Голубятня: RSS как он должен быть Сергей Голубицкий
Голубятня: RSS как он должен быть
Сергей Голубицкий
Опубликовано 23 марта 2012 года
Сегодня пофилософствуем на одну из самых важных и горячих тем айтишной жизни: управление информационными потоками.
После перехода три с половиной года назад на Mac OS X мой подход к потреблению информации вынужденно изменился. Вынужденно, поскольку на платформе Надкусана элементарно не нашлось сторонних программ класса Website Watcher, которые бы позволяли отслеживать информацию в привычно-упорядоченном режиме.
Как это все выглядело на Windows? В программу было вбито около сотни линков на порталы, которые меня интересовали по самым различным темам — от компьютерного софта до философии и астрологии. Каждое утро Website Watcher соединялся с сайтами по списку, находил новое содержание, выделял его желтым цветом и услужливо представлял мне обновления в форме, удобной для глаза.
Я этот информационный поток перемалывал, разделяя на фракции: что-то — в мусорную корзину, что-то — на последующую углубленную проработку, что-то — просто откладывал до лучших времен. Натуральный алгоритм работы — почти дословно по Аллену.
На Маке аналога Website Watcher, как я уже отметил, не нашлось, поэтому я вынужденно перешел на агрегаторы RSS-потоков. Программ этого класса очень много, хотя до недавнего времени они поражали однообразием.
Благодаря энергичному развитию технологии Google Reader и ее универсальной поддержки во всех RSS-агрегаторах практически любая страница в интернете автоматически портировалась в программу, что превращало работу с информацией практически неотличимой от привычного алгоритма Website Watcher. Более того: там, где RSS-лента не форматировалась, на помощь приходил сервис page2rss.com, который превращал любой html-контент в RSS-канал.
Выше я сделал оговорку — «до недавнего времени». Не случайно: мои алгоритмы работы с информацией претерпели кардинальное переосмысление, что привело к очередному тупику. Из которого пока что я не вижу выхода, поскольку не знаю программ, способных соответствовать моим новым требованиям к сбору и обработке информации.
Поясню о чем идет речь — в надежде, что, может, кто из читателей что-то знает ценное и подскажет хотя бы направление, в котором следует искать. Главное изменение — отказ от этапа первичной переработки информационного шлака. Отказ вынужденный и продиктованный полным несоответствием старых алгоритмов моим текущим потребностям. Подозреваю, что дело не только во мне лично, а в объективных изменениях, таких как качественная интенсификация информационного потока и релятивизация информации.
Поясню, о чем речь. Технически моя работа раньше выглядела следующим образом: просматриваю полный поток новой информации, который отражается на RSS-ленте (или, как в Website Watcher, просто на порталах, которые я отслеживаю), и произвожу сортировку по вышеприведенному «алленовскому» алгоритму (в корзину, когда-нибудь, дальнейшее углублении темы).
В какой-то момент поймал себя на том, что перестал чисто физически справляться с нагрузкой. Информационный поток стал настолько интенсивен (вырос в разы!), что уже не только не хватает времени, но и руки опускаются, когда утром в RSS-агрегаторе красуются цифры 600, 400, 1380. Это количество обновившихся за день страниц на интересующих меня порталах!
И цифры эти совершенно нереальные! У меня просто нет времени перелопачивать этот ворох шлака, в котором, дай бог, найдется пяток-другой реально полезных и нужных мне информационных поводов.
В мой библиотеке iBooks аккуратно отформатированы, аннотированы, сопровождены метатагами и красивыми обложками 650 книжек — одна к одной! И все они дожидаются часа, когда их библиотекарь сподобится почитать хоть что-нибудь! А я не могу читать! Потому что у меня нет времени! Я работаю 15 часов 7 дней в неделю, давно превратившись в чукчу-писателя из анекдота.
Мне не только некогда читать, но и в сложившемся цейтноте подход к информации выработался абсолютно утилитарный: все, цепляет мой глаз, подлежит фильтрации по принципу «пригодится ли мне это в моей работе или не пригодится». Смогу использовать информацию в Голубятне? Замечательно — сохраняем! Смогу использовать в корпоративных биографиях для БЖ? Сохраняем? В НДС? Тоже. Остальное — в мусорную корзину! Потому что все равно — теперь я это с абсолютной ясностью осознаю — никогда уже в этой жизни у меня не будет ни времени, ни возможности вернуться к тому или иному информационному поводу, каким бы полезным для души и саморазвития он мне не казался.
Короче говоря, новый подход к переработке информации требует радикальной смены алгоритмов и — вместе с ними — компьютерных программ. И таких программ на рынке нет! По крайней мере я о них не знаю, отчего печалюсь несказанно.
В моем представлении хороший RSS-агрегатор как минимум должен обладать гибкой системой поиска. Гибкой системы нет вообще ни у одной программы: максимум на что приходится надеяться, так это на пошлую строку, куда вы можете что-то вбить в надежде получить ответ.
Вот лучший из лучших — NetNewsWire:
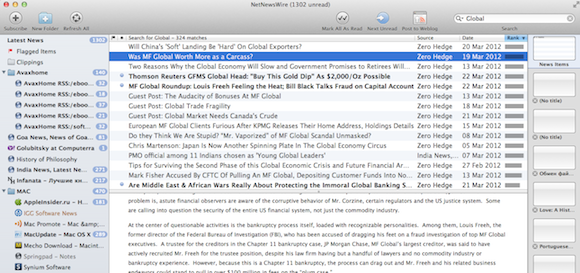
Задаю в поисковой строке «Global», получаю огромный список страниц, на которых ... нет даже цветовой подсветки найденного слова! Как прикажете работать?! Выковыривать ключевые слова глазами из текста, зачастую в несколько десятков тысяч знаков?!
И это, как я сказал, один из самых продвинутых RSS-агрегаторов для Мака! Он от того продвинутый, что радикально выпадает из мейнстримного тренда Apple, требующего предельной простоты интерфейса и функционала. Надкусан считает, что пользователь себя обманывает, когда ему кажется, что ему нужны все эти дополнительные опции и тонкие настройки! Нормальному человеку это на самом деле не нужно.
А что нужно? Нужно, чтобы было кошерно. А кошерно — это когда непременно Cocoa.
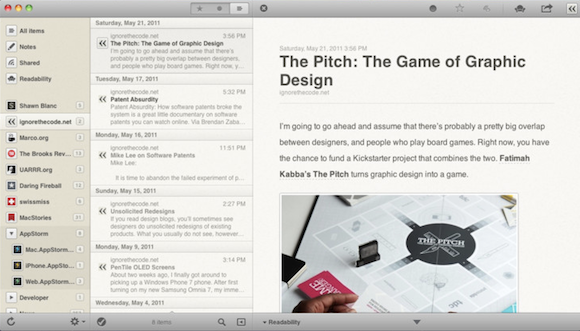
Перед нами самый популярный RSS-агрегатор для Mac OS X — свежий любимец публики под названием Reader (чего стоит одно это наглое название с претензией на конечную инстанцию стиля и функционала!) Все, что вы видите на скриншоте, полностью исчерпывает возможности этой программы, которая раскупается в App Store как горячие пирожки! Почитайте отзывы — все как один восторженные и взахлеб: лучший из лучший! Есть все, что мне надо!
Инфузории, чесслово! В Reader нет вообще никакого поиска по RSS-каналам! Вообще никакого! Это не программа, а грубое оскорбление умственных возможностей людей, сидящих за компьютерами. Когда я установил Reader в первый раз, то глазам своим не поверил: подумал, наверное какой-то подвох, ну не могут же люди так искренне радоваться такому говну?! Нужно докопаться до истины.
Я копался целых три месяца, но так и не сумел увидеть в фаворите никакого кошера кроме Cocoa! Под конец сдался, сказал себе — простите, но это не мое, и удалил программу к чертовой матери, вернувшись к уродливому, безнадежно устаревшему, не кошерному, но обладающему хоть рудиментарной функциональностью NetNewsWire.
Какой же должна быть программа, соответствующая самым современным требованиями к обработке информационных потоков в эпоху предельной их интенсификации? Скромно, все же, надеюсь, что мои нужды не эксклюзивны и отражают какие-то объективные тенденции в дата-майнинге, а посему позволю себе обобщения.
Требований, собственно, не много:
1) Никакого шлакового информационного потока! Задача решается установкой первичных фильтров на входе, которые пользователь изначально кастомизирует, а затем периодически подвергает перенастройке. Иными словами, информационный поток очищается от всего лишнего и на монитор подается только та информация, которая определяется пользователем как релевантная для его нужд;
2) Непременное использование Push-технологии, которая бы «подавала» информацию пользователю либо по мере ее поступления, либо в четко указанные сроки (периоды);
3) Функциональный акцент должен делаться на поисковые возможности программы. Речь не об убогой строке поиска, а о полноценном поисковом интерфейсе, булеанах, возможности задавать дополнительные условия поиска, анализе what if и прочих элементах серьезного дата-майнинга.
Ничего подобного даже рядом не существует на Mac OS X и, боюсь, не существует сегодня и для Windows (поправьте, если ошибаюсь — буду несказанно благодарен!).
Единственное, что удалось обнаружить, и что вселяет надежду, поскольку появляется шанс расширить технологию и на другие платформы, так это программа Push Reader, которая создана для айфона:
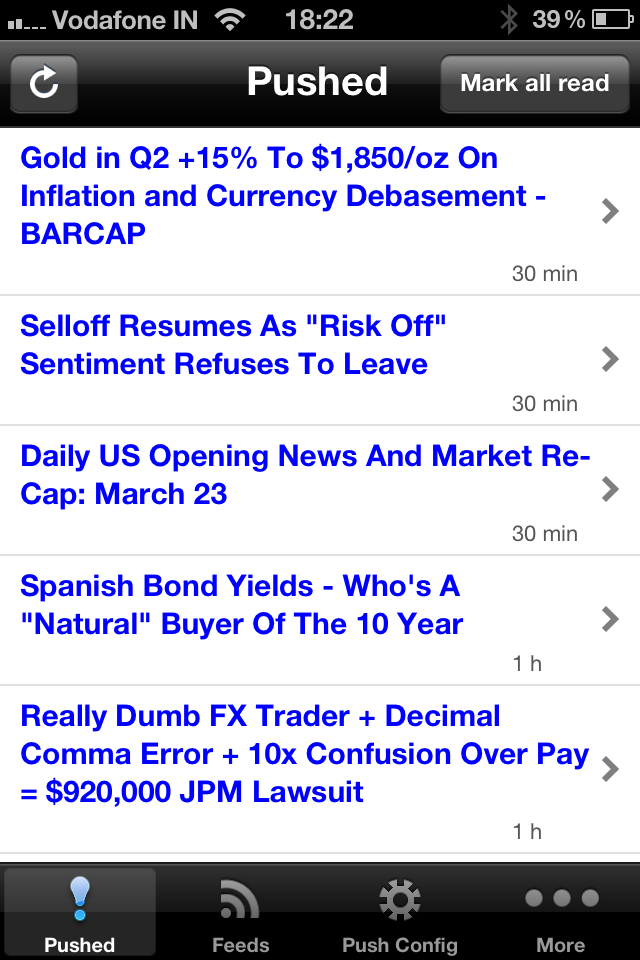
С заданной регулярностью программа соединяется с отслеживаемыми сайтами и принудительно доставляет нужный вам контент, оставляя уведомления в информационном центре iOS. Нужны контент хоть и предельно примитивно, но задается с помощью ключевых слов по каждой RSS-ленте:
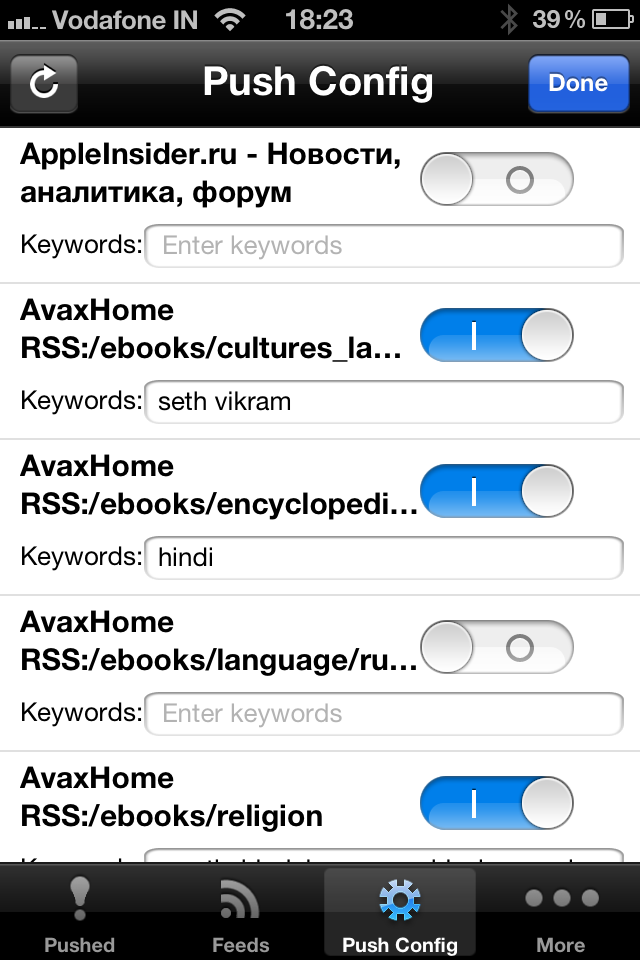
Все это бесконечно зачаточно и убого, но хоть как-то уже напоминает алгоритмы будущего. Именно в этом направлении следует работать программистам, чтобы соответствовать требованиям времени в плане работы с информацией.
Господа гики, даю очередную наводку на золотую жилу (а я таких за 13 лет существования Голубятен, уж поверьте, дал не мало!): напишите полноценную программу для Windows и Mac OS X, которая позволяет автоматизировать переработку информационного шлака! И вы на годы вперед обеспечите себя и своих детей. Не говоря о том, что осчастливите тысячи пользователей, которые томятся под гнетом убогих софтверных решений, существующих на рынке.
Ну а пока что, за неимением лучшего, вынужденно перевел удовлетворение информационного голода на айфон, потому как Push Reader даже не поддерживает разрешение планшета и на айпаде работает в позорном окошке! Остается только надеяться, что мучения мои временные.
К оглавлению
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
2.7. Что такое кластер, и какого размера он должен быть?
2.7. Что такое кластер, и какого размера он должен быть? Кластер - минимальный размер места на диске, которое может быть выделено файловой системой для хранения одного файла. Определяется он, как правило, автоматически, при форматировании винчестера, по зависимости
Каким должен быть ваш корпоративный Твиттер. Форма
Каким должен быть ваш корпоративный Твиттер. Форма Сайт, внешний вид аккаунта, блога, ваше мобильное приложение нельзя свести только к текстам, которые там размещены. Это сумма визуальных и смысловых компонентов, которые воспринимаются целиком, не разбиваясь на
13-Я КОМНАТА: Каким должен быть читатель
13-Я КОМНАТА: Каким должен быть читатель Автор: Леонид Левкович-МаслюкМы в редакции часто спорим: что именно интересует наших читателей в журнале? Вспомнив сейчас эти обсуждения, я понял, что мы упускаем из виду широко известный принцип: читателя больше всего интересует то,
Голубятня: Ась? Сергей Голубицкий
Голубятня: Ась? Сергей Голубицкий Опубликовано 12 октября 2010 года Читатели со стажем не дадут соврать: о системах распознания речи (VRS, Voice Recognition Systems) я писал регулярно, начиная с самой первой статьи, опубликованной в бумажной «Компьютерре» аж в 1996
Голубятня: I Am You Сергей Голубицкий
Голубятня: I Am You Сергей Голубицкий Праздник «Холи» возбудил не только гоанцев, но и всю творчески активную тусовку европейского десанта. Надо сказать, что в Гоа постоянно проживает значительное количество музыкантов, художников, поэтов и танцоров, которые работают, не
Голубятня: PX Сергей Голубицкий
Голубятня: PX Сергей Голубицкий На следующей неделе у меня будет большая съемка в передаче «Крипто» («Совершенно секретно»), посвященной «Филадельфийскому эксперименту». Казалось бы — ну что еще можно высосать интересного из этого замшелого сюжета в наши
Голубятня: Just 5 Сергей Голубицкий
Голубятня: Just 5 Сергей Голубицкий Опубликовано 12 января 2011 года Продолжаем новогодний видео марафон. Сегодня вертим в руках телефоны второго поколения от Just 5. В видео клипе я назвал сотрудников этой удачливой компании «нашими соотечественниками»
Глава 1 Каким должен быть компьютер
Глава 1 Каким должен быть компьютер • Немного о компьютере• Типичные конфигурации
Голубятня: Out-of-the-box Сергей Голубицкий
Голубятня: Out-of-the-box Сергей Голубицкий Опубликовано 24 августа 2010 года Концепция out-of-the-box хорошо известна шозистам мира, хотя и не особо принята в нашем айтишном королевстве. Смысл концепции прост: распаковал коробку, достал и сразу же начал
Голубятня: Сергей Комаров Сергей Голубицкий
Голубятня: Сергей Комаров Сергей Голубицкий Опубликовано 15 июля 2010 года Очередной микроюбилей — 200 публикация «Голубятни Онлайн». Вспоминаю бумажные «Голубятню 100», «Голубятню 200», «Голубятню 300», «Голубятню 400»! Надеялся дожить до совсем уж
Голубятня: АК-47 Сергей Голубицкий
Голубятня: АК-47 Сергей Голубицкий Опубликовано 16 июня 2010 года Пауза, вызванная традиционным летним анабазисом на юга, затянулась, поэтому беру стахановские обязательства: до конца месяца выдавать посты в удвоенном ритме! Тем более, что совсем без
Голубятня: КГ/АМ Сергей Голубицкий
Голубятня: КГ/АМ Сергей Голубицкий Опубликовано 26 марта 2012 года Повидло у меня сегодня слегка не первой свежести, но не беда: сладкий продукт не тухнет :) Тем более, что хочу предложить читателям довольно непривычный аспект хорошо знакомой
Объект съемки не должен быть слишком мелким
Объект съемки не должен быть слишком мелким Перед тем как сделать снимок, постарайтесь оптимально заполнить поле кадра. Посмотрите, как он скомпонован. Не торопитесь, лучше оцените, насколько объект съемки заполняет кадр. Когда вы фотографируете человека, старайтесь,
Горизонт должен быть ровным
Горизонт должен быть ровным Снимая пейзажи (или портреты на фоне пейзажа), старайтесь обращать внимание на горизонт. Уделяя все внимание модели или другому объекту съемки, вы можете забыть о ровном положении камеры, и горизонт «упадет» (рис. 13.11). Для полного контроля над
Голубятня: RSS как он должен быть
Голубятня: RSS как он должен быть Автор: Сергей ГолубицкийОпубликовано 23 марта 2012 годаСегодня пофилософствуем на одну из самых важных и горячих тем айтишной жизни: управление информационными потоками. После перехода три с половиной года назад на Mac OS X мой подход к