Выбор фрагментов текста для обработки
До сих пор мы вызывали sed для обработки всего переданного редактору потока данных. В некоторых случаях с помощью sed надо обработать лишь какую-то часть текста — некую конкретную строку или группу строк. Для достижения такой цели можно воспользоваться двумя подходами:
• Задать ограничение на номера обрабатываемых строк.
• Указать фильтр, соответствующие которому строки нужно обработать.
Рассмотрим первый подход. Тут допустимо два варианта. Первый, рассмотренный ниже, предусматривает указание номера одной строки, которую нужно обработать:
$ sed '2s/test/another test/' myfile
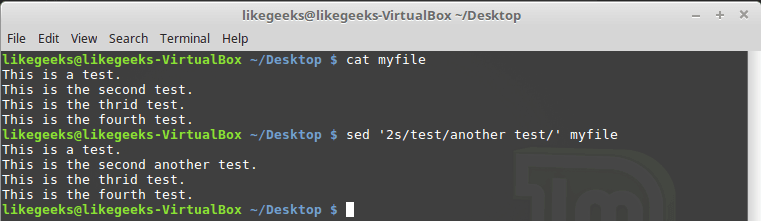
Обработка только одной строки, номер который задан при вызове sed
Второй вариант — диапазон строк:
$ sed '2,3s/test/another test/' myfile

Обработка диапазона строк
Кроме того, можно вызвать команду замены так, чтобы файл был обработан начиная с некоей строки и до конца:
$ sed '2,$s/test/another test/' myfile

Обработка файла начиная со второй строки и до конца
Для того, чтобы обрабатывать с помощью команды замены только строки, соответствующие заданному фильтру, команду надо вызвать так:
$ sed '/likegeeks/s/bash/csh/' /etc/passwd
По аналогии с тем, что было рассмотрено выше, шаблон передаётся перед именем команды s.

Обработка строк, соответствующих фильтру
Тут мы использовали очень простой фильтр. Для того, чтобы в полной мере раскрыть возможности данного подхода, можно воспользоваться регулярными выражениями. О них мы поговорим в одном из следующих материалов этой серии.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК