Совет 15. Помните о различиях в реализации string
Совет 15. Помните о различиях в реализации string
Бьерн Страуструп однажды написал статью с интригующим названием «Sixteen Ways to Stack a Cat» [27], в которой были представлены разные варианты реализации стеков. Оказывается, по количеству возможных реализаций контейнеры string не уступают стекам. Конечно, нам, опытным и квалифицированным программистам, положено презирать «подробности реализации», но если Эйнштейн был прав, и Бог действительно проявляется в мелочах... Даже если подробности действительно несущественны, в них все же желательно разбираться. Только тогда можно быть полностью уверенным в том, что они действительно несущественны.
Например, сколько памяти занимает объект string? Иначе говоря, чему равен результат sizeof(string)? Ответ на этот вопрос может быть весьма важным, особенно если вы внимательно следите за расходами памяти и думаете о замене низкоуровневого указателя char* объектом string.
Оказывается, результат sizeof (string) неоднозначен — и если вы действительно следите за расходами памяти, вряд ли этот ответ вас устроит. Хотя у некоторых реализаций контейнер string по размеру совпадает с char*, так же часто встречаются реализации, у которой string занимает в семь раз больше памяти. Чем объясняются подобные различия? Чтобы понять это, необходимо знать, какие данные и каким образом будут храниться в объекте string.
Практически каждая реализация string хранит следующую информацию:
•размер строки, то есть количество символов;
•емкость блока памяти, содержащего символы строки (различия между размером и емкостью описаны в совете 14);
•содержимое строки, то есть символы, непосредственно входящие в строку. Кроме того, в контейнере string может храниться:
•копия распределителя памяти. В совете 10 рассказано, почему это поле не является обязательным. Там же описаны странные правила, по которым работают распределители памяти.
Реализации string, основанные на подсчете ссылок, также содержат:
•счетчик ссылок для текущего содержимого.
В разных реализациях string эти данные хранятся по-разному. Для наглядности мы рассмотрим структуры данных, используемые в четырех вариантах реализации string. В выборе нет ничего особенного, все варианты позаимствованы из широко распространенных реализаций STL. Просто они оказались первыми, попавшимися мне на глаза.
В реализации А каждый объект string содержит копию своего распределителя памяти, размер строки, ее емкость и указатель на динамически выделенный буфер со счетчиком ссылок (RefCnt) и содержимым строки. В этом варианте объект string, использующий стандартный распределитель памяти, занимает в четыре раза больше памяти по сравнению с указателем. При использовании нестандартного указателя объект string увеличится на размер объекта распределителя.

В реализации В объекты string по размерам не отличаются от указателей, поскольку они содержат указатель на структуру. При этом также предполагается использование стандартного распределителя памяти. Как и в реализации А, при использовании нестандартного распределителя размер объекта string увеличивается на размер объекта распределителя. Благодаря оптимизации, присутствующей в этом варианте, но не предусмотренной в варианте А, использование стандартного распределителя обходится без затрат памяти.
В объекте, на который ссылается указатель, хранится размер строки, емкость и счетчик ссылок, а также указатель на динамически выделенный буфер с текущим содержимым строки. Здесь же хранятся дополнительные данные, относящиеся к синхронизации доступа в многопоточных системах. К нашей теме они не относятся, поэтому на рисунке соответствующая часть структуры данных обозначена «Прочее».
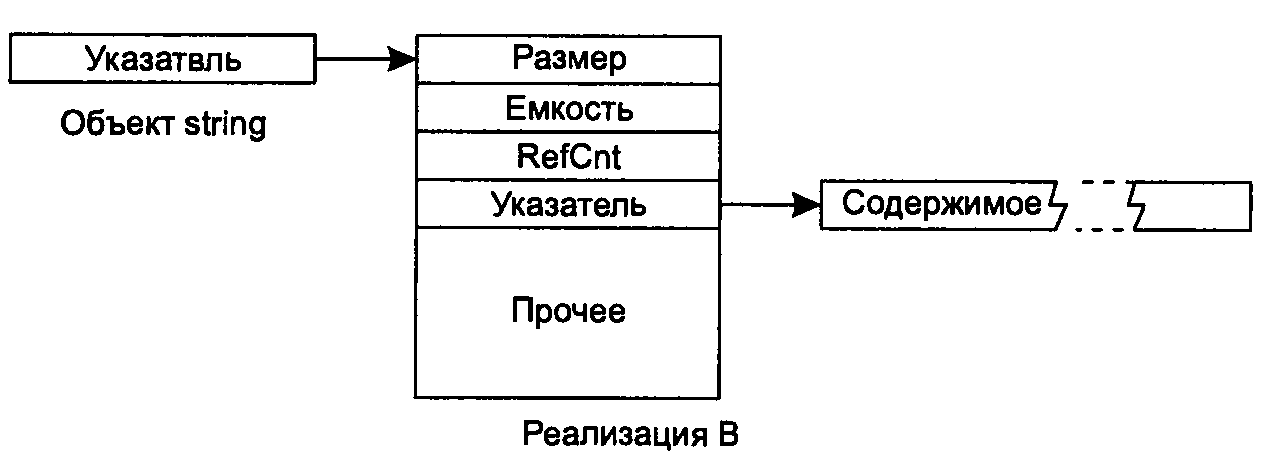
Блок «Прочее» оказался больше остальных блоков, поскольку я постарался выдержать масштаб изображения. Если один блок вдвое больше другого, значит, он занимает вдвое больше памяти. В реализации В размер данных синхронизации примерно в шесть раз превышает размер указателя.
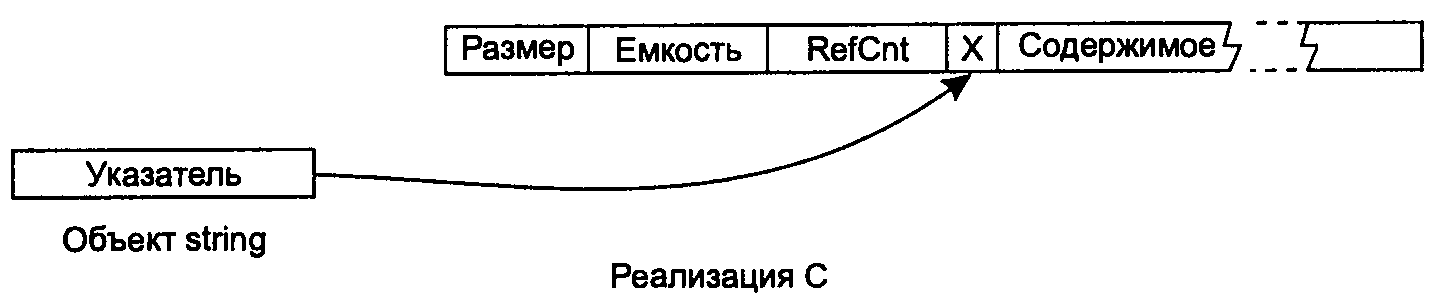
В реализации С размер объекта string всегда равен размеру указателя, но этот указатель всегда ссылается на динамически выделенный буфер, содержащий все данные строки: размер, емкость, счетчик ссылок и текущее содержимое. Распределители уровня объекта не поддерживаются. В буфере также хранятся данные, описывающие возможности совместного доступа к содержимому; эта тема здесь не рассматривается, поэтому соответствующий блок на рисунке помечен буквой «X» (если вас интересует, зачем может потребоваться ограничение доступа к данным с подсчетом ссылок, обратитесь к совету 29 «More Effective С++»).
В реализации D объекты string занимают в семь раз больше памяти, чем указатель (при использовании стандартного распределителя памяти). В этой реализации подсчет ссылок не используется, но каждый объект string содержит внутренний буфер, в котором могут храниться до 15 символов. Таким образом, небольшие строки хранятся непосредственно в объекте string — данная возможность иногда называется «оптимизацией малых строк». Если емкость строки превышает 15 символов, в начале буфера хранится указатель на динамически выделенный блок памяти, в котором содержатся символы строки.

Я поместил здесь эти диаграммы совсем не для того, чтобы убедить читателя в своем умении читать исходные тексты и рисовать красивые картинки. По ним также можно сделать вывод, что создание объекта string командами вида
string s("Perse"); // Имя нашей собаки - Персефона, но мы
// обычно зовем ее просто "Перси"
в реализации D обходится без динамического выделения памяти, обходится одним выделением в реализациях А и С и двумя — в реализации В (для объекта, на который ссылается указатель string, и для символьного буфера, на который ссылается указатель в этом объекте). Если для вас существенно количество операций выделения/освобождения или затраты памяти, часто связанные с этими операциями, от реализации В лучше держаться подальше. С другой стороны, наличие специальной поддержки синхронизации доступа в реализации В может привести к тому, что эта реализация подойдет для ваших целей лучше, чем реализации А и С, а количество динамических выделений памяти уйдет на второй план. Реализация D не требует специальной поддержки многопоточности, поскольку в ней не используется подсчет ссылок. За дополнительной информацией о связи между многопоточностью и строками с подсчетом ссылок обращайтесь к совету 13. Типичная поддержка многопоточности в контейнерах STL описана в совете 12.
В архитектуре, основанной на подсчете ссылок, все данные, находящиеся за пределами объекта string, могут совместно использоваться разными объектами string (имеющими одинаковое содержимое), поэтому из приведенных диаграмм также можно сделать вывод, что реализация А обладает меньшими возможностями для совместного использования данных. В частности, реализации В и С допускают совместное использование данных размера и емкости объекта, что приводит к потенциальному уменьшению затрат на хранение этих данных на уровне объекта. Интересно и другое: отсутствие поддержки распределителей уровня объекта в реализации С означает, что это единственная реализация с возможностью использования общих распределителей: все объекты string должны работать с одним распределителем! (За информацией о принципах работы распределителей обращайтесь к совету 10.) Реализация D не позволяет совместно использовать данные в объектах string.
Один из интересных аспектов поведения string, не следующий непосредственно из этих диаграмм, относится к стратегии выделения памяти для малых строк. В некоторых реализациях устанавливается минимальный размер выделяемого блока памяти; к их числу принадлежат реализации А, С и D. Вернемся к команде
string s ("Perse"); // Строка s состоит из 5 символов
В реализации А минимальный размер выделяемого буфера равен 32 символам. Таким образом, хотя размер s во всех реализациях равен 5 символам, емкость этого контейнера в реализации А равна 31 (видимо, 32-й символ зарезервирован для завершающего нуль-символа, упрощающего реализацию функции c_str). В реализации С также установлен минимальный размер буфера, равный 16, при этом место для завершающего нуль-символа не резервируется, поэтому в реализации С емкость s равна 16. Минимальный размер буфера в реализации D также равен 16, но с резервированием места для завершающего нуль-символа. Принципиальное отличие реализации D заключается в том, что содержимое строк емкостью менее 16 символов хранится в самом объекте string. Реализация В не имеет ограничений на минимальный размер выделяемого блока, и в ней емкость s равна 7. (Почему не 6 или 5? Не знаю. Простите, я не настолько внимательно анализировал исходные тексты.)
Из сказанного очевидно следует, что стратегия выделения памяти для малых строк может сыграть важную роль, если вы собираетесь работать с большим количеством коротких строк и (1) в вашей рабочей среде не хватает памяти или (2) вы стремитесь по возможности локализовать ссылки и пытаетесь сгруппировать строки в минимальном количестве страниц памяти.
Конечно, в выборе реализации string разработчик обладает большей степенью свободы, чем кажется на первый взгляд, причем эта свобода используется разными способами. Ниже перечислены ишь некоторые переменные факторы.
• По отношению к содержимому string может использоваться (или не использоваться) подсчет ссылок. По умолчанию во многих реализациях подсчет ссылок включен, но обычно предоставляется возможность его отключения (как правило, при помощи препроцессорного макроса). В совете 13 приведен пример специфической ситуации, когда может потребоваться отключение подсчета ссылок, но такая необходимость может возникнуть и по другим причинам. Например, подсчет ссылок экономит время лишь при частом копировании строк. Если в приложении строки копируются редко, затраты на подсчет ссылок не оправдываются.
•Объекты string занимают в 1-7 (по меньшей мере) раз больше памяти, чем указатели char*.
•Создание нового объекта string может потребовать нуля, одной или двух операций динамического выделения памяти.
•Объекты string могут совместно использовать данные о размере и емкости строки.
•Объекты string могут поддерживать (или не поддерживать) распределители памяти уровня объекта.
•В разных реализациях могут использоваться разные стратегии ограничения размеров выделяемого блока.
Только не поймите меня превратно. Я считаю, что контейнер string является одним из важнейших компонентов стандартной библиотеки и рекомендую использовать его как можно чаще. Например, совет 13 посвящен возможности использования string вместо динамических символьных массивов. Но для эффективного использования STL необходимо разбираться во всем разнообразии реализаций string, особенно если ваша программа должна работать на разных платформах STL при жестких требованиях к быстродействию.
Кроме того, на концептуальном уровне контейнер string выглядел предельно просто. Кто бы мог подумать, что его реализация таит столько неожиданностей?
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Объект String
Объект String Объект String предоставляет средства для форматирования и выделения части строк. Для этой цели он содержит обширный перечень методов (табл. 11.14 и 11.15).Таблица 11.14. Свойства объекта String Таблица 11.15. Методы объекта String Рассмотрим использование методов объекта
string-length()
string-length() Как можно предположить, функция string-length возвращает длину (length) переданной ей строки. Функция применяется таким образом:number string-length(string?)В следующем примере я определяю длину названия каждой планеты при помощи string-length:<?xml version="1.0"?><xsl:stylesheet
Объект String
Объект String Встроенный объект String предназначен для выполнения различных операций над текстовыми строками. Обычно объекты класса String создаются просто с помощью записи в переменную текстового литерала:var s1, s2;s1 = "Это строка";s2 = "Это тоже строка";Также можно создавать такие
Помните: в Интернете пользователь может делать все, что захочет
Помните: в Интернете пользователь может делать все, что захочет Интернет – это совместно используемая, свободная информационная среда. Посетители не только сами решают, что смотреть, но и как смотреть. Пользователь может многое:– выбрать размер страницы и разрешение
string и wstring
string и wstring Все, что говорится о контейнере string, в равной степени относится и к wstring, его аналогу с расширенной кодировкой символов. Соответственно, любые упоминания о связи между string и char или char* относятся и к связи между wstring и wchar_t или wchar_t*. Иначе говоря, отсутствие
Совет 10. Помните о правилах и ограничениях распределителей памяти
Совет 10. Помните о правилах и ограничениях распределителей памяти Распределители памяти первоначально разрабатывались как абстракция для моделей памяти, позволяющих разработчикам библиотек игнорировать различия между near- и far-указателями в некоторых 16-разрядных
Совет 16. Научитесь передавать данные vector и string функциям унаследованного интерфейса
Совет 16. Научитесь передавать данные vector и string функциям унаследованного интерфейса С момента стандартизации С++ в 1998 году элита С++ настойчиво подталкивает программистов к переходу с массивов на vector. Столь же открыто пропагандируется переход от указателей char* к объектам
Совет 19. Помните о различиях между равенством и эквивалентностью
Совет 19. Помните о различиях между равенством и эквивалентностью Алгоритм find и функция set::insert являются типичными представителями семейства функций, проверяющих совпадение двух величин, однако делают это они по-разному. Для find совпадением считается равенство двух
Совет 31. Помните о существовании разных средств сортировки
Совет 31. Помните о существовании разных средств сортировки Когда речь заходит об упорядочении объектов, многим программистам приходит в голову всего один алгоритм: sort (некоторые вспоминают о qsort, но после прочтения совета 46 они раскаиваются и возвращаются к мыслям о
Совет 34. Помните о том. какие алгоритмы получают сортированные интервалы
Совет 34. Помните о том. какие алгоритмы получают сортированные интервалы Не все алгоритмы работают с произвольными интервалами. Например, для алгоритма remove (см. советы 32 и 33) необходимы прямые итераторы и возможность присваивания через эти итераторы. Таким образом,
Совет 50. Помните о web-сайтах, посвященных STL
Совет 50. Помните о web-сайтах, посвященных STL Интернет богат информацией об STL. Если ввести в любой поисковой системе запрос «STL», вы получите сотни ссылок, часть из которых даже будет содержать полезную информацию. Впрочем, большинство программистов STL в поисках не нуждается
6.9 Класс String
6.9 Класс String Вот довольно реалистичный пример класса строк string. В нем производится учет ссылок на строку с целью минимизировать копирование и в качестве констант применяются стандартные символьные строки С++.#include «stream.h» #include «string.h»class string (* struct srep (* char* s; // указатель на