Глава 6 Программные архитектуры корпоративных систем
Ранее были рассмотрены основные понятия корпорации и корпоративной системы, затем – основные подходы к разработке этих систем с точки зрения их жизненного цикла на уровне моделей (более формальный, общий подход), после этого – основные методологии проектирования. Напомним, это тоже не вполне строгий подход с математической точки зрения, по сути, это набор правил хорошего тона, полезных советов, рекомендаций для реализации и сопровождения информационных систем. Поэтому имеет смысл ограничиться констатацией тех подходов, которые приемлемы для корпоративных приложений. Это MSF, RUP и те, которые приемлемы лишь отчасти, – Scrum, Agile. Знать ЖЦ нужно, чтобы иметь представление о создании и функционировании систем. Направление методологий и моделей жизненного цикла – это во многом ортогональные направления. Например, в RUP можно использовать спиральную или каскадную модель, а в MSF – эволюционные или инкрементальные подходы.
Ранее мы рассматривали разработку КИС с концептуальной точки зрения, теперь начнем более предметный разговор и спустимся на технологический уровень.
Первое, с чего следует начать описание, – это программная архитектура. Во время эскизного или архитектурного проектирования вместе с базовыми функциональными требованиями разрабатывается общая архитектура системы: количество компонентов и их взаимодействие. На этом этапе стоит определиться с технологией – будет ли приложение файл-серверным, клиент-серверным, двух– или трехзвенным и каким образом будут эти звенья взаимодействовать, будет ли оно иметь на нижнем уровне БД и насколько сложными будут структуры данных (рис. 6.1).
Следующее, о чем следует рассказать перед технологическими средствами и приемами, которые используются в Microsoft и его инструментальных средствах проектирования, – это CASE-средства, которые поддерживают все этапы разработки КИС. Это тяжелые и дорогие инструменты, поэтому стоит говорить об их масштабном применении, прежде всего в КИС.
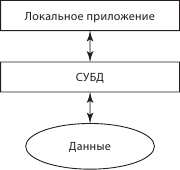
Рис. 6.1. Обработка данных СуБД: локальный компьютер
Перейдем к рассмотрению классификации программных архитектур.
Прежде всего речь пойдет о сетевых архитектурах, так как корпорация – распределенная структура. Будут рассмотрены устройство сетевых архитектур и принципы их функционирования. Второе ограничение – архитектуры, основанные на БД. В определении программной инженерии по Липаеву было сказано, что в КИС, как правило, используются БД. Корпоративные БД – это отдельная большая тема.
Корпоративные информационные системы можно назвать открытыми лишь в определенном смысле этого слова. Корпорации не хотят открывать свои конфиденциальные данные внешним заказчикам. Корпорация не может доверить оценку рисков внешнему разработчику, и разработчик, и заказчик должны быть внутри системы. Но принципы объединения ИС должны базироваться на открытых стандартах. Далее речь пойдет о них.
БД в корпорациях содержат тера– или даже петабайты данных. Уже в 2005–2006 гг. объемы данных в корпорации Intel превысили 3 петабайта. Объемы данных растут экспоненциально, приблизительно в 2 раза за пять лет. Таким образом, к настоящему времени этот показатель удвоился. Управление такими БД – масштабная проблема, но останавливаться на ней мы сейчас не будем.
Говоря о корпоративных системах, их стоит разделять на две части – клиентскую и серверную. Клиент запрашивает информацию, сервер ее обрабатывает и предоставляет. Другое дело, как именно они взаимодействуют. Простой случай – файл – сервер. Более сложный подход – клиент-серверная архитектура. Отдельно выделяется сервер БД – в ряде случаев это оправданно, причем серверы нас интересуют с логической, а не аппаратной стороны.
Как происходит разделение функций между клиентом и сервером? Здесь, как в любой сложной промышленной системе, речь идет о специализации и кооперировании. Мы выделяем функциональные роли все более и более тонкие, точные. Детализируя понятие «сервер», сначала происходит классификация клиент и сервер. Далее происходит уточнение: есть серверы баз данных, серверы шифрования, телекоммуникационные серверы. На этой основе происходит классификация системных архитектур.
Существуют разные организации клиент-серверного взаимодействия. Далее подробно будет рассмотрено, как осуществляется обработка информации в БД, какой существует CASE-инструментарий для работы с БД, что такое реинжиниринг БД и SQL-запросы. Потом будут описаны более сложные структуры на основе клиент-серверного подхода.
Рассмотрим двух– и трехуровневый клиент-сервер, где сервер приложений явно выделяется как отдельный операционный слой. Чем большая производительность необходима, тем большая нужна специализация. По сути, речь идет о программном обеспечении. То, как операционный слой распределяется по аппаратному обеспечению, зависит от топологии сети, от задач, администраторов БД и сетевых администраторов корпорации, здесь возможен достаточно широкий спектр решений. Далее будет рассмотрено, какие расширения серверной части программной реализации имеются в современных сетевых архитектурах, какие существуют распределенные БД различных уровней.
Под корпорацией в широком смысле мы понимаем не только производственную, но и разветвленную структуру, например госструктуру, которая также решает какие-то общие задачи. Можно говорить о федеративных БД, о БД масштаба государства, об интегрированных БД, которые объединяют различные системы и подходы к организации данных.
Еще один интересный пример крупномасштабных систем – это GRID-системы. Он не очень часто используется в корпорациях. Это системы, в которых взаимодействуют большое количество необязательно мощных компьютеров, но обеспечивается масштабирование и в короткие сроки обрабатываются терабайты данных.
Важно отменить значимость клиент-серверной архитектуры. Она обеспечивает достаточно простой и довольно дешевый коллективный доступ к данным в сетевых средах, не обязательна локальная вычислительная сеть.
Появлению семейств клиент-серверной архитектуры мы обязаны последовательной реализации концепции открытых систем. На основе открытых стандартных протоколов взаимодействия можно, как на заводе, собирать комплексные системы высокой сложности, причем дешево осуществлять сборку этих систем, даже если компоненты реализуются в разных странах. Один из подходов к такому проектированию – это компонентный подход, который реализован Microsoft. Сборка осуществляется из компонентов с открытым интерфейсом. Подобный подход предлагает Sun в Enterprise JavaBeans.
Корпорация – организация с большим количеством информационных систем, возможно относящихся к разным поколениям, например, во многих банках работают мейнфреймы и существует множество систем, написанных на языке Cobol. Идея открытых систем в том, чтобы объединить информационные системы. Телекоммуникационные системы существовали и ранее, но распространение, миниатюризация и удешевление ЭВМ привели к изменению ситуации. В последнее время появились не только ЛВС, но и Интернет.
Среда Интернет была построена, по сути, Пентагоном. Идея состояла в том, чтобы распределить компьютеры по стране так, чтобы некоторые из них могли выходить из строя, а между собой компьютеры могли взаимодействовать по методу точка-точка.
Сейчас сотрудникам корпораций необходим круглосуточный доступ к данным из любой точки планеты. Нужно обеспечить независимость от программно-аппаратного обеспечения и серьезную стандартизацию, возможно выше уровня операционной системы. Таким образом возникли открытые системы. Они обладают рядом важных свойств, которые позволяют наращивать комплексы без потери работоспособности. Во-первых, это мобильность, которая обеспечивает легкость миграции приложений в аппаратно-программной среде. Когда мы заказываем билет через Интернет, мы не отдаем себе отчет в том, с каким именно сервером мы работаем. Это возможно, так как разработчики обеспечивают соответствие стандартам. Еще одно свойство – интероперабельность обеспечивает легкость построения новых приложений на основе готовых компонентов со стандартными интерфейсами. Приложения по известным описаниям компонентов могут строиться независимо друг от друга и с учетом взаимодействия по стандартным протоколам взаимодействовать.
Кроме того, имеется возможность обеспечить постепенное наращивание функциональности приложений, можно улучшать компоненты независимо. Это обеспечивает эволюционный путь развития системы и позволяет плавно вести сопровождение.
Основной принцип при проектировании корпоративных систем, если рассматривать разработку в интернет-аспекте, состоит в разделении ресурсов и функций между компьютерами, предназначенными для обслуживания и запроса информации, между клиентами и серверами. При этом развитие идеи ЛВС приводит к выделению функциональных компонентов. Выделяются компьютеры – рабочие станции для обеспечения прикладного интерфейса (пример – веб-браузер как тонкий клиент). Можно обеспечить легкий и недорогой набор функций, который позволяет получить доступ к корпоративным данным. С другой стороны, есть сервер с существенными объемами памяти и вычислительной мощностью. Часто это может быть кластер из нескольких машин. Сервер предоставляет средства обслуживания пользователя, он получает одно логическое имя на кластер, и мы не знаем, какой именно компьютер обрабатывает наш запрос, нам не важно, какой компьютер нам отвечает.
Дальнейшая спецификация функций приводит к выделению серверов телекоммуникационных, вычислительных и дисковых (файл-серверов), кэш-серверов. Также есть серверы БД, обрабатывающие множество запросов. Для этого выделяется кластер для обработки SQL-запросов. Здесь четко разделены роли сервера и клиента. Сервер предоставляет ресурсы клиентам, клиентами могут выступать и другие серверы.
Основные принципы архитектуры клиент – сервер: выделенный программный интерфейс, четко определенные протоколы взаимодействия (рис. 6.2). В физически разных местах присутствуют независимо взаимодействующие с одним сервером, не знающие друг о друге клиенты. При этом клиент никак не может определить, сколько еще клиентов взаимодействуют с сервером, протоколы, функции, количество параметров четко определены в описаниях компонентов. На этой основе мы можем независимо постепенно наращивать функциональность клиента и сервера.
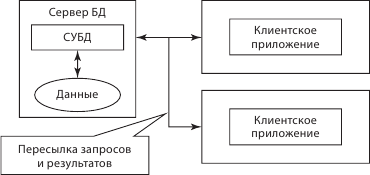
Рис. 6.2. Обработка данных СуБД: клиент – сервер
В больших корпоративных сетях есть относительно старые части, которые используют свои средства кодировки шифрования и передачи. Одним из стандартных решений является применение Remote Procedure Call (RPC). Обращение к серверу сводится к вызову функции. Все детали реализации остаются для разработчика сервера неважными, поэтому приложения на основе RPC легко переносятся в среды с открытыми интерфейсами.
Далее речь пойдет о базах данных корпоративных систем, их особенностях и разновидностях. Корпоративные базы данных бывают достаточно разнородными. БД можно назвать приборной доской бизнеса – по ней видны бизнес-успехи, текучесть кадров, динамика движения средств.
Базы данных – неотъемлемая часть информационных систем. В корпорациях уже имеются петабайты данных, и эти объемы растут, удваиваясь каждые пять лет. В корпорациях необходимо распределенное управление БД. В основе подобных технологий лежат распределенные СУБД, основанные на концепции открытых систем. Стандарты взаимодействия в таких системах фиксированы, и имеется возможность масштабируемости и плавного наращивания функциональности. В основе архитектур, которые поддерживают корпоративные информационные системы с базами данных, лежит разделение систем по функциям на клиентскую и серверную части. В развитие этой идеи выделяются специализированные серверы для телекоммуникаций, баз данных, осуществления прикладной логики, шифрования. В связи с такой специализацией традиционная двухзвенная архитектура преобразуется в трехзвенную, в которой выделяются три уровня – презентационная логика, бизнес-логика и логика доступа к ресурсам. В зависимости от балансировки этих трех уровней логики осуществляется дальнейшая конкретизация трехзвенной архитектуры клиент – сервер до моделей с толстым клиентом, тонким клиентом и явным выделением сервера приложений.
Речь идет о больших и сложных БД, поэтому стоит рассмотреть особенности применения архитектуры клиент – сервер к БД. Важно, что явно выделяется приложение клиент – frontend и серверное приложение – backend. Для пользователя, работающего через веб-браузер, все происходит незаметно. Один из примеров графического интерфейса – это банкомат. Ограничения целостности достигаются тем, что БД находятся на сервере. В случае заказа билетов через терминал речь идет о возможности покупки билета на одно и то же место. Здесь есть достаточно важный ряд вопросов и ограничений. Эти ограничения стоит хранить как можно ближе к серверу, производящему общение с базой данных, при этом запросы будут обрабатываться существенно быстрее.
Преимущества лучших черт предыдущих архитектур обеспечивают централизованное администрирование, в том числе и баз данных, безопасность, надежность и отказоустойчивость и файл-серверов, обеспечивающих достаточно низкую стоимость реализации и распределение обработки данных с использованием клиентских компьютеров. Современные клиентские компьютеры, как правило, достаточно мощные. Вспомним, что Windows Vista налагает серьезные требования на вычислительную мощность и объемы памяти современных компьютеров (1Гб RAM). Ряд ресурсов клиента можно использовать.
Рассмотрим, как осуществляется обработка данных в различных архитектурах. Самый простой, исторически первый подход – персональный компьютер. Здесь все происходит локализованно и достаточно просто. Система управления БД и приложение клиент находятся на одном компьютере. В корпоративных системах такое невозможно, поскольку, во-первых, объемы данных исчисляются петабайтами, во-вторых, консолидированные отчеты требуют сбора данных из большего количества компаний из разных стран. Локальные приложения для корпоративных приложений неприменимы.
Самое простое, что можно применить, – это файл-сервер. Есть выделенный компьютер-клиент и другой выделенный компьютер (файл-сервер), возможно, в другом сегменте локальной сети. Файл-сервер хранит исключительно данные. Например, на нем могут храниться документы для коллективной работы с ними. У клиента есть приложение СУБД, текстовый редактор или редактор таблиц, с помощью которых он взаимодействует с этими данными. При этом клиентов может быть довольно много. Пересылка данных осуществляется по каналам локальной сети. Все остальное, кроме данных, нужно устанавливать на клиентские машины заново. Бизнес-логика, СУБД находятся у клиента. Это невыгодно для больших нагрузок и интенсивностей SQL-запросов. Возможно долгое ожидание сервера, если вычисления осуществляются на клиенте. Магистраль тоже может быть перегружена. Для разгрузки магистрали и нагрузки сервера используется клиент-серверная архитектура. Таким образом мы избавляемся от долгой и дорогостоящей настройки СУБД на каждом клиенте. СУБД находится на сервере и взаимодействует с данными на этом или другом сервере. Логически обращение происходит всегда к одному серверу. На клиенте находится только приложение (логика). Таким образом, сервер становится существенным звеном. Магистраль разгружается. Клиент становится более специализированным и дешевым. Обработка данных становится эффективнее, и количество пользователей можно увеличить. При этом в явном виде можно выделить сервер базы данных как особый уровень (рис. 6.3).
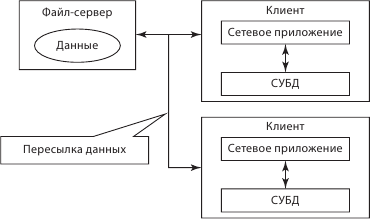
Рис. 6.3. Обработка данных СуБД: файл-сервер
Возможности, характерные для данной архитектуры таковы: во-первых, явно присутствуют клиентская и серверная части; во-вторых, сервер БД отвечает за хранение данных и предоставление доступа к БД. Общая база данных хранится на сервере и доступна всем пользователям ЛВС. Таким образом, клиент получает согласованные данные, доступные всем пользователям, хранение удешевляется, а доступ к БД становится распределенным. Отдельные фрагменты БД могут храниться на разных компьютерах в одном узле ЛВС.
Запрос на доступ к данным инициируется клиентской частью. Все клиент-серверное взаимодействие строится на стандартах. В данном случае используется язык SQL – язык структурных запросов к БД со стандартами от 1992 г. и более поздний стандарт ANSI. Они позволяют инкрементально наращивать функциональность и обеспечить взаимодействие БД, созданных разными производителями (Microsoft, Oracle). Под SQL-сервером понимается логическое имя, возможно группа компьютеров или кластер со стандартным интерфейсом в виде языка SQL. При этом в идеале любой SQL-клиент совместим с любым SQL-сервером. Если вернуться к схеме взаимодействия клиента и сервера БД, то можно видеть, что на сервер приходится большая нагрузка. В связи с этим SQL-сервер является не только центральным звеном системы БД, но и наиболее ответственным и важным звеном, узким местом всей системы, несмотря на то, что клиент сам по себе достаточно мощный. Если клиент может взять на себя часть функций прикладной логики, то он должен ее на себя взять. В этом и состоит перспектива систем управления БД – гибкая балансировка нагрузки между клиентом и сервером.
Исторически первым методом организации клиент-серверного взаимодействия была RPC. Эта архитектура значима и сегодня. На довольно низком уровне можно обеспечить распределение нагрузки. Некоторые компоненты могут располагаться на клиенте. Если ЛВС вычислительно неоднородна, то взаимодействие на уровне процедурных сервисов позволяет скрыть неоднородность сети. При этом снижается значимость аппаратной совместимости. Часть парка аппаратного обеспечения может быть заменена без критического влияния на важные системы. Принцип открытых систем сглаживает подобные неровности инкапсуляцией функциональности на прикладном уровне процедур приложений. Если говорить о SQL-сервере, то функциональное разделение производится следующим образом. СУБД работает на стороне сервера, на стороне клиента организуется лишь инициирование запросов к SQL-серверу. Вся работа по формированию запросов, обработке данных, организации транзакционного многопользовательского взаимодействия осуществляется на стороне сервера. Ряд запросов носит типовой характер. Результат этих запросов стоит кешировать в ОЗУ на сервере. Таким образом возникает возможность хранения кэша на выделенном сервере. Если клиент использует одни и те же запросы, стоит кешировать БД на локальной машине. Так можно моделировать работу сервера на клиенте и осуществлять ряд операций по обработке данных локально. В отличие от традиционной клиент-серверной архитектуры мы получаем распараллеливание и балансировку прикладных функций между клиентом и сервером. Прежде чем обсудить трехзвенную архитектуру, поговорим об особенности архитектуры сервера баз данных.
Основное требование к серверу БД – обеспечение максимальной производительности при большом числе пользователей, даже если они сложные и требуют взаимодействия таблиц, расположенных на разных серверах, пользователей много и запросы разные. Используются многопроцессорные, многопоточные архитектуры. Ведущие производители применяют различные подходы.
Рассмотрим основы многопроцессорной и многопоточной архитектуры. При каждом сеансе связи пользователя с сервером осуществляется создание нового экземпляра приложения (Oracle). При этом преимуществом является масштабируемость, что требует большого объема памяти. Многопоточный подход (Microsoft, Sybase) заключается в том, что на один экземпляр приложения запускается несколько потоков, это требует меньше ресурсов. При многопроцессорном подходе ОС ориентируется на разделение времени между экземплярами приложений, при каждом соединении создается новый процесс.
Вернемся к вопросу о балансировке нагрузки между клиентом и сервером. Речь идет о выделении третьего уровня прикладной логики. Верхний уровень, связанный с логикой работы приложения, расщепляется на два. Трехуровневая архитектура включает в себя презентационную логику (PL), бизнес-логику (BL) и логику доступа к ресурсам (AL). BL можно размещать как на сервере, так и на клиенте, а также выделить на отдельный сервер, тогда появляется понятие сервера приложений. Тонкий клиент – легкий клиент с презентационной логикой, например браузер. Толстый клиент (remote data access, RDA) объединяет бизнес-логику и презентационную логику. Сервер приложений можно выделить в отдельный программный уровень.
Под толстым клиентом (RDA) понимается объединение на клиентской части логики, связанной с презентацией, и бизнес-логики. Только логика доступа к ресурсам оставлена на сервере (рис. 6.4).
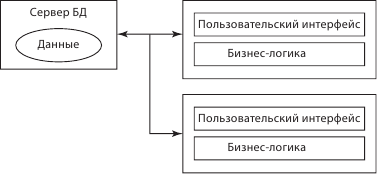
Рис. 6.4. Модель трехуровневой архитектуры клиент – сервер: толстый клиент
Другой вариант взаимодействия в трехуровневой модели – тонкий клиент (как правило это веб-браузер) (рис. 6.5). У клиента остается только презентационная логика, а бизнес-логика и логика доступа к ресурсам остаются на сервере. Дальнейшая балансировка загрузки дает возможность выделить еще один логический слой – сервер приложений, который не обязательно является отдельным физическим сервером.
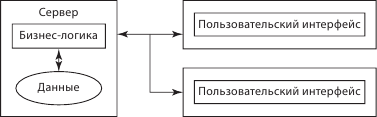
Рис. 6.5. Модель трехуровневой архитектуры клиент – сервер: тонкий клиент
КИС активно взаимодействуют с более крупными системами, которые представляют собой конгломераты информационных систем федеративного интегрированного уровня. Преимущественно такое взаимодействие осуществляется в режиме частичного предоставления данных или организации специфического доступа к ним в форме мультибаз данных. Интегрированные федеративные системы являются глобальными системами, объединяющими различные модели данных, как реляционные, так и иерархические, сетевые в ряде случаев и объектные, и конгломераты различных СУБД (рис. 6.6).
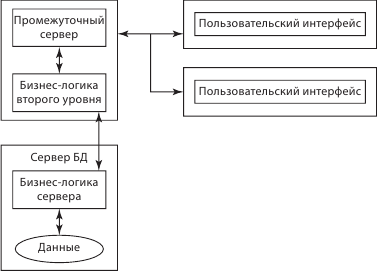
Рис. 6.6. Модель трехуровневой архитектуры клиент – сервер: сервер приложений
Рассмотрим особенности тонкого и толстого клиентов. Тонкий клиент широко распространен в корпоративных системах. Клиент становится легче, а все, что связано с бизнес-логикой, выносится на сервер. Клиент требует только настройки соединения, и обновление его становится проще. Использование тонких клиентов делает возможным применение бездисковых станций. Администраторам становится легче обеспечивать безопасность. При необходимости миграции в новую среду можно организовать ее удаленно. Это дает экономию на десятках тысяч клиентов.
Толстые клиенты преимущественно распространены в системах, не требующих частой коррекции. Если часть бизнес-логики переносится на логический сервер, выделяется уровень приложений (Application Layer, AL). При этом на сервере БД работает только та часть бизнес-логики, которую можно вынести в бизнес-правила уровня предприятия или целой группы логически связанных прикладных программ. Тонкие клиенты работают на компьютерах пользователей, сервер БД освобождается от бизнес-логики и работает только на передачу данных серверу приложений и пользователям. Реализация сервера приложений может быть как в виде SQL-сервера, так и в виде персональной СУБД.
В случае толстого клиента бизнес-логика переносится на мощные клиентские компьютеры. На клиентских машинах происходит взаимодействие бизнес-логики и презентационной логики, а на сервере осуществляются только SQL-запросы.
При использовании тонкого клиента вся бизнес-логика, которая была сосредоточена на каждом из сотен тысяч клиентов, переносится на сервер и централизованно управляется там. Она взаимодействует с данными и SQL-серверами. Клиент снабжается только пользовательским интерфейсом. Администрирование и централизованная миграция производятся на сервере, поэтому изменения с точки зрения сроков и стоимости происходят более эффективно. Бизнес-логика может быть расположена на одном и том же сервере с БД, а может быть перенесена на один или несколько серверов. Коррективы в таких системах можно вносить как на нижнем уровне, так и на более высоком. Например, в семействе Oracle Applications на нижнем уровне расположен сервер базы данных Oracle Server, а на более высоком уровне существует Application Server, на котором и располагаются все компоненты, выполняющие прикладные задачи. Это ERP-системы Oracle Applications или Oracle Business Suit, которые осуществляют прикладную логику: учет, планирование и управление основными видами корпоративных ресурсов.
Для производства корпоративных приложений нужно эффективно пользоваться специализированными инструментальными средствами, которые этот цикл поддерживают. Речь идет о средствах автоматизированного проектирования корпоративных приложений, или CASE-средствах. При этом если говорить о базах данных, необходимы специфические CASE-средства. В чем же заключаются эти особенности применительно к распределенным системам клиент-серверного типа? Эти средства являются достаточно универсальными, так как обеспечивают возможность соединения с различными серверами БД и позволяют разрабатывать графические интерфейсы (формы ввода данных, отчеты), чтобы пользователи могли взаимодействовать с данными в этих графических интерфейсах. Речь идет о том, что взаимодействие с базой данных может осуществлять не только программист, но и опытный пользователь, системный, бизнес-аналитик. Более того, если правильно построить цикл разработки корпоративной системы, можно обеспечить возможность взаимодействия этого бизнес-аналитика с существующей системой и развитие этой системы бизнес– аналитиком. Он сможет строить в терминах бизнес-логики, почти естественных языковых терминах, необходимые запросы и отчеты. При этом в почти автоматическом режиме происходит соединение с сервером БД, и графический интерфейс во многом набирается из тех примитивов, которые есть в распоряжении такого продвинутого пользователя.
Особенность систем проектирования взаимодействия корпоративных систем с базами данных – это в первую очередь объектная ориентированность. Речь идет о наборе компонентов для взаимодействия с серверами, основанных на технологиях ODBC (Object Database Connectivity), соединении с базами данных на основе объектных технологий либо более старой технологии OLE (Object Linking and Embedding). Кроме того, это визуализация, основанная на объектных библиотеках, средство командной разработки (например, Visual Studio Team System/Team Suit), а также языки четвертого поколения, которые поддерживают возможность написания программ в терминах скрипт-языков или во многом визуальной разработки.
К CASE-поддержке систем с базами данных можно отнести такие средства, как:
• Oracle Developer;
• Borland Delphi;
• MS Visual Studio (MSVS);
• Sybase PowerBuilder.
В Oracle Developer есть расширения для создания веб-приложений Oracle Web Developer, кроме того, также как и в MSVS, в нем может быть использовано подключение к другим базам данных на основе открытых интерфейсов (например, ODBC). Эти средства являются конвейерами для интеграции с различными SQL-серверами.
Средства, поддерживающие разработку персональных СУБД, с которых начинались небольшие системы, – это были, по сути, CASE-средства и серверы базы данных в миниатюре. Они также поддерживают SQL-запросы и разработку бизнес-логики, независимую работу клиентского приложения и в ряде случаев имеют специализированные форматы хранения данных, основанные на специфических СУБД (например, в семействе приложений Lotus на основе Lotus Domino сервера и персональной СУБД Lotus Approach речь может идти о нереляционной БД, многозначной структуре данных, когда речь идет о неатомарных атрибутах в БД). Рассмотрим основы того, из чего выросли современные средства. Атрибутами настольных систем были легкий удобный графический интерфейс, интеграция с пакетами офисных приложений (MS Office в том числе), визуальные средства, которые позволяют вести быстрое построение приложений и отчетов. В MS Access есть набор визардов для экспресс-построения отчетов, и среда реализации основана на объектном подходе (ODBC, COM, OLE). В MS Access можно встроить макросы на Visual Basic, который во многом является объектным. Эти средства хоть и в нестандартном виде используют язык SQL, с помощью которого осуществляется запрос к локальной БД.
Усовершенствование этих средств и выделение явного уровня клиента и сервера привели к появлению определенных особенностей в двух– и трехуровневой архитектурах клиент – сервер.
Если говорить о двухуровневой архитектуре клиент – сервер, можно выделить следующие особенности применительно к сетевым средам Интернет и интранет. Интернет важен для корпоративных сетей. В данном случае мы разделяем уровни веб-браузера и вебсервера. Речь идет о взаимодействии по протоколу HTTP. Сервер предоставляет клиенту HTML-страницу, а браузер отображает страницу, обрабатывая HTML-теги (рис. 6.7).
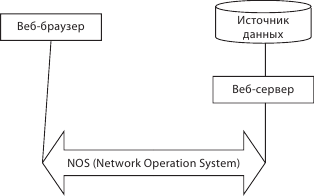
Рис. 6.7. Двухуровневая архитектура клиент – сервер в сетях Интернет/интранет
При переходе к трехуровневой системе возникает промежуточный слой, связанный с JSP (Java Server Pages) или ASP (Active Server Pages). Промежуточный слой в виде веб-сервера, сервер БД, осуществляющий SQL-взаимодействие с БД, и клиент в виде веб-браузера.
Основные протоколы – HTTP, или HTTPS. Преимуществами являются снижение трафика, большая взаимозаменяемость компонентов за счет стандартных интерфейсов и протоколов, а также увеличение безопасности. Недостаток связан с тем, что HTTP – это протокол без состояния (stateless). В связи с этим сложно организовать транзакционную обработку БД, что крайне важно для систем корпоративного размера, поскольку многопользовательская работа подразумевает транзакционность и изоляцию пользователя. Осуществляется псевдопараллельная работа со сложным управлением транзакциями.
При трехуровневой архитектуре обобщенное взаимодействие между клиентом и сервером выглядит следующим образом (рис. 6.8). Клиент в виде веб-браузера отсылает серверу запрос на доставку веб-страниц, данных в рамках протокола HTTP. Выполняется передача данных в определенном формате. После того как веб-сервер получает запрос на отображение веб-страницы от сервера БД, он передает после перекодирования HTML-страницы клиенту. Вебсервер – это промежуточное звено между клиентом и БД. Он получает от клиента в сыром виде запрос на получение информации и обращается к серверу БД по средствам запросов. Существуют программы расширения серверной части, которая получает от вебсервера запрос на получение данных и общается с сервером БД. Она принимает запрос, переформулирует его на языке SQL и передает его серверу БД. Сервер БД специализируется исключительно на выполнении SQL-запросов. Он выполняет запрос в форме определенного количества записей из БД программе-расширению. После чего происходит передача информации веб-серверу с преобразованием в формат веб-браузера. Затем происходит передача клиенту страницы с результатом. Таким образом, происходит двухуровневое взаимодействие.
В трехзвенном клиент-сервере взаимодействие происходит более сложным образом. Между веб-сервером и источником данных появляется еще один уровень, реализующий прикладную логику на основе программных расширений. Информация в формате HTML от веб-браузера преобразуется к виду, который может быть транслирован в SQL-запрос, который выполняет SQL-сервер. После этого происходит обратное преобразование в HTML и передача его клиенту. Используются программы-расширения CGI-скрипты, API. Основная цель для трехзвенной клиент-серверной архитектуры – за счет взаимодействия по стандартным протоколам осуществить специализацию деятельности компонентов. И за счет этой специализации ускоряется обработка запросов. Отдельно выделяется задача поддержания соединения с БД для минимизации сетевого трафика. Кроме того, для обеспечения масштабируемости необходимо поддерживать резерв в соединении с БД для того, чтобы в пиковый период увеличить нагрузку. Стандартизация компонентов дает возможность инкрементально наращивать функциональность отдельных систем.
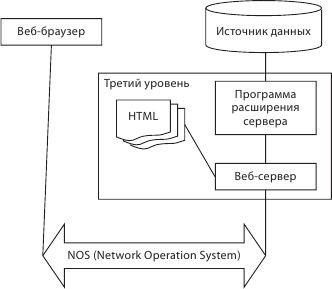
Рис. 6.8. Трехуровневая архитектура клиент – сервер в сетях Интернет/интранет
Кроме традиционных корпоративных систем стоит рассмотреть системы, не являющиеся корпоративными с точки зрения решаемых бизнес-задач. Речь идет о системах, которые поддерживают на уровне государств функционирование достаточно важных информационных служб, например электронное правительство или система, объединяющая различные модели данных и построенные на их основе базы данных. В ряде случаев необходимо использовать не только реляционные базы данных, но и современные объектно-ориентированные модели данных, которые в чисто реляционные таблицы не вполне укладываются исходя из динамического характера объектов и ряда других факторов. Имеются как теоретические, так и удовлетворительные практические результаты в объединении неоднородных источников данных. При этом возможны различные подходы к интеграции неоднородных баз данных. Это можно осуществить путем разработки новых моделей данных, которые объединяют различные подходы к хранению данных (реляционный, сетевой, иерархический, объектно-ориентированный) на основе чисто объектных моделей. Другой подход основан на преобразовании языков манипулирования данными (аналогичных SQL) для взаимодействия с данными, которые хранятся в нереляционных форматах, создании адаптеров для такого рода нереляционных СУБД. При интеграции подобных систем в глобальную среду сетевых коммуникаций, в интернет-среду важной проблемой становится обработка достаточно сложных запросов. Важными аспектами такой интеграции является управление транзакциями на глобальном уровне. Это сложная и многоплановая задача. Сложность вызывает оптимизация запросов, если речь идет об использовании разного рода баз данных для ответов на запросы, а кроме того, администрирование этих данных, ведение журнала, аудит пользователей для получения консолидированных отчетов по безопасности.
Зачастую пользователи этих систем не могут открыть все свои данные в федеративные системы защиты. Выходом является формирование мультибаз данных, которые сохраняют локальную автономность, т. е. для ряда систем имеет место лишь частичная интеграция в федеративные системы. Глобальной схемы данных пользователями не предоставляется, доступ дается в ограниченном виде или особыми способами с механизмами защиты.
Другим интересным направлением в развитии корпоративных систем с базами данных является их взаимодействие с GRID-системами, которые представляют собой глобальные высокопроизводительные сети для вычислений над большими объемами данных в короткие сроки. В ряде случаев такие объемы данных накапливались годами и измеряются терабайтами. Интеграция гетерогенных информационных систем в мультибазы данных и их взаимодействие с GRID являются перспективными направлениями исследований. При этом интерес представляет как построение моделей данных в основном на основе объектов для поддержки этих интегрированных систем, так и разработка средств реализации такого рода систем, в том числе специализированных адаптеров для известных систем, чтобы появилась возможность интегрировать вновь создаваемые системы в существующие среды.
GRID-системы – это системы распределенных вычислений, отличные от традиционных корпоративных СУБД. В ряде корпораций уже есть примеры использования таких систем. Под этим термином понимается глобально распределенная сеть, которая в отличие от корпоративных систем должна обеспечивать очень высокую производительность, дающую возможность обычным компьютерам соперничать в производительности с супер-ЭВМ. В ряде отраслей знания есть потребность хранения и обработки терабайтных объемов данных. Это нужно в биологии для анализа ДНК, в медицине для компьютерной томографии в реальном времени и анализа развития онкологических заболеваний, в геофизике для анализа спутниковых данных об атмосферных явлениях, в астрономии для анализа динамики космических тел, в физике элементарных частиц для анализа данных с ускорителей, в криптографии, вычислениях (константы пи). Характерные скорости поступления информации в таких системах – 100 Мб/с.
Необходима возможность подключения к одной сети множества компьютеров, соединенных оптоволоконными линиями. Для реализации GRID объединяются организации, обладающие высоким потенциалом с точки зрения количества единиц современной вычислительной техники. Примером могут служить ЦЕРН (Европейский центр ядерных исследований) или МИФИ (GRID-центр).
Помимо перечисленных задач есть отрасли, потенциально нуждающиеся в GRID: видеоконференции, дистанционное обучение, изучение фундаментальных процессов, научные исследования, имеющие дистанционный характер, высокопроизводительные вычисления.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК