Голубятня: Сверхполезная Сергей Голубицкий
Голубятня: Сверхполезная
Сергей Голубицкий
Опубликовано 20 ноября 2010 года
Сегодня расскажу о замечательнейшей утилите, работающей под Windows (под Maс OS X аналогов не существует). Сначала, однако, хочу подвести небольшую теоретическую базу под всю категорию данного софта.
Речь идет о ?text batch converters, конвертеров поточного преобразования текстовых файлов. Думаю, не будет преувеличением, что с годами пользователи (подчеркиваю: пользователи, а не профувязанные с компом не-буду-лишний-раз-произносить-кто-чтобы-не-сердить ) накапливают нечеловечески запасы всякого сетевого хлама — фильмов, картинок, звуков и книжек. Хлам — это я, конечно, пошутил: мусор на вашем компе сродни дворняжке, которую вы подобрали щенком лет восемь назад в городском парке у помойки и с тех пор породнились с ней душой и сердцем. Так что это только для взгляда со стороны на компьютере у вас хранится никому не нужный хлам. Для вас это — ценнейшая и полезнейшая информация, которую вы непременно когда-нибудь прослушаете, просмотрите, прочитаете.
Не буду опять расстраивать и говорить, что с огромной долей вероятности вы никогда уже в жизни собранную коллекцию не посмотрите и не послушаете, а уж тем более — не почитаете. Скорее всего плоды ваших многочасовых компьютерных бдений-скачиваний плавно перекочуют вашим наследникам после того, как вы отчалите в мир теней и гипотетических радостей. Надежда, однако, никогда не умирает, поэтому все мы верим, что наступит тот день, когда.... да я! да как открою первую страницу! да как начну глотать книгу за книгой! Ну и так далее.
Впрочем, есть и более прагматичный вариант, относящийся в первую очередь к книгам. Даже если вы никогда их не прочитаете, сохраняется шанс их использовать в виде ... референций! Для любого писателя или журналиста книги, собственно, вообще только и нужны, что для референций, но даже для рядового пользования электронная библиотека, переведенная в вид индексированной базы данных, представляет собой несоизмеримо более ценный объект, чем склад пылящихся электронных фолиантов в папках, поддиректориях, подподдиректориях и т.п. Положим, вы никогда не осилите шеститомник под редакцией Кеннета Сеттона об истории крестовых походов, и даже три тома Стивена Рансимена на ту же тему не потянете (не потому что не интересно или сложно — как раз наоборот, захватывающе и просто, а потому что банально нет времени), однако единожды введенные в базу данных и индексированные эти книги сослужат вам удивительную службу при написании статьи, дружеской беседе и — вот она, сермяга! — на форумных баталиях! Даже не будучи прочитанными книги начинают приносить пользу, переходят из абсолютно пассивного бесполезного качества, в полуактивное состояние. Уже ради этого можно оправданно продолжать закачивать и закачивать все новое и новое ad infinitum ? .
Короче говоря, вот о чем и к чему я клоню. С годами выделилась группа софтверных утилит, которые интересуют меня на голову больше всего остального — это те самые выше помянутые конвертеры поточного преобразования текстовых файлов. Дело в том, что электронные книги я как и все остальные пользователи собираю по сотням сусеков, поэтому в компьютер они попадают в самом непотребном виде. Во-первых, форматы: pdf, djvu (это самые мои ненавистные — кто только придумал этот чудовищный формат!), txt, doc, rtf, fb2, epub, pdb и бог весь еще что. Во-вторых, это кодировки: Cyrillic Windows (CP-1251), Cyrillic DOS (866), Cyrillic Unix (KOI8-R) плюс вся череда европейских и экстравагантных кодировок, унаследованных из ошибок (форточных) молодости. Можно, конечно, попытаться все это хозяйство в сыром виде закинуть в базу данных и проиндексировать, но почти гарантировано на выходе вы получите бесполезный инструмент.
Почему? Потому что файлы с неопознанной кодировкой в таком — абракадабровом — виде в базу данных и попадут, где и сгинут окончательно: ведь вы никогда не сможете выйти на первоисточник по своим запросам! Многое, конечно, зависит от выбранной базы данных. В Windows нам повезло — есть фантастический Архивариус 3000, зато под Mac OS X дела обстоят сильно печальнее: встроенный Spotlight, умиляющий примитивом, да FoxTrot Professional Search за какие-то непотребные деньги — 100 евро, которые, может, и оправдались бы, если бы продукт был достойный. А так — ползает еле-еле хуже даже почившей в бозе недотыкомки Евфрат Документооборот (когда-то лет 10 назад я сравнивал эту базу данных с восходящей звездой Cros, а года четыре назад уже и сам Cros уступил все лавры первенства Архивариусу 3000 — эх, бегут годы, бегут!).
Так вот: и Spotlight, и FoxTrot виндузовые кодировки в чисто текстовых файлах по умолчанию не понимают. Индексируют абракадаброй со всеми вытекающими. Можно, конечно, каждый файл отдельно открывать в TextEdit и перекодировать в UTF-8, но у меня этих файлов — с расширением TXT — в библиотеке тысяч сорок, если не более.
В итоге самыми востребованными в моем хозяйстве стали программы, которые на потоке преобразую различные текстовые файлы: конвертируют из одного формата в другой, меняют кодировки, унифицируют форматирование и прочая.
Вопросы унифицирования формата в Mac OS X решаются вполне себе пристойно: программа TextSoap вполне себе достойна форточного титана TextPipe Pro. Конвертация форматов по моим запросам более ли менее решается планомерным уничтожением в библиотеке дикого Djvu с помощью ABBYY Finereader. Под Маком существует только обрезанная версия Express, которая Djvu не понимает, зато с ним можно разобраться в версии Finereader для Windows с помощью дополнения DjVu.dll.
Для конвертации кодировок под Mac OS X нет ничего путного даже рядом (вполне, впрочем, вероятно, что плохо искал, так что если кто знает, поделитесь знаниями, пожалуйста), поэтому опять же приходится запускать виртуальную машину Parallels, а на ней — voila героиня нашей сегодняшней истории! — маленькую блестящую утилитку по имени UTFCast.
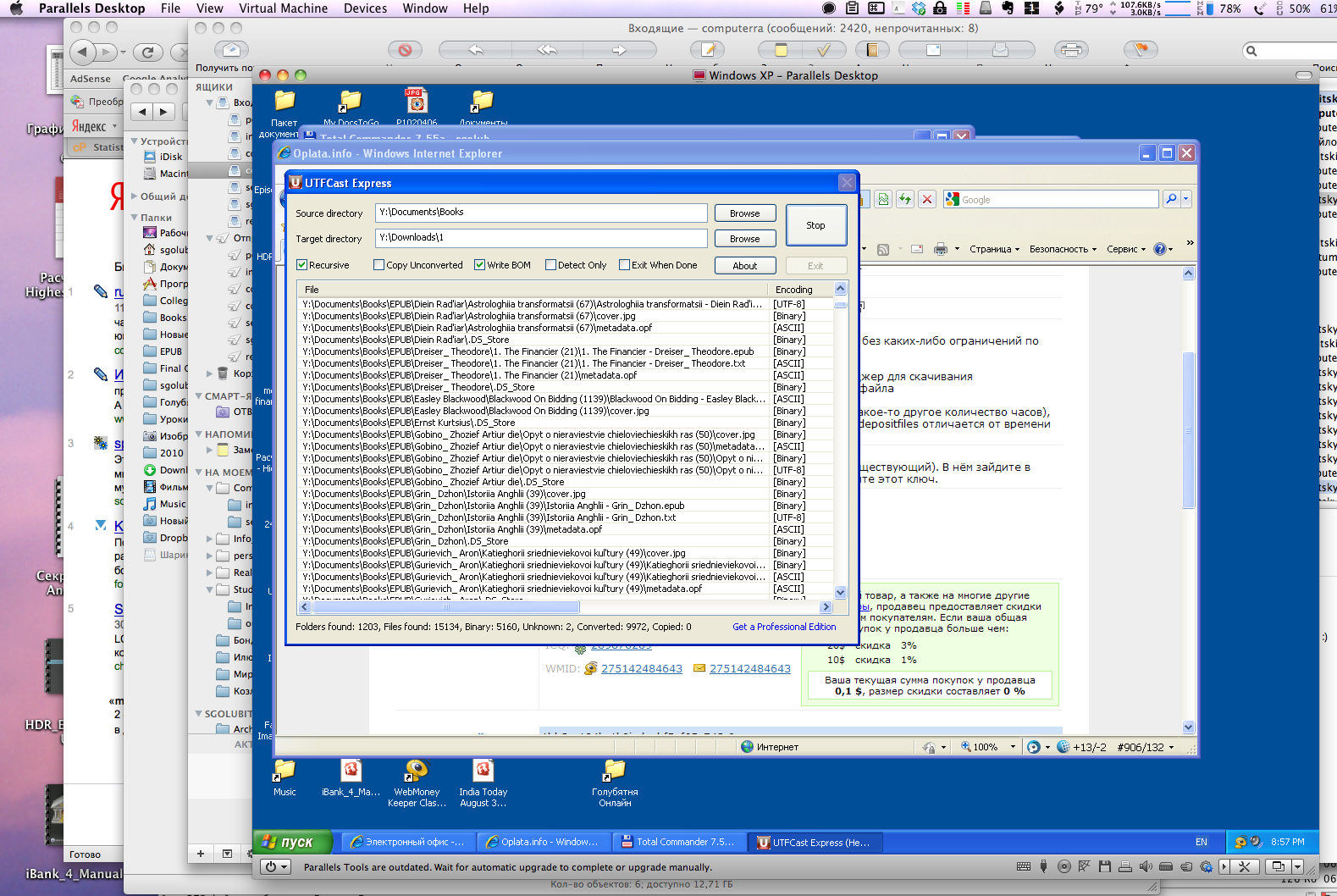
Надо сказать, что кодировочных конверторов для Windows создано море разливанное, однако я специально привлекаю внимание читателей именно к UTFCast — не только потому, что утилита жуть какая шустрая, удобная и надежная, но и потому что делает она единственно правильное дело: конвертирует кодировочный хлам прошлого в Unicode (UTF-8, UTF-16 или UTF-32). И это правильно, потому как, чем скорее все свои текстовые документы мы унифицируем в уникоде, тем проще нам будет жить и работать в будущем.
UTFCast представлен в двух ипостасях: бесплатной версии Express, которой мне лично хватило за глаза даже для поточной конвертации нескольких десятков тысяч файлов, и в платной Professional, которая за скромные 30 долларов позволяет конвертировать не только UTF-8, но и 16/32, обладает продвинутой техникой определения кодировок (30 штук) и обрабатывает в несколько потоков миллионы файлов на головокружительной скорости 40 мегабайт текста в секунду.
Welcome, короче, to the future!
К оглавлению
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Голубятня: Ась? Сергей Голубицкий
Голубятня: Ась? Сергей Голубицкий Опубликовано 12 октября 2010 года Читатели со стажем не дадут соврать: о системах распознания речи (VRS, Voice Recognition Systems) я писал регулярно, начиная с самой первой статьи, опубликованной в бумажной «Компьютерре» аж в 1996
Голубятня: Подстава Сергей Голубицкий
Голубятня: Подстава Сергей Голубицкий Опубликовано 16 декабря 2010 года Что-то сюжеты для моих постов обходятся мне все дороже и дороже. Ну да ладно: искусство настаивает на жертвоприношениях.Короче говоря два дня назад меня подставили на дороге. По
Голубятня: Дресс-код Сергей Голубицкий
Голубятня: Дресс-код Сергей Голубицкий Опубликовано 19 августа 2010 года Любое современное общество больно неврозом. Вопрос лишь в мере поражения души, сердца и мозга. Возьмем, к примеру, современную Америку. Неврозов много и большинство из них
Голубятня: Пратьяхара Сергей Голубицкий
Голубятня: Пратьяхара Сергей Голубицкий Опубликовано 16 апреля 2011 года Нигде больше кроме Индии я не встречал людей с чистой парадигмой. То есть таких, у которых та или иная психологическая или социальная функция доведена до предела, до
Голубятня: Шаньчжай Сергей Голубицкий
Голубятня: Шаньчжай Сергей Голубицкий Опубликовано 20 апреля 2011 года Сегодня у нас обзорный пост, предваряющий целый букет видеопрезентаций, которые прольются на читательские головы, начиная со следующей недели. У меня скопилось в ожидании
Голубятня: I Am You Сергей Голубицкий
Голубятня: I Am You Сергей Голубицкий Праздник «Холи» возбудил не только гоанцев, но и всю творчески активную тусовку европейского десанта. Надо сказать, что в Гоа постоянно проживает значительное количество музыкантов, художников, поэтов и танцоров, которые работают, не
Голубятня: Что еще? Сергей Голубицкий
Голубятня: Что еще? Сергей Голубицкий Опубликовано 25 июня 2011 года На мартовской презентации айпада Garage Band явился, как говориться, story apart. Не удивительно, что в среде профессиональных музыкантов и композиторов, познакомившихся с уникальными и
Голубятня: PX Сергей Голубицкий
Голубятня: PX Сергей Голубицкий На следующей неделе у меня будет большая съемка в передаче «Крипто» («Совершенно секретно»), посвященной «Филадельфийскому эксперименту». Казалось бы — ну что еще можно высосать интересного из этого замшелого сюжета в наши
Голубятня: Just 5 Сергей Голубицкий
Голубятня: Just 5 Сергей Голубицкий Опубликовано 12 января 2011 года Продолжаем новогодний видео марафон. Сегодня вертим в руках телефоны второго поколения от Just 5. В видео клипе я назвал сотрудников этой удачливой компании «нашими соотечественниками»
Голубятня: Out-of-the-box Сергей Голубицкий
Голубятня: Out-of-the-box Сергей Голубицкий Опубликовано 24 августа 2010 года Концепция out-of-the-box хорошо известна шозистам мира, хотя и не особо принята в нашем айтишном королевстве. Смысл концепции прост: распаковал коробку, достал и сразу же начал
Голубятня: Интерактив №3 Сергей Голубицкий
Голубятня: Интерактив №3 Сергей Голубицкий Опубликовано 01 июля 2010 года Продолжаем жамкать Жумлу с помощью, как теперь оказалось, уже двух профи. Андрей Мироненко JOOMLA. Часть 3 Продолжим.В процессе написания статьи и ответов на
Голубятня: Мера Сергей Голубицкий
Голубятня: Мера Сергей Голубицкий Опубликовано 02 июля 2010 года Внимательно наблюдаю за баталиями вокруг нового IPHONE 4: то ли антенна слабовата, то ли конструкция кривая, то ли полосы какие-то желтые вытянулись по экрану да пятна (эх, как же все
Голубятня: Сергей Комаров Сергей Голубицкий
Голубятня: Сергей Комаров Сергей Голубицкий Опубликовано 15 июля 2010 года Очередной микроюбилей — 200 публикация «Голубятни Онлайн». Вспоминаю бумажные «Голубятню 100», «Голубятню 200», «Голубятню 300», «Голубятню 400»! Надеялся дожить до совсем уж
Голубятня: АК-47 Сергей Голубицкий
Голубятня: АК-47 Сергей Голубицкий Опубликовано 16 июня 2010 года Пауза, вызванная традиционным летним анабазисом на юга, затянулась, поэтому беру стахановские обязательства: до конца месяца выдавать посты в удвоенном ритме! Тем более, что совсем без
Голубятня: КГ/АМ Сергей Голубицкий
Голубятня: КГ/АМ Сергей Голубицкий Опубликовано 26 марта 2012 года Повидло у меня сегодня слегка не первой свежести, но не беда: сладкий продукт не тухнет :) Тем более, что хочу предложить читателям довольно непривычный аспект хорошо знакомой