Поиск и замена текста
Поиск и замена текста
В текстовом редакторе Adobe InDesign можно воспользоваться полезнейшей функцией поиска и замены фрагментов текста. Причем, раз мы имеем дело с программой верстки, найденные фрагменты можно не только заменить другими, но и оформить каким-то образом – назначить им стиль оформления, изменить отдельные параметры шрифта и т. д.
Следует особо отметить, что возможности по поиску и замене в версии CS3 обновлены и расширены; и если раньше для решения особо сложных задач дизайнерам могло недоставать возможностей Adobe InDesign и в процессе подготовки текста к работе приходилось обращаться к текстовым редакторам других производителей, то InDesign новой версии способен «дать фору» любому текстовому процессору.
Команда Edit ? Find/Change (Редактировать ? Найти/Заменить) позволяет вызвать диалоговое окно поиска и замены текста (рис. 16.15).
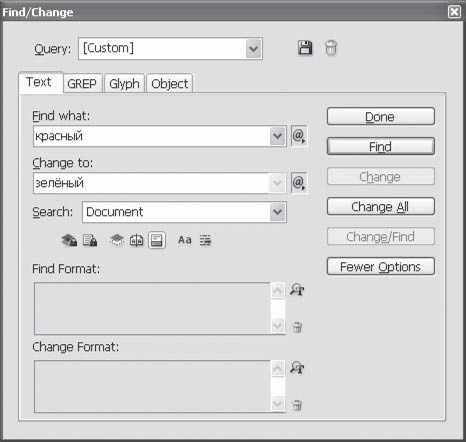
Рис. 16.15. Диалоговое окно Find/Change (Найти/Заменить), вкладка Text (Текст)
Раскрывающийся список Query (Запрос) позволяет выбрать одну из сохраненных настроек поиска и замены (создать их можно с помощью кнопки Save Query (Сохранить запрос) со значком дискеты справа от списка). Это полезно, если вы регулярно выполняете одни и те же операции по поиску и замене; среди «заводских» сохраненных запросов есть, к примеру, такие полезные, как замена прямых кавычек на типографские или замена двойных пробелов на одинарные.
Как видно на рис. 16.15, диалоговое окно Find/Change (Найти/Заменить) содержит четыре вкладки:
• Text (Текст) – здесь выполняются несложные операции по поиску и замене фрагментов текста;
• GREP – на этой вкладке можно создавать очень сложные запросы для поиска и замены текста;
• Glyph (Символ) – эта вкладка предназначена для поиска и замены отдельных символов в тексте;
• Object (Объект) – с помощью настроек этой вкладки можно находить объекты в документе и изменять их свойства.
Рассмотрим настройки этих вкладок.
Примечание
Операции по поиску и замене, выполняемые с помощью вкладки GREP, используют язык запросов POSIX, ставший де-факто стандартом в своей области и хорошо знакомый пользователям операционных систем Unix и Linux.
Возможности поиска и замены с использованием языка POSIX чуть ли не безграничны и позволяют выполнять очень сложные действия: запрос может содержать вариативные части и даже несложные логические условия. Однако в связи с этим язык POSIX достаточно не прост и может оказаться трудным для понимания.
В этой книге мы не будем касаться ни языка запросов POSIX, ни операций по поиску и замене текста с помощью вкладки GREP в принципе. Простой поиск и замена не требует использования этой вкладки; если же вы чувствуете необходимость, познакомиться с языком POSIX можно в соответствующей специальной литературе.
На вкладке Text (Текст) (см. рис. 16.15) вводится текст, который нужно найти (в поле Find What), и текст, на который нужно заменить найденное (в поле Change to). Кнопки Find (Найти), Change (Заменить), Change All (Заменить все) и Change/Find (Заменить и найти следующее) в правой части окна предназначены собственно для выполнения поиска и замены.
В правой же части диалогового окна находится кнопка More Options (Больше настроек), нажав которую мы отобразим поля Find Format (Искать форматирование) и Change Format (Заменить форматирование), с помощью которых можно ограничивать поиск с учетом оформления текста или изменять оформление. Сами поля служат только для отображения выбранного форматирования, а настраивается оно с помощью кнопок рядом с полями, которые открывают окно, по своему наполнению очень похожее на окно стиля абзацев и позволяющее указать самые разнообразные параметры оформления.
С помощью дополнительных меню рядом с полями поиска и замены можно задействовать при поиске и замене специальные символы (например, находить знаки табуляции, пробелы разной ширины), переменные (любой символ, любая цифра) и т. д. Такие символы и переменные обозначаются специальными последовательностями знаков, начинающихся со знака ^ (циркумфлекс, или знак возведения в степень). К примеру, знак табуляции обозначается символами ^t, а любая цифра – ^9. Символы можно вводить не только из дополнительного меню, но и вручную – только при этом их придется знать на память.
Раскрывающийся список Search (Искать в) позволяет указать, в какой части документа следует искать и заменять текст. Значения включают в себя All Documents (Все документы), Document (Текущий документ), Story (Текст в текущем фрейме и связанных с ним), To End of Story (С позиции курсора до конца текста) и Selection (Выделенный фрагмент). В зависимости от того создано ли выделение и установлен ли в тексте курсор, в списке могут присутствовать не все варианты: понятно, что бессмысленно предлагать искать в выделенном фрагменте, если выделенного фрагмента нет.
Под раскрывающимся списком Search (Искать в) присутствуют семь кнопок (на остальных вкладках кнопок только пять), позволяющих модифицировать условия поиска.
Кнопка Include Locked Layers (Включая заблокированные слои) позволяет производить поиск (и только поиск, замена невозможна) во фреймах, находящихся на заблокированных слоях в документе.
Кнопка Include Locked Stories (Включая заблокированные фрагменты текста) позволяет производить поиск (опять же, замена недоступна) в текстовых фреймах, защищенных от изменений.
Кнопка Include Hidden Layers (Включая скрытые слои) позволяет искать и заменять текст во фреймах, находящихся на отключенных, неотображающихся слоях документа.
Кнопка Include Master Pages (Включая мастер-страницы) позволяет искать и заменять текст во фреймах, находящихся на мастер-страницах.
Кнопка Include Footnotes (Включая сноски) позволяет искать и заменять текст не только в основной части текстовых фреймов, но и в автоматически созданных блоках со сносками.
Примечание
Все сказанное относительно этих пяти кнопок справедливо и для работы на других вкладках. Разумеется, в этом случае будет искаться не текст, а отдельные символы или объекты.
Кнопка Case Sensitive (С учетом регистра) позволяет искать написание слова, точно совпадающее с запросом по регистру написания букв. При нажатой кноп ке и запросе вася слова «Вася» и «ВАСЯ» найдены не будут.
При нажатой кнопке Whole Word (Целое слово) можно находить только законченные слова, соответствующие критерию поиска. Так, к примеру, программа по запросу «лук» с нажатой кнопкой не найдет слова «лука» и «луковый», поскольку в них с критерием совпадает только часть слова.
Однако «полезность» функции поиска и замены заключается не столько в возможности находить точно заданные фрагменты текста, сколько в возможности использования масок поиска или регулярных выражений (второй термин пришел из программирования). Говоря проще, вы можете задать неточный критерий поиска и найти все попадающие под него фрагменты. Соответственно, найденные фрагменты можно заменить или оформить каким-то образом.
Понять сущность поиска и замены с использованием масок поиска проще на очень легком примере. Предположим, что мы хотим найти в тексте все даты формата «1950 г.», «1951 г.», «1980 г.» и т. д. Нам нужно найти эти даты и выделить их красным цветом. Конечно же, эту задачу можно выполнить вручную – по очереди искать каждое новое число. Однако если диапазон дат в тексте – от 1950 до 1999 года, то нам придется повторить операцию поиска 50 раз, что, конечно же, несколько утомительно.
Внимание!
Здесь и далее будет использоваться написание в квадратных скобках и выделение курсивом для обозначения специальных символов.
Вместо этого можно отдать команду: найти все фрагменты текста, начинающиеся с цифр «1» и «9» и заканчивающиеся символами «[пробел]г.». Правда, такой поиск может найти все что угодно, например число «19» в начале текста и сокращение «г.» в конце. Поэтому нужно еще больше конкретизировать запрос и оформить его так: «19[любой-символ][любой-символ][пробел]г.». Отдав команду найти все фрагменты текста, попадающие под запрос, и выделить их цветом, мы решим поставленную задачу.
Следует заметить, что созданный запрос все же не настолько точен, как хотелось бы. Например, если текст будет содержать последовательность символов «195, г. Москва», то текст «195, г.» будет найден и выделен (ведь и цифра «5», и запятая попадают под определение «любой символ»). Поэтому программы часто содержат несколько разных специальных символов для создания масок – чем их больше и чем они разнообразней, тем более точный запрос вы можете создать.
Например, запрос формата «19[любая-цифра][любая-цифра][пробел]г.» будет более точным. А если бы мы исхитрились использовать определение вида «19[любая-цифра-от-5-до-9][любая-цифра][пробел]г.», то ошибки были бы исключены, и даже «1915 год» не был бы выделен, поскольку третья цифра (единица) не попадет под заданное определение. Такие сложные запросы позволяет ис пользовать архитектура запросов POSIX и раздел поиска GREP, о котором мы в этой книге не говорим; приведем только пример записи подобного запроса, чтобы вы могли убедиться, что это действительно непросто (рис. 16.16); возможности же вкладки Text (Текст) скромнее, и с ее помощью такого запроса составить нельзя. При работе с вкладкой Text (Текст) Adobe InDesign позволяет использовать четыре символа для образования масок поиска, которые находятся в подменю поля поиска Wildcards (Переменные): Any Digit (Любая цифра), Any Letter (Любая буква), Any Character (Любой символ), White Space (Любой пробельный символ, включая табуляции).
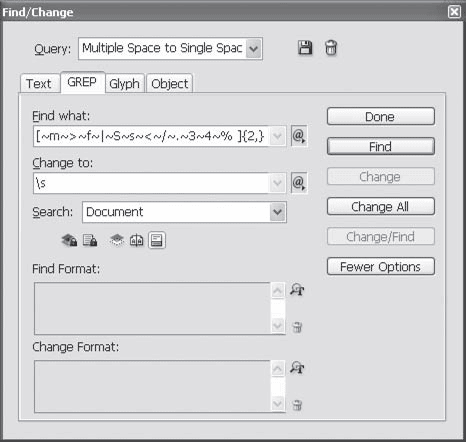
Рис. 16.16. Диалоговое окно Find/Change (Найти/Заменить), вкладка GREP
Процедуру поиска и замены можно и нужно использовать в процессе подготовки текста к верстке. В идеальном случае, как это уже говорилось, следует подготавливать текст перед импортом в Adobe InDesign в программе, где создавался текстовый файл; однако принципы использования масок поиска идентичны во всех редакторах, потому вы всегда сможете найти аналоги в других программах.
Рассмотренные в предыдущем разделе часто встречающиеся проблемы в тексте можно удалить проверенными способами. В большинстве случаев для этого потребуется несколько операций по поиску и замене, выполненных над одним текстом.
Если в тексте не используются специальные символы конца абзаца, то абзацы можно определить по пустой строке между ними или по пробелам или символу табуляции в начале абзаца. В обоих случаях задача – найти и удалить все символы конца абзаца, кроме правильных.
Если абзацы разделены пустой строкой, то сначала мы должны убедиться, что эта строка действительно пустая. В частности, в ней не должно быть пробелов – а они там часто могут встретиться. Следовательно, первым делом мы должны найти все строки, начинающиеся с пробела, и удалить этот пробел. В этом случае формат поиска будет выглядеть так – ^p^w, замены – ^p.
Поиск и замену следует повторить многократно, до тех пор, пока количество найденных и замененных случаев не будет равно нулю (если бы мы знали, сколько пробелов в пустых строках, можно было бы справиться быстрее, но мы не знаем этого точно – не считать же их по всему тексту).
Следующим шаг – найти все пустые строки. Теперь, когда они совсем пустые, в тексте они выглядят как знак «конец абзаца» сразу после другого знака «конец абзаца». Мы находим все двойные знаки абзаца (формат поиска – ^p^p) и заменяем их чем-нибудь таким, что никогда и ни при каких условиях не встретится в тексте (например, вот таким сочетанием: ==((АБЗАЦ))==) – чтобы потом случайно не заменить чем-нибудь нужным.
