22. π эр Квадрат, или Арифметические вычисления с высокой точностью
22.
? эр Квадрат,
или Арифметические вычисления с высокой точностью
Математику часто считают сухой наукой, однако и математику творили люди. Одной из самых печальных была судьба Уильямса Шенкса, жившего в девятнадцатом веке и посвятившего себя вычислению числа ? с высокой точностью. Закончив многолетний труд, Шенкс в 1837 г. опубликовал значение ? до 707-го десятичного знака, впоследствии исправив некоторые знаки. Может быть, надо счесть за благо, что Шенкс умер в 1882 г., поскольку в 1946 г. было показано, что его вычисления ошибочны начиная с 528-го десятичного знака. Фактически Шенкс не продвинулся дальше своих предшественников.
Полученное Шенксом значение было проверено, вероятно, с помощью механических устройств, а компьютер был впервые использован для вычисления ? только в 1949 г.; это была машина ENIAC. Даже тогда проект был монументальным. Джорж У. Рейтуиснер писал: «Поскольку получить машину в рабочее время было практически невозможно, мы воспользовались разрешением выполнить эту работу за 4 выходных дня в период летних отпусков, когда ENIAC стоял без дела». Собственно вычисления (не программирование!) заняли 70 часов: было получено несколько больше 2 000 цифр. Все это время приходилось постоянно обслуживать компьютер, поскольку из-за ограниченности его возможностей требовались постоянная перфорация и ввод промежуточных результатов. Те первые программисты так же далеки от нынешних, как Шенкс далек от них.
Как бы мы стали вычислять ?? Во-первых, необходимо выражение, которое можно вычислять. Ряд
?/4 = 1 ? 1/3 + 1/5 ? 1/7 + 1/9 ? …
довольно прост для понимания, но он ужасно медленно сходится. Гораздо лучше ряд для арктангенса
arctg x = x ? х3/3 + х5/5 ? х7/7 + …, |x| ? 1
Объединим его с формулой сложения для тангенса
tg (a + b) = (tg a + tg b)/(1 ? tg a · tg b)
и выберем а и b так, чтобы tg (a + b) = 1 = tg ?/4. (Учитывая, что tg (arctg x) = х для ??/2 < х < ?/2, можно взять, например, а = arctg (1/2), b = arctg (1/3).)
Тогда
arctg (tg (a + b)) = a + b = arctg 1 = ?/4,
и теперь можно использовать приведенный выше ряд для нахождения a и b. На практике чаще всего используются следующие суммы:
?/4 = 4 arctg (1/5) ? arctg (1/239),
?/4 = 8 arctg (1/10) ? 4 arctg (1/515) ? arctg (1/239),
?/4 = 3 arctg (1/4) + arctg (1/20) + arctg (1/1985).
Теперь мы собираемся просуммировать эти ряды на ЭВМ. Как известно, все, что нужно для суммирования, — это простой итерационный цикл, но тут возникает одна проблема. Точность вычислений на ЭВМ ограничена, а весь смысл этого упражнения в том, чтобы найти много-много цифр числа ?, значительно превзойдя обычную точность. Первое, что приходит в голову, — промоделировать ручные методы выполнения арифметических действий. Будем представлять числа очень большими целочисленными массивами (по одной десятичной цифре в каждом элементе), тогда ясно, как составить программы сложения, вычитания и умножения. Запрограммировать ручной метод деления несколько сложнее, но все же возможно. Неприемлемым, однако, оказывается время выполнения алгоритмов. Хотя на это редко обращают внимание, но при ручных методах для умножения или деления n-значных чисел требуется время, пропорциональное n?. Если речь идет об операциях над числами из тысяч цифр, то такие расходы будут нам не по карману. К счастью, имеются лучшие алгоритмы.
Как можно быстро умножать?
Алгоритм быстрого умножения Тоома—Кука, описываемый Кнутом, зиждется на четырех основных идеях[31]. Вот первая из них. Пусть нам известен способ выполнения некоторой операции над исходными данными размера n за время T(n). Если эту операцию удастся разбить на r частей, выполнение каждой из которых займет менее чем T(n)/r шагов, то такое разбиение позволит улучшить общее время, если, конечно, считать, что вспомогательные организационные расходы не сведут экономию на нет. Пусть, далее, каждая из r частей есть применение того же алгоритма к исходным данным длины n/r и каждая часть может быть разбита аналогичным образом. Тогда можно продолжать это разбиение, пока мы не получим столь короткие исходные данные, что вычисления для них станут тривиальными и займут лишь небольшой фиксированный отрезок времени. Этот принцип разделяй и властвуй обычно дает выигрыш во времени работы алгоритма по крайней мере в log n раз; так, классический метод умножения требует времени n?, и его можно свести к
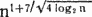 , что существенно лучше при больших n (не забывайте, что у обеих функций стоимости имеются постоянные множители).
, что существенно лучше при больших n (не забывайте, что у обеих функций стоимости имеются постоянные множители).
Остальные три идеи касаются чисел и действий над многочленами. Во-первых, заметим, что, если число U имеет длину n битов и записывается в двоичном виде как
un?1un?2…u2u1u0,
причем n делится на r + 1, то U можно также записать в виде
Ur2rn/(r+1) + Ur?12(r?1)n/(r+1) + … + U12n/(r+1) + U0,
где каждое Ui есть блок из n/(r + 1) битов исходного представления U. Фактически U = U(2n/(r + 1)), где многочлен U(x) есть
Urxr + Ur?1xr?1 + … + U1x + U0.
Во-вторых, мы видим, что если U и V — два n-разрядных числа, записанных в виде такого многочлена, то их произведение W дается формулой
W = UV = U(2n/(r + 1))V(2n/(r + 1)) = W(2n/(r + 1))
и если бы мы смогли найти хотя бы коэффициенты W(х), то вычислить W по W было бы сравнительно просто; для этого понадобились бы только сдвиги, сложения и умножения чисел из n/r битов. В-третьих, к счастью, W(х) — многочлен степени 2r и его можно найти с помощью интерполяции его значений в точках 0, 1, 2, …, 2r?1, 2r. Эти значения равны просто U(0), V(0), U(1), V(1), …, U(2r), V(2r). Более того, для вычисления всех этих многочленов и интерполяции требуется умножать числа только из n/r битов. Представляется, что эти действия подпадают под принцип «разделяй и властвуй».
Алгоритм Тоома—Кука весьма сложен, поэтому мы не будем подробно объяснять его; за этим можно обратиться к книге Кнута. Все же необходимо сообщить основные идеи и обозначения. Длинные числа должны быть как-то представлены; будем писать [p, u] для обозначения числа u из p битов. Вероятно, внутреннее представление [p, u] будет некоторой разновидностью списка или цепочки. Кроме основного алгоритма нам понадобятся подпрограммы для сложения и вычитания длинных чисел (используйте стандартный ручной метод сложения слева направо), умножения длинного числа на короткое (небольшое) число, деления длинного числа на короткое, сдвига длинного числа путем приписывания нулей справа и для разбиения длинного числа [p, u] на более короткие длинные числа [p/(r + 1), ur], [p/(r + 1), ur?1], …, [p/(r + 1), u0], как описано выше. Кроме подпрограмм, работающих непосредственно с числами, алгоритм использует четыре стека для хранения промежуточных частичных результатов и несколько временных переменных, поэтому требуются подпрограммы для выполнения некоторых действий над стеком, а также подпрограммы для выделения и освобождения памяти под длинные числа. При написании всяческих вспомогательных подпрограмм черновой работы может оказаться предостаточно.
Алгоритм быстрого умножения Тоома—Кука
Исходными данными служат два положительных длинных числа [n, u] и [n, v]; результатом — их произведение [2n, uv]. Используются четыре стека U, V, W и С, в которых при выполнении алгоритма будут храниться длинные числа, и пятый стек, содержащий коды временно приостановленных операций (имеется всего три кода, и для их представления можно воспользоваться малыми целыми числами). Массивы q и r целых чисел имеют индексы от 0 до 10; необходимо выделить память для этих двух массивов и для еще нескольких временных переменных, упомянутых в алгоритме.
1. (Начальная установка.) Сделать все стеки пустыми. Присвоить К значение 1, q0 и q1 — значение 16, r0 и r1 — значение 4, Q — значение 4 и R — значение 2.
2. (Построение таблицы размеров). Пока К < 10 и qK?1 + qK ? n, выполнять следующие вычисления. Изменить К на К + 1, Q — на Q + R; если (R + 1)? ? Q, то изменить R на R + 1; установить qK равным 2Q и rK равным 2R. Если цикл оканчивается из-за К = 10, то остановиться, выдав сообщение об ошибке — число битов n слишком велико, массивы q и r переполнились. В противном случае присвоить k значение K. Поместить [qK + qK?1, v] и за ним [qK?1 + qK, u] в стек С (вероятно, потребуется добавить к [n, u] и [n, v] слева нули). Поместить в управляющий стек код стоп.
3. (Главный внешний цикл.) Пока управляющий стек не пуст, выполнять шаги с 4-го по 18-й. Если на этом шаге управляющий стек окажется пустым, то остановиться с сообщением об ошибке; в управляющем стеке должен быть по крайней мере один элемент.
4. (Внутренний цикл разбиения и и v.) Пока к > 1, выполнять шаги с 5-го по 8-й.
5. (Установка параметров разбиения.) Установить k равным k ? 1, s равным qk, t равным rk и р равным qk?1 + qk.
6. (Разбиение верхнего элемента стека С.) Длинное число [qk + qk+1, u] на вершине С следует рассматривать как t + 1 чисел длиной s битов каждое. Разбить [qk + qk+1, u] на длинные числа [s, Ut], [s, Ut?1], …, [s, U1], [s, U0]. Эти t + 1 чисел являются коэффициентами многочлена степени t, который следует вычислить в точках 0,1, …, 2t ? 1, 2t no правилу Горнера. Для i = 0, 1, …, 2t ? 1, 2t вычислить [р, Xi] по формуле
(…([s, Ut]i + [s, Ut?1])i+ … + [s, U1])i + [s, U0]
и сразу поместить [р, Xi] в стек U. Для выполнения умножений можно использовать подпрограмму умножения длинных чисел на короткие; никакой промежуточный или окончательный результат не потребует более p битов. Удалить [qk + qk+1, u] из стека С.
7. (Продолжение разбиения.) Выполнить над числом [m, v], находящимся сейчас на вершине стека С, ту же последовательность действий, что на шаге 6; полученные числа [p, Y0], …, [p, Y2t] поместить в стек V в порядке получения. Не забудьте удалить вершину стека С.
8. (Заполнение заново стека С.) Попеременно удалять (2t раз) вершины стеков V и U и помещать эти значения в стек С. В результате значения, вычисленные на шагах 6 и 7, будут помещены, чередуясь, в стек С в обратном порядке. После выполнения этого перемешивания верхняя часть стека С, рассматриваемая снизу вверх, будет иметь вид [р, Y2t], [p, X2t], …, [р, Y0], [p, Х0], на вершине будет [р, Х0]. Поместить в управляющий стек один код операции интерполировать и 2t кодов операции сохранять и вернуться к шагу 4.
9. (Подготовка к интерполяции.) Присвоить к значение 0. Выбрать два верхних элемента стека С и поместить их в обычные переменные и и v. Оба числа и и v будут состоять из 32 битов. Используя некоторую другую подпрограмму умножения, вычислить [64, w] = [64, uv]. Это умножение можно выполнить аппаратно или с помощью подпрограммы, как вы найдете нужным.
10. (Интерполяция при необходимости.) Выбрать вершину управляющего стека в переменную А. Если значение А есть интерполировать, то выполнить шаги с 11-го по 16-й, в противном случае перейти к шагу 17,
11. (Организация интерполяции.) Поместить [m, w] в стек W (это может быть значение, полученное на шаге 9 или 16). Присвоить s значение qk, t — значение rk, р — значение qk?1 + qk. Обозначим верхнюю часть стека W, рассматриваемую снизу вверх, как
[2р, Z0], [2p, Z1], …, [2р, Z2t?1], [2p, Z2t],
последнее из этих значений — на вершине стека.
12. (Внешний цикл деления Z.) Выполнять шаг 13 для i = 1, 2, …, 2t.
13. (Внутренний цикл деления Z.) Присвоить [2p, Zj] значение ([2р, Zj] ? [2р, Zj?1])/i для j=2t, 2t ? 1, …, i + 1, i. Все разности будут положительными, а все деления выполняются нацело, т. е. без остатка.
14. (Внешний цикл умножения Z.) Выполнять шаг 15 для i = 2t ? 1, 2t ? 2, …, 2, 1.
15. (Внутренний цикл умножения Z.) Заменить [2р, Zj] на [2p, Zj] ? i[2p, Zj+1] для j = i, i + 1, …, 2t ? 2, 2t ? 1. Все разности будут положительными, и все результаты поместятся в 2р битов.
16. (Образование нового w и начало нового цикла.) Присвоить значение многочлена
(… ([2р, Z2t]2s + [2p, Z2t?1]2s + … + [2p, Zi]2s + [2p, Z0]
переменной [2(qk + qk+1), w]. Этот шаг можно выполнять, используя только сдвиги и сложения длинных чисел. Заметьте, что используется та же переменная [m, w], что и на шаге 9. Удалить [2р, Z2t], …, [2p, Z0] из стека W. Присвоить k значение k + 1 и вернуться к шагу 10.
17. (Проверка окончания.) Если А имеет значение стоп, то в переменной [m, w], уже вычисленной на шаге 9 или 16, находится результат алгоритма. В этом случае окончить работу.
18. (Сохранение значения.) Значением А должен быть код сохранить (если это не так, завершить алгоритм по ошибке). Присвоить k значение k + 1 и поместить [qk + qk?1, w] в стек W. Это значение w, только что вычисленное на шаге 9 или 16. Теперь вернуться к шагу 3.
Комментарии к алгоритму Тоома—Кука
Мы почти не обосновывали и не объясняли алгоритм; вам придется кое в чем поверить на слово. Причина отсутствия объяснений кроется в том, что они крайне длинны и математичны, и у нас просто не хватило бы места. Изложение алгоритма в большой степени опирается на монографию Кнута; если вы хотите ознакомиться с алгоритмом подробнее, обратитесь к этой книге. Мы все же дадим некоторые комментарии, возможно способствующие лучшему пониманию.
1. (Структура алгоритма.) Наша версия алгоритма отличается от описанной у Кнута в основном структурой циклов. На рис. 22.1 представлена общая схема верхнего уровня алгоритма Тоома—Кука[32].
begin
long integer [n, u], [n, v];
integer K, Q, R, q [0: 10], r [0: 10];
long integer stack C, U, V, W;
control stack code;
integer k, p, s, t, i, j;
long integer X, Y, Z, w;
control A;
Шаг 1;
Шаг 2;
while code не пуст do
while k > 1 do
шаг 5; шаг 6; шаг 7; шаг 8;
end;
шаг 9;
pop code into A; while А = интерполировать do
шаг 11;
for i=1 to 2t do шаг 13;
for i=2t ? 1 downto 1 do шаг 15;
шаг 16;
end;
if A = стоп then return [m, w];
if A = сохранить then шаг 18; else abort;
end; * главного цикла *
end; * алгоритма Тоома—Кука *
Рисунок 22.1. Управляющая схема алгоритма Тоома—Кука.
2. (Таблицы размеров.) Значения массивов, вычисленные на шаге 2, показаны в табл. 22.1; число в колонке nk равно наибольшему числу битов, которое может быть обработано алгоритмом при K = k. Очевидно, что предельное значение 10 для K не является очень серьезным ограничением. При желании этот предел можно повысить.
Таблица 22.1. Значения q, r и n k qk rk nk 0 16 4 1 16 4 32 2 64 4 80 3 256 4 320 4 1024 8 1280 5 8192 8 9216 6 65536 16 73728 7 1048576 16 1114112 8 16777216 16 17825792 9 268435456 32 285212672 10 8589934592 32 88583700383. (Глубина стеков в первом цикле.) Максимальная глубина стеков U и V на шагах с 5-го по 8-й равна 2(rK?1 + 1). Глубина стека С может возрастать до
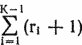 .
.
4. (Глубина стеков во втором цикле.) Общая глубина стека W может достигать
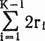 . Управляющий стек может достигать глубины
. Управляющий стек может достигать глубины
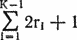 . На шагах 14, 15 и 16 верхняя часть стека W используется как массив. Этот массив может содержать максимум 2rk?1 + 2 элементов.
. На шагах 14, 15 и 16 верхняя часть стека W используется как массив. Этот массив может содержать максимум 2rk?1 + 2 элементов.
5. (Размер исходных данных.) Для любого числа битов n в диапазоне ni?1 + 1 ? n ? ni алгоритм Тоома—Кука требует одинакового времени вычислений. Таким образом, сложность вычислений весьма негладко зависит от размера исходных данных. Поэтому при выполнении длинных вычислений имеет смысл подбирать число битов вблизи верхнего конца одного из диапазонов для n. Учитывайте, что для представления одной десятичной цифры требуется примерно 3? бита.
6. (Как умножить два 32-разрядных числа?) На шаге 9 требуется умножить два 32-разрядных числа, получив 64-разрядное произведение, причем оба сомножителя обязательно положительны. На многих ЭВМ имеется аппаратная возможность такого умножения, но результат нельзя получить, пользуясь языками высокого уровня. Ну и, конечно, некоторые ЭВМ не имеют подобней аппаратуры. Поэтому для выполнения этого умножения нужно написать подпрограмму, причем она должна быть эффективной, поскольку время работы алгоритма определяется главным образом временем умножения 32-разрядных чисел. Вероятно, достаточно хорошим методом будет разбиение чисел на части и моделирование ручного способа умножения. Тем не менее если нужно получить произведение uv и число и записано в виде u1·216 + u0, a v — в виде v1·216 + v0, то произведением будет
(232 + 216)u1v1 + 216(u1 ? u0)(v0 ? v1) + (216 + 1)u0v0.
Вычисление по этой формуле выполняется при помощи только 16-битовых вычитаний и умножений, а также некоторых сдвигов и сложений. Обратите внимание, что одно умножение сэкономлено.
Что можно сказать относительно деления?
При вычислении предложенных рядов наряду с умножением используется деление чисел высокой точности. К счастью, при помощи алгоритма умножения удается выполнять деление почти так же быстро, как умножение. Для нахождения частного нужно приблизительно угадать число, обратное к делителю, скорректировать его, чтобы обратное стало точным, и затем умножить на делимое. Уточнение обратного осуществляется по методу Ньютона. Даны два числа [m, u] и [n, v]; мы считаем, что u ? v (хотя это предположение несущественно) и что n-й бит v равен 1 (т. е. у v нет старших нулей). Чем больше разница размеров и и v, тем более точным будет частное; разницу можно увеличить, умножая и на степень двойки. Отметим, что алгоритм деления будет неоднократно вызывать алгоритм умножения. Для нескольких первых из этих умножений можно воспользоваться обычной операцией умножения коротких чисел. Кроме того, все умножения и деления на степень двойки суть фактически сдвиги влево и вправо.
1. (Выбор размера обратного.) Найти наименьшее j, такое, что 2j ? max (m, 2n). Присвоить к значение 2j?1.
2. (Нормализация v.) Присвоить [k, v] значение 2k?n [n, v]. На этом шаге мы сдвигаем v влево, чтобы оно заняло k битов, причем левый бит был бы равен 1. Присвоить [2, а] значение [2, 2].
3. (Вычисление последовательных приближений к 1/v.) Выполнить шаг 4 для i = 1, 2, …, j ? 1.
4. (Вычисление приближения из 2i битов.) Присвоить [2i+1, d] значение
23·2i [2i?1 + 1, a] ? [2i?1 + 1, a]2 ([k, v]/2k?2i)
Деление в скобках (фактически сдвиг вправо) должно выполнятъся до умножения; идея состоит в том, чтобы ускорить умножение, отбросив лишние биты v, ненужные в данном приближения. Хотя кажется, что результат d может содержать больше 2i+1 битов, этого никогда не произойдет. Затем присвоить [2i + 1, а] значение [2i+1, d]/2i?1.
5. (Улучшение окончательной оценки.) Присвоить [3k, d] значение
22k[k + 1, а] ? [k + 1, а]2·[k, v].
Затем присвоить [k + 1, а] значение
([Зk, d] + 22k?2)/22k?1.
6. (Окончательное деление.) Выдать в качестве результата
([k + 1, a] · [m, u] + 2k+n?2)/22+k?1[33].
Как использовать алгоритмы?
Для нахождения ? надо будет провести вычисления по одной из формул, выписанных ранее в этом пункте, с использованием ряда для арктангенса. Фактически для страховки следует использовать две формулы и затем сравнить результаты бит за битом. Значением ? будет общая начальная часть этих двух результатов.
Все еще остается открытым вопрос, как с помощью алгоритмов, работающих только с целыми числами, получить очевидно дробные значения членов ряда. Пусть мы хотим вычислить я, скажем, с точностью 1000 битов. Вычислим тогда 21000?, умножив все числители на 21000. Эта процедура делает также все делимые много больше делителей (как предполагалось выше) и позволяет прекратить вычисления, когда частные станут нулевыми.
Выберем теперь (не обязательно наилучший) ряд для вычислений, скажем
? = 16 arctg(1/5) ? 4 arctg(1/239).
Мы фактически будем вычислять 21000?, поэтому хотелось бы вычислить 21000·16 arctg (1/5). Первым членом соответствующего ряда будет 21000·16/5; назовем его a1 (отметим, что a1 складывается с суммой). Теперь, чтобы получить следующий член ai+1 из ai, поделим a1 на 5·5·(2i ? 1)[34]. Если ai добавлялся к сумме, то вычтем ai+1 из суммы, если ai вычитался, прибавим ai+i. Будем поделим a1 на 5·5·(2i ? 1). Если ai добавлялся к сумме, то вычисления заканчиваются, когда члены обоих рядов станут нулевыми. В результате получим примерно тысячу битов числа ?. Результат, конечно, надо будет перевести в десятичную систему.
Тема. Составьте программы, реализующие описанные выше алгоритмы умножения и деления, и все необходимые им служебные подпрограммы. Используйте их для вычисления я с высокой точностью при помощи одного из выписанных рядов. Проследите, чтобы ваши программы не оказались слишком тесно привязаны к вычислению ?; библиотека программ для вычислений с высокой точностью может быть полезна и для других задач. Должна быть предусмотрена возможность увеличения точности счета без изменения программ, а лишь путем расширения памяти для результатов. Выходные данные должны включать статистику по использованию каждой программы, по числу выполнений каждого шага двух центральных алгоритмов и по использованию памяти. Сбор такой информации обойдется очень дешево в сравнении со всей работой.
Указания исполнителю. Этот этюд длинный и трудный. Не последнюю роль здесь играет то, что два центральных алгоритма нужно в какой-то степени принимать на веру. Однако, как это часто бывает в реальных задачах, главной проблемой является не кодирование программы, а выбор структур данных. Как представлять длинные числа? Обозначение [m, u] наводит на мысль, что всякое длинное число представляется парой аргументов длина и значение. Часть длина легко реализуется, но значение имеет, очевидно, переменную длину, и его трудно будет непосредственно хранить в памяти. Поэтому мы сделаем значение указателем на очень длинный вектор битов; тогда каждая пара будет иметь фиксированный размер. Однако имеющийся в нашем распоряжении вектор не настолько длинен, чтобы мы могли позволить себе использовать каждую его часть только по одному разу. Таким образом, нужна программа для сбора ненужной памяти. Сейчас мы фактически описали традиционную схему размещения цепочек.
Итак, в конечном итоге нам нужны кроме алгоритма умножения и деления следующие вспомогательные подпрограммы:
Выделение памяти. Получая величину длина в качестве аргумента, эта подпрограмма возвращает указатель в вектор битов, который может использоваться как значение. Начиная с бита, на который указывает значение, расположено длина битов, которые не будут использоваться ни для каких других целей.
Возврат памяти. Исходными данными для этой подпрограммы служит пара длина и значение. Связанная с ними память освобождается для повторного использования. Эту подпрограмму необходимо вызывать всякий раз, когда длина какой-либо переменной меняется.
Уплотнение памяти. Эта подпрограмма должна просмотреть всю используемую память и попытаться объединить неиспользуемые отрезки вектора битов в более длинные отрезки. Обычно подпрограмма уплотнения вызывается в тех случаях, когда подпрограмма выделения памяти не смогла найти достаточно длинную цепочку последовательных битов. Поскольку такая возможность может не потребоваться при решении коротких задач, эту подпрограмму можно запрограммировать позднее. Существует много способов хранения информации о неиспользуемой памяти.
Сдвиг. Исходными данными для подпрограммы служат длинное число и величина сдвига; результатом должно быть длинное число, сдвинутое вправо или влево на соответствующую величину. Эта операция отвечает умножению или делению на степень двойки.
Сложение. Исходными данными подпрограммы служат два длинных числа, а результатом должна быть их сумма в виде числа на один бит длиннее более длинного из операндов. Такое сложение можно выполнять так же, как вручную, двигаясь справа налево.
Вычитание. Эта подпрограмма аналогична подпрограмме сложения и выдает разность двух длинных чисел.
Подавление нулей. Исходными данными этой подпрограммы служит длинное число, а результатом должно быть более короткое длинное число, имеющее то же значение, но без старших нулей. Если окажется, что исходное число равно нулю, то результатом должно быть [1, 0].
Короткое умножение. Исходными данными служат два длинных числа длиной точно 32 бита; результатом должно быть их 64-разрядное произведение. Эту операцию можно выполнять справа налево, как в ручном методе.
Умножение длинного на короткое. Исходными данными служат длинное число и обычное число, по величине равное 64 или меньше; результатом должно быть их произведение в виде длинного числа. Эту операцию можно выполнять справа налево, как вручную.
Деление длинного на короткое. Исходными данными служат длинное число и обычное число, не превосходящее 64, а результатом должно быть длинное частное от деления длинного числа на короткое. Эту операцию можно выполнять слева направо, как это делается вручную.
Перевод. Исходными данными для этой подпрограммы является длинное число, а результатом должно быть то же число, записанное в десятичной системе на некотором устройстве вывода. При появлении потребности в более сложном выводе можно разработать более детальные спецификации подпрограммы перевода.
Инструментовка. В качестве языка реализации сразу же приходит на ум Паскаль: в этом языке хорошие структуры данных и управляющие структуры. Однако Паскаль не позволяет легко переводить внутреннее битовое представление в битовые цепочки, доступные программисту, и обратно. Языки более низкого уровня — BLISS и XPL — обеспечивают более прямой доступ к ЭВМ за счет некоторой потери выразительности и надежности. Хорошая защищенность языков высокого уровня и доступ к машинному представлению сочетаются в PL/I, но обычно за это приходится расплачиваться временем выполнения. Для данного этюда важно также время, которое вы потеряете, пытаясь постичь некоторые весьма изощренные возможности PL/I. Интересной представляется реализация на Траке, поскольку в этом случае автоматически решается задача распределения памяти для цепочек.
Длительность исполнения. Одному исполнителю на 5 недель или двум на 3 недели.
Развитие темы. Как только у нас появляется арифметика высокой точности, сразу же возникает много интересных задач. Одна из них — точное вычисление числа e. Ряд для e особенно прост:
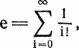
где 0! = 1. Любой студент, изучающий математический анализ, может придумать еще очень много рядов и констант.
* Партия переводчика. Можно существенно сократить как время работы программ, так и время их написания, если, не послушавшись автора, создать набор специализированных программ для вычисления ?. Анализируя ряд для ?, мы видим, что его вычисление требует всего двух программ высокой точности. Это программа сложения-вычитания длинных чисел (сложение и вычитание настолько похожи, что их можко рассматривать как одно действие) и программа деления длинного числа на короткое, т. е. на представимое в виде обычного целого числа. Эти действия, выполняемые классическими ручными методами, занимают лишь линейное по n время.
Кроме того, имеет смысл хранить длинные числа не в двоичной системе счисления, а в десятичной (конечно, не по одной цифре в элементе массива, а по столько цифр, сколько помещается в обычном целом числе). При этом отпадает необходимость в программе перевода. Теперь арифметические программы могут работать несколько медленнее (но вовсе не обязательно; далеко не все компиляторы используют команды сдвига для умножения и деления на степени двойки), тем не менее в целом можно получить выигрыш в скорости, поскольку время работы алгоритма перевода длинных чисел из двоичной системы в десятичную (описанного у Кнута) пропорционально n?, т. е. того же порядка, что и время всех остальных вычислений.
С помощью лишь этих программ сложения и деления можно вычислить многие математические константы: ?, e, ?2, ?2, ln 2 и т. д. Реализация такого усеченного варианта потребует, вероятно, не более одной человеко-недели. Сложные динамические структуры данных уже не потребуются; у нас будет всего два-три длинных числа известного размера, для представления которых вполне подойдут массивы Фортрана.
Литература
Ахо, Хопкрофт, Ульман (Aha А. V., Haperoft J. E., Ullman J. D.). The Design and Analysis of Computer Algorithms. Addison-Wesley, Reading, MA, 1974. Section 8.2, pp. 279–286. [Имеется перевод: Ахо А., Хопкрофт Дж., Ульман Дж. Построение и анализ вычислительных алгоритмов. — М.: Мир, 1979, § 8.2, с. 313–320.]
Мы почерпнули алгоритм умножения у Кнута, а алгоритм деления — у Ахо, Хопкрофта и Ульмана; оба алгоритма переработаны для наших целей Эти книги содержат подробную информацию по основам и детальный анализ алгоритмов, включая оценки сложности. Описываются также альтернативные алгоритмы умножения, основанные на быстром преобразовании Фурье[35].
Брент (Brent R. P.). A FORTRAN Multiple-Precision Arithmetic Package, Department of Computer Science, Carnegie-Mellon University, May 1976.
Брент описывает пакет подпрограмм для арифметических действий с высокой точностью, написанных на переносимом, машинно-независимом Фортране. Благодаря включенной в книгу библиографии, вы сможете найти другие работы в этой области. В пакете, предложенном Брентом, не используется алгоритм Тоома—Кука, и автор объясняет почему.
Брент (Brent R. P.). Fast Multiple-precision Evaluation of Elementary Functions, Stanford University, Technical Report STAN-CS-75-515, August 1975.
Томас (Thomas G. В., Jr.). Calculus and Analytic Geometry, 3rd ed. Addison-Wesley, Reading, MA, 1960. Section 16.3—3, pp. 809–812.
Томас приводит сведения по математическому анализу, необходимые для рассмотренных нами вычислений и подобных им; изложение в его книге простое и классическое. Рейтуиснер, а также Шенкс и Ренч — два примера из ряда работ по вычислению ?. В обеих работах дается некоторый исторический обзор, обе они используют подход, предлагаемый Томасом. Брент развивает совершенно новые методы вычисления функций sin, cos, log, arctg и т. д., основанные на эллиптических интегралах. Его алгоритмы работают значительно быстрее описанных нами рядов. Работа Брента пока существует в виде технического доклада.
Кнут (Knuth D. E.). The Art of Computer Programming/Seminumerical Algorithms, Addison-Wesley, Reading, MA, 1969. Section 4.3.3, pp. 258–280. [Имеется перевод: Кнут Д. Искусство программирования для ЭВМ. Т. 2. Получисленные алгоритмы. — М.: Мир, 1977, п. 4.3.3., стр. 314–340[36].]
Рейтуиснер (Reitwiesner G. W.). An ENIAC Determination of ? and e to More than 2000 Decimal Places, Mathematical Tables and Aids to Computation, 4, pp. 11–15, 1950.
Шенкс, Ренч (Shanks D., Wrench J. W.). Calculation of ? to 100 000 Decimals, Mathematics of Computation, 16, pp. 76–99, 1962.
* Кудрявцев Л. Д. Математический анализ. — М.: Высшая школа, 1973.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Дисковые системы высокой доступности
Дисковые системы высокой доступности Диски — это механические устройства, а механические устройства могут ломаться. Стандартная форма защиты для любой вычислительной системы — периодическое сохранение данных с дисков на другой носитель, обычно, ленту. Эта резервная
Управление точностью построения объектов
Управление точностью построения объектов На вкладке построений Drafting диалогового окна Options, показанной на рис. 3.10, можно сделать следующие назначения. Рис. 3.10. Диалоговое окно управления точностью построения объектов• В области AutoSnap Settings назначаются следующие параметры
R.4.3 Значения с плавающей точкой и двойной точностью
R.4.3 Значения с плавающей точкой и двойной точностью Для выражений типа float может использоваться арифметика с обычной точностью. Если значение с плавающей точкой меньшей точности преобразуется в значение типа float равной или большей точности, то изменения значения не
R.4.5 Арифметические преобразования
R.4.5 Арифметические преобразования Для большинства операций преобразования операндов и тип результата определяются одними и и теми же правилами. Это правило можно назвать "обычными арифметическими преобразованиями".Если один из операндов есть long double, другой операнд
3.4. Сравнение чисел с плавающей точкой с ограниченной точностью
3.4. Сравнение чисел с плавающей точкой с ограниченной точностью ПроблемаТребуется сравнить значения с плавающей точкой, но при этом выполнить сравнение на равенство, больше чем или меньше чем с ограниченным количеством десятичных знаков. Например, требуется, чтобы 3.33333 и
Арифметические развлечения
Арифметические развлечения Есть много примеров арифметических игр, головоломок и развлечений. Их можно найти в [BAL], [BER], [KUE]. Мы обращаемся и к другим источникам и добавляем некоторые задачи, которые представляют интерес собственно с точки зрения программирования. Многие
I. Арифметические операции
I. Арифметические операции + Прибавляет величину, находящуюся справа, к величине, стоящей слева - Вычитает величину, стоящую справа, из величины, указанной слева - Будучи унарной операцией, изменяет знак величины, стоящей справа * Умножает величину справа на величину,
Управление точностью построения объектов
Управление точностью построения объектов На вкладке построений Drafting диалогового окна Options, показанной на рис. 3.10, можно сделать следующие назначения. Рис. 3.10. Диалоговое окно управления точностью построения объектов• В области AutoSnap Settings назначаются следующие
Критерий хи-квадрат
Критерий хи-квадрат Представьте себе, что есть две монеты, над которыми поработал мошенник. Каким образом можно доказать, что монеты имеют смещенный центр тяжести? Конечно, наш предполагаемый мошенник мог быть достаточно глупым и просто сбалансировать монеты таким
Управление точностью построения объектов
Управление точностью построения объектов На вкладке построений Drafting диалогового окна Options, показанной на рис. 3.19, можно сделать следующие назначения. Рис. 3.19. Диалоговое окно управления точностью построения объектов• В области AutoSnap Settings назначаются следующие параметры
Арифметические операции
Арифметические операции К арифметическим относятся бинарные операции +, -, *, / для вещественных и целых чисел, бинарные операции div и mod для целых чисел и унарные операции + и - для вещественных и целых чисел. Тип выражения x op y, где op - знак бинарной операции +, - или *,
HD-CeBIT: В царстве высокой четкости
HD-CeBIT: В царстве высокой четкости Автор: Родион НасакинНD-экраны встречались в павильонах на каждом шагу. Дополняли картину видеокамеры, аудиотехника и множество других девайсов, производители которых пытались приобщиться, пожалуй, к самой значимой тенденции на рынке
Цифровые видеокамеры высокой чёткости Олег Нечай
Цифровые видеокамеры высокой чёткости Олег Нечай Опубликовано 18 августа 2011 года За последние два-три года видеотехника высокой чёткости стала доступной не только состоятельным кинолюбителям: недорогие жидкокристаллические и плазменные
54. Арифметические команды
54. Арифметические команды Такие команды работают с двумя типами:1) целыми двоичными числами, то есть с числами, закодированными в двоичной системе счисления.Десятичные числа – специальный вид представления числовой информации, в основу которого положен принцип