СОФТЕРРА: Три вопроса
СОФТЕРРА: Три вопроса
Автор: Константин Курбатов
К концу лета возвращаются домой с каникул/из отпусков стайки студентов, белых воротничков и редакторов еженедельных журналов. И пока студенты пытаются вспомнить имена преподавателей, а белые воротнички лихорадочно восстанавливают навыки скоростного набора текста и игры в пасьянс, редакторы еженедельных журналов вдруг обнаруживают новые версии программного обеспечения, требующие немедленного обзора…
Как известно, формат PDF замечателен тем, что на любом компьютере вы видите оформление текста именно таким, каким его задумывал создатель файла. Беда в том, что нередко мы бы желали, чтобы файл был задуман в формате Word, в крайнем случае Excel, а некоторые любители изящной словесности предпочли бы TXT.
Кто виноват?
Для разрешения этого экзистенциального противоречия компания ABBYY выпустила уже вторую версию своей утилиты PDF Transformer. Но кому нужна утилита для конвертирования файлов из PDF в текстовый формат, когда прямо в Acrobat Reader можно выделить текст и перенести его в любую программу через буфер обмена?
На самом деле загвоздка бывает с теми файлами, в которых нет никакого текста. Точнее, текст в них представлен в виде растрового изображения, и поэтому желание «ткнуть сюда мышкой» и скопировать кулинарный рецепт в «аську» обычно встречает угрюмое непонимание «Акробата». И тут наш преобразователь, поигрывая мускулами своего старшего брата [Или, наверное, дяди?] FineReader’а, такой текст с легкостью распознает (37 языков, включая, разумеется, албанский) и помещает в итоговый DOC-, RTF-, XLS-, TXT-, HTML-… или опять в PDF-файл, но уже с текстовым слоем [Так называемый Searchable PDF, который может быть проиндексирован поисковиком, а текст из него можно копировать обычным образом через буфер обмена].
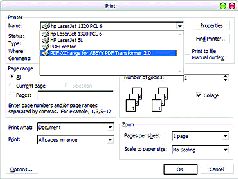
Кроме того, в новой версии появился «виртуальный PDF-принтер» (рис. 1), благодаря которому счастливые пользователи получили возможность создавать свои собственные непригодные для редактирования документы.
Кому это выгодно?
Как ни странно, возможность «печатать» в PDF оказалась очень удобной для записи на диск нужных веб-страниц. Все ссылки с них сохраняются и продолжают работать [Кстати, это верно и наоборот: ссылки из PDF переходят в итоговый документ, включая сноски и оглавление]. А возможность за пару кликов отправить этот файл по электронной почте, вообще удивительно удобная штука - белые воротнички, лишенные http-доступа на работе, будут вам безмерно благодарны. Кстати, размер такого файла можно регулировать за счет качества сохраняемых картинок, поэтому веб-страницы с многомегабайтными картинками легко можно уложить в 3-4-мегабайтный PDF. Еще одно применение - распознавание документов, хранящихся в виде обычных сканов (например, тексты патентов в Интернете), - вы просто «печатаете» их в PDF, а затем конвертируете его в доступный для редактирования формат (RTF, HTML), причем вместе со всеми прилагающимися схемками и иллюстрациями.
Что делать?
Я попробовал распознать и перевести в HTML-форму один из недавних материалов нашего журнала, для того чтобы его можно было выложить на сайт. Подписи к иллюстрациям достаточно красноречивы, но хотелось бы сделать несколько замечаний.

Во-первых, разрывы колонок воспринимаются программой как разрывы абзацев, поэтому если между ними был перенос слова, его надо вручную корректировать. Во-вторых, обрабатывая сложно сверстанный PDF-файл, программа постоянно ошибалась при автоматическом выборе порядка следования текстовых блоков, в результате многоколоночный текст с иллюстрациями сильно перемешивался. И это одна из главных причин, почему в новой версии появился интерфейс, в котором можно управлять разбиением на блоки. В-третьих, часто диаграммы определяются как таблицы из-за регулярных фоновых квадратиков, и в этом случае ручной режим просто необходим (рис. 3). И наконец, не могу не сказать о хорошем качестве распознавания на пестром разноцветном фоне. Не претендуя на объективность оценки, я тем не менее должен отметить практически полное отсутствие ошибок (рис. 2).

Итак, за 1490 рублей пользователь получает немало дополнительных функций, которые полностью оправдывают удорожание программы (за первую версию просили 830 рублей) [Любопытно, что лицензия позволяет установить программу на два компьютера - домашний и, например, ваш мобильный или рабочий].
А вот на вопрос, действительно ли это вам нужно, я предлагаю ответить самостоятельно…
Что нового?
Точное сохранение оформления документа
Это не новшество, то же самое делала и первая версия. Но теперь у программы появился некий интерфейс, который можно вызвать, если выбрать «конвертировать, используя пользовательские настройки». В этом случае пред вашим взором предстанет чудное окошко (рис. 4), где в левой части можно видеть странички PDF-файла, а в правой - «куда ставить-то», то есть формат, параметры конвертации и папку для итогового файла. Вся прелесть этого режима в том, что можно не только собственноручно выбирать области распознавания (выбрасывая, например, колонтитулы) и их тип [Это особенно важно для выбора таблица/картинка, так как некоторые картинки с регулярными прямоугольниками (графики) программа объявляет таблицей], но и порядок распознавания блоков (рис. 5), что особенно помогает, когда файл представляет собой сложный многоколоночный текст.
Варианты сохранения оформления документов
Так как появилась возможность манипулировать блоками, разработчики реализовали некоторые характерные сценарии преобразования в виде отдельных опций. При сохранении в формате Microsoft Excel можно, например, выбрать «Игнорировать текст вне таблицы», и тогда будет конвертирована только информация из блоков-таблиц. Это особенно полезно, если, скажем, нужно преобразовать в Excel PDF-прайс-лист какой-нибудь компании без логотипов и печатей.

Интеллектуальное преобразование PDF-файлов
Очень необычное, но важное нововведение. Некоторые сетевые сканеры со встроенными системами распознавания текста создают так называемые Searchable PDF. В нем имеется дополнительный невидимый слой, в который помещается распознанный текст. Если программа находит такой слой, то она чаще всего использует его, не тратя время на процесс распознавания. С другой стороны, содержимое этого слоя не всегда соответствует оригиналу, особенно если он содержит фрагменты на языках, не поддерживаемых OCR сканера. «Трансформер» проводит экспресс-анализ и для каждого абзаца принимает решение: извлечь текст из невидимого слоя или распознать изображение и получить текст заново.

Преобразование PDF-файлов с нестандартными шрифтами
Если в свойствах PDF-файла указаны нестандартные шрифты, то при «вытягивании» текста обычным образом вы получите «кракозябры» вместо букв. Для решения этой проблемы во второй версии появилась галочка «конвертировать как изображение» (рис. 6), что позволяет заново распознать весь текст даже в необычных шрифтах. В итоге вы получите распознанный текст в наиболее похожем стандартном шрифте Windows…
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Естественная постановка вопроса
Естественная постановка вопроса Ссылки с бирж – это огромный наемный легион, который способен обеспечить рывок в топ. Однако в SEO — армии нужны и верные боевые части, остающиеся с полководцем надолго без преобладания корыстных мотивов. Это естественные ссылки. Как они
Два ключевых вопроса владельцу интернет-магазина
Два ключевых вопроса владельцу интернет-магазина Появляется закономерный вопрос: зачем делать самые низкие цены, если их нереально найти и по ним покупают самые проблемные клиенты?Второй, не менее важный вопрос: если в итоге с самой низкой ценой может оказаться только
СОФТЕРРА: Софтерра
СОФТЕРРА: Софтерра Автор: Илья ШпаньковСкромный счетовод ОС WindowsАдрес mironovlab.ruВерсия 10.5Размер 1,2 МбайтИнтерфейс русскийЦена 250 рублейОзнакомительный период 25 запусковПрограмма StatistXP пригодится там, куда еще не добралось чудо коммуникационных технологий под названием
СОФТЕРРА: Софтерринки
СОФТЕРРА: Софтерринки Автор: Илья ШпаньковРазведка не дремлет ОС Windows, DOSАдрес www.astra32.com/ruВерсия 1.52Размер 1,3 МбайтИнтерфейс многоязычный (русский поддерживается)Цена 400 рублейДемонстрационная версия обладает функциональными ограничениямиКак правило, подробные данные о
СОФТЕРРА: Софтерринки
СОФТЕРРА: Софтерринки Автор: Илья ШпаньковДомашний финансист ОС Windows, Linux+WineАдрес www.mechcad.netВерсия 3.9.2Размер 1,7 МбайтИнтерфейс многоязычный (русский поддерживается)Цена 300 рублейОзнакомительный период 30 днейПока человечество не придумало ничего лучше денег, спрос на
СОФТЕРРА: Софтерринки
СОФТЕРРА: Софтерринки Автор: Илья ШпаньковКонцентрируй это ОС WindowsАдрес www.infortech.ru/products/fclientВерсия 3.119.63.1Размер 3,4 МбайтИнтерфейс русскийЦена 354 руб.Ознакомительный период 30 днейИнтернет просто трещит по швам от обилия новостных рассылок, блогов, форумов и прочего
СОФТЕРРА: Веб-софтинки
СОФТЕРРА: Веб-софтинки Автор: Илья ШпаньковФоторедактор для браузера Адрес pixenate.comИнтерфейс английский, испанскийБраузеры Firefox, Safari, MSIE 6.0+Графический редактор PXN8 (Pixenate), несмотря на свою "привязанность" к Интернету, обладает неплохим набором инструментов редактирования
СОФТЕРРА: Софтерринки
СОФТЕРРА: Софтерринки Автор: Илья ШпаньковДыроискатель ОС WindowsАдрес www pspl comВерсия 1.10Размер 976 КбайтИнтерфейс английский (русский не поддерживается)Цена бесплатноЛицензия проприетарная (freeware)Да, в Windows хватает опасных уязвимостей, однако самостоятельный поиск и латание
Цена вопроса Автор: Роман Косячков.
Цена вопроса Автор: Роман Косячков. © 2004, Издательский дом | http://www.computerra.ru/Журнал «Домашний компьютер» | http://dk.compulenta.ru/Этот материал Вы всегда сможете найти по его постоянному адресу: /2006/121/280082/Лучшие умы, участвующие в игре под названием «бизнес», концентрируют свои усилия
СОФТЕРРА: Софтерринки
СОФТЕРРА: Софтерринки Автор: Илья ШпаньковСредство от беспамятства ОС WindowsАдрес www.roboform.com/ruВерсия 6.8.9Размер 2,5 МбайтИнтерфейс многоязычный (русский поддерживается)Цена бесплатноЛицензия проприетарная (freeware)Надежное сохранение паролей — дело хлопотное, а особенно,
СОФТЕРРА: Софтерринки
СОФТЕРРА: Софтерринки Автор: Илья ШпаньковПоиск двойников ОС WindowsАдрес www.bolidesoft.com/imagecomparer.html Версия 3.1Размер 2,8 МбайтИнтерфейс многоязычный (русский не поддерживается)Цена $29,95Ознакомительный период 30 днейПри работе с крупными коллекциями цифровых фотографий
софтерра: Webология
софтерра: Webология Автор: Илья ШпаньковТворческий беспорядок Адрес stixy.comИнтерфейс английскийкириллица поддерживаетсяСпору нет, стикеры - штука удобная. Создатели ресурса Stixy решили перенести это изобретение в онлайн, попутно усовершенствовав полезную идею. На
ТЕМА НОМЕРА: Цена вопроса
ТЕМА НОМЕРА: Цена вопроса Автор: Илья Щуров VoyagerСтоя у окна в сараеподобном аэропорту небольшого чешского городка Пардубице и глядя в хвост улетающему в Москву самолету, я думал о цене ошибки ввода-вывода. Чтобы опоздать на рейс, достаточно было неправильно прочитать
СОФТЕРРА: Weboлогия
СОФТЕРРА: Weboлогия Автор: Яков ШпунтДетки в поиске Адрес kids.quintura.com Интерфейс английский (русский не поддерживается)кириллица не поддерживается При всех своих достоинствах Интернет полон сайтов, которые могут искалечить детскую психику. Поэтому одной из забот