Сингулярность:[54] легенда о происхождении ботов Джейсон Арбон
Сингулярность:[54] легенда о происхождении ботов
Джейсон Арбон
Давным-давно, в далеком-далеком офисе Google родилась… первая версия Chrome. Уже по первым поступившим данным было понятно, что Chrome отображает веб-страницы иначе, чем Firefox. В начале мы оценивали эти различия, только отслеживая объем поступающих сообщений о багах и подсчитывая количество жалоб на проблемы совместимости от пользователей, которые удаляли браузер после пробного использования.
Мне было интересно, есть ли более многоразовый, автоматизированный и объективный метод оценки того, насколько хорошо мы работаем в этой области. Были ребята до меня, которые пытались организовать автоматическое сравнение снимков веб-страниц между браузерами, а кто-то даже пытался использовать продвинутые методы распознавания изображений и границ. Правда, эти методы часто не работали, потому что между страницами всегда много различий, вспомните хотя бы о разных картинках в рекламе, меняющемся контенте и т.д. В базовых тестах макетов WebKit вычислялся хэш-код всего макета страницы (см. рис. 3.33). Поэтому когда обнаруживалась проблема, инженеры не имели понятия о том, что именно в приложении не работает, у них был только снимок ошибки. Многочисленные ложноположительные[55] срабатывания только прибавляли работы инженерам, вместо того чтобы уменьшать ее.

Рис. 3.33. В ранних средствах тестирования макетов WebKit использовались хэши всего макета страницы. Теперь мы можем тестировать целые страницы и обнаруживать сбои на уровне элементов, а не на уровне страницы
Мысли постоянно возвращали меня к ранней простой реализации ChromeBot, которая обходила миллионы URL-адресов в запущенных копиях браузера Chrome на тысячах виртуальных машин. Она искала всевозможные сбои, используя для этого свободное процессорное время в центрах обработки данных. Это был ценный инструмент, который находил баги на ранней стадии, а функциональное тестирование взаимодействия с браузером добавлялось позже. К сожалению, технология утратила свою новизну и использовалась только для выявления редких сбоев. А что, если построить более серьезную версию этого инструмента, которая будет нырять во всю страницу целиком, а не только ходить по берегу? И назвать ее, например, Bots.
Я подумал об использовании другого подхода: работы в DOM.[56] Около недели ушло на подготовку эксперимента, в котором загружалось много веб-страниц одна за другой, а потом в них внедрялся код JavaScript, который извлекал карту внутренней структуры веб-страницы.
Многие умные люди скептически отнеслись к этому решению. Они считали, что моя идея была обречена на неудачу, потому что:
— реклама постоянно изменяется;
— контент на таких сайтах, как CNN.com, постоянно меняется;
— специфичный для конкретного браузера код будет по-разному отображаться в разных браузерах;
— баги в самих браузерах будут приводить к возникновению различий;
— работа потребует огромных объемов данных.
Такая реакция сделала мою задачу только интереснее, и неудачи я не боялся. В прошлом я уже работал с другой поисковой системой, поэтому у меня была уверенность, что я смогу отделить сигнал от шума. К тому же в таком проекте у меня не было конкуренции. И я поднажал. В Google данные могут сказать много. И я хотел, чтобы они заговорили.
Чтобы запустить эксперимент, мне нужны были контрольные данные, с которыми я мог бы сравнивать полученные. Лучшим источником информации были тестировщики проекта Chrome, ведь они каждый день вручную открывали около 500 популярных сайтов в Chrome, пытаясь найти различия с Firefox. Я поговорил с подрядчиками, которые прогоняли вручную все эти сайты и сравнивали результаты с Firefox. Они рассказали, что сначала проблемы находились почти в половине популярных сайтов, но ситуация постепенно улучшалась, и сейчас расхождения встречаются редко — менее чем в 5% сайтов.
Я взял WebDriver (Selenium следующего поколения) и провел эксперимент. WebDriver лучше поддерживал Chrome, и его API куда более понятный. В первый прогон я собрал данные в разных версиях Chrome, от ранних до текущей, чтобы увидеть, найдет ли автоматизация такой же тренд. Тесты просто загружали те же веб-сайты, проверяли каждый пиксель, определяли, какой элемент HTML (не RGB-значение!) был видим в этой точке,[57] а потом отправляли данные на сервер. Выполнение на моем компьютере занимало около 12 часов, поэтому я запустил программу на ночь.
Полученные данные выглядели хорошо, поэтому я заменил Firefox на Chrome и снова запустил те же тесты на ночь. Конечно, мог появиться шум от изменения контента сайтов, но моя задача была только узнать, как выглядят данные, а потом выполнить обе серии параллельно. Когда я пришел утром в офис, я обнаружил, что мой компьютер выдернут из розетки. Мои соседи странно посматривали в мою сторону и сказали, что мне нужно поговорить со специалистами по безопасности. Я мог только догадываться, что они себе надумали. Оказалось, что во время обхода мой компьютер подхватил вирус с неизвестной сигнатурой, который и разбушевался ночью. Меня спросили, хочу ли я снять данные со своего компьютера, прежде чем диск будет уничтожен. К счастью, все мои данные хранились в облаке, и я отпустил свой компьютер с миром. После этого я стал запускать такие тесты только с внешних виртуальных машин.
За двое суток машины независимо выдали данные, которые были ужасно похожи на те, что мы получили примерно за год ручной тестовой работы (см. рис. 3.34). Подозрительно похожи.
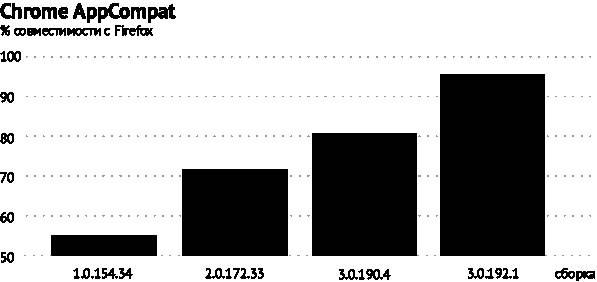
Рис. 3.34. Первые данные, демонстрирующие сходство между метриками количества, вычисленными людьми и ботами
Все это выглядело многообещающе. Результаты нескольких дней программирования и двух ночей выполнения на одном компьютере, кажется, сравнялись с результатами года работы группы тестировщиков. Я поделился своими данными с моим директором, имя которого называть не буду. Он посчитал, что это очень здорово, но предложил сосредоточиться на других, более зрелых проектах. Я поступил по-гугловски: сказал, что поставлю эксперимент на паузу, но делать этого не стал. Тем летом у нас была пара отличных интернов, которых мы подключили к оформлению этих запусков и поиску путей для более наглядного представления различий, — мы формировали продукт. Они экспериментировали, замеряя разницу времени выполнения. Эрик Ву и Елена Янг продемонстрировали свою работу в конце лета и заставили всех поверить, что у нашего метода большое будущее.
Теджас Шах тоже оказался под впечатлением. Когда практиканты ушли от нас, Теджас создал инженерную команду, которая должна была превратить этот эксперимент в реальность.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
§ 70. Разрешение экранов. И немного о происхождении 72 точек на дюйм
§ 70. Разрешение экранов. И немного о происхождении 72 точек на дюйм 24 июня 2001Компьютер не имеет ни малейшего представления о том, какое разрешение (в точках на дюйм) в данный момент на экране. Более того, компьютер не может об этом спросить ни у монитора, ни у видеокарты.
