]);
saxParser.parse(f, handler);
for (int k = 0; k < pers.size(); k++)
System.out.println((pers.get(k)).getSurname());
}catch(SAXNotRecognizedException x){
System.err.println("HeH3BecTHoe свойство: " +
JAXP_SCHEMA_LANGUAGE) ;
System.exit(1);
}catch(Exception ex){
System.err.println(ex);
}
}
public void warning(SAXParseException ex){ System.err.println("Warning: " + ex); System.err.println("line = " + ex.getLineNumber() +
" col = " + ex.getColumnNumber());
}
public void error(SAXParseException ex){ System.err.println("Error: " + ex);
System.err.println("line " col
+ ex.getLineNumber() +
+ ex.getColumnNumber());
}
public void fatalError(SAXParseException ex){ System.err.println("Fatal error: " + ex); System.err.println("line = " + ex.getLineNumber() +
" col = " + ex.getColumnNumber());
}
}
После того как класс-обработчик написан, проанализировать документ очень легко. Стандартные действия приведены в методе main () программы листинга 28.9.
Поскольку реализация парсера сильно зависит от его программного окружения, SAX-парсер — объект класса SAXParser — создается не конструктором, а фабричным методом newSAXParser().
Объект-фабрика, в свою очередь, формируется методом newinstance (). Далее можно методом
void setFeature(String name, boolean value);
установить свойства парсеров, создаваемых этой фабрикой. Например, после
fact.setFeature("http://xml.org/sax/features/namespace-prefixes", true);
парсеры, создаваемые фабрикой fact, будут учитывать префиксы имен тегов и атрибутов.
Список таких свойств можно посмотреть в документации Java API в описании пакета org.xml.sax или на сайте проекта SAX http://www.saxproject.org/. Следует учитывать, что не все парсеры полностью выполняют эти свойства.
Если к объекту-фабрике применить метод
void setValidating(true);
как это сделано в листинге 28.9, то она будет производить парсеры, проверяющие структуру документа. Если применить метод
void setNamespaceAware(true);
то объект-фабрика будет производить парсеры, учитывающие пространства имен.
После того как объект-парсер создан, остается только применить метод parse (), передав ему имя анализируемого файла и экземпляр класса-обработчика событий.
В классе javax.xml.parsers.SAXParser есть десяток методов parse(). Кроме метода parse (File, DefaultHandler), использованного в листинге 28.9, существуют еще методы, позволяющие извлечь документ из входного потока класса InputStream, объекта класса InputSource, адреса URI или из специально созданного источника класса InputSource.
Методом setProperty() можно задать различные свойства парсера. В листинге 28.9 этот метод использован для того, чтобы парсер проверял правильность документа с помощью схемы XSD. Если парсер выполняет проверки, т. е. применен метод setValidating(true), то имеет смысл сделать развернутые сообщения об ошибках. Это предусмотрено интерфейсом ErrorHandler. Он различает предупреждения, ошибки и фатальные ошибки и описывает три метода, которые автоматически выполняются при появлении ошибки соответствующего вида:
public void warning(SAXParserException ex); public void error(SAXParserException ex); public void fatalError(SAXParserException ex);
Класс DefaultHandler делает пустую реализацию этого интерфейса. При расширении данного класса можно сделать реализацию одного или всех методов интерфейса ErrorHandler. Пример такой реализации приведен в листинге 28.9. Класс SAXParserException хранит номер строки и столбца проверяемого документа, в котором замечена ошибка. Их можно получить методами getLineNumber( ) и getColumnNumber ( ), как сделано в листинге 28.9.
Анализ документов XML с помощью StAX
Интерфейсы и классы StAX собраны в пакеты javax.xml.stream, javax.xml.stream.events, javax.xml. stream.util, но на практике достаточно применения только нескольких интерфейсов и классов.
Основные методы разбора документа описаны в интерфейсе XMLStreamReader. Разбор заключается в том, что парсер просматривает документ, переходя от элемента к элементу и от одной части элемента к другой методом next (). Метод next () возвращает одну из целочисленных констант, описанных в интерфейсе XMLStreamConstants, показывающих тип той части документа, в которой находится парсер: start_document, start_element, END_ELEMENT, CHARACTERS и т. д. В зависимости от этого типа интерфейс XMLStreamReader предоставляет те или иные методы обработки документа. Так, если парсер находится в открывающем теге элемента, start_element, то мы можем получить короткое имя элемента методом getLocalName ( ), число атрибутов методом getAttributeCount(), имя и значение k-го атрибута методами getAttributeName(k) и getAttributeValue(k). Если парсер находится в теле элемента, characters, можно получить содержимое тела методом
getText().
Программа следующего листинга 28.10 выполняет средствами StAX ту же работу, что и программа, записанная в листинге 28.9.
Листинг 28.10. Класс-обработчик документа XML средствами StAX
import javax.xml.stream.*; import java.util.*; import j ava.io.*;
public class NotebookHandlerStAX implements XMLStreamConstants{ private Person person; private Address address;
private static Vector<Person> pers = new Vector<>(); boolean inBirthday, inStreet, inCity, inZip,
inWorkPhone, inHomePhone;
private void processElement(XMLStreamReader element) throws XMLStreamException{ switch (element.getLocalName()){ case "name": person = new Person(element.getAttributeValue(0), element.getAttributeValue(1), element.getAttributeValue(2)); break; case "birthday": inBirthday = true; break; case "address": address = new Address(); break; case "street": inStreet = true; break; case "city": inCity = true; break; case "zip": inZip = true; break; case "work-phone": inWorkPhone = true; break; case "home-phone": inHomePhone = true; break;
}
}
private void processText(String text){ if (inBirthday){
person.setBirthday(text); inBirthday = false;
}else if (inStreet){
address.setStreet(text) ; inStreet = false;
}else if (inCity) {
address.setCity(text); inCity = false;
}else if (inZip){
address.setZip(text); inZip = false;
}else if (inWorkPhone){ person.addWorkPhone(text); inWorkPhone = false;
}else if (inHomePhone){ person.addHomePhone(text); inHomePhone = false;
}
}
private void finishElement(String name){ switch (name){
case "address": person.addAddre s s(addre ss);
address = null; break; case "person": pers.add(person); person = null; break;
}
}
public static void main(String[] args){ if (args.length < 1){
System.err.println("Usage: java NotebookHandlerStAX ntb.xml");
System.exit(1);
}
NotebookHandlerStAX handler = new NotebookHandlerStAX(); try{
FileInputStream inStream = new FileInputStream(args[0]);
XMLStreamReader xmlReader =
XMLInputFactory.newInstance(). createXMLStreamReader(inStream) ; int event;
while (xmlReader.hasNext()) { event = xmlReader.next(); switch (event){
case START_ELEMENT: handler.processElement(xmlReader); break; case CHARACTERS: handler.processText(xmlReader.getText()); break; case END_ELEMENT: handler.finishElement(xmlReader.getLocalName());
}
}
xmlReader.close() ;
}catch(Exception ex){ ex.printStackTrace() ;
}
}
}
Связывание данных XML с объектами Java
В приведенном примере мы сами создали классы Address и Person, представляющие документ XML. Поскольку структура документа XML четко определена, можно разработать стандартные правила связывания данных XML с объектами Java и создать программные средства для их реализации.
Корпорация Sun Microsystems разработала пакет интерфейсов и классов JAXB (Java Architecture for XML Binding), облегчающих связывание данных. Он входит в стандартную поставку Java SE, а также может быть скопирован с сайта http:// jaxb.dev.java.net/. Для работы с пакетом JAXB анализируемый документ XML обязательно должен быть снабжен описанием на языке XSD.
В состав пакета JAXB входит компилятор xj c (XML-Java Compiler). Он просматривает схему XSD и строит по нему объекты Java в оперативной памяти, а также создает исходные файлы объектов Java. Например, после выполнения команды
$ xjc -roots notebook ntb.xsd -d sources
в которой ntb.xsd — файл листинга 28.4 — в каталоге sources (по умолчанию в текущем каталоге) будут созданы файлы Addressjava, Namejava, Notebookjava, Personjava, PhoneListjava с описаниями объектов Java.
Флаг -roots показывает один или несколько корневых элементов, разделенных запятыми.
Созданные компилятором xjc исходные файлы обычным образом, с помощью компилятора j avac, компилируются в классы Java.
Получив объекты данных, можно перенести в них содержимое документа XML методом unmarshal (), который создает дерево объектов, или, наоборот, записать объекты Java в документы XML методом marshal (). Эти методы уже записаны в созданный компилятором xj c класс корневого элемента, в примере это класс Notebook.
Объекты данных JDO
Задачу связывания данных естественно обобщить — связывать объекты Java не только с документами XML, но и с текстовыми файлами, реляционными или объектными базами данных, другими хранилищами данных.
Корпорация Sun Microsystems опубликовала спецификацию JDO, сейчас уже версии 3.0, и разработала интерфейсы для работы с JDO. Спецификация JDO рассматривает более широкую задачу связывания данных, полученных не только из документа XML, но и из любого источника данных, называемого информационной системой предприятия (Enterprise Information System, EIS). Спецификация описывает два набора классов и интерфейсов:
? JDO SPI (JDO Service Provider Interface) — вспомогательные классы и интерфейсы, которые следует реализовать в сервере приложений для обращения к источнику данных, создания объектов, обеспечения их сохранности, выполнения транзакций, проверки прав доступа к объектам; эти классы и интерфейсы составляют пакет
javax.jdo.spi;
? JDO API (JDO Application Programming Interface) — интерфейсы, предоставляемые пользователю для доступа к объектам, управления транзакциями, создания и удаления объектов; эти интерфейсы собраны в пакет javax.jdo.
Есть много коммерческих и свободно распространяемых реализаций интерфейсов JDO.
Сообщество Apache Software Foundition назвало свою реализацию Apache JDO. Эту разработку можно посмотреть по адресу http://db.apache.org/jdo/index.html.
Фирма DataNucleus, http://www.datanucleus.org/, выпускает продукт Access Platform, бывший JPOX.
Компания SolarMetric, http://www.solarmetric.com/, выпускает свою реализацию спецификации JDO под названием Kodo JDO. Ее можно встроить в серверы приложений WebLogic, WebSphere, JBoss.
Некоторые фирмы разработали свои варианты JDO, более или менее соответствующие спецификации. Наиболее известна свободно распространяемая разработка, названная Castor. Ее можно посмотреть по адресу http://www.castor.org/.
С помощью Castor можно предельно упростить связывание данных. Например, создание объекта Java из простого документа XML, если отвлечься от проверок и обработки исключительных ситуаций, выполняется одним действием:
Person person = (Person)Unmarshaller.unmarshal(
Person.class, new FileReader("person.xml"));
Обратно, сохранение объекта Java в виде документа XML в самом простом случае выглядит так:
Marshaller.marshall(person, new FileWriter("person.xml"));
В более сложных случаях надо написать файл XML, аналогичный схеме XSD, с указаниями по связыванию данных (mapping file).
Анализ документов XML с помощью DOM API
Как видно из предыдущих разделов, SAX-парсер читает документ только один раз, отмечая появляющиеся по ходу чтения открывающие теги, содержимое элементов и закрывающие теги. Этого достаточно для связывания данных, но неудобно для редактирования документа.
Консорциум W3C разработал спецификации и набор интерфейсов DOM (Document Object Model), которые можно посмотреть на сайте этого проекта http://www.w3.org/ DOM/. Методами этих интерфейсов документ XML можно загрузить в оперативную память в виде дерева объектов. Это позволяет не только анализировать документ анализаторами, основанными на структуре дерева, но и менять дерево, добавляя или удаляя объекты из дерева. Кроме того, можно обращаться непосредственно к каждому объекту в дереве и не только читать, но и изменять информацию, хранящуюся в нем. Но все это требует большого объема оперативной памяти для загрузки большого дерева.
Корпорация Sun Microsystems реализовала интерфейсы DOM в пакетах javax.xml. parsers и org.w3c.dom, входящих в состав пакета JAXP. Воспользоваться этой реализацией очень легко:
DocumentBuilderFactory fact =
DocumentBuilderFactory.newInstance();
DocumentBuilder builder = fact.newDocumentBuilder();
Document doc = builder.parse("ntb.xml");
Метод parse () строит дерево объектов и возвращает ссылку на него в виде объекта типа Document. В классе DocumentBuilder есть несколько методов parse ( ), позволяющих загрузить файл с адреса URL, из входного потока, как объект класса File или из источника класса InputSource.
Интерфейс Document, расширяющий интерфейс Node, описывает дерево объектов документа в целом. Интерфейс Node — основной интерфейс в описании структуры дерева — описывает узел дерева. У него есть еще один наследник — интерфейс Element, описывающий лист дерева, соответствующий элементу документа XML. Как видно из структуры наследования этих интерфейсов, и само дерево, и его лист считаются узлами дерева. Каждый атрибут элемента дерева описывается интерфейсом Attr. Еще несколько интерфейсов — CDATASection, Comment, Text, Entity, EntityReference, ProcessingInstruction, Notation — описывают разные типы элементов XML.
На рис. 28.2 показано начало дерева объектов, построенного по документу, приведенному в листинге 28.2. Обратите внимание на то, что текст, находящийся в теле элемента, хранится в отдельном узле дерева — потомке узла элемента. Для каждого атрибута открывающего тега тоже создается отдельный узел.
 Рис. 28.2. Дерево объектов документа XML
Рис. 28.2. Дерево объектов документа XML
Интерфейс Node
Интерфейс Node описывает тип узла одной из следующих констант:
? attribute_node — узел типа Attr, содержит атрибут элемента;
? CDATA_SECTION_NODE узел типа CDADASection, содержит данные типа CDATA;
? comment_node — узел типа Comment, содержит комментарий;
? DOCUMENT_FRAGMENT_NODE в узле типа DocumentFragment находится фрагмент документа;
? DOCUMENT_NODE корневой узел типа Document;
? DOCUMENT_TYPE_NODE узел типа Document;
? ELEMENT_NODE узел является листом дерева типа Element;
? entity_node — в узле типа Entity хранится сущность entity;
? ENTITY_REFERENCE_NODE в узле типа EntityReference хранится ссылка на сущность;
? NOTATION_NODE-в узле хранится нотация типа Notation;
? PROCESSING_INSTRUCTION_NODE- узел типа ProcessingInstruction, содержит инструкцию
по обработке;
? TEXT_NODE в узле типа Text хранится текст.
Методы интерфейса Node описывают действия с узлом дерева:
? public short getNodeType ( ) — возвращает тип узла;
? public String getNodeName() — возвращает имя узла;
? public string getNodeValue() — возвращает значение, хранящееся в узле;
? public boolean hasAttributes ( ) - выполняет проверку существования атрибутов у
элемента XML, хранящегося в узле в виде объекта типа NamedNodeMap, если это узел типа Element;
? public NamedNodeMap getAttributes() — возвращает атрибуты; метод возвращает null, если у элемента нет атрибутов;
? public boolean hasChildNodes ( ) -проверяет, есть ли у данного узла узлы-потомки;
? public NodeList getChildNodes() - возвращает список узлов-потомков в виде объекта
типа NodeList;
? public Node getFirstchild() — возвращает первый узел в списке узлов-потомков;
? public Node getLastchild() — возвращает последний узел в списке узлов-потомков;
? public Node getParentNode() — возвращает родительский узел;
? public Node getPreviousSibling( ) - возвращает предыдущий узел, имеющий того же
предка, что и данный узел;
? public Node getNextsibling() — возвращает следующий узел, имеющий того же предка, что и данный узел;
? public Document getOwnerDocument() — возвращает ссылку на весь документ. Следующие методы позволяют изменить дерево объектов:
? public Node appendChild(Node newChild) — добавляет новый узел-потомок newChild;
? public Node insertBefore(Node newChild, Node refChild) — вставляет новый узел-потомок newChild перед существующим потомком refChild;
? public Node replaceChild(Node newChild, Node oldChild) — заменяет один узел-потомок oldChild новым узлом newChild;
? public Node removeChild(Node child) — удаляет узел-потомок.
Интерфейс Document
Интерфейс Document добавляет к методам своего предка Node методы работы с документом в целом:
? public DocumentType getDocType() — возвращает общие сведения о документе в виде объекта типа DocumentType;
? getName(), getEntitied(), getNotations() и другие методы интерфейса DocumentType возвращают конкретные сведения о документе;
? public Element getDocumentElement() — возвращает корневой элемент дерева объектов;
? public NodeList getElementsByTagName(String name);
public NodeList getElementsByTagNameNS(String uri, String qname); public Element getElementById(String id)
возвращают все элементы с указанным именем tag без префикса или с префиксом, а также элемент, определяемый значением атрибута с именем ID.
Несколько методов позволяют изменить структуру и содержимое дерева объектов:
? public Element createElement(String name) — создает новый пустой элемент по его имени;
? public Element createElementNS(String uri, String name) — создает новый пустой элемент по имени с префиксом;
? public CDATASection createCDATASection(String name) — создает узел типа CDATA SECTION
node;
? public EntityReference createEntityReference(String name) — создает узел типа ENTITY
reference_node;
? public ProcessingInstruction createProcessingInstruction(String name) — создает узел
типа processing_instruction_node;
? public TextNode createTextNode(String name) — создает узел типа TEXT_NODE;
? public Attr createAttribute (String name) — создает узел-атрибут с именем name;
? public Attr createAttributeNS(String uri, String name) — аналогично;
? public Comment createComment(String comment) — создает узел-комментарий;
? public DocumentFragment createDocumentFragment() — создает пустой документ — фрагмент данного документа с целью его дальнейшего заполнения;
? public Node importNode(Node importedNode, boolean deep) — вставляет созданный узел, а значит, и все его поддерево, в дерево документа. Этим методом можно соединить два дерева объектов. Если второй аргумент равен true, то рекурсивно вставляется все поддерево.
Интерфейс Element
Интерфейс Element добавляет к методам своего предка Node методы работы с атрибутами открывающего тега элемента XML и методы, позволяющие обратиться к вложенным элементам. Только один метод
public String getTagName();
дает сведения о самом элементе, а именно имя элемента.
Прежде чем получить значение атрибута с именем name, надо проверить его наличие методами
public boolean hasAttribute(String name);
public boolean hasAttributeNS(String uri, String name);
Второй из этих методов учитывает пространство имен с именем uri, записанным в виде строки URI; имя name должно быть полным, с префиксом.
Получить атрибут в виде объекта типа Attr или его значение в виде строки по имени name с учетом префикса или без него можно методами
public Attr getAttributeNode(String name);
public Attr getAttributeNodeNS(String uri, String name);
public String getAttribute(String name);
public String getAttributeNS(String uri, String name);
Удалить атрибут можно методами
public Attr removeAttributeNode(Attr name);
public void removeAttribute(String name);
public void removeAttributeNS(String uri, String name);
Установить значение атрибута можно методами
public void setAttribute(String name, String value);
public void setAttributeNS(String uri, String name, String value);
Добавить атрибут в качестве потомка можно методами
public Attr setAttributeNode(String name);
public Attr setAttributeNodeNS(Attr name);
Два метода позволяют получить список узлов-потомков:
public NodeList getElrmentsByTagName(String name);
public NodeList getElrmentsByTagNameNS(String uri, String name);
Итак, методы перечисленных интерфейсов позволяют перемещаться по дереву, менять структуру дерева, просматривать информацию, хранящуюся в узлах и листьях дерева, и изменять ее.
Приведем пример работы с деревом объектов, построенным по документу XML. Добавим в адресную книжку листинга 28.2 новый рабочий или домашний телефон Сидоровой. Это действие записано в листинге 28.11.
Листинг 28.11. Анализ адресной книжки с помощью DOM API
import org.w3c.dom.*; import javax.xml.parsers.*; import org.xml.sax.*;
class ErrHand implements ErrorHandler{
public void warning(SAXParseException ex){ System.err.println("Warning: " + ex); System.err.println("line = " + ex.getLineNumber() +
" col = " + ex.getColumnNumber());
}
public void error(SAXParseException ex){ System.err.println("Error: " + ex); System.err.println("line = " + ex.getLineNumber() +
" col = " + ex.getColumnNumber());
}
public void fatalError(SAXParseException ex){ System.err.println("Fatal error: " + ex); System.err.println("line = " + ex.getLineNumber() +
" col = " + ex.getColumnNumber());
}
public class TreeProcessDOM{
static final String JAXP_SCHEMA_MNGUAGE =
"http://j ava.sun.com/xml/j axp/properties/schemaLanguage";
static final String W3C XML SCHEMA =
"http://www.w3.org/2001/XMLSchema";
public static void main(String[] args) throws Exception{ if (args.length != 3){
System.err.println("Usage: java TreeProcessDOM " + "<file-name>.xml {workjhome} <phone>");
System.exit(-1);
}
DocumentBuilderFactory fact = DocumentBuilderFactory.newInstance(); fact.setNamespaceAware(true); fact.setValidating(true) ;
try{
fact. setAttribute ( JAXP_SCHEMA_LANGUAGE, W3C_XML_SCHEMA) ; }catch(IllegalArgumentException x){
System.err.println("HeH3BecTHoe свойство: " +
JAXP_SCHEMA_LANGUAGE) ;
System.exit(-1);
}
DocumentBuilder builder = fact.newDocumentBuilder(); builder.setErrorHandler(new ErrHand());
Document doc = builder.parse(args[0]);
NodeList list = doc.getElementsByTagName("notebook"); int n = list.getLength(); if (n == 0){
System.err.println("Документ пуст.");
System.exit(-1);
}
Node thisNode = null;
for (int k = 0; k < n; k++){ thisNode = list.item(k);
String elemName = null;
if (thisNode.getFirstChild() instanceof Element){
elemName = (thisNode.getFirstChild()).getNodeName(); if (elemName.equals("name")){
if (!thisNode.hasAttributes()){
System.err.println("ATpH5yTbi отсутствуют " + elemName);
System.exit(1);
}
NamedNodeMap attrs = thisNode.getAttributes();
Node attr = attrs.getNamedItem("surname"); if (attr instanceof Attr)
if (((Attr)attr).getValue().equals("Сидорова")) break;
}
}
}
NodeList topics = ((Element)thisNode)
.getElementsByTagName("phone-list");
Node newNode;
if (args[1].equals("work"))
newNode = doc.createElement("work-phone"); else newNode = doc.createElement("home-phone");
Text textNode = doc.createTextNode(args[2]);
newNode.appendChild(textNode);
thisNode.appendChild(newNode);
}
}
Дерево объектов можно вывести на экран дисплея, например, как объект класса JTree — одного из компонентов графической библиотеки Swing. Именно так сделано на рис. 28.2. Для вывода применена программа DomEcho из электронного учебника "Web Services Tutorial". Исходный текст программы слишком велик, чтобы приводить его здесь, но его можно посмотреть по адресу http://java.sun.com/webservices/ tutorial.html. В состав парсера Xerces в качестве примера анализа документа в раздел samples/ui/ входит программа TreeView, которая тоже показывает дерево объектов в виде дерева JTree библиотеки Swing.
Другие DOM-парсеры
Модель дерева объектов DOM была первоначально разработана группой OMG (Object Management Group) в рамках языка IDL (Interface Definition Language) без учета особенностей Java. Только потом она была переведена на Java консорциумом W3C в виде интерфейсов и классов, составивших пакет org.w3c.dom. Этим объясняется, в частности, широкое применение в DOM API интерфейсов и фабричных методов вместо классов и конструкторов.
Данное неудобство привело к появлению других разработок.
Участники общественного проекта JDOM не стали реализовать модель DOM, а разработали свою модель дерева объектов, получившую название JDOM. Они выпускают одноименный свободно распространяемый программный продукт, с которым можно ознакомиться на сайте проекта http://www.jdom.org/. Этот продукт широко используется для обработки документов XML средствами Java.
Участники другого общественного проекта — dom4j — приняли модель W3C DOM, но упростили и упорядочили DOM API. С их одноименным продуктом dom4j можно ознакомиться на сайте http://www.dom4j.org/.
Преобразование дерева объектов в XML
Итак, дерево объектов DOM построено надлежащим образом. Теперь надо его преобразовать в документ XML, страничку HTML, документ PDF или объект другого типа. Средства для выполнения такого преобразования составляют третью часть набора JAXP — пакеты javax.xml.transform, javax.xml.transform.dom, javax.xml.transform.sax, javax.xml. transform. stream, которые представляют собой реализацию языка описания таблиц стилей для преобразований XSLT (XML Stylesheet Language for Transformations) средствами Java.
Язык XSLT разработан консорциумом W3 как одна из трех частей, составляющих язык записи таблиц стилей XSL (XML Stylesheet Language). Все материалы по XSL можно посмотреть на сайте проекта по адресу http://www.w3.org/Style/XSL/.
Интерфейсы и классы, входящие в пакеты javax.xml.transform.*, управляют процессором XSLT, в качестве которого выбран процессор Xalan, разработанный в рамках проекта Apache Software Foundation, http://xml.apache.org/xalan-j/.
Исходный объект преобразования должен иметь тип Source. Интерфейс Source определяет всего два метода доступа к идентификатору объекта:
public String getSystemId(); public void setSystemId(String id);
У интерфейса Source есть три реализации. Класс DOMSource подготавливает к преобразованию дерево объектов DOM, класс SAXSource подготавливает SAX-объект, а класс StreamSource — простой поток данных. В конструкторы этих классов заносится ссылка на исходный объект — для конструктора класса DOMSource это узел дерева, для конструктора класса SAXSource-имя файла, для конструктора класса StreamSource — входной
поток. Методы перечисленных классов позволяют задать дополнительные свойства исходных объектов преобразования.
Результат преобразования описывается интерфейсом Result. Он тоже определяет точно такие же методы доступа к идентификатору объекта-результата, как и интерфейс Source. У него тоже есть три реализации- классы DOMResult, SAXResult и StreamResult. В конст
рукторы этих классов заносится ссылка на выходной объект. В первом случае это узел дерева, во втором — объект типа ContentHandler, в третьем — файл, в который будет занесен результат преобразования, или выходной поток.
Само преобразование выполняется объектом класса Transformer. Вот стандартная схема преобразования дерева объектов DOM в документ XML, записываемый в файл.
TransformerFactory transFactory = TransformerFactory.newInstance();
Transformer transformer = transFactory.newTransformer();
DOMSource source = new DOMSource(document);
File newXMLFile = new File("ntb1.xml");
FileOutputStream fos = new FileOutputStream(newXMLFile);
StreamResult result = new StreamResult(fos); transformer.transform(source, result);
Вначале методом newInstance() создается экземпляр transFactory фабрики объектов-преобразователей. Методом
public void setAttrbute(String name, String value);
класса TransformerFactory можно установить некоторые атрибуты этого экземпляра. Имена и значения атрибутов зависят от реализации фабрики.
С помощью фабрики преобразователей создается объект-преобразователь класса Transformer. При формировании этого объекта в него можно занести объект, содержащий правила преобразования, например таблицу стилей XSL.
В созданный объект класса Transformer методом
public void setParameter(String name, String value);
можно занести параметры преобразования, а методами
public void setOutputProperties(Properties out); public void setOutputProperty(String name, String value);
легко определить свойства преобразованного объекта. Имена свойств name задаются константами, которые собраны в специально определенный класс OutputKeys, содержащий только эти константы. Вот их список:
? cdata_sect I on_e lements — список имен секций cdata через пробел;
? doctype_public — открытый идентификатор public преобразованного документа;
? doctype_system — системный идентификатор system преобразованного документа;
? encoding — кодировка символов преобразованного документа, значение атрибута encoding объявления XML;
? indent — делать ли отступы в тексте преобразованного документа. Значения этого свойства "yes" или "no";
? media_type — MIME-тип содержимого преобразованного документа;
? METHOD — метод вывода, одно из значений: "xml", "html" или "text";
? omit_xml_declaration — не включать объявление XML. Значения "yes" или "no";
? STANDALONE- отдельный или вложенный документ, значение атрибута standalone
объявления XML. Значения "yes" или "no";
? version — номер версии XML для атрибута version объявления XML.
Например, можно задать кодировку символов преобразованного документа следующим методом:
transformer.setOutputProperty(OutputKeys.ENCODING, "Windows-1251");
Затем в приведенном примере по дереву объектов document типа Node создается объект класса DOMSource — упаковка дерева объектов для последующего преобразования. Тип аргумента конструктора этого класса — Node, откуда видно, что можно преобразовать не все дерево, а какое-либо его поддерево, записав в конструкторе класса DOMSource корневой узел поддерева.
Наконец, определяется результирующий объект result, связанный с файлом newCourses.xml, и осуществляется преобразование методом transform().
Более сложные преобразования выполняются с помощью таблицы стилей XSL.
Таблицы стилей XSL
В документах HTML часто применяются таблицы стилей CSS (Cascading Style Sheet), задающие общие правила оформления документов HTML: цвет, шрифт, заголовки. Выполнение этих правил придает документам единый стиль оформления.
Для документов XML, в которых вообще не определяются правила визуализации, идея применить таблицы стилей оказалась весьма плодотворной. Таблицы стилей для документов XML записываются на специально сделанной реализации языка XML, названной XSL (XML Stylesheet Language). Все теги документов XSL относятся к пространству имен с идентификатором http://www.w3.org/1999/XSL/Transfonm. Обычно они записываются с префиксом xsl. Если принят этот префикс, то корневой элемент таблицы стилей XSL будет называться <xsl: stylesheet>.
Простейшая таблица стилей выглядит так, как записано в листинге 28.12.
Листинг 28.12. Простейшая таблица стилей XSL
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="text" encoding="CP866"/>
</xsl:stylesheet>
Здесь только определяется префикс пространства имен xsl и правила вывода, а именно выводится "плоский" текст, на что показывает значение text (другие значения — html и xml), в кодировке CP866. Такая кодировка выбрана для вывода кириллицы на консоль MS Windows. Объект класса Transformer, руководствуясь таблицей стилей листинга 28.12, просто выводит тела элементов так, как они записаны в документе XML, т. е. просто удаляет теги вместе с атрибутами, оставляя их содержимое.
Эту таблицу стилей записываем в файл, например, simple.xsl. Ссылку на таблицу стилей можно поместить в документ XML как одну из инструкций по обработке:
<?xml version="1.0" encoding="Windows-1251"?>
<?xml-stylesheet type="text/xsl" href="simple.xsl"?>
<notebook>
<!— Продолжение адресной книжки —>
После этого XML-парсер, если он, кроме того, является XSLT -процессором, выполнит преобразование, заданное в файле simple.xsl.
Другой путь — использовать таблицу стилей при создании объекта-преобразователя, например, так, как записано в листинге 28.13.
Листинг 28.13. Консольная программа преобразования документа XML
import java.io.*;
import javax.xml.transform.*;
import j avax.xml.transform.stream.*;
public class SimpleTransform{
public static void main(String[] args) throws TransformerException{ if (args.length != 2){
System.out.println("Usage: " +
"java SimpleTransform xmlFileName xsltFileName"); System.exit(1);
}
File xmlFile = new File(args[0]);
File xsltFile = new File(args[1]);
Source xmlSource = new StreamSource(xmlFile);
Source xsltSource = new StreamSource(xsltFile);
Result result = new StreamResult(System.out);
TransformerFactory transFact = TransformerFactory.newInstance();
Transformer trans = transFact.newTransformer(xsltSource); trans.transform(xmlSource, result);
}
}
После компиляции набираем в командной строке
java SimpleTransform ntb.xml simple.xsl
и получаем на экране дисплея содержимое тегов документа ntb.xml.