Следующий шаг – удаление всех знаков «конец абзаца» и замена их знаком «пробел». Просто удалять знаки «конец абзаца» нельзя, потому что это может привести к тому, что слова «сольются»; если же возникнут двойные пробелы, то их легко найти и удалить. В результате проведенной операции весь текст сольется в одну строку, но настоящие абзацы отмечены в тексте нашим сложным набором символов. Найдя его и заменив знаком «конец абзаца», мы закончим исправление абзацев в тексте.
Если абзацы отмечены пробелами или знаком табуляции, то алгоритм действий будет похож на предыдущий. Только в этом случае мы найдем все знаки табуляции (или цепочки пробелов) в начале абзаца и заменим их каким-нибудь набором символов, не встречающимся в тексте. Затем нужно удалить все знаки «конец абзаца» и заменить использованный набор символов знаком «конец абзаца».
Знаки кавычек можно исправить при использовании поиска и замены. В то время, как уникальный признак закрывающей кавычки придумать нельзя (перед ней может быть любой символ, а после нее пробел или знак препинания), открывающие кавычки всегда стоят после пробела. Найдя и заменив все знаки «фут» или «дюйм» после пробела открывающейся кавычкой, следующим шагом мы можем найти все оставшиеся знаки «фут» или «дюйм» и заменить закрывающейся кавычкой.
Знаки «тире» можно найти и исправить в несколько приемов. Тире использу ется при оформлении диалогов или как знак препинания. В первом случае найти и заменить легко: достаточно найти все знаки «дефис», стоящие в начале абзаца. Знак «тире» как знак препинания принято отделять от слов пробелами, и это подскажет, как его найти. Однако следует помнить, что иногда комбинация знаков «запятая» и «тире» пишется без пробела, поэтому может возникнуть необходимость искать отдельно знаки «дефис» после пробела и отдельно – знаки «дефис» перед пробелом. В обоих случаях желательно добавить пробелы вокруг знака «тире»; появляющиеся двойные пробелы убрать очень легко, зато добавление пробелов может исправить некоторые ошибки, например «прилипшие» к словам знаки.
Знаки переносов можно попытаться убрать нахождением и удалением (не заменой пробелом!) всех дефисов в конце строки (абзаца, если это текст в формате TXT). Однако при этом могут быть удалены и знаки «тире», поэтому нужно оформить запрос как «[любая-буква][дефис]». Тем не менее, после этого необходимо внимательно просмотреть весь текст на предмет неудаленных пробелов или случайно внесенных ошибок.
Примечание
Изучив заводские сохраненные настройки поиска и замены, вы можете обнаружить, что они содержат настройки для замены дефисов на тире, двойных пробелов на одинарные и удаления пустых строк. Часть из этих запросов создана с использованием вкладки GREP, чтобы обойтись одной операцией по иска и замены вместо нескольких. Тем не менее мы привели эти примеры, чтобы вы знали, как они «устроены» и могли самостоятельно выполнять подобные операции в других ситуациях.
Вкладка Glyph (Символ) (рис. 16.17) позволяет находить и заменять отдельные символы в тексте.
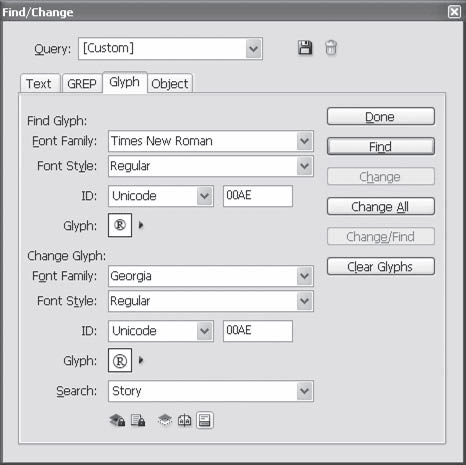
Рис. 16.17. Диалоговое окно Find/Change (Найти/Заменить), вкладка Glyph (Символ)
Как для искомого символа (в группе настроек Find Glyph (Найти символ)), так и для символа, которым заменяется найденный (в группе настроек Change Glyph (Заменить символ)), можно установить следующие атрибуты:
• Font Family (Семейство шрифтов) – из этого раскрывающегося списка выбирается гарнитура шрифта, символ которого требуется найти (или гарнитура шрифта, символом которого нужно заменить найденное);
• Font Style (Начертание) – в этом списке выбирается одно из начертаний выбранной гарнитуры;
• ID (Идентификатор) – с помощью этого списка и находящегося рядом поля можно указать нужный символ. В поле вводится номер (или буквенно-цифровой идентификатор) символа, а раскрывающийся список позволяет выбрать одну из систем классификации символов – в зависимости от нее одному и тому же символу будут соответствовать разные номера. Система Unicode, выбранная по умолчанию, является «естественной» для операционной системы Windows, и использовать ее будет проще всего.
Поле Glyph (Символ) отображает выбранный с помощью параметра ID (Идентификатор) символ, так что вы можете проверить, правильно ли указали его номер. Кроме того, дополнительное меню рядом с полем Glyph (Символ) открывает вспомогательное окно, в котором можно выбрать нужный символ из списка символов шрифта.
Кнопка Clear Glyphs (Очистить символы) в правой части диалогового окна обнуляет настройки, выполненные в окне. Остальные элементы диалогового окна выполняют те же функции, что и при работе с вкладкой Text (Текст).
Команды вкладки Object (Объект) (рис. 16.18) находят в документе объекты по их оформлению и изменяют его.
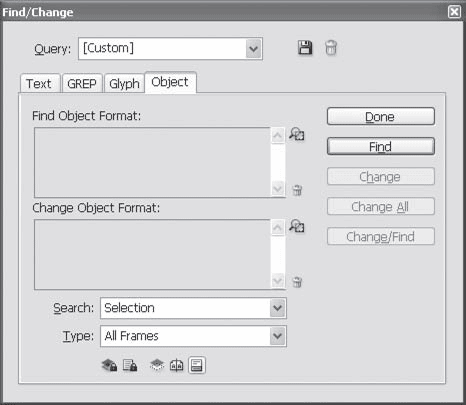
Рис. 16.18. Диалоговое окно Find/Change (Найти/Заменить), вкладка Object (Объект)
Поля Find Object Format (Искать форматирование объекта) и Change Object Format (Заменить форматирование объекта) отображают выполненные с помощью вспомогательного диалогового окна настройки; само же диалоговое окно открывается нажатием кнопок рядом с полями и содержит все настройки, которые могут быть у объекта, включая добавившиеся в Adobe InDesign CS3 эффекты объектов.
Раскрывающийся список Search (Искать в) по-прежнему позволяет указать область поиска: по всему документу, во всех открытых документах или среди выделенных объектов. С помощью раскрывающегося списка Type (Тип) можно дополнительно сузить область поисков – в зависимости от выбранного значения будут найдены и изменены только объекты определенного типа. Команда Text Frames (Текстовые фреймы) находит только фреймы с текстом (или пустые фреймы, которые тем не менее должны содержать текст), команда Graphic Frames (Графические фреймы) находит фреймы с изображениями (в том числе и потенциально возможными). Любопытно, что с точки зрения Adobe InDesign графические объекты (прямоугольники, эллипсы, многоугольники) – это тоже фреймы, но еще не «использованные». Значение Unassigned Frames (Неназначенные фреймы) позволит найти именно эти фигуры – иными словами, фреймы и не текстовые, и не графические. Наконец, команда All Frames (Все фреймы) найдет все: графические фреймы, текстовые фреймы и простые объекты.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Поиск и замена данных
Поиск и замена данных В программе HtmlPad реализована возможность быстрого поиска данных. Этот механизм полезно использовать при работе с большими программными кодами или с большими объемами данных, поскольку поиск требуемой информации вручную (например, путем просмотра
Быстрый поиск и замена данных в программе NeonHtml
Быстрый поиск и замена данных в программе NeonHtml В программе NeonHtml реализована возможность быстрого поиска данных. Это особенно актуально при работе с большими программными кодами или с большими объемами данных, поскольку поиск требуемой информации вручную (например,
Поиск и замена данных
Поиск и замена данных В программе Extra Hide Studio имеется удобный механизм для быстрого поиска и замены данных. Эта возможность особенно актуальна при работе с большими исходными кодами, поскольку поиск данных путем просмотра всего кода может занять слишком много времени, и к
Поиск на научных сайтах с использованием платформы Flexum «Поиск по научным сайтам»
Поиск на научных сайтах с использованием платформы Flexum «Поиск по научным сайтам» Тема научного поиска не прошла мимо разработчиков персональных поисковиков. Подробному рассказу о возможностях таких поисковых систем посвящена отдельная глава нашей книги (см. главу 6).
3.1. Поиск и замена фрагментов
3.1. Поиск и замена фрагментов Текстовый редактор успешно справляется с поиском и заменой текста в отдельном файле. Однако, если это же нужно сделать сразу в нескольких файлах, лучше воспользоваться специальными программами, с помощью которых можно заменить фрагменты
Поиск и замена текста с помощью VBA в Word
Поиск и замена текста с помощью VBA в Word Хотя это звучит и несколько необычно, но Find - это объект Word VBA. Объекты Find принадлежат диапазонам и выделенным областям. Для обнаружения или форматирования текста с помощью объекта Find вам потребуется выполнить следующие действия.1.
Поиск и замена форматирования
Поиск и замена форматирования Для поиска текста с определенным форматированием используйте свойства объекта Find, касающиеся форматирования. Они идентичны свойствам, используемым при работе с форматированием диапазона или выделенной области, как я уже отмечал в разделе
Автоматический поиск и замена данных
Автоматический поиск и замена данных В процессе работы иногда возникает необходимость быстро найти те или иные данные (слово, текстовый фрагмент и т. д.) либо заменить одни данные на другие. Для решения такой задачи в Publisher 2007 реализован механизм автоматического поиска и
Поиск и замена
Поиск и замена В новой версии Excel был полностью изменен пользовательский интерфейс и расширены функциональные возможности средства Найти и заменить. Теперь можно с помощью одной операции производить поиск и замену по всем листам книги, повторно выполнять запросы поиска
Поиск и замена символов
Поиск и замена символов Иногда при подготовке электронных документов возникает задача поиска определенных текстовых фрагментов. Например, вы забыли номер чертежа, но помните, что в его названии или дополнительной информации, размещенной на чертеже, содержится
5.7. Поиск и замена
5.7. Поиск и замена В документе можно производить автоматический поиск текста и замену его другим.Поиск и замена ведется по введенному образцу. Если в качестве образца указано слово «ход», то компьютер найдет и слово «пароход», если предварительно не поставить условие, что
13.3.4. Поиск и замена текста
13.3.4. Поиск и замена текста Как вы уже догадались, окно Найти и заменить используется не только для перехода на нужную страницу. Вкладка Найти используется для поиска текста. Для быстрого доступа к этой вкладке нажмите Ctrl+F или выберите команду меню Правка, Найти. Нажмите
Поиск и замена
Поиск и замена Для поиска в тексте документа нужного слова или сочетания символов служит окно поиска и замены (рис. 9.19), которое открывается нажатием Ctrl+F. Если надо, чтобы оно сразу открылось как окно замены, используйте сочетание Ctrl+H. Рис. 9.19. Окно поиска и замены.Для
Поиск и замена фрагментов фильма
Поиск и замена фрагментов фильма Очень часто бывает нужно найти в изображении или фильме Flash какой-либо текст и, возможно, заменить его на другой. Специально для этого Flash, как и многие другие программы, работающие с документами, предлагает богатые возможности по поиску и
Поиск и замена текста
Поиск и замена текста Поиск определенного слова или фразы в большом документе является довольно непростой задачей, но ее можно значительно упростить, если воспользоваться командой Главная ? Редактирование ? Найти. В появившемся окне (рис. 5.20) введите искомый текст и
Поиск и замена данных
Поиск и замена данных По современным меркам таблица с несколькими тысячами записей считается небольшой, но даже в такой таблице ручной поиск или отбор нужной информации может занять продолжительное время. С помощью средств поиска, сортировки и фильтрации нужные данные