Пример отличного кандидата Джейсон Арбон
Пример отличного кандидата Джейсон Арбон Одного нашего кандидата (который, кстати, уже великолепно справляется с работой в Google) спросили, как бы он организовал тестирование граничных условий для версии этой функции с 64-разрядными целыми числами. Он быстро догадался, что
Пользовательские сценарии Джейсон Арбон
Пользовательские сценарии Джейсон Арбон Пользовательские истории описывают реальные или смоделированные способы, которыми пользователи используют приложение. Они описывают, чего хотят пользователи, смотрят на продукт их глазами, не учитывая архитектуру приложения и
Как отличить тестировщика от разработчика в тестировании Джейсон Арбон
Как отличить тестировщика от разработчика в тестировании Джейсон Арбон Роли разработчика в тестировании и инженера по тестированию взаимосвязаны, но между ними есть фундаментальные различия. Я был на обеих позициях и управлял обеими ролями. Взгляните на списки,
Управление «пиратским кораблем» для чайников Джеймс Арбон
Управление «пиратским кораблем» для чайников Джеймс Арбон «Пиратский корабль» — метафора, которую мы используем, когда говорим про управление командами тестирования в Google. Наше тестирование — это мир, в котором инженеры по природе своей постоянно задают вопросы,
Пример режима сопровождения: Google Desktop Джейсон Арбон
Пример режима сопровождения: Google Desktop Джейсон Арбон На середине очередного проекта мне предложили взяться за колоссальную задачу тестирования Google Desktop с десятками миллионов пользователей, клиентскими и серверными компонентами и интеграцией с поиском Google. Я стал
Слияние BITE с RPF Джеймс Арбон
Слияние BITE с RPF Джеймс Арбон В первые дни тестирования Chrome OS мы обнаружили, что главное качество платформы — безопасность — сильно осложняет тестирование. Тестируемость часто конфликтует с безопасностью, а ведь в Chrome OS очень большой упор сделан именно на безопасность.В
Инновации и эксперименты в тестировании Джеймс Арбон
Инновации и эксперименты в тестировании Джеймс Арбон Мы в Google за любые эксперименты, поэтому у нас и создается множество инноваций. Ну и куча неудачных экспериментов заодно. Даже если уже есть хорошее решение, мы не запрещаем инженерам пытаться придумать еще лучше.
Цвет Сириуса: первая легенда ярчайшей звезды ночного неба Дмитрий Вибе
Цвет Сириуса: первая легенда ярчайшей звезды ночного неба Дмитрий Вибе Опубликовано 12 января 2014 Зима в наших широтах — время, когда мы можем наблюдать ярчайшую звезду ночного неба, Сириус, альфу Большого Пса. Она заметно превосходит по видимому
Голубятня: Легенда №17 Сергей Голубицкий
Голубятня: Легенда №17 Сергей Голубицкий Опубликовано 31 мая 2013 Сегодня пятница, а значит на «Голубятне» — кинодень. Хочу поделиться с родной IT-братией впечатлениями от просмотра очередного отечественного патриотогонного действа под названием
Спутники Сириуса: вторая легенда ярчайшей звезды ночного неба Дмитрий Вибе
Спутники Сириуса: вторая легенда ярчайшей звезды ночного неба Дмитрий Вибе Опубликовано 19 января 2014 В конце концов, подумаешь — красный Сириус. Нет, лёгкий аромат тайны, конечно, присутствует: был местами красным, стал везде белым… Но всё равно
"Хаябуса-2" позволит узнать о происхождении жизни на Земле Михаил Карпов
"Хаябуса-2" позволит узнать о происхождении жизни на Земле Михаил Карпов Опубликовано 19 августа 2010 года Японское аэрокосмическое агентство JAXA готовится запустить вторую версию зонда «Хаябуса». Забавно, что японцы опять выбрали это имя — ведь
Кафедра Ваннаха: Сингулярность и джонка Ваннах Михаил
Кафедра Ваннаха: Сингулярность и джонка Ваннах Михаил Опубликовано 29 июня 2010 года Каждому этапу развития технологии соответствует свой миф. Первые успехи ракетной техники и пилотируемой космонавтики породили миф об освоении космоса, о «караванах
Кафедра Ваннаха: Взгляд россиян на сингулярность Ваннах Михаил
Кафедра Ваннаха: Взгляд россиян на сингулярность Ваннах Михаил Опубликовано 02 июля 2010 года Сегодняшние взгляды интеллигентных россиян на высокотехнологическое развитие нашей страны достойны плача на реках Вавилонских. Дескать, быть нам под