Приложение E Описание Base64
Приложение E
Описание Base64
Этот алгоритм был разработан для представления произвольных последовательностей байтов в форму, читаемую для человека. Кодирующий и декодирующий алгоритмы очень просты, но закодированные данные примерно на 33% больше, чем некодированные. Этот метод идентичен тому, который используется в приложениях PEM (Privacy Enhanced Mail), описанной в RFC 1421 с одним отличием: base64 не приемлет встроенного «чистого» текста.
Base64 использует 65-символьный поднабор из US-ASCII, выделяя 6 бит на каждый печатный символ. (65-й символ «=» используется для обозначения функции спец. обработки).
Этот поднабор имеет важное свойство: он идентичен всем версиям языковой кодировки ISO 646, включая US ASCII, а также всем версиям EBCDIC. Другие популярные механизмы кодирования (uuencode, base85 — часть уровня 2 PostScript) не разделяют этих свойств и поэтому не удовлетворяют требованиям переносимости для двоичных данных электронной почты.
Процесс кодирования преобразует 3 входных символа в виде 24-битной группы, обрабатывая их слева направо. Эти группы затем рассматриваются как 4 соединенные 6-битные группы, каждая из которых транслируется в одиночный символ алфавита base64. При кодировании base64, входной поток байтов должен быть упорядочен старшими битами вперед.
Каждая 6-битная группа используется как индекс для массива 64-х печатных символов. Символ, на который указывает значение индекса, помещается в выходную строку. Эти символы выбраны так, чтобы быть универсально представимыми и исключают символы, имеющие специальное значение для SMTP-транспорта («.», CR, LF) и для синтаксиса вложенных тел MIME («-»).
Таблица: Алфавит Base64
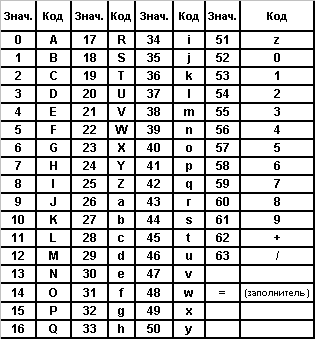
Выходной поток (закодированные байты) должен иметь длину строк не более 76 символов. Все признаки перевода строки и другие символы, отсутствующие в таблице 1, должны быть проигнорированы декодером base64. Среди данных в Base64 символы, не перечисленные в табл. 1, переводы строки и т.п. должны говорить об ошибке передачи данных, и, соответственно, почтовая программа должна оповестить пользователя о ней.
Если в хвосте потока кодируемых данных осталось меньше, чем 24 бита, справа добавляются нулевые биты до образования целого числа 6-битных групп. А до конца 24-битной группы остается от 0 до 3-х недостающих 6-битных групп, вместо каждой из которых ставится символ-заполнитель «=». Поскольку весь входной поток представляет собой целое число 8-битных групп (т.е., просто байтных значений), то возможны лишь следующие случаи:
(1) входной поток как раз оканчивается 24-битной группой. В таком случае, выходной поток будет оканчиваться четырьмя символами Base64 без символа «=»;
(2) хвост входного потока имеет длину 8 бит. Тогда в конце выходного кода будут два символа Base64, с добавлением двух символов «=»;
(3) хвост входного потока имеет длину 16 бит. Тогда в конце выходного будут стоять три символа Base64 и один символ «=».
Т.к. символ «=» является хвостовым заполнителем, его появление в теле письма может означать только то, что конец данных достигнут. Но такой гарантии нет, если число переданных битов кратно 24.
Любые бессмысленные последовательности в коде Base64 вроде «=====» должны быть игнорированы.
Основано на:
Спецификация RFC 1521 «MIME — Multipurpose Internet Mail Extensions. Part one.»
Перевод: Антон Воронин
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Включение музыки (base64)
Включение музыки (base64) Летом 2008 года весь мир облетела страница, содержащая реализацию первого уровня Super Mario Brothers. В нее, в общем, можно играть, хотя упущены многие ключевые аспекты (нет грибов, нет флага, нет повышающих очков и т. д.). Однако это, на самом деле, не самый
Приложение 5 Описание прилагаемой дискеты
Приложение 5 Описание прилагаемой дискеты Большинство примеров сценариев, которые приведены в книге, содержатся на прилагаемой дискете. Примеры находятся в папках, названных в соответствии с нумерацией глав, к которым они относятся: Chapter01, Chapter02, …, Chapter11 (табл.
Приложение. Описание прилагаемого компакт-диска
Приложение. Описание прилагаемого компакт-диска На компакт-диске, прилагаемом к книге, находится большинство дистрибутивов программ, которые в ней описаны. Если приложение бесплатно, то вы можете свободно использовать версию, записанную на прилагаемый к книге
Приложение A. Детальное описание специальных команд
Приложение A. Детальное описание специальных команд A.1. Вывод списка правил Чтобы вывести список правил нужно выполнить команду iptables с ключом L, который кратко был описан ранее в главе Как строить правила. Выглядит это примерно так:iptables -LЭта команда выведет на экран
ПРИЛОЖЕНИЕ Описание компакт-диска
ПРИЛОЖЕНИЕ Описание компакт-диска Диск предназначен в первую очередь тем пользователям, у которых низкоскоростной Интернет и которым по этой причине будет трудно скопировать дистрибутивы программ с сайта разработчиков. Если же у вас высокоскоростной Интернет, и вы
Приложение 1 Описание компакт-диска
Приложение 1 Описание компакт-диска
Приложение 3. Описание электронного архива
Приложение 3. Описание электронного архива По ссылке ftp://85.249.45.166/9785977506601.zip можно скачать электронный архив с рассмотренными в книге листингами и соответствующими им HTML-файлами (шаблонами) и рисунками. Эта ссылка доступна также со страницы книги на сайте www.bhv.ru.В
Приложение A. Краткое описание директив PSpice
Приложение A. Краткое описание директив PSpice В данном разделе директивы приведены в краткой форме. Этот список будет полезен, если вам необходимо найти команду, которую вы уже видели или использовали. Более подробная информация приведена в приложениях В и D и в конце каждой
Приложение Описание компакт-диска
Приложение Описание компакт-диска На компакт-диске, прилагаемом к книге, находятся дистрибутивы всех плагинов, которые описаны в книге. Исключение составляют только те коммерческие дополнительные модули, для которых недоступны демонстрационные версии, или те, для
2.37. base64-кодирование и декодирование
2.37. base64-кодирование и декодирование Алгоритм base64 часто применяется для преобразования двоичных данных в текстовую форму, не содержащую специальных символов. Например, в конференциях так обмениваются исполняемыми файлами.Простейший способ осуществить base64-кодирование и
Приложение Описание компакт-диска
Приложение Описание компакт-диска
Приложение Описание компакт-диска
Приложение Описание компакт-диска К книге прилагается установочный компакт-диск с дистрибутивом Ubuntu 10.04 для 32-битных компьютеров — именно эта версия использовалась при написании книги. 32-битная версия является более универсальной — ее можно установить как на 32-битные,
Приложение 5 Описание DVD-диска
Приложение 5 Описание DVD-диска К книге прилагается DVD-диск, на котором находятся:? система КОМПАС-Viewer V11;? система КОМПАС-3D LT V11;? задания по 15 темам в формате КОМПАС 5.11 R03, что позволяет выполнять учебные задания в любой версии КОМПАС-3D, старше указанной. По каждой теме
Приложение Ж Описание стандарта ISBN
Приложение Ж Описание стандарта ISBN Международное агентство ISBN присваивает идентификатор группы, который обозначает либо группу стран (например, 0 — для англоязычных стран: Великобритании, США, Австралии, Канады, Ирландии и других), либо отдельную страну (например, 933 —