В более сложных случаях просто изменяем таблицу стилей. Например, если мы хотим получить содержимое документа на консоли, то таблицу стилей для объекта-преобразователя класса Transformer надо записать так, как показано в листинге 28.14.
Листинг 28.14. Таблица стилей для показа адресной книжки
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" encoding="CP866" />
<xsl:template match="person">
<xsl:apply-templates />
</xsl:template>
<xsl:template match="name">
<xsl:value-of select="@first" /> <xsl:text> </xsl:text> <xsl:value-of select="@second" /> <xsl:text> </xsl:text>
<xsl:value-of select="@surname" />
</xsl:template>
<xsl:template match="address">
<xsl:value-of select="street" /> <xsl:text> </xsl:text> <xsl:value-of select="city" /> <xsl:text> </xsl:text> <xsl:value-of select="zip" />
</xsl:template>
<xsl:template match="phone-list">
<xsl:value-of select="work-phone" /> <xsl:text>
</xsl:text> <xsl:value-of select="home-phone" /> <xsl:text>
</xsl:text> </xsl:template>
</xsl:stylesheet>
Мы не будем в данной книге заниматься языком XSL — одно его описание будет толще всей этой книги. На русский язык переведена "библия" XSLT [20]. Ее автор Майкл Кэй (Michael H. Kay) создал и свободно распространяет популярный XSLT -процессор Saxon, http://saxon.sourceforge.net/.
Преобразование документа XML в HTML
С помощью языка XSL и методов класса Transformer можно легко преобразовать документ XML в документ HTML. Достаточно написать соответствующую таблицу стилей. В листинге 28.15 показано, как это можно сделать для адресной книжки листинга 28.2.
Листинг 28.15. Таблица стилей для преобразования XML в HTML
<?xml version="1.0" encoding="Windows-1251"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" encoding="Windows-1251"/>
<xsl:template match="/">
<html><head><title>ADpecHaH книжка</title></head> <body><h2>Фамилии, адреса и телефоны</!а2>
<xsl:apply-templates />
</body></html>
</xsl:template>
<xsl:template match="name">
<p />
<xsl:value-of select="@first" /> <xsl:text> </xsl:text> <xsl:value-of select="@second" /> <xsl:text> </xsl:text> <xsl:value-of select="@surname" /> <br />
</xsl:template>
<xsl:template match="address">
<br />
<xsl:value-of select="street" /> <xsl:text> </xsl:text>
<xsl:value-of select="city" /> <xsl:text> </xsl:text>
<xsl:value-of select="zip" /> <br />
</xsl:template>
<xsl:template match="phone-list">
Рабочий: <xsl:value-of select="work-phone" /> <br />
Домашний: <xsl:value-of select="home-phone" /> <br />
</xsl:template>
</xsl:stylesheet>
Эту таблицу стилей можно записать в файл, например, ntb.xsl, и сослаться на него в документе XML, описывающем адресную книжку:
<?xml version="1.0" encoding="Windows-1251"?>
<?xml-stylesheet type="text/xsl" href="ntb.xsl"?>
<notebook>
<!— Содержание адресной книжки —>
После этого любой браузер, "понимающий" XML и XSLT, например Mozilla Firefox или Internet Explorer, покажет содержимое адресной книжки, как предписано листингом 28.15.
Если набрать в командной строке
$ java SimpleTransform ntb.xml ntb.xsl > ntb.html
то в текущем каталоге будет записан преобразованный HTML-файл с именем ntb.html.
Вопросы для самопроверки
1. Зачем понадобился новый язык разметки XML?
2. Какой основной цели служат элементы XML?
3. Каким образом выявляется смысл элементов XML?
4. Обязателен ли корневой элемент в документе XML?
5. Почему документ XML должен быть снабжен описанием DTD, схемой XSD или описанием на каком-то другом языке?
6. Как выполняется синтаксический анализ документа XML?
7. В каких случаях удобнее проводить синтаксический анализ документа XML, основываясь на событиях, а в каких — построением дерева?
8. Каким образом можно преобразовать один документ XML в другой документ?
9. Почему в технологии XML предпочитают использовать таблицы стилей XSL, а не CSS?
10. Какими способами можно перебрать только узлы-элементы?
11. Преобразуются ли узлы, для которых не написаны правила преобразования?
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК