Глава 4 Принципы работы микропроцессора
Теперь рассмотрены принципы работы основных узлов микропроцессорной системы, и можно перейти к изучению операционного блока микропроцессора. Он предназначен для выполнения команд, т. е. реализует операции обработки данных. Однако прежде чем рассмотреть этот блок, давайте научимся представлять данные в двоичном виде и немного поучимся считать. Обратите внимание, что все примеры будут приведены в двоичном виде. Именно в такой форме выполняет обработку данных цифровая аппаратура. Здесь не будет использоваться шестнадцатеричная или восьмеричная форма записи двоичного кода. Эти формы записи двоичного числа удобны своею краткостью. Но для лучшего понимания принципов обработки данных удобней использовать двоичную запись.
Виды двоичных кодов
В микропроцессорах двоичные коды используются для представления любых обрабатываемых данных: чисел, текста, команд и т. д. При этом разрядность двоичных кодов может превышать разрядность внутренних регистров самого процессора и ячеек используемой памяти. В таком случае длинный код может занимать несколько ячеек памяти и обрабатываться несколькими командами процессора. Подчеркнем, что все ячейки памяти, выделенные под многобайтное число, рассматриваются как одно число.
Для представления числовых данных могут использоваться знаковые и беззнаковые коды. Для определенности примем разрядность процессора равной 8 битам, и в последующих примерах будем рассматривать именно такие числа.
Беззнаковые двоичные коды
Первый вид двоичных кодов, который мы рассмотрим, используется для представления целых беззнаковых чисел. В нем каждый двоичный разряд представляет собой степень цифры 2. Формат 8-разрядного беззнакового двоичного кода приведен на рис. 4.1.
Рис. 4.1. Формат 8-разрядного беззнакового двоичного кода
При этом минимально возможное число, которое можно записать таким двоичным кодом, равно 0. Максимально возможное число, которое можно представить этим кодом, можно определить как
М = 2n — 1
где n — разрядность двоичного числа. Разрядность числа обычно выбирают кратной разрядности микропроцессора.
Эти два числа полностью определяют диапазон значений чисел, которые можно представить двоичным кодом. В случае двоичного 8-разрядного беззнакового двоичного кода целые числа, которые можно записать с его помощью, находятся в диапазоне от 0 до 255. Восьмиразрядное двоичное число обычно называют байтом.
Для беззнакового двоичного 16-разрядного кода диапазон представляемых значений будет от 0 до 65535. В микропроцессорной системе, построенной на 8-разрядном процессоре, для хранения 16-разрядного числа используется две ячейки памяти, расположенные в соседних адресах. Для работы с числами, занимающими несколько ячеек памяти, используются специальные команды микропроцессора, позволяющие учитывать перенос между младшими и старшими байтами.
Прямые знаковые двоичные коды
Второй вид двоичных кодов, который мы рассмотрим, — это прямые целые знаковые коды. В этих кодах старший разряд в слове используется для представления знака числа. В прямом знаковом коде нулем обозначается знак «+», а единицей — знак «-». В результате введения знакового разряда диапазон чисел, представляемых двоичным кодом, смещается в сторону отрицательных чисел. Формат 8-разрядного прямого знакового двоичного кода приведен на рис. 4.2. На рисунке приведено шесть различных чисел, записанных в этом коде.
Рис. 4.2. Формат 8-разрядного прямого знакового двоичного кода
Диапазон 8-разрядных целых чисел, которые можно записать, пользуясь таким кодом, простирается от -127 до +127. Для 16-разрядного числа этот диапазон составит от -32767 до +32767. В 8-разрядном процессоре для хранения такого числа используются две ячейки памяти, расположенные в соседних адресах.
Недостатком прямого знакового кода является то. что знаковый разряд и цифровые разряды приходится обрабатывать раздельно. Алгоритм программ, работающих с такими кодами, получается сложный. Для выделения и изменения знакового разряда приходится применять механизм маскирования разрядов, что резко увеличивает размер программы и уменьшает ее быстродействие. Для того чтобы алгоритм обработки знакового и цифровых разрядов не различался, были введены обратные двоичные коды.
Знаковые обратные двоичные коды
Обратные двоичные коды отличаются от прямых только тем, что отрицательные числа в них получаются инвертированием всех разрядов положительного числа. При этом обработка знакового и цифровых разрядов не различается. Алгоритм работы с такими кодами резко упрощается.
Тем не менее, при работе с обратными кодами требуется специальный алгоритм распознавания знака, вычисления абсолютного значения числа и восстановления знака результата числа. Кроме того, в прямом и обратном коде для представления числа 0 используются два разных кода, тогда, как известно, что число 0 положительное и отрицательным не может быть никогда. Формат 8-разрядного обратного знакового двоичного кода приведен на рис. 4.3. На рисунке приведено шесть различных чисел, записанных в этом коде.
Рис. 4.3. Формат 8-разрядного обратного знакового двоичного кода
Знаковые дополнительные двоичные коды
От перечисленных недостатков свободны дополнительные коды. Они позволяют суммировать положительные и отрицательные числа, не анализируя знаковый разряд, и при этом получать правильный результат. Все это становится возможным благодаря тому, что дополнительные числа являются естественным кольцом чисел, а не искусственным образованием, как прямые и обратные коды. Кроме того, немаловажным является то обстоятельство, что вычислять дополнение в двоичном коде чрезвычайно легко. Для этого достаточно к обратному коду добавить 1.
Формат 8-разрядного дополнительного знакового двоичного кода приведен на рис. 4.4. На рисунке приведено шесть различных чисел, записанных в этом коде.
Рис. 4.4. Формат 8-разрядного дополнительного знакового двоичного кода
Числа, которые можно представлять 8-разрядным дополнительным двоичным кодом, находятся в диапазоне от -128 до +127. Для 16-разрядного кода этот диапазон будет от -32768 до +32767. В 8-разрядном процессоре для хранения 16-разрядного числа используются две ячейки памяти, расположенные в соседних адресах.
В обратных и дополнительных кодах наблюдается интересная особенность, которая называется эффектом распространения знака: при преобразовании однобайтного числа в двухбайтное достаточно всем битам старшего байта присвоить значение знакового бита исходного байта. То есть для хранения знака числа можно использовать сколько угодно старших битов. При этом значение кода совершенно не изменяется. Эффект распространения знака используется при подключении таких устройств, как АЦП или ЦАП, к микропроцессору если их разрядности не совпадают.
Использование для представления знака числа двух битов предоставляет интересную возможность контролировать возникновение переполнения при выполнении арифметических операций. В качестве второго знакового бита используется флаг переноса С. Можно конечно использовать и большее количество знаковых битов, но это никаких дополнительных преимуществ не дает.
Рассмотрим несколько примеров работы с дополнительными двоичными кодами.
1. Просуммируем числа +12 и +5. Суммирование этих чисел в двоичном и десятичном представлении приведено на рис. 4.5.
Рис. 4.5. Суммирование чисел +12 и +5
В этом примере видно, что в результате суммирования получается правильный результат. Это можно проконтролировать по флагу переноса С, который совпадает со знаком результата (эффект распространения знака действует).
2. Просуммируем два отрицательных числа -12 и -5. Суммирование этих чисел в двоичном и десятичном представлении приведено на рис. 4.6.
Рис. 4.6. Суммирование чисел -12 и -5
В этом примере флаг переноса С тоже совпадает со знаком результата, т. е. переполнения не произошло и в этом случае.
3. Просуммируем положительное и отрицательное числа -12 и +5. Суммирование этих чисел в двоичном и десятичном представлении приведено на рис. 4.7.
Рис. 4.7. Суммирование чисел -12 и +5
В этом примере при суммировании положительного и отрицательного числа автоматически получается правильный знак результата. В данном случае знак результата отрицательный. Флаг переноса совпадает со знаком результата, поэтому переполнения не было (мы можем убедиться в этом непосредственными вычислениями на бумаге или на калькуляторе).
4. Просуммируем положительное и отрицательное числа +12 и -5. Суммирование этих чисел в двоичном и десятичном представлении приведено на рис. 4.8.
Рис. 4.8. Суммирование чисел +12 и -5
В данном примере знак результата положительный. Флаг переноса совпадает со знаком результата, поэтому переполнения не было и в этом случае.
5. Просуммируем числа +100 и +31. Суммирование этих чисел в двоичном и десятичном представлении приведено на рис. 4.9.
Рис. 4.9. Суммирование чисел +100 и +31
В этом примере видно, что в результате суммирования произошло переполнение 8-битовой переменной, т. к. в результате операции над положительными числами получился отрицательный результат. Если рассмотреть флаг переноса С, то он не совпадает со знаком результата. Эта ситуации является признаком переполнения результата и легко обнаруживается при помощи операции «исключающее ИЛИ» над старшим битом результата и флагом переноса С. Большинство процессоров осуществляют эту операцию аппаратно и помещают результат во флаг переполнения OV.
6. Просуммируем числа -100 и -31. Суммирование этих чисел в двоичном и десятичном представлении приведено на рис. 4.10.
Рис. 4.10. Суммирование чисел -100 и -31
В этом примере операции над отрицательными числами в результате суммирования произошло переполнение 8-битовой переменной, т. к. получился положительный результат. И в этом случае если рассмотреть флаг переноса С, то он не совпадает со знаком результата. Отличие от предыдущего случая только в комбинации этих битов. В примере 5 говорят о переполнении результата (комбинация 01), а в примере 6 — об антипереполнении результата (комбинация 10).
Представление рациональных чисел в двоичном коде с фиксированной запятой
Кроме целых чисел, часто требуется работать с рациональными числами. Как и в случае целых чисел, рациональные числа могут быть беззнаковыми и знаковыми. Для двоичного представления знаковых рациональных чисел могут быть использованы прямые, обратные и дополнительные коды. Принцип их построения точно такой же, как и в случае целых чисел.
Рассмотрим, как можно записать рациональное число. Ранее, рассматривая целые числа, мы предполагали, что в двоичном числе запятая, разделяющая целую и дробную части, находится правее самого младшего разряда. Но кто сказал, что она должна всегда находиться именно в этом месте? Мы можем договориться, что запятая, разделяющая целую и дробную части двоичного числа, находится слева от самого старшего разряда, и тогда в такой переменной можно будет записывать только дробные числа, меньшие 1,010. Формат 8-разрядного дробного беззнакового двоичного кода приведен на рис. 4.11. На рисунке приведены два числа, записанных в этом коде.
Рис. 4.11. Формат 8-разрядного дробного беззнакового двоичного кода
Или договоримся, что она находится точно посередине кода, и тогда мы сможем записывать числа, содержащие как целую, так и дробную части. Формат такого 8-разрядного беззнакового двоичного кода приведен на рис. 4.12. На рисунке приведены два числа, записанных в этом коде.
Рис. 4.12. Формат 8-разрядного смешанного беззнакового двоичного кода
Остальные виды двоичных кодов, используемых для представления чисел с фиксированной запятой, рассматривать не будем. Они строятся точно так же, как и для целых чисел.
Представление рациональных чисел в двоичном коде с плавающей запятой
Часто приходится обрабатывать очень большие числа (например, расстояние между звездами) или, наоборот, очень маленькие числа (например, размеры атомов или электронов). При таких вычислениях пришлось бы использовать числа с фиксированной запятой очень большой разрядности. В то же время нам не нужно знать расстояние между звездами с точностью до миллиметра. Для вычислений с такими величинами числа с фиксированной запятой неэффективны.
В десятичной арифметике в таких случаях число записывается в виде мантиссы, умноженной на 10 в степени, отображающей порядок числа, например:
2∙105; 1,6∙10-38.
В алгебре такое представление рациональных чисел называют стандартным видом числа. В двоичной арифметике тоже используется похожая форма записи чисел — представление с плавающей запятой (часто также называемое представлением с плавающей точкой).
А теперь рассмотрим промышленные стандарты, используемые для представления чисел с плавающей запятой в компьютерах. Существует стандарт IEEE 754 для представления чисел с одинарной точностью (float) и с двойной точностью (double). Для записи числа в формате с плавающей запятой одинарной точности требуется 32-битовое слово.
Для записи чисел с двойной точностью требуется 64-битовое слово. Чаще всего числа хранятся в нескольких соседних ячейках памяти процессора. Форматы одинарной точности и удвоенной точности числа с плавающей запятой приведены на рис. 4.13.
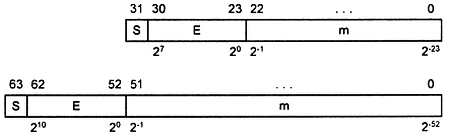
Рис. 4.13. Форматы чисел с плавающей запятой
На рис. 4.13 над полями числа с плавающей запятой показан номер двоичного разряда, а внизу двоичный вес каждого разряда. При этом буквой S обозначен знак числа, 0 — это положительное число, 1 — отрицательное число, е обозначает смещенный порядок числа. Смещение требуется, чтобы не вводить в число еще один знак. Смещенный порядок — всегда положительное число. В формате одинарной точности для порядка выделено 8 битов. Для смещенного порядка двойной точности отводится 11 битов. Для формата одинарной точности принято смещение 127, а для формата двойной точности — 1023. В десятичной мантиссе числа стандартного вида старший разряд — это цифра от 1 до 9. Старший разряд двоичной мантиссы — всегда 1. Поэтому для хранения старшей единицы двоичной мантиссы не выделяется отдельный бит. Единица подразумевается, как и запятая, отделяющая дробную часть от целой. Кроме того, в формате чисел с плавающей точкой принято, что мантисса всегда больше 1. То есть значения мантиссы лежат в диапазоне от 1 до 2.
Рассмотрим несколько примеров.
1. Определить число с плавающей запятой, лежащее в четырех соседних байтах:
11000001 01001000 00000000 00000000.
• Знаковый бит, равный 1, показывает, что число отрицательное.
• Экспонента 10000010 в десятичном виде соответствует числу 130. Вычтя число 127 (смещение) из 130, получим число 3.
• Теперь запишем мантиссу с учетом неявной единицы:
100 1000 0000 0000 0000 0000 1,1001
• И, наконец, определим десятичное число: 1100,12 = 12,510.
2. Определить число с плавающей запятой, лежащее в четырех соседних байтах:
11000011 00110100 00000000 00000000.
• Знаковый бит, равный 1, показывает, что число отрицательное.
• Экспонента 10000110 в десятичном виде соответствует числу 134. Вычтя число 127 из 134, получим число 7.
• Теперь запишем мантиссу:
011 0100 0000 0000 0000 0000 1,01101.
• И, наконец, определим десятичное число: 101101002 = 18010.
Для того чтобы записать ноль, достаточно записать в смещенный порядок число 000000002. Значение мантиссы при этом не имеет значения. Число, в котором все байты равны 0, тоже попадает в этот диапазон значений.
Бесконечность соответствует смещенному порядку 11111112 и мантиссе, равной 1,0. При этом существует минус бесконечность и плюс бесконечность (переполнение и антипереполнение), которые часто отображаются на экране монитора как +INF и — INF.
При таком значении порядка все остальные комбинации битов в мантиссе (в том числе и все единицы) воспринимаются как не числа и отображаются на экране как NaN.
Представление десятичных чисел
Иногда бывает удобно хранить числа в памяти процессора в десятичном виде (например, для вывода на экран дисплея или при финансовых расчетах). Для представления таких чисел используются двоично-десятичные коды. Цифра одного десятичного разряда представляется при помощи четырех двоичных битов, называемых тетрадой. Иногда встречается название, пришедшее из англоязычной литературы, — нибл. При помощи четырех битов можно закодировать шестнадцать цифр. Лишние комбинации в двоично-десятичном коде являются запрещенными. Таблица соответствия двоично-десятичного кода и десятичных цифр приведена в табл. 4.1.
Остальные комбинации двоичного кода в тетраде являются запрещенными.
Запишем пример двоично-десятичного кода:
1258 = 0001 0010 0101 1000
589 = 0000 0101 1000 1001
Достаточно часто в памяти процессора для хранения одной десятичной цифры выделяется одна ячейка памяти (8-, 16- или 32-разрядная). Это делается для повышения скорости работы программы. Для того чтобы отличить такое представление двоично-десятичного числа от стандартного, последнее называют упакованной формой двоично-десятичного числа.
Суммирование двоично-десятичных чисел
Суммирование двоично-десятичных чисел можно производить по правилам обычной двоичной арифметики, а затем производить двоично-десятичную коррекцию, заключающуюся в проверке каждой тетрады на допустимость ее кода. Если в какой-либо тетраде обнаруживается запрещенная комбинация или был перенос в старшую тетраду, то это говорит о переполнении. В этом случае необходимо произвести двоично-десятичную коррекцию. Двоично-десятичная коррекция заключается в дополнительном суммировании числа 6 (число запрещенных комбинаций) с тетрадой, в которой произошло переполнение. Приведем два примера использования двоично-десятичной коррекции. Просуммируем десятичное число 18, записываемое в двоично-десятичном коде как 0001 1000 и десятичное число 13, двоично-десятичный код 0001 0011. Ожидаемый результат 31. Запишем наши действия в столбик, как это показано на рис. 4.14.
Рис. 4.14. Суммирование чисел 18 и 13 в двоично-десятичном коде
В результате выполнения двоичного суммирования получим число 0010 1011 (2B16). To есть младшая тетрада содержит запрещенную комбинацию. Это означает, что необходимо выполнить десятичную коррекцию. Прибавим к младшей тетраде код коррекции 6. Эта операция показана на рис. 4.14 в столбике, записанном справа. В результате второго двоичного суммирования получаем результат 31. То есть именно то, что и ожидалось!
Во втором примере просуммируем два десятичных числа 19, записываемых в двоично-десятичном коде как 0001 1001. Ожидаемый результат 38.
Запишем наши действия в столбик, как это показано на рис. 4.15.
В результате выполнения двоичного суммирования получим число 0011 0010 (32). В этом случае запрещенных комбинаций нет. Но зато был перенос в старшую тетраду, т. е. и в этом случае необходимо выполнить десятичную коррекцию. Прибавим к младшей тетраде код коррекции 6.
Эта операция показана на рис. 4.15 в столбике, записанном справа. В результате второго двоичного суммирования получаем результат 38. То есть именно то, что и ожидалось! Работа со старшей тетрадой ничем не отличается от работы с младшей тетрадой, рассмотренной в приведенных примерах.
Рис. 4.15. Суммирование двух чисел 19 в двоично-десятичном коде
Представление текстовых данных в памяти процессора
Для кодирования всех символов и букв достаточно восьми двоичных разрядов. Наиболее распространенными являются таблицы кодирования текста ASCII с национальными расширениями, применяемые в DOS (и которые можно использовать для записи текстов в микропроцессорах), и таблицы ANSI, применяемые в Windows. В этих двух группах таблиц первые 128 символов совпадают. В этой части таблицы содержатся символы цифр, знаков препинания, латинские буквы верхнего и нижнего регистров и управляющие символы. Национальные расширения символьных таблиц и символы псевдографики содержатся в последних 128 кодах этих таблиц, поэтому кодировки русских текстов в DOS и Windows не совпадают. Таблица ASCII-символов приведена в Приложении.
Арифметико-логические устройства
Теперь после того как мы научились работать с двоичными кодами, можно перейти к устройствам, которые могут выполнять различные операции над этими числами — суммировать, вычитать, увеличивать и уменьшать на единицу. При этом выбор выполняемой операции желательно выполнять также при помощи двоичного кода. Такое устройство получило название арифметического устройства. Если же оно, кроме арифметических операций, выполняет еще и логические, то его называют арифметико-логическим устройством (АЛУ).
Ранее были рассмотрены схемы, осуществляющие суммирование многоразрядных кодов. Однако часто требуется осуществлять не только суммирование, но и вычитание двоичных кодов. Двоичные коды, при помощи которых можно записывать отрицательные числа, уже рассматривались в предыдущих разделах. Там же было показано, что при использовании дополнительных кодов операцию вычитания двух положительных чисел можно заменить операцией суммирования положительного и отрицательного числа, при этом получение двоичного отрицательного числа из положительного является элементарной операцией. Для этого необходимо проинвертировать число и прибавить к нему 1.
Схема вычитателя числа А из числа В приведена на рис. 4.16, а схема читателя числа В из числа А приведена на рис. 4.17. В этих схемах прибавление единицы к проинвертированному числу осуществляется подачей уровня логической единицы на вход переноса сумматора PL. Основным элементом этих двух схем является сумматор. Различаются они лишь местом включения инверторов.
Рис. 4.16. Схема вычитателя числа А из числа В
Рис. 4.17. Схема вычитателя числа В из числа А
Если же потребуется в процессе вычислений изменять арифметическую операцию, то в схему можно ввести коммутатор, который будет изменять ее внутреннюю структуру в зависимости от выполняемой арифметической операции. Такое устройство получило название арифметического устройства. Его структурная схема приведена на рис. 4.18. По ней легко получить принципиальную схему, поэтому для упрощения анализа все дальнейшие рассуждения будем производить по структурной схеме.
Рис. 4.18. Структурная схема арифметического устройства
В приведенной на рис. 4.18 схеме используются четырехвходовые мультиплексоры, для управления каждым из которых достаточно двух битов. То есть для управления всей схемой в целом достаточно четырех сигналов управления. Попытаемся построить таблицу операций, которые будет выполнять эта схема. На результат операции будет влиять входной сигнал переноса сумматора PI, поэтому его тоже включим в состав кода, управляющего схемой. Операции, которые выполняются арифметическим устройством в зависимости от кода, поданного на управляющие линии, приведены в табл. 4.2.
Проанализируем эту таблицу. Если на все управляющие входы подать низкий потенциал, то к входу сумматора будут подключены коды А и В без инверсии. В этом случае будет производиться операция суммирования. Эта ситуация отображена первыми двумя строками (с номерами 0 и 1) таблицы выполняемых операций.
Операция вычитания осуществляется строками 2, 3, 8 и 9. В этом случае один из операндов поступает на вход сумматора через блок инверторов. Единица, требуемая для получения дополнительного кода, подается на вход переноса сумматора PI.
Часто используемой операцией является увеличение числа на единицу (инкрементирование) или уменьшение числа на единицу (декрементирование). Эти операции позволяют легко организовывать циклы в программе и переходить от предыдущего операнда к следующему. Они могут быть выполнены при помощи кодов, записанных в строках 4, 7, 16 и 25.
Кроме того, схема арифметического устройства может просто передавать на выход любой из входных кодов без изменения, что позволяет осуществлять копирование данных (суммирование с константой ноль) через это устройство без дополнительных схем коммутации.
При небольшом изменении схемы такое устройство сможет осуществлять не только арифметические, но и логические операции. Для этого нужно ввести дополнительный коммутатор, который будет разрывать цепи переноса между разрядами. Эта управляющая цепь обычно называется М. Подчеркнем основную особенность полученного устройства: выбор вида выполняемой операции при помощи кода, подаваемого на специальные выводы. Это дает возможность использовать одно и то же устройство для выполнения различных функций. Разработка такого устройства позволила обменивать большую скорость выполнения отдельных операций на сложность реализуемого алгоритма, что, в конце концов, привело к разработке микропроцессорных систем. Развитие этих систем изменило окружающий нас мир.
Классификация микропроцессоров
Прежде чем приступить к изучению внутреннего устройства микропроцессоров, рассмотрим основные их типы.
По внутреннему устройству в настоящее время наметилось два направления развития микропроцессоров:
— RISC-процессоры (процессоры с сокращенным набором команд);
— CISC-процессоры (процессоры с полным набором команд).
В процессорах с полным набором команд используется уровень микропрограммирования, обеспечивающий декодирование и выполнение команд микропроцессора. Команды микропрограмм называют микрокомандами. В этих процессорах формат команды не зависит от аппаратуры процессора. На одной и той же аппаратуре при смене микропрограммы могут быть реализованы различные микропроцессоры.
С другой стороны, смена аппаратуры никак не влияет на программное обеспечение микропроцессора. При разработке новых микросхем можно использовать аппаратурные решения, никак не связанные с предыдущей микросхемой. Главное, чтобы микропрограмма эмулировала эту микросхему. То есть пользователь воспринимает новую микросхему как полный аналог старой. С его точки зрения у микропроцессора только увеличивается производительность, снижается потребление энергии, уменьшаются габариты устройств.
Определение микрокоманды и пример реализации микропрограммы будут подробно рассмотрены ниже по тексту данной главы. Поэтому сейчас эти понятия уточняться не будут.
Неявным недостатком CISC-процессоров является то, что производители микросхем стараются увеличить количество команд, которые может выполнять микропроцессор, тем самым увеличивая сложность микропрограммы и замедляя выполнение каждой команды.
В RISC-процессорах декодирование и исполнение команды производятся аппаратно, поэтому количество команд ограничено минимальным набором. В этих процессорах понятия команда и микрокоманда совпадают.
Преимуществом этого типа процессоров является то, что команда может быть в принципе выполнена за один такт (не требуется выполнение микропрограммы), однако для выполнения тех же действий, которые выполняет одиночная команда CISC-процессора, требуется выполнение некоторой последовательности команд RISC-процессоров, иногда это последовательность довольно длинная. То есть выигрыш в быстродействии микропроцессора может быть сведен к нулю.
В большинстве случаев быстродействие у RISC-процессоров выше, чем у CISC-процессоров. Тем не менее, при выборе процессора нужно принимать в расчет все параметры в целом. Нужно учитывать, что тактовая частота RISC-процессора может оказаться значительно ниже, чем у CISC-процессора (особенно если в нем применяются специальные меры по повышению производительности), разрядность команды может оказаться выше, чем у CISC-процессора (что чаще всего и бывает). В результате общий объем исполняемой программы для RISC-процессора, как правило, превышает объем подобной программы для CISC-процессора.
Следующий признак классификации архитектур микропроцессоров — это система команд. По системе команд микропроцессоры отличаются огромным разнообразием, зависящим от фирмы-производителя. Тем не менее, можно определить две крайние архитектуры построения микропроцессоров:
— аккумуляторные микропроцессоры;
— микропроцессоры с регистрами общего назначения.
В микропроцессорах с регистрами общего назначения операнды математических операций могут находиться в любом внутреннем регистре.
В зависимости от типа операции команда может быть одноадресной, двухадресной или трехадресной.
Принципиальным отличием аккумуляторных процессоров является то, что математические операции могут производиться только над одной особой ячейкой памяти, аккумулятором. Для того чтобы произвести операцию над произвольной ячейкой памяти, ее содержимое необходимо скопировать в аккумулятор, выполнить требуемую операцию, а затем скопировать полученный результат в произвольную ячейку памяти.
В настоящее время в чистом виде не существует ни та, ни другая архитектуры. Все выпускаемые в настоящее время процессоры обладают системой команд с признаками, как аккумуляторных процессоров, так и микропроцессоров с регистрами общего назначения.
Следующий признак, по которому классифицируются микропроцессоры, — это способ работы с системной памятью. По способу работы с системной памятью существует два основных принципа построения микропроцессоров:
— гарвардская архитектура;
— архитектура фон Неймана.
В гарвардской архитектуре принципиально различаются два вида памяти:
— память программ;
— память данных.
В гарвардской архитектуре принципиально невозможно производить операцию записи в память программ, что исключает возможность случайного разрушения управляющей программы в случае неправильных действий надданными. Кроме того, в ряде случаев для памяти программ и памяти данных выделяются отдельные шины обмена данными. Эти особенности определили области применения гарвардской архитектуры микропроцессоров. Она применяется в микроконтроллерах, где требуется обеспечить высокую надежность работы аппаратуры. В сигнальных процессорах эта архитектура, кроме высокой надежности работы устройств, позволяет обеспечить высокую скорость выполнения программы за счет одновременного считывания управляющих команд и обрабатываемых данных.
Отличие архитектуры фон Неймана заключается в принципиальной возможности работы над управляющими программами точно так же, как и над данными. Это позволяет производить загрузку и выгрузку управляющих программ в произвольное место памяти процессора, которая в этой архитектуре не разделяется на память программ и память данных.
Любой участок памяти может служить как памятью программ, так и памятью данных. Причем в разные моменты времени одна и та же область памяти может использоваться и как память программ, и как память данных. Для того чтобы программа могла работать в произвольной области памяти, ее необходимо модифицировать перед загрузкой, т. е. работать с нею как с обычными данными. Эта особенность архитектуры позволяет наиболее гибко управлять работой микропроцессорной системы, но создает принципиальную возможность искажения управляющей программы, что понижает надежность работы аппаратуры. Архитектура фон Неймана используется в универсальных компьютерах и в некоторых видах микроконтроллеров.
В качестве примера реализации микропроцессора в. дальнейшем рассмотрим устройство процессора с полным набором команд. При этом будет рассматриваться упрощенная модель процессора.
Ядро CISC-микропроцессора состоит из двух основных частей:
— операционного блока;
— блока микропрограммного управления.
Операционный блок (ОБ) предназначен для считывания команд из системной памяти и выполнения считанных команд. Эти действия он осуществляет под управлением блока микропрограммного управления (БМУ), который формирует последовательность микрокоманд, необходимую для выполнения машинной команды. Микрокоманды меняются каждый раз после прихода импульса синхронизации микропроцессора.
Операционный блок микропроцессора
Основным принципом работы любого цифрового устройства с памятью, в том числе и микропроцессора, является наличие цепи синхронизации CLK. Синхросигнал, как и цепь питания, подводится к любому регистру цифрового устройства. Схема одного из вариантов операционного блока приведена на рис. 4.19.
Рис. 4.19. Операционный блок
В схеме, приведенной на рис. 4.19, явно просматривается, что отдельные биты микрокоманды (обозначены надписями внизу схемы) управляют различными элементами ОБ, поэтому их можно рассматривать независимо друг от друга. Такие группы битов называются полями микрокоманды. Кроме битов, управляющих арифметико-логическим устройством (АЛУ) и регистрами общего назначения (РОН), в микрокоманде есть биты, управляющие БМУ. Формат микрокоманды рассматриваемого процессора приведен на рис. 4.20. Результат выполнения микрокоманды записывается во внутренние регистры ОБ по сигналу синхронизации микропроцессора CLK.
Рис. 4.20. Формат микрокоманды процессора
Попробуем реализовать аккумуляторный процессор с архитектурой фон Неймана. В этом случае потребуется более простая система команд. Что такое команды микропроцессора и как они реализуются, мы рассмотрим позднее.
Для реализации аккумуляторного процессора необходимо один из регистров ОБ выделить в качестве аккумулятора АСС. Для хранения и декодирования выполняемой команды выделим 8-разрядный регистр, который назовем RI.
Для дальнейших рассуждений лучше иметь перед глазами временную диаграмму записи или чтения ОЗУ или чтения из ПЗУ. Можно воспользоваться временными диаграммами, приведенными на рис. 3.30 или 4.25.
Для работы с микросхемами ОЗУ и ПЗУ, в которых может храниться программа, требуется специальный счетчик, который будет определять начальный адрес команд микропроцессора. Назовем это устройство программным счетчиком. Счетчик можно реализовать на любом регистре, подключенном к АЛУ. Для этого к содержимому регистра будем добавлять длину команды и, тем самым, вычислять адрес следующей команды.
Выход программного счетчика можно было бы подключить к внешним выводам микропроцессора, в состав которого входит рассматриваемый операционный блок. Однако кроме адресов команд нам потребуются адреса данных, над которыми будет производиться работа. Поэтому выделим отдельный регистр, в который мы будем записывать необходимый адрес. Выходы этого регистра подключим к внешним выводам микропроцессора. Этот регистр назовем регистром адреса, а выводы, к которым будут подключены выходы этого регистра, — шиной адреса.
Значения битов регистра адреса непосредственно определяют уровни сигналов на линиях шины адреса. Таким образом, в данной главе впервые рассказано о записи двоичного кода в регистр для формирования логических сигналов на внешних выводах микросхемы. Этот метод широко используется в микропроцессорной технике, и примеры его применения будут часто встречаться в последующих главах.
Определим необходимую разрядность шины адреса, а значит и разрядность регистра адреса и программного счетчика. Так как в качестве примера мы выбрали 8-разрядный микропроцессор, то и все регистры в этом процессоре восьмиразрядные. Максимальное беззнаковое число, которое можно записать в такой регистр, — 255, но для большинства программ такого объема памяти недостаточно.
В приведенной на рис. 4.19 схеме для того, чтобы получить 16-разрядный адрес используются два 8-разрядных регистра адреса, которые образуют 16-разрядную пару регистров. Теперь максимальное число, которое можно записать в этих двух регистрах, будет 65535, что во многих случаях достаточно для адресации программ и обрабатываемых ими данных. Для того чтобы различать регистры старшего и младшего байта регистра адреса, обозначим их как RA — старший байт и RA — младший байт.
То же самое можно сказать и про программный счетчик. Он тоже должен быть 16-разрядным. И для него тоже выделим два 8-разрядных регистра.
Для того чтобы различать регистры старшего и младшего байта программного счетчика, обозначим их как РСН — старший байт и PCL — младший байт. Это позволяет при помощи 8-разрядного АЛУ формировать 16-разрядный адрес очередной команды при помощи последовательной работы с младшим и старшим байтом адреса.
Для реализации операций чтения или записи ОЗУ, кроме адреса и собственно данных, требуются еще сигналы управления. В простейшем случае это сигналы записи (WR) и чтения (RD). Для их формирования используем еще один регистр, выходы которого выведем за пределы микросхемы микропроцессора. Назовем его регистром управления (CR). Для формирования необходимых сигналов достаточно записывать в определенный бит регистра логический 0 или 1. Определим формат регистра управления. Пусть бит 0 этого регистра будет сигналом записи, а бит 1 — сигналом чтения. Остальные биты этого регистра пока не важны. Если потребуются дополнительные сигналы управления системной шиной, то можно воспользоваться зарезервированными сейчас битами. Полученный формат регистра управления приведен на рис. 4.21.
Рис. 4.21. Формат регистра управления (CR)
Блок микропрограммного управления
В простейшем случае блок микропрограммного управления можно построить на счетчике с возможностью предварительной записи и ПЗУ.
Структурная схема такого блока приведена на рис. 4.22.
Рис. 4.22. Блок микропрограммного управления
В этой схеме адрес очередной микрокоманды формирует двоичный счетчик. Если требуется осуществить безусловный или условный переход, то новый адрес записывается из ПЗУ в этот счетчик, как в обычный параллельный регистр, по сигналу параллельной записи V. Переход к следующему адресу микрокоманды производится по сигналу синхронизации микропроцессора CLK.
В приведенной схеме условный переход возможен по знаку результата операции, переносу, нулевому результату или переполнению. Следует заметить, что достаточно лишь флага N (знака числа) для реализации перехода по нескольким условиям: больше, меньше, больше или равно, меньше или равно.
Содержимое ПЗУ блока микропрограммного управления называется микропрограммой. Именно эта микропрограмма и реализует конкретный микропроцессор. При смене микропрограммы, в принципе, можно реализовать на одном и том же кристалле другой микропроцессор.
Команды микропроцессора
Команды микропроцессора в отличие от микрокоманд разрабатываются независимо от аппаратуры микросхемы, поэтому их разрядность обычно кратна восьми разрядам. Команда микропроцессора содержит как минимум код операции (КОП). Она может состоять только из кода операции, когда не требуется указывать адрес операнда (операнды это данные, над которыми выполняется заданная операция), или может состоять из кода операции и адресов операндов или данных. Однобайтовые команды позволяют работать с внутренними программно доступными регистрами процессора. Многобайтные команды могут содержать адреса операндов, размещенных в ОЗУ или ПЗУ, или сами операнды (данные). Форматы команд очень сильно зависят от структуры процессора. Рассмотрим построение команд для 8-разрядного процессора, построенного по архитектуре фон Неймана. Примеры форматов команд для такого процессора приведены на рис. 4.23.
Рис. 4.23. Форматы различных команд микропроцессора
Если для кода операции используется 8-разрядное число (байт), то при помощи этого числа можно закодировать 256 операций. В процессе разработки системы команд для операции может быть назначен любой код. Система команд является важным признаком, характеризующим конкретное семейство процессоров.
При кодировании команд разработчик микропроцессора может назначить любой операции любое число. Например, для операции сложения можно назначить код 1, для операции вычитания код 12 и т. д. Для выполнения одной и той же операции над разными регистрами процессора назначаются разные коды команд. Поэтому для операции суммирования может потребоваться 8 чисел (команд). Например, 1 — просуммировать аккумулятор с регистром R0, 2 — просуммировать аккумулятор с регистром R1, 3 — просуммировать аккумулятор с регистром R2 и т. д.
Запоминать эти коды очень утомительно для человека. При программировании в машинных кодах легко совершить ошибку и очень трудно найти ее, особенно если коды различаются только одним битом. Для сокращения объема записи вместо двоичного кода можно воспользоваться шестнадцатеричным, однако это не увеличивает удобочитаемости программы. Фрагмент шестнадцатеричного представления исполняемого кода программы для микропроцессора приведен на рис. 4.24.
Рис. 4.24. Фрагмент исполняемого кода микропроцессора
Ну, как? Очень легко разобраться в такой последовательности чисел?
Я думаю, не слишком. Чтобы уменьшить объем запоминаемой информации и увеличить наглядность исходного текста программы, для каждой операции процессора придумывают мнемоническое обозначение.
В качестве мнемонического обозначения операции обычно используют сокращения английских слов, образующих название этой операцию. Например, для операции копирования используется мнемоническое обозначение MOV; для операции суммирования — ADD; для операции вычитания — SUB; для операции умножения — MUL и т. д.
Полная запись команды содержит мнемоническое обозначение операции и используемые этой операцией операнды, которые перечисляются через запятую. При этом обычно операнд-приемник результата записывается первым, а операнд-источник операнда — вторым. Например:
MOV R0, А ;Скопировать содержимое регистра А в регистр R0
ADD A, R5 ;Просуммировать содержимое регистров R5 и А, результат поместить в регистр А
Приведенные выше команды — однобайтовые, т. к. в них используются только внутренние регистры процессора. Если в команде используется константа в качестве операнда или указывается адрес операнда в памяти, то код команды будет занимать в памяти два или три байта. Например:
MOV А, 1025 ;Скопировать содержимое ячейки памяти с адресом 1025 в регистр А
ADD A, #110 ;Просуммировать содержимое регистра А с числом 110
Несмотря на то, что общий объем исходного текста программы увеличивается, скорость написания и особенно отладки программ при применении мнемонического обозначения команд возрастает. Кто сомневается, может попробовать разобраться в программе, приведенной на рис. 4.24.
Теперь вместо одного текста программы в памяти компьютера или на бумаге придется хранить два варианта представления: один для человека, в дальнейшем будем называть этот вариант исходным текстом программы; другой для микропроцессора, в дальнейшем будем называть этот вариант загрузочным модулем.
Преобразование программы, записанной в мнемоническом виде, в машинные коды является рутинной работой, которую можно поручить компьютерной программе. Язык программирования, в котором для обозначения машинных команд используются мнемонические обозначения, называется ассемблером. Точно так же называют и программу или пакет программ, которые осуществляет трансляцию (преобразование) исходного текста программы, написанной на языке программирования ассемблер (исходный модуль), в машинные коды (загрузочный модуль).
Теперь, когда мы рассмотрели все составные части микропроцессора: операционный блок, блок микропрограммного управления, — а также систему команд, можно, наконец, приступить к реализации самого микропроцессора. Напомню, что архитектура микропроцессора реализуется микропрограммой и очень мало зависит от аппаратуры, для которой пишется эта микропрограмма. То есть, написав микропрограмму, мы тем самым построим микропроцессор с конкретной архитектурой. Микропрограмма состоит из сотен однотипных блоков, написанных для различных команд микропроцессора, поэтому достаточно рассмотреть реализацию нескольких типовых команд.
Микропрограммирование
Все действия микропроцессора и сигналы на его выводах определяются последовательностью микрокоманд, подаваемых на управляющие входы блока обработки сигналов. Эта последовательность микрокоманд называется микропрограммой.
При изучении принципов работы ОЗУ и ПЗУ приводились временные диаграммы, которые необходимо сформировать для того, чтобы записать или прочитать необходимые данные. Выберем одну из этих временных диаграмм (см. рис. 3.30).
Любую временную диаграмму формирует микропроцессор. Устройство микросхемы, на примере которой мы будем рассматривать формирование необходимых сигналов, было проанализировано при обсуждении операционного блока. По его структурной схеме (см. рис. 4.19) можно определить формат микрокоманды, управляющей этим блоком. Он приведен на рис. 4.20.
Для того чтобы разобраться в приводимых далее микропрограммах, желательно постоянно иметь перед собой временную диаграмму, формат микрокоманды и схему операционного блока.
Работа любого цифрового устройства начинается с заранее заданных начальных условий. Эти начальные условия формируются специальным сигналом RESET (сброс), который вырабатывается после подачи питания. Договоримся, что сигнал сброса микропроцессора будет записывать в регистр программного счетчика PC нулевое значение. Это условие справедливо не для всех процессоров. Например, IBM-совместимые процессоры при сбросе микросхемы записывают в программный счетчик значение F0000h, а процессоры фирмы Motorola заносят в него содержимое ячейки памяти с адресом FFFFh.
Выполнение любой команды начинается со считывания ее кода из памяти (ОЗУ или ПЗУ). Необходимые для этого микрокоманды подаются на входы управления ОБ из БМУ, как только снимается сигнал сброса.
В случае однобайтной команды достаточно считать из системной памяти только код операции и выполнить задаваемые им действия. Временная диаграмма этого процесса приведена на рис. 4.25. Последовательность операций, которые необходимо выполнить микропрограмме, показана стрелочками. Для считывания следующей команды микропрограмма запускается заново (зацикливается).
Для того чтобы считать код операции из памяти, сначала необходимо адрес этой команды выставить на шине адреса. Этот адрес хранится в счетчике команд PC. После сигнала сброса микропроцессора в этом регистре хранится нулевое значение. Скопируем его в регистр адреса RA, выходы которого подключены к шине адреса:
Рис. 4.25. Временные диаграммы сигналов считывания однобайтных команд из памяти
Затем сформируем сигнал считывания. Для этого в регистр управления запишем константу 1111 1110.
При этом на временной диаграмме, приведенной на рис. 4.25, сигнал чтения RD примет нулевое значение. Теперь можно считать число с шины данных, а т. к. память в этот момент выдает на нее код операции, то мы считаем именно его. Запишем его в регистр команд и снимем сигнал чтения с системной шины.
Для этого в регистр управления запишем константу 1111 1111.
Прежде, чем перейти к дальнейшему выполнению микропрограммы, увеличим содержимое счетчика команд на 1.
После считывания команды ее необходимо декодировать. Это можно выполнить микропрограммным способом, проверяя каждый бит регистра команд, и осуществляя ветвление по результату проверки, или включить в состав блока микропрограммного управления аппаратный дешифратор команд, который сможет осуществить переход микропрограммы на любую из 256 ветвей за один такт синхронизации микропроцессора. Выберем второй путь. Восьмым тактом микропрограмма направляется на одну из 256 ветвей, отвечающую за выполнение считанной команды. Например, если это была команда mov A, R0, to следующая микрокоманда будет выглядеть следующим образом:
И т. к. в этом случае команда полностью выполнена, то счетчик микрокоманд сбрасывается для выполнения следующей команды.
Рассмотрим еще один пример. Пусть из системной памяти считывается команда безусловного перехода JMP 1234. Первые восемь микрокоманд совпадают для всех команд микропроцессора. Различие наступает, начиная с девятой микрокоманды, которая зависит от выполняемой машинной команды. При выполнении команды безусловного перехода необходимо считать адрес новой команды, который записан в байтах, следующих за кодом операции.
Этот процесс аналогичен считыванию кода операции:
Теперь считаем второй байт адреса перехода.
Рис. 4.26. Временная диаграмма выполнения команды JMP 1234
В результате выполнения этой микропрограммы в программный счетчик будет загружен адрес, записанный во втором и третьем байтах команды безусловного перехода JMP 1234. Временная диаграмма, формируемая рассмотренной микропрограммой, приведена на рис. 4.26.
По аналогии с рассмотренными примерами можно разработать другие микропрограммы, которые могут понадобиться в дальнейшем.
Итак, подведем итоги
На этом закончим рассмотрение внутреннего устройства и принципов работы микропроцессора. Полученных знаний достаточно для того, чтобы приступить к рассмотрению принципов работы систем, построенных с использованием микропроцессора.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК